图解UNIX的I/O模型
一、简述
UNIX系统将所有的外部设备都看作一个文件来看待,所有打开的文件都通过文件描述符来引用。文件描述符是一个非负整数,它指向内核中的一个结构体。当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符。而对于一个socket的读写也会有相应的文件描述符,称为socketfd(socket描述符)。
在UNIX系统中,I/O输入操作(例如标准输入或者套接字的输入)通常包含以下两个不同的阶段:
- 等待数据准备好
- 从内核向进程复制数据
例如对于套接字的输入,第一步是等待数据从网络中到达,当所等待的数据到达时,数据被复制到内核中的缓冲区。第二步则是把数据从内核缓冲区复制到应用进程的缓冲区。
根据在这两个不同阶段处理的不同,可以将I/O模型划分为以下五种类型:
- 阻塞式I/O模型
- 非阻塞式I/O模型
- I/O复用
- 信号驱动式I/O
- 异步I/O
二、I/O模型
为简单起见,我们以UDP套接字中的recvfrom函数作为系统调用来说明I/O模型。recvfrom函数类似于标准的read函数,它的作用是从指定的套接字中读取数据报。recvfrom会从应用进程空间运行切换到内核空间中运行,一段时间后会再切换回来。有关recvfrom函数的介绍,可以参考本文的参考资料3。
2.1 阻塞式I/O模型
阻塞式I/O模型可以说是最简单的I/O模型。
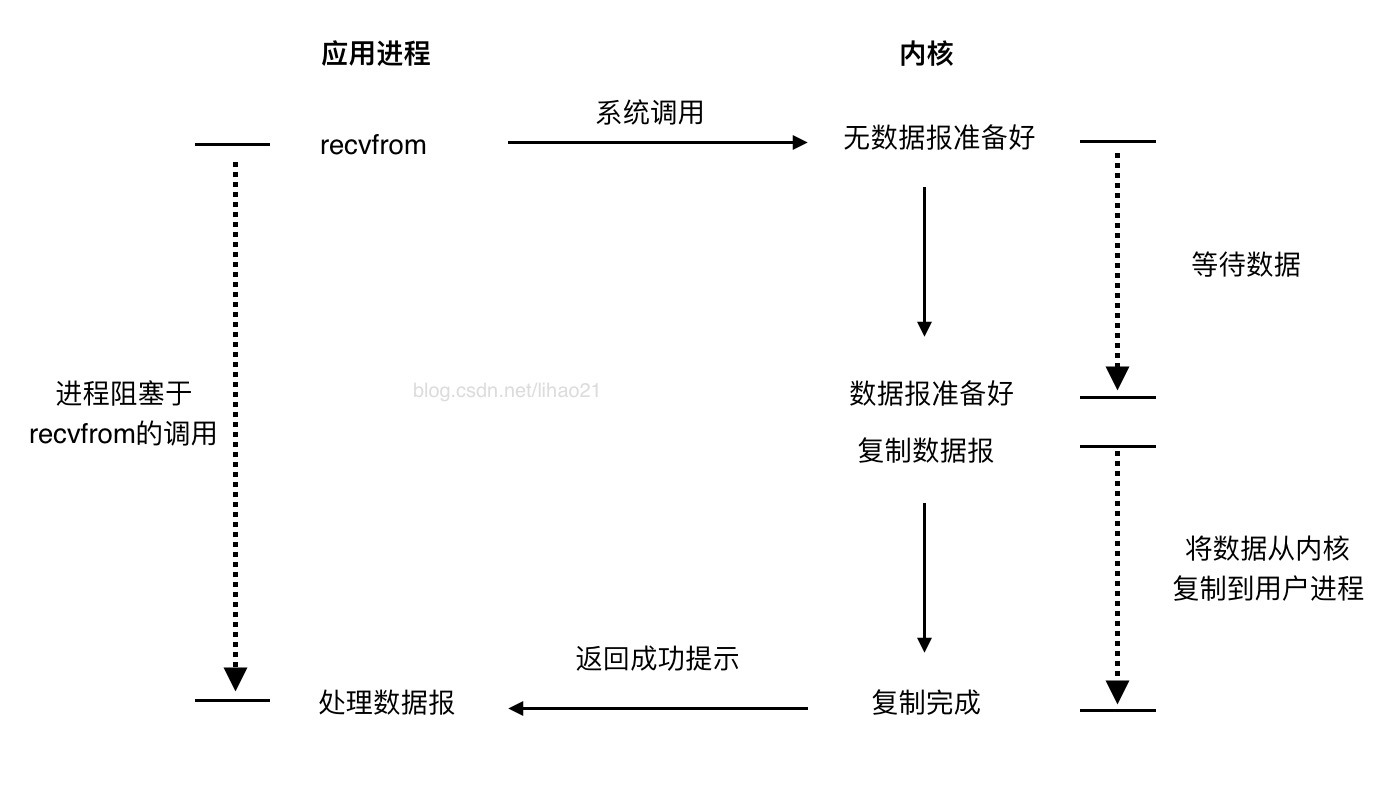
图1:阻塞式I/O模型
图1是阻塞式I/O模型的示意图,阅读此图须注意箭头的方向,沿着剪头方向顺时针阅读。
图1中,应用进程调用recvfrom,然后切换到内核空间中运行,直到数据报到达且被复制到应用进程缓冲区中才返回。我们说进程从调用recvfrom开始到它返回的整段时间内是被阻塞的。recvfrom成功返回后,应用进程开始处理数据报。
2.2 非阻塞式I/O模型
进程把一个套接字设置为非阻塞是指,在等待I/O数据时,进程并不阻塞,如果数据还没准备好,则直接返回一个错误。
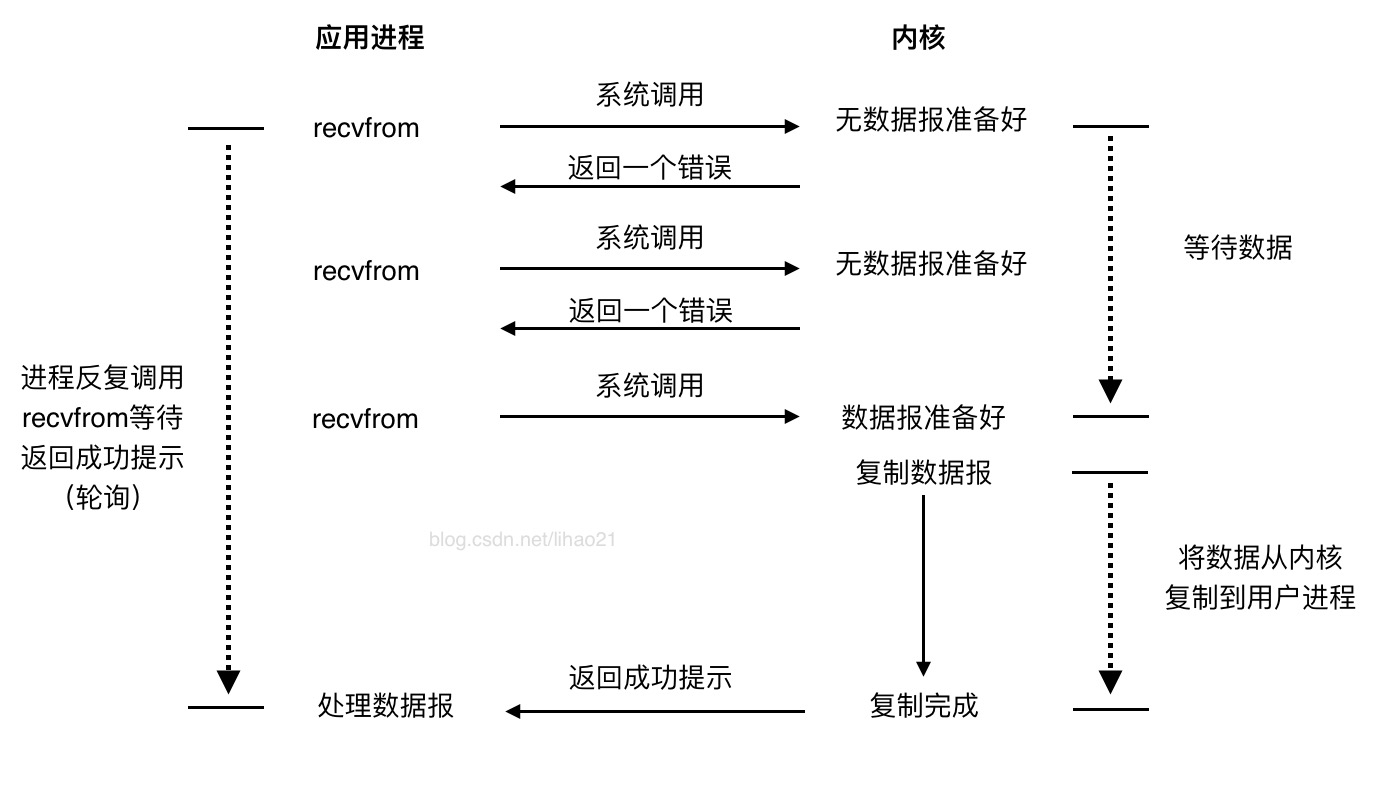
图2:非阻塞式I/O模型
图2是非阻塞I/O模型的示图。
在前两次调用recvfrom时由于数据报没准备好,因此内核马上返回一个系统调用错误。第3次调用recvfrom时,数据报已准备好,数据报被复制到应用进程的缓冲区,接着recvfrom成功返回。
当一个应用进程像这样不断对一个非阻塞描述符循环调用recvfrom时,我们称之为轮询。应用进程会持续轮询内核,以确定某个操作是否就绪。轮询操作会消耗大量的CPU时间。
2.3 I/O复用模型
我们常用的select和poll函数使用了I/O复用模型。我们以select为例说明I/O复用模型的特点。
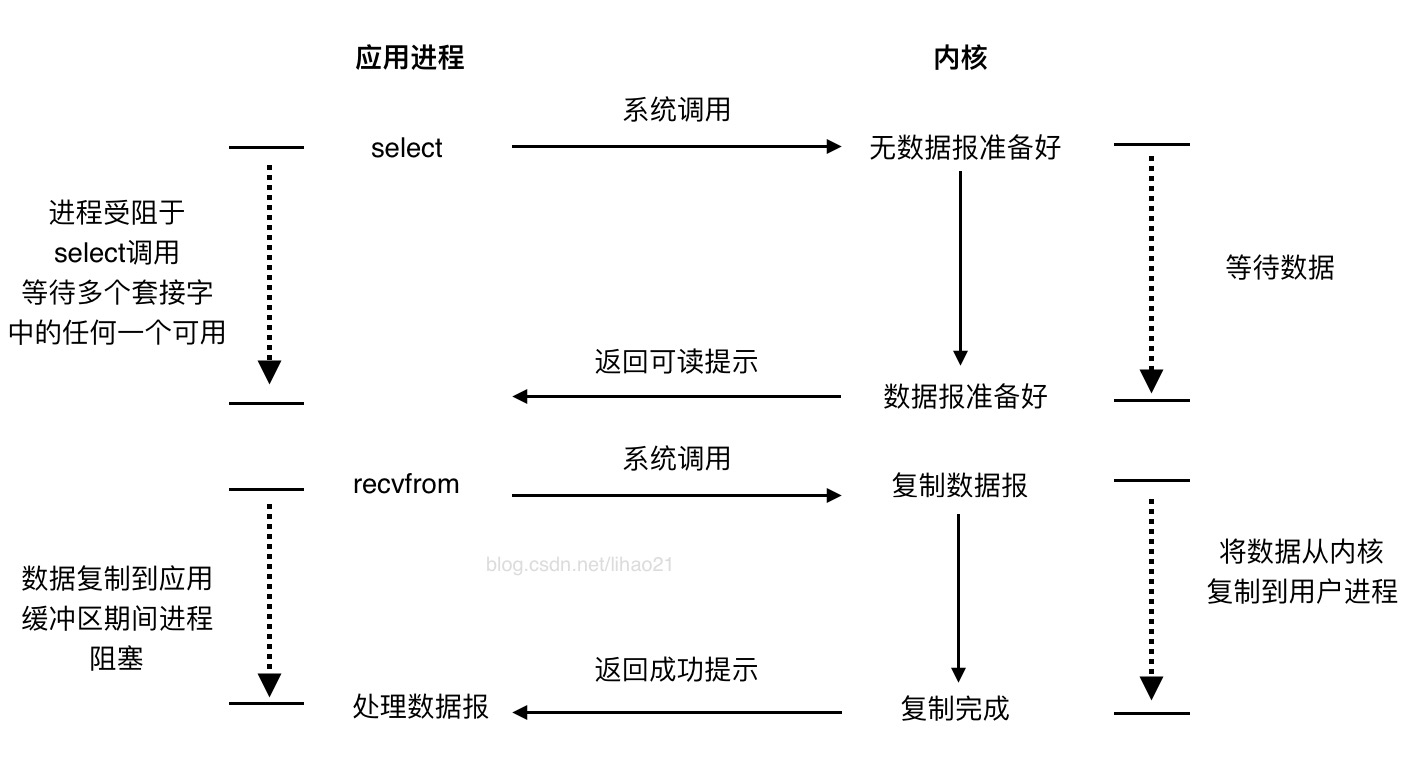
图3:I/O复用模型
图3是I/O复用模型的示意图。
当我们调用select函数时,将会阻塞于此函数,等待数据报套接字变为可读。当等待的多个套接字中的其中一个或者多个变得可读时,我们调用recvfrom把数据报复制到应用进程缓冲区。
比较图3与图1,I/O复用模型好像没什么优势,而且应用进程为了获取数据报,还得增加了一个额外的select系统调用。不过I/O复用模型的优势在于可以同时等待多个(而不只是一个)套接字描述符就绪。
2.4 信号驱动式I/O模型
信号驱动I/O模型用得比较少,图4是该模型的示意图。
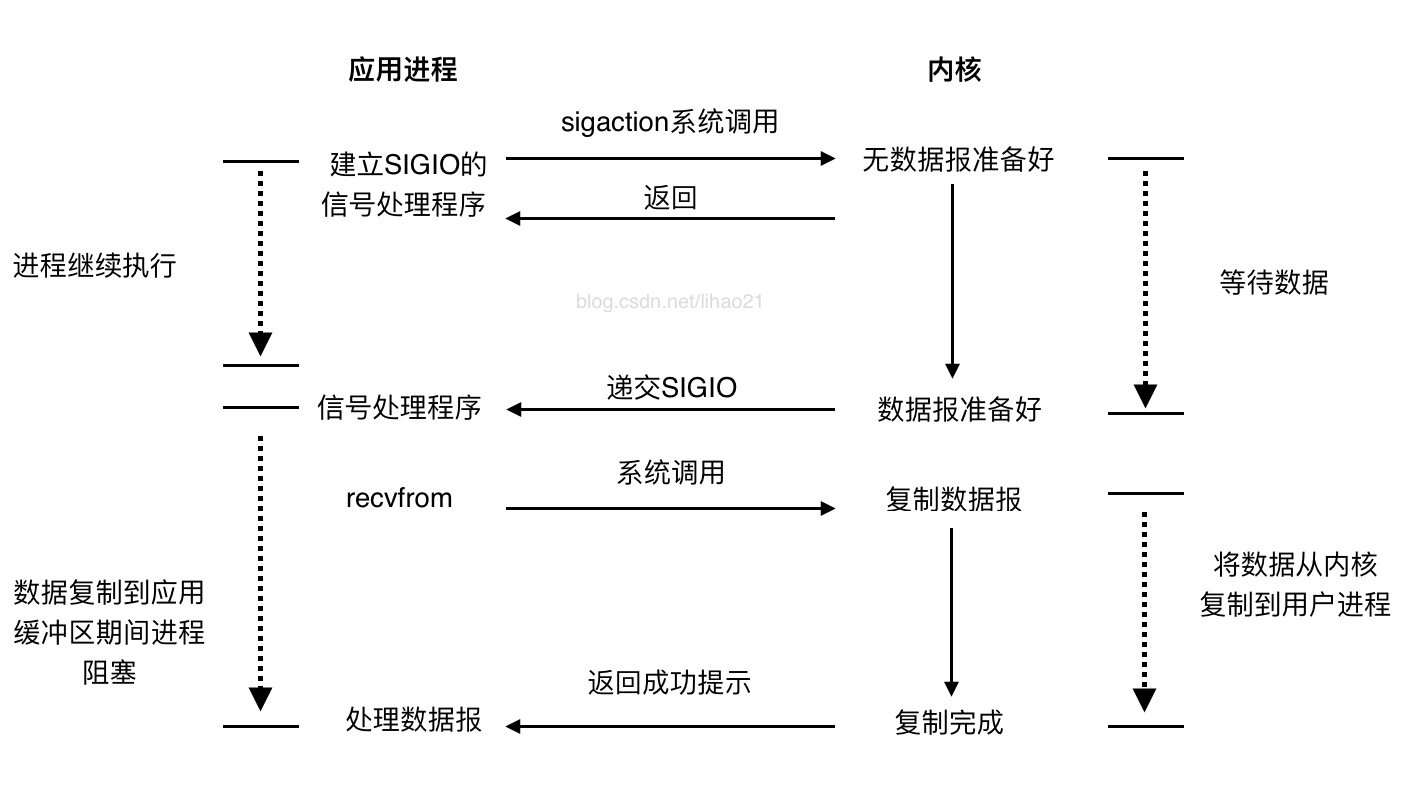
图4:信号驱动式I/O模型
为了使用该I/O模型,需要开启套接字的信号驱动I/O功能,并通过sigaction系统调用安装一个信号处理函数。sigaction函数立即返回,我们的进程继续工作,即进程没有被阻塞。当数据报准备好时,内核会为该进程产生一个SIGIO信号,这样我们可以在信号处理函数中调用recvfrom读取数据报,也可以在主循环中读取数据报。无论如何处理SIGIO信号,这种模型的优势在于等待数据报到达期间不被阻塞。
2.5 异步I/O模型
异步I/O模型的工作机制是,启动某个操作,并让内核在整个操作(包括等待数据和将数据从内核复制到用户空间)完成后通知应用进程。
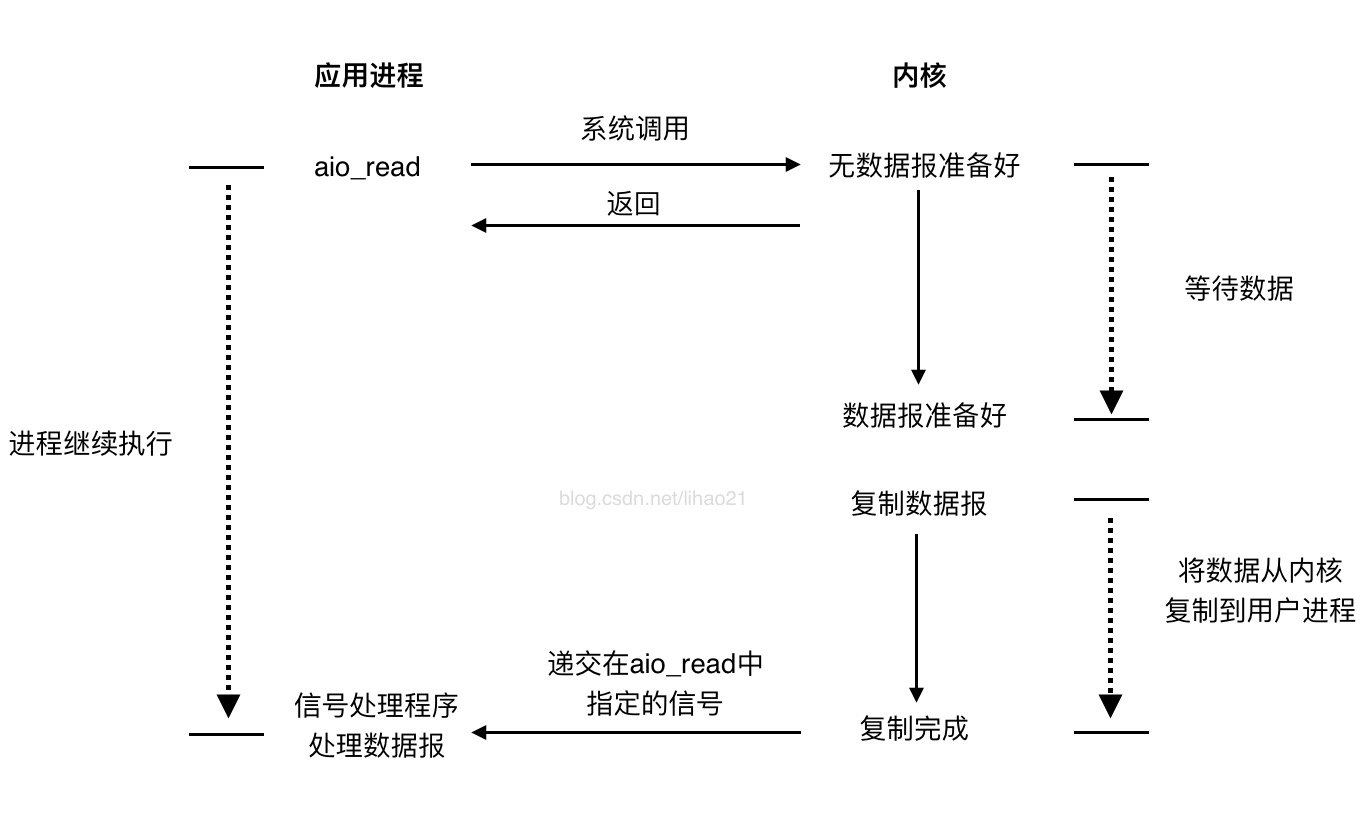
图5:异步I/O模型
图5是异步I/O模型的示意图。我们调用aio_read函数,告诉内核,当整个I/O操作完成后通知我们。该系统调用立即返回,而在等待I/O完成期间,应用进程不会被阻塞。当I/O完成(包括数据从内样复制到用户进程)后,内核会产生一个信号通知应用进程,应用进程对数据报进行处理。
异步I/O模型与信号驱动式I/O的区别在于:信号驱动式I/O在数据报准备好时就通知应用进程,应用进程还需要将数据报从内核复制到用户进程缓冲区;而异步I/O模型则是整个操作完成才通知应用进程,应用进程在整个操作期间都不会被阻塞。
2.6 各种I/O模型的比较
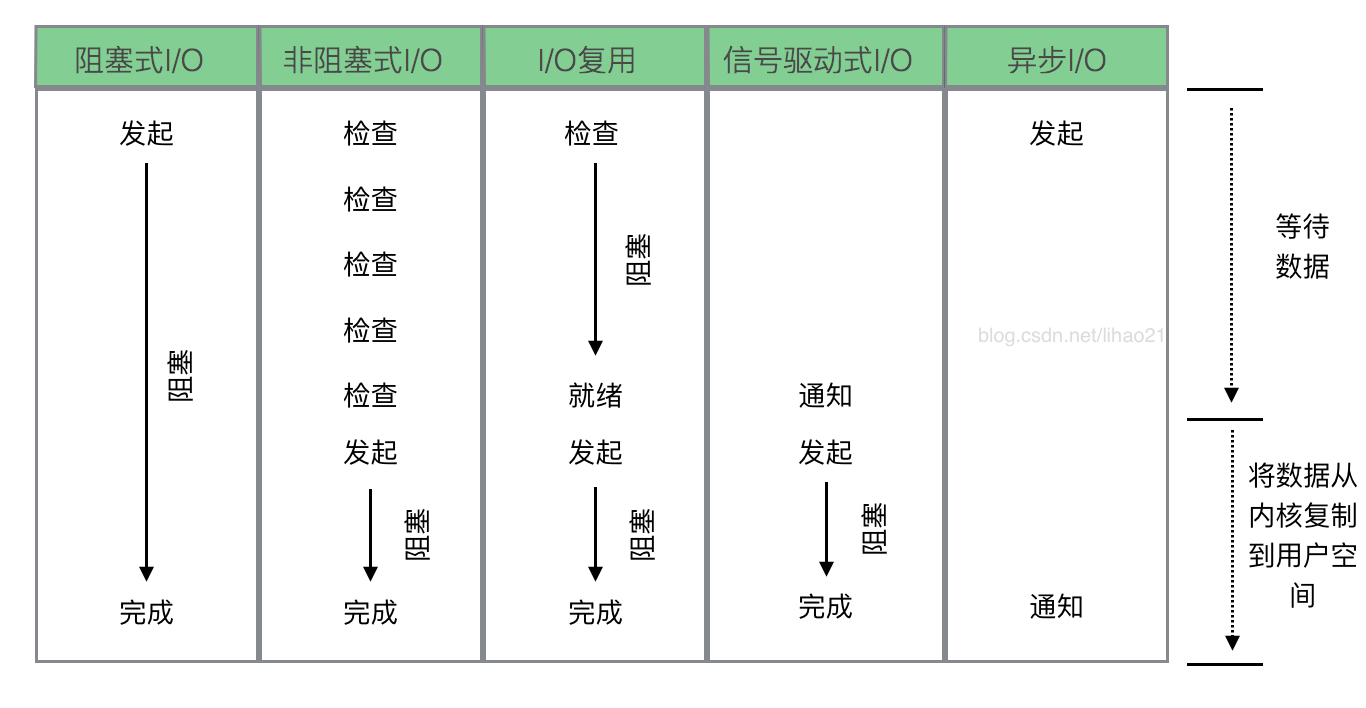
图6:5种I/O模型的比较
从图6可以看到,前四种I/O模型的主要区别在于第一个阶段,它们的第二个阶段是一样的:在数据从内核复制到应用进程的缓冲区期间,进程会被阻塞于recvfrom系统调用。
而异步I/O模型则是整个操作完成内核才通知应用进程。
三、同步I/O和异步I/O
POSIX标准将同步I/O和异步I/O定义为:
同步I/O操作:导致请求进程阻塞,直到I/O操作完成。
异步I/O操作:不导致请求进程阻塞。
根据上述两个定义,本文介绍的前面四种模型,包括阻塞式I/O,非阻塞式I/O,I/O复用和信号驱动式I/O模型都是同步I/O模型,因为其中真正的I/O操作(recvfrom)将阻塞进程。只有异步I/O模型才符合POSIX标准的异步I/O定义。
四、生活中的类比例子
以生活中钓鱼为例子(例子参考了参考资料2),来说明各种I/O模型的不同,例子中的等待鱼上钩对应于上文中的等待数据,拉竿操则作对应于上文的将数据从内核复制到用户空间。
有A,B,C,D,E五个人在钓鱼。
A使用了最古老的鱼竿,所以开始钓鱼后,就一直守着,直接鱼上钩了再拉竿;
B由于着急想知道有没鱼上钩,所以隔一会就看一次鱼竿看有没鱼上钩,直到看到鱼上钩后,再拉竿;
C同时使用了N支鱼竿来钩鱼,然后等着,只要有其中一支鱼竿有鱼上钩,就将对应的鱼竿拉起来;
D的鱼竿比较高级,当有鱼上钩后,会发出警报提示,所以D开始钓鱼后不用一直守着,一旦鱼竿发出警报,D再回来拉竿即可;
E为了更省事,直接雇个佣人给他钓鱼,当佣人钓起鱼后,再通知E去取鱼即可。
五、参考资料
- Unix网络编程,卷1:套接字联网API,第三版,W. Richard Stevens著
- http://blog.csdn.net/historyasamirror/article/details/5778378
- http://pubs.opengroup.org/onlinepubs/009695399/functions/recvfrom.html
图解UNIX的I/O模型的更多相关文章
- Netty源码分析一<序一Unix网络I/O模型简介>
Unix网络 I/O 模型 我们都知道,为了操作系统的安全性考虑,进程是无法直接操作I/O设备的,其必须通过系统调用请求内核来协助完成I/O动作,而内核会为每个I/O设备维护一个buffer.以下 ...
- Unix/Linux 网络 IO 模型简介
概述 Linux内核将所有外部设备都看做一个文件来操作.对该文件的读写操作会调用内核提供的系统命令, 返回一个fd(file descriptor)文件描述符.而对一个socket的读写也有相应的描述 ...
- Unix的I/O模型
对于一次I/O操作(以read为例),数据首先被拷贝到内核的某个缓冲区,然后再从内核缓冲区拷贝到应用进程缓冲区. 因此,一次I/O操作通常包含两个阶段: (1) 等待数据准备好 (2) 从内核向进程复 ...
- UNIX网络编程-Select模型学习
1.相关接口介绍 1.1 select ---------------------------------------------------------------------- #include ...
- UNIX网络编程-Poll模型学习
1.相关接口介绍 1.1 poll ---------------------------------------------------------------------- #include &l ...
- 浅谈Unix I/O模型
关于I/O模型的文章比较多,参考多篇后理解上仍然不太满意,终需自己整理一次,也是编写高吞吐量高性能网络接口模块的基础.这里所说的主要针对网络I/O,近几年面对越来越大的用户请求量,如何优化这些步骤直接 ...
- Unix下5种I/O模型
Unix下I/O模型主要分为5种: (1)阻塞式I/O (2)非阻塞式I/O (3)I/O复用(select和poll) (4)信号驱动式I/O (5)异步I/O 1.阻塞式I/O模型 unix基本的 ...
- UNIX 5种I/O模型
Unix 5 I/O模型 I/O操作分为两步: (1)先将数据从 存储介质 (磁盘或者网络等)拷贝到 内核缓冲区,此时称为数据准备好,可以被用户读取. (2)由用户应用程序拷贝内核缓冲区数据 到用户缓 ...
- Java I/O 模型的演进
什么是同步?什么是异步?阻塞和非阻塞又有什么区别?本文先从 Unix 的 I/O 模型讲起,介绍了5种常见的 I/O 模型.而后再引出 Java 的 I/O 模型的演进过程,并用实例说明如何选择合适的 ...
随机推荐
- ctags 寻找方法定义处
ctags这个是vim的一个插件,它可以用来生成一个检索文件,里面保存有一些索引信息.例如,一些类跟方法.变量等的定义位置当我们对一个路径执行ctags -R的时候,就会自动生成一个ctags,然后我 ...
- android 图片特效处理之光晕效果
这篇将讲到图片特效处理的图片光晕效果.跟前面一样是对像素点进行处理,本篇实现的思路可参见android图像处理系列之九--图片特效处理之二-模糊效果和android图像处理系列之十三--图片特效处理之 ...
- Android官方文档翻译——Fragment生命周期
网上有的博客写得太乱 不如自己翻译官方文档 Lifecycle 生命周期 Though a Fragment's lifecycle is tied to its owning activity, i ...
- es6 ----- export 和 import
ES6 模块不是对象,而是通过export命令显式指定输出的代码,再通过import命令输入. 下面列出几种import和export的基本语法: 第一种方式: 在lib.js文件中, 使用 expo ...
- JDK版本切换批处理脚本
我们经常在开发是遇到jdk版本切换的问题 1.手动去修改JAVA_HOME环境变量,将变量的值指向对应的JDK版本的安装目录即可. 2.通过编写批处理脚本来根据选择的JDK版本动态修改JAVA_HOM ...
- Linux 交换分区swap
Linux 交换分区swap 一.创建和启用swap交换区 如果你的服务器的总是报告内存不足,并且时常因为内存不足而引发服务被强制kill的话,在不增加物理内存的情况下,启用swap交换区作为虚拟内存 ...
- 控制面板项 .cpl 文件说明
控制面板项 .cpl 文件说明 appwiz.cpl 程序和功能.卸载或更改程序 bthprops.cpl 蓝牙控制面板 desk.cpl ...
- js38---门面模式
(function(){ //门面 function addEvebtFacade(el,type,fn){ if(window.addEventListener){ //使用与火狐浏览器 alert ...
- Flume的核心概念
Event:一条数据 Client:生产数据,运行在一个独立的线程. Agent (1)Sources.Channels.Sinks (2)其他组件:Interceptors.Channel S ...
- Eclipse&STS常用小技巧
开发是经常用到的代码可进行快捷提示,比如mian alt+/就提示出了main方法是不是很方便,为什么就能提示出来呢? 马上来了: 在你使用的java开发工具中点击Window--->Prefe ...