1、使用Python3爬取美女图片-网站中的每日更新一栏
此代码是根据网络上其他人的代码优化而成的,
环境准备:
pip install lxml
pip install bs4
pip install urllib
#!/usr/bin/env python
#-*- coding: utf-8 -*- import requests
from bs4 import BeautifulSoup
import os
import urllib
import random class mzitu(): def all_url(self, url):
html = self.request(url)
all_a = BeautifulSoup(html.text, 'lxml').find('div', class_='all').find_all('a')
for a in all_a:
title = a.get_text()
print(u'开始保存:', title)
title = title.replace(':', '')
path = str(title).replace("?", '_')
if not self.mkdir(path): ##跳过已存在的文件夹
print(u'已经跳过:', title)
continue
href = a['href']
self.html(href) def html(self, href):
html = self.request(href)
max_span = BeautifulSoup(html.text, 'lxml').find('div', class_='pagenavi').find_all('span')[-2].get_text()
for page in range(1, int(max_span) + 1):
page_url = href + '/' + str(page)
self.img(page_url) def img(self, page_url):
img_html = self.request(page_url)
img_url = BeautifulSoup(img_html.text, 'lxml').find('div', class_='main-image').find('img')['src']
self.save(img_url, page_url) def save(self, img_url, page_url):
name = img_url[-9:-4]
try:
img = self.requestpic(img_url, page_url)
f = open(name + '.jpg', 'ab')
f.write(img.content)
f.close()
except FileNotFoundError: ##捕获异常,继续往下走
print(u'图片不存在已跳过:', img_url)
return False def mkdir(self, path): ##这个函数创建文件夹
path = path.strip()
isExists = os.path.exists(os.path.join("D:\mzitu", path))
if not isExists:
print(u'建了一个名字叫做', path, u'的文件夹!')
path = path.replace(':','')
os.makedirs(os.path.join("D:\mzitu", path))
os.chdir(os.path.join("D:\mzitu", path)) ##切换到目录
return True
else:
print(u'名字叫做', path, u'的文件夹已经存在了!')
return False def requestpic(self, url, Referer): ##这个函数获取网页的response 然后返回
user_agent_list = [ \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \
65-1 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0",\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
ua = random.choice(user_agent_list)
headers = {'User-Agent': ua, "Referer": Referer} ##较之前版本获取图片关键参数在这里
content = requests.get(url, headers=headers)
return content def request(self, url): ##这个函数获取网页的response 然后返回
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
content = requests.get(url, headers=headers)
return content Mzitu = mzitu() ##实例化
Mzitu.all_url('http://www.mzitu.com/all/') ##给函数all_url传入参数 你可以当作启动爬虫(就是入口)
print(u'恭喜您下载完成啦!')
执行步骤:
重复执行代码的话已保存的不会再次下载保存
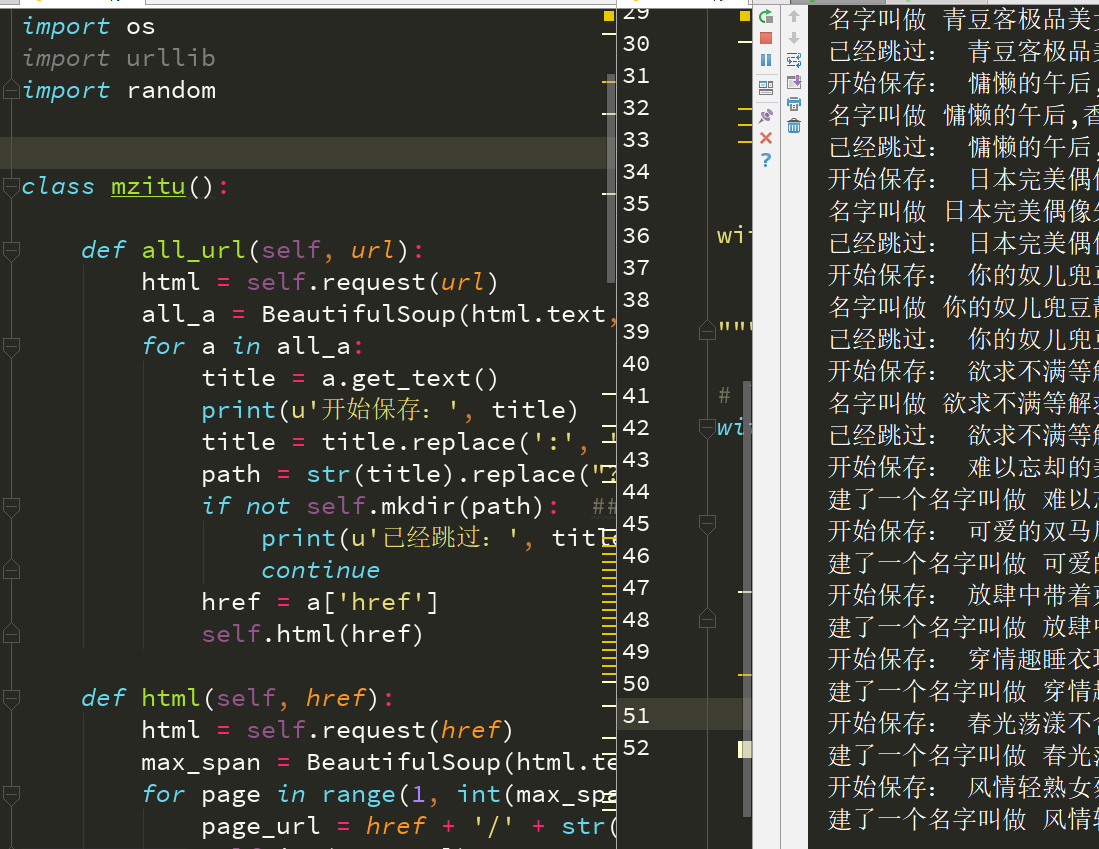
执行结果:
遇到的错误如何解决:
1、错误提示:requests.exceptions.ChunkedEncodingError: ("Connection broken: ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)", ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
错误原因分析:访问量瞬间过大,被网站反爬机制拦截了
解决方法:稍等一段时间再次执行即可
2、requests.exceptions.ChunkedEncodingError: ("Connection broken: ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)", ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
错误原因分析:可能对方服务器做了反爬
解决方法:requests手动添加一下header


1、使用Python3爬取美女图片-网站中的每日更新一栏的更多相关文章
- 2、使用Python3爬取美女图片-网站中的妹子自拍一栏
代码还有待优化,不过目的已经达到了 1.先执行如下代码: #!/usr/bin/env python #-*- coding: utf-8 -*- import urllib import reque ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- android高仿抖音、点餐界面、天气项目、自定义view指示、爬取美女图片等源码
Android精选源码 一个爬取美女图片的app Android高仿抖音 android一个可以上拉下滑的Ui效果 android用shape方式实现样式源码 一款Android上的新浪微博第三方轻量 ...
- Python3爬取王者官方网站英雄数据
爬取王者官方网站英雄数据 众所周知,王者荣耀已经成为众多人们喜爱的一款休闲娱乐手游,今天就利用python3 爬虫技术爬取官方网站上的几十个英雄的资料,包括官方给出的人物定位,英雄名称,技能名称,CD ...
- Python3爬取美女妹子图片转载
# -*- coding: utf-8 -*- """ Created on Sun Dec 30 15:38:25 2018 @author: 球球 "&qu ...
随机推荐
- docker 私有仓库的两种方式
1.使用官方默认的registry镜像构建本地仓库 这种方式适用于小规模的镜像仓库储存,没有Ui界面 (1)docker pull registry (2)docker run -d -p 5000: ...
- SendKeys发送组合键
使用: using System.Windows.Forms;//添加命名空间引用 { SendKeys.SendWait("{DOWN}"); ppt.ppt_sendkey(& ...
- 10行Python代码实现人脸定位
10行python机器学习全卷机网,实现100+张人脸同时定位! 发表评论 1,049 游览 A+ 所属分类:未分类 收 藏 今天介绍一个快速定位人脸的深度学习算法MTCNN,全称是:Multi-t ...
- 【ACM-ICPC 2018 南京赛区网络预赛 A】An Olympian Math Problem
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 估计试几个就会发现答案总是n-1吧. 队友给的证明 [代码] #include <bits/stdc++.h> #def ...
- CodeForcesGym 100548G The Problem to Slow Down You
The Problem to Slow Down You Time Limit: 20000ms Memory Limit: 524288KB This problem will be judged ...
- SQL优化-标量子查询(数据仓库设计的隐患-标量子查询)
项目数据库集群出现了大规模节点宕机问题.经查询,问题在于几张表被锁.主要问题在于近期得几个项目在数据库SQL编写时大量使用了标量子查询. 为确定为题确实是由于数据表访问量超过单节点限制,做了一些测试. ...
- G - Arctic Network
G - Arctic Network #include<cmath> #include<cstdio> #include<cstring> #include&l ...
- 由free命令想到的
root@xdj-Z9PA-D8-Series:~# free -m total used free shared buffers cached Mem: 15977 1683 14293 0 132 ...
- POJ 1320
作弊了--!该题可以通过因式分解得到一个佩尔方程....要不是学着这章,估计想不到.. 得到x1,y1后,就直接代入递推式递推了 x[n]=x[n-1]*x[1]+d*y[n-1]*y[1] y[n] ...
- 全屏滚动实现:fullPage.js和fullPage
fullPage.js和fullPage都能实现全屏滚动,二者差别是:fullPage.js需依赖于JQuery库,而fullPage不须要依赖不论什么一个js库.能够单独使用. 一.fullPage ...