CNN结构:用于检测的CNN结构进化-一站式方法
有兴趣查看原文:YOLO详解
人眼能够快速的检测和识别视野内的物体,基于Maar的视觉理论,视觉先识别出局部显著性的区块比如边缘和角点,然后综合这些信息完成整体描述,人眼逆向工程最相像的是DPM模型。
目标的检测和定位中一个很困难的问题是,如何从数以万计的候选窗口中挑选包含目标物的物体。只有候选窗口足够多,才能保证模型的 Recall。传统机器学习方法应用,使用全局特征+级联分类器的思路仍然被持续使用。常用的级联方法有haar/LBP特征+Adaboost决策树分类器级联检测
和HOG特征 + SVM分类器级联检测。
目前,基于CNN的目标检测框架主要有两种:
一种为two-stage基于框选择的方式,另一种是 one-stage ,例如 YOLO、SSD 等,这一类方法速度很快,但识别精度没有 two-stage 的高,其中一个很重要的原因是,利用一个分类器很难既把负样本抑制掉,又把目标分类好。
YOLO的原始论文为 2016 CVPR You Only Look Once:Unified, Real-Time Object Detection。
论文这样说:We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem
to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be
optimized end-to-end directly on detection performance.
YOLO的特别之处,在于把检测问题表示为一个分类问题,而不是以往的寻找绑定框/包围盒+分类的问题。使用一个网络实现检测的功能,成为一个端到端的图像检测系统。
网络结构
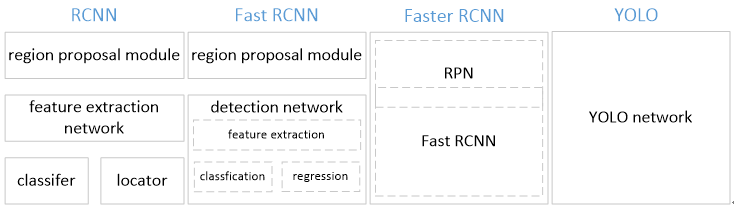
从网络设计上,YOLO与rcnn、fast rcnn及faster rcnn的区别如下:
(1)YOLO训练和检测均是在一个单独网络中进行。YOLO没有显示地求取region proposal的过程。而rcnn/fast rcnn 采用分离的模块(独立于网络之外的selective search方法)求取候选框(可能会包含物体的矩形区域),训练过程因此也是分成多个模块进行。Faster rcnn使用RPN(region proposal network)卷积网络替代rcnn/fast
rcnn的selective search模块,将RPN集成到fast rcnn检测网络中,得到一个统一的检测网络。尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络(注意这两个网络核心卷积层是参数共享的)。
(2)YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
One Stage方法基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。从YOLO开始,逐渐发展的CNN网络有YOLO、SSD-Net、YOLO-9000、ION-Net等。从网络设计上,YOLO与rcnn、fast rcnn及faster rcnn的区别如下:
YOLO检测步骤
如图所示

检测过程分为3个步骤,(1)将图像缩放到448*448(2)通过神经网格进行检测和分类(3)NMS抑制,输出最终结果。
YOLO网络结构

YOLO检测网络包括24个卷积层和2个全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception 模块,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
YOLO论文中,作者还给出一个更轻快的检测网络fast YOLO,它只有9个卷积层和2个全连接层。使用titan x GPU,fast YOLO可以达到155fps的检测速度,但是mAP值也从YOLO的63.4%降到了52.7%,但却仍然远高于以往的实时物体检测方法(DPM)的mAP值。
作为回归方法的YOLO
把检测问题描述为一个回归问题。


YOLO将输入图像分成
S x S 个格子,每个格子负责检测 ‘落入’ 该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如上图所示,图中物体狗的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的物体狗。
每个格子输出
B 个bounding box/BBX包围盒(包含物体的矩形区域)信息,以及 C 个物体属于某种类别的概率信息。
Bounding box信息包含5个数据值,分别是x,y,w,h,和confidence。其中 x,y 是指当前格子预测得到的物体的bounding box的中心位置的坐标。w, h 是BBX / 包围盒 的宽度和高度。
注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到 [0,1] 区间内;x,y是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到 [0,1] 。
confidence反映当前BBX是否包含物体以及物体位置的准确性,计算方式如下:
confidence = P(object)* IOU,
其中,若BBX包含物体,则P(object) = 1;否则P(object) = 0. IOU(intersection over union)为预测 BBX与物体真实区域的交集面积(以像素为单位,用真实区域的像素面积归一化到[0,1]区间)。
YOLO网络最终的全连接层的输出维度是S*S*(B*5 + C)。
For evaluating YOLO on PASCAL VOC, we use S = 7,B = 2. PASCAL VOC has 20 labelled classes so C = 20. Our final prediction is a 7 *7 *30 tensor.
YOLO论文中,作者训练采用的输入图像分辨率是448x448,S=7,B=2;采用VOC 20类标注物体作为训练数据,C=20。因此输出向量为7*7*(20 + 2*5)=1470维。作者开源出的YOLO代码中,全连接层输出特征向量各维度对应内容如下:

缺点:
*由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。输入图像必须resize一下。
*虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
损失函数定义
YOLO使用均方和误差MSE作为loss函数来优化模型参数,即网络输出的S*S*(B*5 + C)维向量与真实图像的对应S*S*(B*5 + C)维向量的均方和误差。如下式所示。其中,corrdError、iouError和classError分别代表预测数据与标定数据之间的坐标误差、IOU误差和分类误差。
【1】
YOLO对上式loss的计算进行了如下修正。
[1] 位置相关误差(坐标、IOU)与分类误差对网络loss的贡献值是不同的,因此YOLO在计算loss时,使用修正
。
[2] 在计算IOU误差时,包含物体的格子与不包含物体的格子,二者的IOU误差对网络loss的贡献值是不同的。若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用修正
。(注此处的‘包含’是指存在一个物体,它的中心坐标落入到格子内)。
[3]对于相等的误差值,大物体误差对检测的影响应小于小物体误差对检测的影响。这是因为,相同的位置偏差占大物体的比例远小于同等偏差占小物体的比例。YOLO将物体大小的信息项(w和h)进行求平方根来改进这个问题。(注:这个方法并不能完全解决这个问题)。
综上,YOLO在训练过程中Loss计算如下式所示:

其 中,为网络预测值,
帽
为标注值。表示物体落入格子i中,
和
分别表示物体落入与未落入格子i的第j个bounding
box内。
注:
*YOLO方法模型训练依赖于物体识别标注数据,因此,对于非常规的物体形状或比例,YOLO的检测效果并不理想。
*YOLO采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果。
* YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
YOLO训练方式
1、网络训练/预训练。使用ImageNet1000类数据训练YOLO网络的前20个卷积层+1个average池化层+1个全连接层。训练图像分辨率resize到224x224。
2、用步骤1得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,然后用VOC 20类标注数据 / 或者自己标记的数据集进行YOLO模型训练。为提高图像精度,在训练检测模型时,将输入图像分辨率resize到448x448。
YOLO优缺点
优点
- 简单方便快。YOLO将物体检测作为回归问题进行求解,整个检测网络pipeline简单。在titan x GPU上,在保证检测准确率的前提下(63.4% mAP,VOC 2007 test set),可以达到45fps的检测速度。
- 背景误检率低。YOLO在训练和推理过程中能‘看到’ 整张图像的整体信息,而基于region proposal的物体检测方法(如rcnn/fast rcnn),在检测过程中,只‘看到’候选框内的局部图像信息。因此,若当图像背景(非物体)中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体。测试证明,YOLO对于背景图像的误检率低于fast
rcnn误检率的一半。论文中,YOLO对背景内容的误判率(4.75%)比fast rcnn的误判率(13.6%)低很多。
- 通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
缺点:
- 识别物体位置精准性差。论文中,YOLO的定位准确率较差,占总误差比例的19.0%,而fast rcnn仅为8.6%。
- 召回率低。只能找到一个。
SSD-NET
The Single Shot Detector(SSD)
GitHub:使用MxNet的SSD-Net实现 https://github.com/zhreshold/mxnet-ssd
文章链接:论文阅读:SSD: Single Shot MultiBox Detector 
2016年 ECCV 2016 的一篇文章,是 UNC Chapel Hill(北卡罗来纳大学教堂山分校) 的 Wei Liu 大神的新作,论文代码:https://github.com/weiliu89/caffe/tree/ssd
SSD 将输出一系列
离散化(discretization) 的 bounding boxes,这些 bounding boxes 是在不同层次(layers) 上的 feature maps 上生成的,并且有着不同的aspect ratio。
主要贡献总结如下:
提出了新的物体检测方法:SSD,比原先最快的YOLO: You Only Look Once 方法,还要快,还要精确。保证速度的同时,其结果的mAP 可与使用region
proposals 技术的方法(如Faster R-CNN)相媲美。SSD 方法的核心就是
predict object(物体),以及其归属类别的 score(得分);同时,在 feature map 上使用小的卷积核,去predict 一系列 bounding boxes 的box offsets。本文中为了得到高精度的检测结果,在不同层次的 feature maps 上去 predictobject、box offsets,同时,还得到不同aspect ratio
的 predictions。本文的这些改进设计,能够在当输入分辨率较低的图像时,保证检测的精度。同时,这个整体 end-to-end 的设计,训练也变得简单。在检测速度、检测精度之间取得较好的trade-off。
本文提出的模型(model)在不同的数据集上,如PASCAL VOC、MS COCO、ILSVRC,
都进行了测试。在检测时间(timing)、检测精度(accuracy)上,均与目前物体检测领域 state-of-art 的检测方法进行了比较。

使用VGG19作为预训练网络同时评测.............................
YOLO-V2
此篇文章:YOLO v2之总结篇(linux+windows)
此篇文章:YOLO v1之总结篇(linux+windows)
为提高物体定位精准性和召回率,YOLO作者提出了YOLO9000。不管是速度还是精度都超过了SSD300,和YOLOv1相比,确实有很大的性能的提升。
提高训练图像的分辨率,引入了faster rcnn中anchor box的思想,对各网络结构及各层的设计进行了改进,输出层使用卷积层替代YOLO的全连接层,联合使用coco物体检测标注数据和imagenet物体分类标注数据训练物体检测模型。相比YOLO , YOLO9000在识别种类、精度、速度、和定位准确性等方面都有大大提升。
跑一遍代码
使用YOLO训练自己的物体识别模型也非常方便,只需要将配置文件中的20类,更改为自己要识别的物体种类个数即可。
训练时,建议使用YOLO提供的检测模型(使用VOC 20类标注物体训练得到)去除最后的全连接层初始化网络。
YOLO作者开源代码请见darknet,Windows版可以参考windarknet,
支持Visual Studio编译。
- YOLO: Unified, Real-Time Object Detection
- YOLO9000: Better, Faster, Stronger
- Rich feature hierarchies for accurate object
detection and semantic segmentation - Fast R-CNN
- Towards Real-Time Object Detection with
Region Proposal Networks - darknet
CNN结构:用于检测的CNN结构进化-一站式方法的更多相关文章
- CNN结构:用于检测的CNN结构进化-分离式方法
前言: 原文链接:基于CNN的目标检测发展过程 文章有大量修改,如有不适,请移步原文. 参考文章:图像的全局特征--用于目标检测 目标的检测和定位中一个很困难的问题是,如何从数以万计的候选 ...
- CNN结构:用于检测的CNN结构进化-结合式方法
原文链接:何恺明团队提出 Focal Loss,目标检测精度高达39.1AP,打破现有记录 呀 加入Facebook的何凯明继续优化检测CNN网络,arXiv 上发现了何恺明所在 FAIR 团 ...
- 使用Dlib来运行基于CNN的人脸检测
检测结果如下 这个示例程序需要使用较大的内存,请保证内存足够.本程序运行速度比较慢,远不及OpenCV中的人脸检测. 注释中提到的几个文件下载地址如下 http://dlib.net/face_det ...
- 【神经网络与深度学习】【计算机视觉】RCNN- 将CNN引入目标检测的开山之作
转自:https://zhuanlan.zhihu.com/p/23006190?refer=xiaoleimlnote 前面一直在写传统机器学习.从本篇开始写一写 深度学习的内容. 可能需要一定的神 ...
- 内核中用于数据接收的结构体struct msghdr(转)
内核中用于数据接收的结构体struct msghdr(转) 我们从一个实际的数据包发送的例子入手,来看看其发送的具体流程,以及过程中涉及到的相关数据结构.在我们的虚拟机上发送icmp回显请求包,pin ...
- RCNN (Regions with CNN) 目标物检测 Fast RCNN的基础
Abstract: 贡献主要有两点1:可以将卷积神经网络应用region proposal的策略,自底下上训练可以用来定位目标物和图像分割 2:当标注数据是比较稀疏的时候,在有监督的数据集上训练之后到 ...
- Atitit.各种 数据类型 ( 树形结构,表形数据 ) 的结构与存储数据库 attilax 总结
Atitit.各种 数据类型 ( 树形结构,表形数据 ) 的结构与存储数据库 attilax 总结 1. 数据结构( 树形结构,表形数据,对象结构 ) 1 2. 编程语言中对应的数据结构 jav ...
- go的基结构体如何使用派生结构体的方法
将派生类的方法声明为接口嵌入到基结构体中,派生结构体声明该接口为自身.
- 十八、dbms_repair(用于检测,修复在表和索引上的损坏数据块)
1.概述 作用:用于检测,修复在表和索引上的损坏数据块. 2.包的组成 1).admin_tables语法:dbms_repair.admin_tables(table_name in varchar ...
随机推荐
- 学习Spring框架等技术的方向、方法和动机
学习Spring框架最早学习Spring框架是在大二的时候,当时看了几本书,看了一些视频,主要是传智播客的.更多的,还是写代码,单独写Spring的,也有与Struts和Hibernate等框架整合的 ...
- 洛谷P1055 ISBN号码【字符数组处理】
题目描述 每一本正式出版的图书都有一个ISBN号码与之对应,ISBN码包括 99 位数字. 11 位识别码和 33 位分隔符,其规定格式如x-xxx-xxxxx-x,其中符号-就是分隔符(键盘上的减号 ...
- Django——9 博客小案例的实现
Django 博客小案例的实现 主要实现博客的增删改查功能 主页index.html --> 展示添加博客和博客列表的文字,实现页面跳转 添加页add.html --> 输入文章标 ...
- win7安装gmpy2
1.下载地址:https://pypi.python.org/pypi/gmpy2 2.安装python和pip python 安装 下载: https://www.python.org/getit/ ...
- noip模拟赛 Chtholly Nota Seniorious
题目背景 大样例下发链接: https://pan.baidu.com/s/1nuVpRS1 密码: sfxg こんなにも.たくさんの幸せをあの人に分けてもらった だから.きっと 今の.私は 谁が何と ...
- class类加载机制
1.类的加载过程 a.加载-链接-初始化-使用-卸载 加载: 查找并加载类的二进制数据 链接: 验证类的正确性,为类的静态变量分配内存,并将其初始化为默认值,把类的符号引用转换为直接引用. 初始化: ...
- 如何拿CSDN博客上的原图
比如带水印的地址: http://img.blog.csdn.net/20140408122234546?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdT ...
- 实现MVC.NET 5的国际化
实现国际化有三种做法: 创建资源文件. 每种语言设置一套单独的View. 1 + 2. 通常而言,第一种方法的可维护性是最高的.因为随着项目的规模的扩大,为每种语言设置一套单独的View,前期的工作量 ...
- Codeforces Round #305 (Div. 2) D题 (线段树+RMQ)
D. Mike and Feet time limit per test 1 second memory limit per test 256 megabytes input standard inp ...
- curses-键盘编码-openssl加解密【转】
本文转载自;https://zhuanlan.zhihu.com/p/26164115 1.1 键盘编码 按键过程:当用户按下某个键时, 1.键盘会检测到这个动作,并通过键盘控制器把扫描码(scan ...