一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助。
1、Scrapy爬虫框架
Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且使用起来非常的方便。它可以应用在数据采集、数据挖掘、网络异常用户检测、存储数据等方面。
Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下图所示。
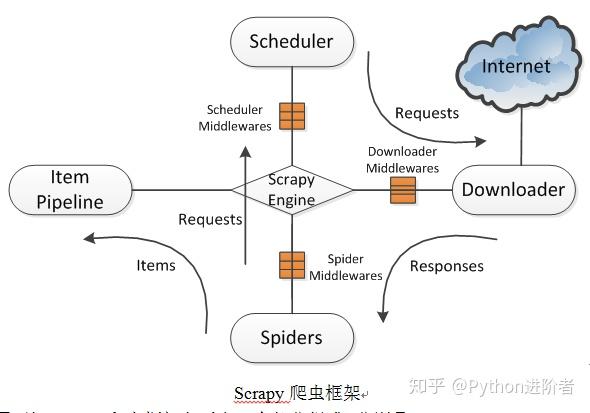 Scrapy爬虫框架
Scrapy爬虫框架
2、由上图可知Scrapy爬虫框架主要由5个部分组成,分别是:Scrapy Engine(Scrapy引擎),Scheduler(调度器),Downloader(下载器),Spiders(蜘蛛),Item Pipeline(项目管道)。爬取过程是Scrapy引擎发送请求,之后调度器把初始URL交给下载器,然后下载器向服务器发送服务请求,得到响应后将下载的网页内容交与蜘蛛来处理,尔后蜘蛛会对网页进行详细的解析。蜘蛛分析的结果有两种:一种是得到新的URL,之后再次请求调度器,开始进行新一轮的爬取,不断的重复上述过程;另一种是得到所需的数据,之后会转交给项目管道继续处理。项目管道负责数据的清洗、验证、过滤、去重和存储等后期处理,最后由Pipeline输出到文件中,或者存入数据库等。
3、这五大组件及其中间件的功能如下:
1) Scrapy引擎:控制整个系统的数据处理流程,触发事务处理流程,负责串联各个模块
2) Scheduler(调度器):维护待爬取的URL队列,当接受引擎发送的请求时,会从待爬取的URL队列中取出下一个URL返回给调度器。
3) Downloader(下载器):向该网络服务器发送下载页面的请求,用于下载网页内容,并将网页内容交与蜘蛛去处理。
4) Spiders(蜘蛛):制定要爬取的网站地址,选择所需数据内容,定义域名过滤规则和网页的解析规则等。
5) Item Pipeline(项目管道):处理由蜘蛛从网页中抽取的数据,主要任务是清洗、验证、过滤、去重和存储数据等。
6) 中间件(Middlewares):中间件是处于Scrapy引擎和Scheduler,Downloader,Spiders之间的构件,主要是处理它们之间的请求及响应。
Scrapy爬虫框架可以很方便的完成网上数据的采集工作,简单轻巧,使用起来非常方便。
4、 基于Scrapy的网络爬虫设计与实现
在了解Scrapy爬虫原理及框架的基础上,本节简要介绍Scrapy爬虫框架的数据采集过程。
4.1 建立爬虫项目文件
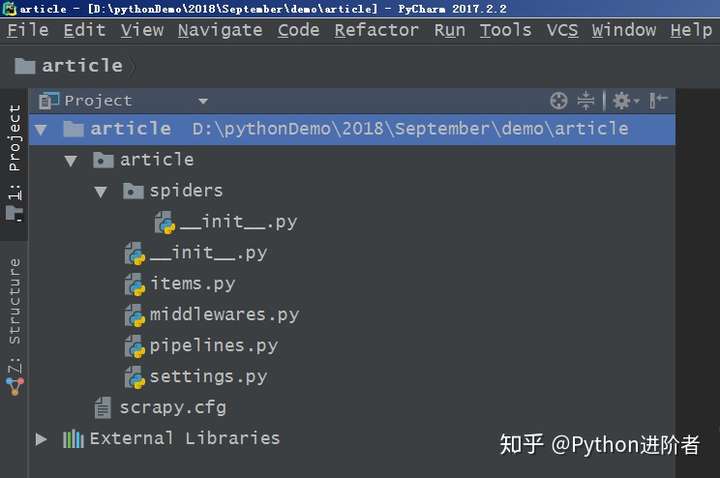
基于scrapy爬虫框架,只需在命令行中输入“scrapy startproject article”命令,之后一个名为article的爬虫项目将自动创建。首先进入到article文件夹下,输入命令“cd article”,之后通过“dir”查看目录,也可以通过“tree /f”生成文件目录的树形结构,如下图所示,可以很清晰的看到Scrapy创建命令生成的文件。

爬虫项目目录结构
顶层的article文件夹是项目名,第二层中包含的是一个与项目名同名的文件夹article和一个文件scrapy.cfg,这个与项目同名的文件夹article是一个模块,所有的项目代码都在这个模块内添加,而scrapy.cfg文件是整个Scrapy项目的配置文件。第三层中有5个文件和一个文件夹,其中__init__.py是个空文件,作用是将其上级目录变成一个模块;items.py是定义储对象的文件,决定爬取哪些项目;middlewares.py文件是中间件,一般不用进行修改,主要负责相关组件之间的请求与响应;pipelines.py是管道文件,决定爬取后的数据如何进行处理和存储;settings.py是项目的设置文件,设置项目管道数据的处理方法、爬虫频率、表名等;spiders文件夹中放置的是爬虫主体文件(用于实现爬虫逻辑)和一个__init__.py空文件。
4.2 之后开始进行网页结构与数据分析、修改Items.py文件、编写hangyunSpider.py文件、修改pipelines.py文件、修改settings.py文件,这些步骤的具体操作后期会文章专门展开,在此不再赘述。
4.3 执行爬虫程序
修改上述四个文件之后,在Windows命令符窗口中输入cmd 命令进入到爬虫所在的路径,并执行“scrapy crawl article”命令,这样就可以运行爬虫程序了,最后保存数据到本地磁盘上。
5、 结束语
随着互联网信息的与日俱增,利用网络爬虫工具来获取所需信息必有用武之地。使用开源的Scrapy爬虫框架,不仅可以实现对web上信息的高效、准确、自动的获取,还利于研究人员对采集到的数据进行后续的挖掘分析。

一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程的更多相关文章
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- 一篇文章带你用Python网络爬虫实现网易云音乐歌词抓取
前几天小编给大家分享了数据可视化分析,在文尾提及了网易云音乐歌词爬取,今天小编给大家分享网易云音乐歌词爬取方法. 本文的总体思路如下: 找到正确的URL,获取源码: 利用bs4解析源码,获取歌曲名和歌 ...
- Scrapy网络爬虫框架的开发使用
1.安装 2.使用scrapy startproject project_name 命令创建scrapy项目 如图: 3.根据提示使用scrapy genspider spider_name dom ...
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- 一篇文章助你理解Python3中字符串编码问题
前几天给大家介绍了unicode编码和utf-8编码的理论知识,以及Python2中字符串编码问题,没来得及上车的小伙伴们可以戳这篇文章:浅谈unicode编码和utf-8编码的关系和一篇文章助你理解 ...
- Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2
Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2 1. 数据采集1 1.1. http lib1 1.2. HTML Parsers,1 1.3. 第8章 web爬取199 1 2 ...
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
原文地址http://blog.csdn.net/qy20115549/article/details/52203722 本文为原创博客,仅供技术学习使用.未经允许,禁止将其复制下来上传到百度文库等平 ...
- Java 网络爬虫获取网页源代码原理及实现
Java 网络爬虫获取网页源代码原理及实现 1.网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL ...
- Golang 网络爬虫框架gocolly/colly 四
Golang 网络爬虫框架gocolly/colly 四 爬虫靠演技,表演得越像浏览器,抓取数据越容易,这是我多年爬虫经验的感悟.回顾下个人的爬虫经历,共分三个阶段:第一阶段,09年左右开始接触爬虫, ...
随机推荐
- bzoj2150: 部落战争(匈牙利)
2150: 部落战争 题目:传送门 题解: 辣鸡数据..毁我AC率 先说做法,很容易就可以看出是二分图匹配的最小路径覆盖(可能是之前不久刚做过类似的题) 一开始还傻逼逼的去直接连边然后准备跑floyd ...
- Android Studio 修改注释模板中的${USER}变量以及修改默认的头部注释
引言 通常我们创建类文件都会自动生成一段头部注释. 有时候这不是我们想要的效果. 它默认是Created By XXX. 而我们要的是@author XXX. 而且这里面的XXX是系统的的用户名,不一 ...
- phpstorm 或 webstorm 设置打开多个项目,多个项目并存。
File -> settings -> Directories -> Add Content Root 中添加你当前的工程目录. 这样就可以节省内存了.之前用一个打开php项目,一个 ...
- nyoj--1036--非洲小孩(区间相交问题)
非洲小孩 时间限制:1000 ms | 内存限制:65535 KB 难度:2 描述 家住非洲的小孩,都很黑.为什么呢? 第一,他们地处热带,太阳辐射严重. 第二,他们不经常洗澡.(常年缺水,怎么洗 ...
- WinForm关于listview的用法介绍
public Form1() { InitializeComponent(); //控件的行为 listView1.Bounds = , ), , ));//相对位置 listView1.View = ...
- (转载)Mac系统下利用ADB命令连接android手机并进行文件操作
Mac系统下利用ADB命令连接android手机并进行文件操作 标签: Mac adb android 2016-03-14 10:09 5470人阅读 评论(1) 收藏 举报 分类: Androi ...
- ccs元素分类 gcelaor
ccs元素的分类与特点 内联元素特点: 1.和其他元素都在一行上: 2.元素的高度.宽度及顶部和底部边距不可设置: 3.元素的宽度就是它包含的文字或图片的宽度,不可改变. inline-block 元 ...
- 虚拟机创建后该如何获取IP地址并访问互联网实用教程
之前在做项目的时候主机IP地址.网关.DNS.子网掩码等都是公司或者对方直接给提供的,但是如果我们自己想搭建一台虚拟机或者一台集群的话,手头又没有IP地址,该肿么办呢? 白慌,这里介绍一个小技巧, ...
- vue 事件上加阻止冒泡 阻止默认事件
重点 vue事件修饰符 <!-- 阻止单击事件冒泡 --> <a v-on:click.stop="doThis"></a> <!-- 提 ...
- 【BZOJ4444】国旗计划 - 决策单调性
Description A国正在开展一项伟大的计划——国旗计划.这项计划的内容是边防战士手举国旗环绕边境线奔袭一圈.这项计划需要多名边防战士以接力的形式共同完成,为此,国土安全局已经挑选了N名优秀的边 ...