ElasticSearch:分析器
ElasticSearch入门 第七篇:分析器
这是ElasticSearch 2.4 版本系列的第七篇:
- ElasticSearch入门 第一篇:Windows下安装ElasticSearch
- ElasticSearch入门 第二篇:集群配置
- ElasticSearch入门 第三篇:索引
- ElasticSearch入门 第四篇:使用C#添加和更新文档
- ElasticSearch入门 第五篇:使用C#查询文档
- ElasticSearch入门 第六篇:复合数据类型——数组,对象和嵌套
- ElasticSearch入门 第七篇:分析器
- ElasticSearch入门 第八篇:存储
- ElasticSearch入门 第九篇:实现正则表达式查询的思路
在全文搜索(Fulltext Search)中,词(Term)是一个搜索单元,表示文本中的一个词,标记(Token)表示在文本字段中出现的词,由词的文本、在原始文本中的开始和结束偏移量、以及数据类型等组成。ElasticSearch 把文档数据写到倒排索引(Inverted Index)的结构中,倒排索引建立词(Term)和文档之间的映射,索引中的数据是面向词,而不是面向文档的。分析器(Analyzer)的作用就是分析(Analyse),用于把传入Lucene的文档数据转化为倒排索引,把文本处理成可被搜索的词。分析器由一个分词器(Tokenizer)和零个或多个标记过滤器(TokenFilter)组成,也可以包含零个或多个字符过滤器(Character Filter)。
在ElasticSearch引擎中,分析器的任务是分析(Analyze)文本数据,分析是分词,规范化文本的意思,其工作流程是:
- 首先,字符过滤器对分析(analyzed)文本进行过滤和处理,例如从原始文本中移除HTML标记,根据字符映射替换文本等,
- 过滤之后的文本被分词器接收,分词器把文本分割成标记流,也就是一个接一个的标记,
- 然后,标记过滤器对标记流进行过滤处理,例如,移除停用词,把词转换成其词干形式,把词转换成其同义词等,
- 最终,过滤之后的标记流被存储在倒排索引中;
- ElasticSearch引擎在收到用户的查询请求时,会使用分析器对查询条件进行分析,根据分析的结构,重新构造查询,以搜索倒排索引,完成全文搜索请求,
可见,分析器扮演的是处理索引数据和查询条件的重要角色。在2.4版本中,ElasticSearch 预定义了7个分析器,并且支持用户根据预定义的字符过滤器,分词器和标记过滤器创建自定义的分析器,以满足用户多样性的文本分析需求。
用户在创建索引时配置索引的分析,通过向ElasticSearch发送请求,在请求body的settings 配置节中设置索引的分析器,例如,为索引配置默认的分析器:

- "settings":{
- "index":{
- "analysis":{
- "analyzer":{
- "default":{
- "type":"standard"
- ,"stopwords":"_english_"
- }
- }
- }
- }
- }
一,字符过滤器(Char Filter)
字符过滤器对未经分析的文本起作用,作用于被分析的文本字段(该字段的index属性为analyzed),字符过滤器在分词器之前工作,用于从文档的原始文本去除HTML标记(markup),或者把字符“&”转换为单词“and”。ElasticSearch 2.4版本内置3个字符过滤器,分别是:映射字符过滤器(Mapping Char Filter)、HTML标记字符过滤器(HTML Strip Char Filter)和模式替换字符过滤器(Pattern Replace Char Filter)。
1,映射字符过滤器
映射字符过滤器,类型是mapping,需要建立一个查找字符和替换字符的映射(Mapping),过滤器根据映射把文本中的字符替换成指定的字符。
2,HTML标记字符过滤器
HTML标记字符过滤器,类型是html_strip,用于从原始文本中去除HTML标记。
3,模式替换字符过滤器
模式替换字符过滤器,类型是pattern_replace,它使用正则表达式(Regular Expression)匹配字符,把匹配到的字符替换为指定的替换字符串。
pattern参数:指定Java正则表达式;
replacement参数:指定替换字符串,把正则表达式匹配的字符串替换为replacement参数指定的字符串;
二,分词器(Tokenizer)
分词器在字符过滤器之后工作,用于把文本分割成多个标记(Token),一个标记基本上是词加上一些额外信息,分词器的处理结果是标记流,它是一个接一个的标记,准备被过滤器处理。ElasticSearch 2.4版本内置很多分词器,本节简单介绍常用的分词器。
1,标准分词器(Standard Tokenizer)
标准分词器类型是standard,用于大多数欧洲语言,使用Unicode文本分割算法对文档进行分词。
2,字母分词器(Letter Tokenizer)
字符分词器类型是letter,在非字母位置上分割文本,这就是说,根据相邻的词之间是否存在非字母(例如空格,逗号等)的字符,对文本进行分词,对大多数欧洲语言非常有用。
3,空格分词器(Whitespace Tokenizer)
空格分词类型是whitespace,在空格处分割文本
4,小写分词器(Lowercase Tokenizer)
小写分词器类型是lowercase,在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务。
5,经典分词器(Classic Tokenizer)
经典分词器类型是classic,基于语法规则对文本进行分词,对英语文档分词非常有用,在处理首字母缩写,公司名称,邮件地址和Internet主机名上效果非常好。
三,标记过滤器(Token Filter)
分析器包含零个或多个标记过滤器,标记过滤器在分词器之后工作,用来处理标记流中的标记。标记过滤从分词器中接收标记流,能够删除标记,转换标记,或添加标记。ElasticSearch 2.4版本内置很多标记过滤器,本节简单介绍常用的过滤器。
1,小写标记过滤器(Lowercase)
类型是lowercase,用于把标记转换为小写形式,通过language参数指定语言,小写标记过滤器支持的语言有:Greek, Irish, and Turkish
2,停用词标记过滤器(Stopwords)
类型是stop,用于从标记流中移除停用词。参数stopwords用于指定停用词,ElasticSearch 2.4版本提供的预定义的停用词列表:预定义的英语停用词是_english_,使用预定义的英语停用词列表是 “stopwords” :"_english_"
- PUT /my_index
- {
- "settings": {
- "analysis": {
- "filter": {
- "my_stop": {
- "type": "stop",
- "stopwords": ["and", "is", "the"]
- }
- }
- }
- }
- }
3,词干过滤器(Stemmer)
类型是stemmer,用于把词转换为其词根形式存储在倒排索引,能够减少标记。
4,同义词过滤器(Synonym)
类型是synonym,在分析阶段,基于同义词规则,把词转换为其同义词存储在倒排索引中
同义词文件的格式示例:
四,系统预定义的分析器
在创建索引映射时引用分析器,如果没有定义分析器,那么ElasticSearch将使用默认的分析器,用户可以通过API设置默认的分析器。
default 逻辑名称用于配置在索引和搜索时使用的分析器,default_search 逻辑名称用于配置在搜索时使用的分析器。
- index :
- analysis :
- analyzer :
- default :
- tokenizer : keyword
1,标准分析器(Standard)
分析器类型是standard,由标准分词器(Standard Tokenizer),标准标记过滤器(Standard Token Filter),小写标记过滤器(Lower Case Token Filter)和停用词标记过滤器(Stopwords Token Filter)组成。参数stopwords用于初始化停用词列表,默认是空的。
2,简单分析器(Simple)
分析器类型是simple,实际上是小写标记分词器(Lower Case Tokenizer),在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务。
3,空格分析器(Whitespace)
分析器类型是whitespace,实际上是空格分词器(Whitespace Tokenizer)。
4,停用词分析器(Stopwords)
分析器类型是stop,由小写分词器(Lower Case Tokenizer)和停用词标记过滤器(Stop Token Filter)构成,配置参数stopwords 或 stopwords_path指定停用词列表。
5,雪球分析器(Snowball)
分析器类型是snowball,由标准分词器(Standard Tokenizer),标准过滤器(Standard Filter),小写过滤器(Lowercase Filter),停用词过滤器(Stop Filter)和雪球过滤器(Snowball Filter)构成。参数language用于指定语言。
6,自定义分析器
分析器类型是custom,允许用户定制分析器。参数tokenizer 用于指定分词器,filter用于指定过滤器,char_filter用于指定字符过滤器。
五,查询分析
在分析(_ayalyze)端点上执行分析查询,用于对查询参数进行分析,并返回分析的结果
1,使用默认的分析器执行查询分析
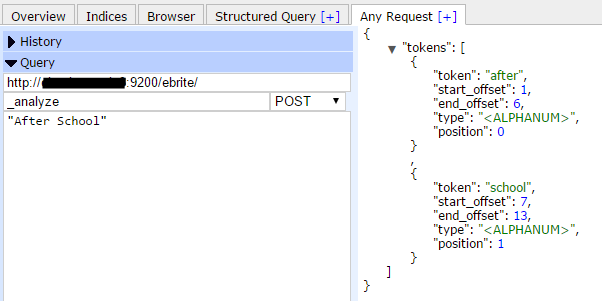
例如,在索引ebrite上执行分析查询,分析字符“After School”,从返回的结果中,可以看到两个标记(Token):“after”和“school”,类型(type)是字符数字类型(<ALPHANUM>),偏移量(offset)从1开始计数,位置(position)从0开始计数。
- POST myindex/_analyze -d
- "After School"
2,指定分析器
- POST myindex/_analyze?analyzer=standard -d
- "After School"

3,指定分词器和过滤器
- POST myindex/_analyze?tokenizer=standard&filters=lowercase -d
- "After School"
4,在特定的字段上执行分析查询
- POST myindex/_analyze?field=doc_field&tokenizer=standard&filters=lowercase -d
- "After School"
附,在创建索引时,指定默认的分析器
示例代码,使用PUT动词,在创建索引时指定默认的分析器,ElasticSearch引擎在索引文档时,使用默认的分析器对index属性为analyzed的文本字段执行分析操作,而非分析字段,将不会应用分析操作。
参考文档:
Elasticsearch: Analyzing Text with the Analyze API
Elasticsearch: The Definitive Guide [2.x] » Dealing with Human Language
ElasticSearch:分析器的更多相关文章
- elasticsearch 分析器 分词器
参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html 在全文搜索(Fu ...
- elasticsearch 分析器阅读笔记(五)
倒排索引 可以查看这里得分词原理https://www.cnblogs.com/LQBlog/articles/5743991.html 分析器 分析器处理过程的3步骤 1.字符过滤器:去除字符的特殊 ...
- Graylog安装操作
Graylog安装操作 实验环境centos7.5系统 mem:4-8G disk:50G 关闭selinux以及firewalld 一.准备环境 1.1.java环境 下载java的j ...
- 操作Document文档
利用客户端操作Document文档数据 1.创建一个文档(创建数据的过程,向表中去添加数据) 请求方式:Post 请求地址:es所在IP:9200/索引库/Type/文档ID(可给可不给,代表唯一标识 ...
- Elasticsearch 自定义多个分析器
分析器(Analyzer) Elasticsearch 无论是内置分析器还是自定义分析器,都由三部分组成:字符过滤器(Character Filters).分词器(Tokenizer).词元过滤器(T ...
- ElasticSearch自定义分析器-集成结巴分词插件
关于结巴分词 ElasticSearch 插件: https://github.com/huaban/elasticsearch-analysis-jieba 该插件由huaban开发.支持Elast ...
- Elasticsearch(八)【NEST高级客户端--分析器】
分析 分析是将文本(如任何电子邮件的正文)转换为添加到反向索引中进行搜索的tokens或terms的过程. 分析由analyzer执行,分析器可以是内置分析器或每个索引定义的定制分析器. 书写分析器测 ...
- Elasticsearch自定义分析器
关于分析器 ES中默认使用的是标准分析器(standard analyzer).如果需要对某个字段使用其他分析器,可以在映射中该字段下说明.例如: PUT /my_index { "mapp ...
- Elasticsearch集成IKAnalyzer分析器
1. 查看标准分析器的分词结果 http://127.0.0.1:9200/_analyze?analyzer=standard&text=标准分析器 都分成了单个汉字, ...
随机推荐
- [appium]-9宫格解锁方法
from appium.webdriver.common.touch_action import TouchAction TouchAction(self.driver).press(x=228,y= ...
- cocos2dx--vs2012+lua开发环境搭建
cocos2dx版本号:cocos2dx2.2.3 lua插件:babelua 1.5.3 下载地址:http://pan.baidu.com/s/1i3mPD8h 第一步:先关闭vs,双击下载下来 ...
- JS学习笔记 - fgm练习 - 输入数字求和 正则replace onkeyup事件
<style> body{font-size: 12px;} .outer{ width: 500px; margin: 0 auto; } span{ color: #999; } in ...
- DE1-SOC学习
https://people.ece.cornell.edu/land/courses/ece5760/DE1_SOC/HPS_peripherials/index.html https://peop ...
- 【MemSQL Start[c]UP 3.0 - Round 1 B】 Lazy Security Guard
[链接]h在这里写链接 [题意] 围成对应面积的方块最少需要多少条边. [题解] 有特定的公式的. 2*ceil(2*根号下(n)); -> 自己找下规律也很简单的. [错的次数] 0 [反思] ...
- 4、基于JZ2440之编写测试代码处理(处理图片识别人脸)
1.代码如下: void detectAndDisplay(Mat image) { CascadeClassifier ccf; //创建脸部对象 //ccf.load(xmlPath); //导入 ...
- ArcSDE:C#打开SDE数据库的几种方式总结
转自原文 ArcSDE:C#打开SDE数据库的几种方式总结 1.通过指定连接属性参数打开数据库 /// <param name="server">数据库服务器名< ...
- 数据结构与算法实验题 7.1 M 商人的求救
问题描述: A 国正面临着一场残酷的战争,城市被支持不同领导的两股势力占据,作为一个商人,M先生并不太关心政治,但是他知道局势很严重,他希望你能救他出去.M 先生说:"为了安全起见,我们的路 ...
- href=“file://” doesn't work
Local Explorer 2016.6.21.0 CRX for Chrome or Chromium https://www.crx4chrome.com/extensions/eokekhgp ...
- (十四)RabbitMQ消息队列-启用SSL安全通讯
原文:(十四)RabbitMQ消息队列-启用SSL安全通讯 如果RabbitMQ服务在内网中,只有内网的应用连接,我们认为这些连接都是安全的,但是个别情况我们需要让RabbitMQ对外提供服务.这种情 ...