文本去重之MinHash算法——就是多个hash函数对items计算特征值,然后取最小的计算相似度
来源:http://my.oschina.net/pathenon/blog/65210
1.概述
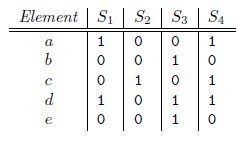
那么对集合A、B,hmin(A) = hmin(B)成立的条件是A ∪ B 中具有最小哈希值的元素也在 ∩ B中。这里
有一个假设,h(x)是一个良好的哈希函数,它具有很好的均匀性,能够把不同元素映射成不同的整数。
所以有,Pr[hmin(A) = hmin(B)] = J(A,B),即集合A和B的相似度为集合A、B经过hash后最小哈希值相
等的概率。
文本去重之MinHash算法——就是多个hash函数对items计算特征值,然后取最小的计算相似度的更多相关文章
- 文本去重之MinHash算法
1.概述 跟SimHash一样,MinHash也是LSH的一种,可以用来快速估算两个集合的相似度.MinHash由Andrei Broder提出,最初用于在搜索引擎中检测重复网页.它也可以应用 ...
- 文本去重之SimHash算法
文本去重之SimHash算法 - pathenon的个人页面 - 开源中国社区 文本去重之SimHash算法
- hash算法和常见的hash函数 [转]
Hash,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值. 这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能 会散列成相同的输出,而不 ...
- HASH、HASH函数、HASH算法的通俗理解
之前经常遇到hash函数或者经常用到hash函数,但是hash到底是什么?或者hash函数到底是什么?却很少去考虑.最近同学去面试被问到这个问题,自己看文章也看到hash的问题.遂较为细致的追究了一番 ...
- [Algorithm] 使用SimHash进行海量文本去重
在之前的两篇博文分别介绍了常用的hash方法([Data Structure & Algorithm] Hash那点事儿)以及局部敏感hash算法([Algorithm] 局部敏感哈希算法(L ...
- 使用SimHash进行海量文本去重[转载]
阅读目录 1. SimHash与传统hash函数的区别 2. SimHash算法思想 3. SimHash流程实现 4. SimHash签名距离计算 5. SimHash存储和索引 6. SimHas ...
- 使用SimHash进行海量文本去重[转]
阅读目录 1. SimHash与传统hash函数的区别 2. SimHash算法思想 3. SimHash流程实现 4. SimHash签名距离计算 5. SimHash存储和索引 6. SimHas ...
- 使用SimHash进行海量文本去重
阅读目录 1. SimHash与传统hash函数的区别 2. SimHash算法思想 3. SimHash流程实现 4. SimHash签名距离计算 5. SimHash存储和索引 6. SimHas ...
- 海量数据去重之SimHash算法简介和应用
SimHash是什么 SimHash是Google在2007年发表的论文<Detecting Near-Duplicates for Web Crawling >中提到的一种指纹生成算法或 ...
随机推荐
- c++中如何查看一个类的内存布局
打开VS command prompt,输入下述命令可以看到对象的内存布局. cl a.cpp -d1 reportSingleClassLayout[classname] // reportSin ...
- python selenium2示例 - email发送
前言 在进行日常的自动化测试实践中,我们总是需要将测试过程中的记录.结果等等等相关信息通过自动的手段发送给相关人员.python的smtplib.email模块为我们提供了很好的email发送等功能的 ...
- 【原创】Hibernate自动生成(2)
本实战是博主初次学习Java,分析WCP源码时,学习HibernateTools部分的实战,由于初次接触,难免错误,仅供参考,希望批评指正. 开发环境: Eclipse Version: Photon ...
- (比赛)B - Super Mobile Charger
B - Super Mobile Charger Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & ...
- shell 字符串处理汇总(查找,替换等等)
字符串: 简称“串”.有限字符的序列.数据元素为字符的线性表,是一种数据的逻辑结构.在计算机中可有不同的存储结构.在串上可进行求子串.插入字符.删除字符.置换字符等运算. 字符: 计算机程序设计及操作 ...
- Residual (numerical analysis)
In many cases, the smallness of the residual means that the approximation is close to the solution, ...
- 我的Java开发学习之旅------>Java 格式化类(java.util.Formatter)基本用法
本文参考: http://docs.oracle.com/javase/1.5.0/docs/api/java/util/Formatter.html http://www.blogjava.net/ ...
- IDEA报错: Invalid bound statement (not found): com.test.mapper.UserMapper.selectByPrimaryKey(转发:https://www.cnblogs.com/woshimrf/p/5138726.html)
学习mybatis的过程中,测试mapper自动代理的时候一直出错,在eclipse中可以正常运行,而同样的代码在idea中却无法成功.虽然可以继续调试,但心里总是纠结原因.百度了好久,终于找到一个合 ...
- linux 11 -- mount,umount
Linux 文件系统是一个以 / 为根的大树,我们在不同的设备和分区上都有文件系统.我们如何处理这种明显的不一致性?根 (/) 文件系统是在初始化过程中挂载的.您创建的其他每个文件系统在挂载 在挂载点 ...
- persisted? vs new_record?
https://joe11051105.gitbooks.io/you-need-to-know-about-ruby-on-rails/content/activerecord/persisted_ ...