Classification and Representation
Classification
To attempt classification, one method is to use linear regression and map all predictions greater than 0.5 as a 1 and all less than 0.5 as a 0. However, this method doesn't work well because classification is not actually a linear function.
The classification problem is just like the regression problem, except that the values we now want to predict take on only a small number of discrete values. For now, we will focus on the binary classification problem in which y can take on only two values, 0 and 1. (Most of what we say here will also generalize to the multiple-class case.) For instance, if we are trying to build a spam classifier for email, then 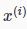 may be some features of a piece of email, and y may be 1 if it is a piece of spam mail, and 0 otherwise. Hence, y∈{0,1}. 0 is also called the negative class, and 1 the positive class, and they are sometimes also denoted by the symbols “-” and “+.” Given x(i), the corresponding
may be some features of a piece of email, and y may be 1 if it is a piece of spam mail, and 0 otherwise. Hence, y∈{0,1}. 0 is also called the negative class, and 1 the positive class, and they are sometimes also denoted by the symbols “-” and “+.” Given x(i), the corresponding  is also called the label for the training example.
is also called the label for the training example.
Hypothesis Representation
We could approach the classification problem ignoring the fact that y is discrete-valued, and use our old linear regression algorithm to try to predict y given x. However, it is easy to construct examples where this method performs very poorly. Intuitively, it also doesn’t make sense for hθ(x) to take values larger than 1 or smaller than 0 when we know that y ∈ {0, 1}. To fix this, let’s change the form for our hypotheses hθ(x) to satisfy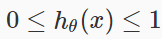 . This is accomplished by plugging
. This is accomplished by plugging  into the Logistic Function.
into the Logistic Function.
Our new form uses the "Sigmoid Function," also called the "Logistic Function":

The following image shows us what the sigmoid function looks like:

The function g(z), shown here, maps any real number to the (0, 1) interval, making it useful for transforming an arbitrary-valued function into a function better suited for classification.
hθ(x) will give us the probability that our output is 1. For example, hθ(x)=0.7 gives us a probability of 70% that our output is 1. Our probability that our prediction is 0 is just the complement of our probability that it is 1 (e.g. if probability that it is 1 is 70%, then the probability that it is 0 is 30%).
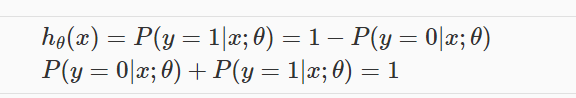
Decision Boundary
In order to get our discrete 0 or 1 classification, we can translate the output of the hypothesis function as follows:

The way our logistic function g behaves is that when its input is greater than or equal to zero, its output is greater than or equal to 0.5:

Remember.

So if our input to g is  , then that means:
, then that means:

From these statements we can now say:

The decision boundary is the line that separates the area where y = 0 and where y = 1. It is created by our hypothesis function.
Example:


Multiclass Classification: One-vs-all
Now we will approach the classification of data when we have more than two categories. Instead of y = {0,1} we will expand our definition so that y = {0,1...n}.
Since y = {0,1...n}, we divide our problem into n+1 (+1 because the index starts at 0) binary classification problems; in each one, we predict the probability that 'y' is a member of one of our classes.

The following image shows how one could classify 3 classes:We are basically choosing one class and then lumping all the others into a single second class. We do this repeatedly, applying binary logistic regression to each case, and then use the hypothesis that returned the highest value as our prediction.

To summarize:

Classification and Representation的更多相关文章
- 浅谈Logistic回归及过拟合
判断学习速率是否合适?每步都下降即可.这篇先不整理吧... 这节学习的是逻辑回归(Logistic Regression),也算进入了比较正统的机器学习算法.啥叫正统呢?我概念里面机器学习算法一般是这 ...
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
原文:http://blog.csdn.net/abcjennifer/article/details/7716281 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Machine Learning - 第3周(Logistic Regression、Regularization)
Logistic regression is a method for classifying data into discrete outcomes. For example, we might u ...
- 《Machine Learning》系列学习笔记之第三周
第三周 第一部分 Classification and Representation Classification 为了尝试分类,一种方法是使用线性回归,并将大于0.5的所有预测映射为1,所有小于0. ...
- Andrew Ng机器学习课程笔记--week3(逻辑回归&正则化参数)
Logistic Regression 一.内容概要 Classification and Representation Classification Hypothesis Representatio ...
- ICLR 2014 International Conference on Learning Representations深度学习论文papers
ICLR 2014 International Conference on Learning Representations Apr 14 - 16, 2014, Banff, Canada Work ...
- Course Machine Learning Note
Machine Learning Note Introduction Introduction What is Machine Learning? Two definitions of Machine ...
- Survey of single-target visual tracking methods based on online learning 翻译
基于在线学习的单目标跟踪算法调研 摘要 视觉跟踪在计算机视觉和机器人学领域是一个流行和有挑战的话题.由于多种场景下出现的目标外貌和复杂环境变量的改变,先进的跟踪框架就有必要采用在线学习的原理.本论文简 ...
- 《Learning Structured Representation for Text Classification via Reinforcement Learning》论文翻译.md
摘要 表征学习是自然语言处理中的一个基本问题.本文研究了如何学习文本分类的结构化表示.与大多数既不使用结构又依赖于预先指定结构的现有表示模型不同,我们提出了一种强化学习(RL)方法,通过自动覆盖优化结 ...
随机推荐
- 商业模式(二):P2P网贷平台,利差和服务费为主的金融玩法
2014~2015,先后在2家P2P平台工作过,还了解过其它若干武汉P2P平台. 结合自己的工作经历和理财经历,说几句~ 1.P2P网贷这种金融类的创业项目和经营风险,远高于制造业和服务业~ ...
- apache 使用 mod_fcgid.so模块时 配置指令
FcgidBusyScanInterval指令 说明:扫描繁忙超时进程的间隔 语法: FcgidBusyScanInterval seconds 默认:FcgidBusyScanInterval 12 ...
- Onsctl 配置ONS服务(10G)
Onsctl Onsctl这个命令是用来管理ONS(Oracle Notification Service)是OracleClustser实现FAN Event Push模型的基础. 在RAC环境下. ...
- Codeforces 441 B. Valera and Fruits
B. Valera and Fruits time limit per test 1 second memory limit per test 256 megabytes input standard ...
- Swift具体解释之三----------函数(你想知道的都在这里)
函数(你想知道的都在这里) 注:本文为作者自己总结.过于基础的就不再赘述 ,都是亲自測试的结果.如有错误或者遗漏的地方.欢迎指正.一起学习. 1. 函数的简单定义和调用 简单的无參函数就不再赘述 , ...
- .NET Entity Framework入门操作
Entity Framework是微软借鉴ORM思想开发自己的一个ORM框架. ORM就是将数据库表与实体对象(相当于三层中的Model类)相互映射的一种思想. 最大的优点就是非常方便的跨数据库平台. ...
- 一个小的考试系统 android 思路
一个小的考试系统 android 思路 假如有 100 组,每组有4个单选钮,设置超时检测确认后去测结果估分视图去切换,如果还有,就再显示下一组 所有结束就给个总结显示 有超时结束过程加上 提示正确选 ...
- js面向对象3-继承
一.了解继承 首先我们一起了解下js中继承,其实继承就是后辈继承前辈的属性和方法. 二.继承的方法 从父类继承属性和方法 这是对象冒充的方法,模仿java的继承方法.实现的原理是,通过改变父类的执行 ...
- 洛谷 P4779【模板】单源最短路径(标准版)
洛谷 P4779[模板]单源最短路径(标准版) 题目背景 2018 年 7 月 19 日,某位同学在 NOI Day 1 T1 归程 一题里非常熟练地使用了一个广为人知的算法求最短路. 然后呢? 10 ...
- PatentTips - Virtual machine management using processor state information
BACKGROUND OF THE INVENTION The invention generally relates to virtual machine management, and more ...