Java集合--Hash、Hash冲突
一、Hash
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。 这个映射函数称做散列函数,存放记录的数组称做散列表。
- 实现Hash算法的关键:实现hash算法 、解决hash冲突
1.Hash函数
首先来说hash函数,java中对象都已一个hashCode()方法,那为什么还需要hash函数呢?hashCode是在jdk中是有符号int类型,这个一个很大的范围,如果散列表的数组能覆盖所有int值的话,就不需要hash函数了,当然内存不允许我们维护这么大的散列表。这时我们需要hash函数将原始hashCode映射到一个很小的数组上去。意思就是将超大超长或不定长的整形数据转换为唯一(理想情况,对于不同对象hash值应该不相同)的定长的hash值,常见的做法是取模法,也是jdk中的实现方式。
- HashMap的hashCode实现:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
第一个hash函数有人称之为“扰动函数”,第二个indexFor函数在jdk8中去掉了,函数内的代码合并到了putVal中,个人认为这两个函数合并起来是一个完整的hash函数。
h & (length-1) 这段代码的作用其实就是取模,假设数组初始化长度为16,那么length-1的结果为15,对应二进制为00001111,如果我们有一个大小为20的key,对应二进制为00010100,与运算后结果为00000100,对应十进制为4。
这里数组的长度必须为2的次幂。由于对key进行了取模运算,所以我们知道当length=16的时候,我们会舍弃调掉key高位的值,只保留了低4位。本来int是32位,只是用低4位冲突是不是太容易发生了?
所以第一个“扰动函数”的作用出现了,这个函数将key本身高16和低16位做了异或运算。

尽管实现了如此有效的散列算法,但只是将不同对象之间hash碰撞的概率降低了,还是不能完全保证不发生hash冲突,因此要继续使用hash表的优点就要解决hash冲突的问题。
二、解决Hash冲突
1.开放定址法(线性探测,二次探测,伪随机探测)
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败。
当哈希表越来越满时聚集越来越严重,这导致产生非常长的探测长度,后续的数据插入将会非常费时。通常数据超过三分之二满时性能下降严重,因此设计哈希表关键确保不会超过这个数据容量的一半,最多不超过三分之二。
- 用开放定址法建立散列表时,建表前须将表中所有单元(更严格地说,是指单元中存储的关键字)置空。
- 空单元的表示与具体的应用相关。
按照形成探查序列的方法不同,可将开放定址法区分为线性探查法、线性补偿探测法、随机探测等。
(1)线性探查法(Linear Probing)
- 该方法的基本思想是将散列表T[0..m-1]看成是一个循环向量,若初始探查的地址为d(即h(key)=d),则最长的探查序列为:
d,d+l,d+2,…,m-1,0,1,…,d-1
即:探查时从地址d开始,首先探查T[d],然后依次探查T[d+1],…,直到T[m-1],此后又循环到T[0],T[1],…,直到探查到T[d-1]为止。
- 探查过程终止于三种情况:
①若当前探查的单元为空,则表示查找成功(若是插入则将key写入其中);
②若当前探查的单元中含有key,则查找成功,但对于插入意味着失败;
③若探查到T[d-1]时仍未发现空单元,则无论是查找还是插入均意味着失败(此时表满,需要扩容)。
- 利用开放地址法的一般形式,线性探查法的探查序列为:
hi=(h(key)+i)%m 0≤i≤m-1 //i=1

- 用线性探测法处理冲突,思路清晰,算法简单,但存在下列缺点:
①哈希表容量不能完全利用,并且扩容将会是灾难的,需要删除以前标记过的元素并需要从新计算所有元素的位置,在频繁的删除和插入时效率变得很低。
②按上述算法建立起来的哈希表,删除工作非常困难。假如要从哈希表 HT 中删除一个记录,按理应将这个记录所在位置置为空,但我们不能这样做,而只能标上已被删除的标记,否则,将会影响以后的查找。
③线性探测法很容易产生堆聚现象。所谓堆聚现象,就是存入哈希表的记录在表中连成一片。按照线性探测法处理冲突,如果生成哈希地址的连续序列愈长(即不同关键字值的哈希地址相邻在一起愈长),则当新的记录加入该表时,与这个序列发生冲突的可能性愈大。因此,哈希地址的较长连续序列比较短连续序列生长得快,这就意味着,一旦出现堆聚(伴随着冲突),就将引起进一步的堆聚。
(2)线性补偿探测法
线性补偿探测法的基本思想是将线性探测的步长从 1 改为 Q ,即将上述算法中的 hi=(h(key)+i)%m改为:hi=(h(key)+Q)%m,这个Q是根据一定的增长率变化的(1、4、9...),这样使得数据分布的足够散乱,不容易出现聚堆现象,而且要求 Q 的变化能使全表得到完整的扫描,以便能探测到哈希表中的所有单元(当然还有其他的线性在散列算法规则,这里只讨论该种方式的再散列)。

(3)随机探测
随机探测的基本思想是将线性探测的步长从常数改为随机数,即令:hi=(h(key)+RN)%m ,其中 RN 是一个随机数。在实际程序中应预先用随机数发生器产生一个随机序列,将此序列作为依次探测的步长。这样就能使不同的关键字具有不同的探测次序,从而可以避免或减少堆聚。基于与线性探测法相同的理由,在线性补偿探测法和随机探测法中,删除一个记录后也要打上删除标记。
2.链地址法(拉链法)
拉链法解决冲突的做法是将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于 1,但一般均取α≤1。
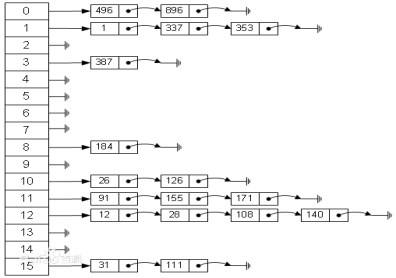
- 与开放定址法相比拉链法的优点
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
- 拉链法的缺点
当发生hash冲突时,需要生成链表由此需要额外占用空间,并且需要花一定的时间和精力维护冲突链表。在扩容的时候需要把所有元素进行重新hash并分配地址,算法较为复杂繁琐。
3.再哈希(了解)
再hash法,就是算hashcode的方法不止一个,一个要是算出来重复啦,再用另一个算法去算。使用一定的算法逻辑的到一种在当前情况不会发生hash冲突的hash算法。
4.建立公共溢出区(了解)
建立一个公共溢出区域,就是把冲突的都放在另一个地方,不在表里面。具体实现不做探讨了(不常用)。
Java集合--Hash、Hash冲突的更多相关文章
- Java 集合 散列表hash table
Java 集合 散列表hash table @author ixenos 摘要:hash table用链表数组实现.解决散列表的冲突:开放地址法 和 链地址法(冲突链表方式) hash table 是 ...
- 【java基础 10】hash算法冲突解决方法
导读:今天看了java里面关于hashmap的相关源码(看了java6和java7),尤其是resize.transfer.put.get这几个方法,突然明白了,为什么我之前考数据结构死活考不过,就差 ...
- HashMap之Hash碰撞冲突解决方案及未来改进
说明:参考网上的两篇文章做了简单的总结,以备后查(http://blogread.cn/it/article/7191?f=wb ,http://it.deepinmind.com/%E6%80%A ...
- Java集合(九)哈希冲突及解决哈希冲突的4种方式
Java集合(九)哈希冲突及解决哈希冲突的4种方式 一.哈希冲突 (一).产生的原因 哈希是通过对数据进行再压缩,提高效率的一种解决方法.但由于通过哈希函数产生的哈希值是有限的,而数据可能比较多,导致 ...
- Java实现一致性Hash算法深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中”一致性Hash算法”部分,对于为什么要使用一致性Hash算法和一致性Hash算法的算法原 ...
- 散列表和JAVA中的hash
引文 hello,今天写的数据结构是散列表(hash表),也算是一种基础数据结构了吧.学过计算机的人大概都能说出来这是个以空间换时间的东西,那么具体怎么实现的是今天要讨论的问题. 为什么需要它?主要还 ...
- 解决Hash碰撞冲突方法总结
Hash碰撞冲突 我们知道,对象Hash的前提是实现equals()和hashCode()两个方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰 ...
- Java实现一致性Hash算法
Java代码实现了一致性Hash算法,并加入虚拟节点.,具体代码为: package com.baijob.commonTools; import java.util.Collection; im ...
- 解决Hash碰撞冲突的方法
Hash碰撞冲突 我们知道,对象Hash的前提是实现equals()和hashCode()两个方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰 ...
- HashMap的底层实现以及解决hash值冲突的方式
class HashMap<K,V> extends AbstractMap<K,V> HashMap put() HashMap get() 1.put() HashMa ...
随机推荐
- Python实现进度条的效果
from itertools import cycle from time import sleep for frame in cycle(r'-\|/-\|/'): print('\r', fram ...
- Axure实现提示文本单击显示后自动消失的效果
Axure实现提示文本单击显示后自动消失的效果 方法/步骤 如图所示,框出的部分为提示文本(已经命名为tooltip),希望达到的效果是默认加载时不显示,点击帮助图标后显示,且2秒后自动消失. ...
- (一)OpenCV-Python学习—基础知识
opencv是一个强大的图像处理和计算机视觉库,实现了很多实用算法,值得学习和深究下. 1.opencv包安装 · 这里直接安装opencv-python包(非官方): pip install ope ...
- java 枚举和数值的相互转换
枚举简介 enum 的全称为 enumeration, 是 JDK 1.5 中引入的新特性,存放在 java.lang 包中 在实际编程中,往往存在着这样的“数据集”,它们的数值在程序中是稳定的,而 ...
- java泛型中特殊符号的含义
java泛型中的标记符含义: E - Element (在集合中使用,因为集合中存放的是元素) T - Type(Java 类) K - Key(键) V - Value(值) N - Number ...
- scikit-learn机器学习(四)使用决策树做分类
我们使用决策树来创建一个能屏蔽网页横幅广告的软件. 已知图片的数据判断它属于广告还是文章内容. 数据来自 http://archive.ics.uci.edu/ml/datasets/Internet ...
- 反射序列化字段的时候,需要添加[Datamember]不然会,忽略这个字段
反射序列化字段的时候,需要添加[Datamember]不然会,忽略这个字段
- php 转化整型需要注意的地方
public function tt(){ $num = '19.90'; echo $num; echo '<br/>--------------<br/>'; echo 1 ...
- 使用apache commons net进行ftp传输
apache commons net的maven地址: http://mvnrepository.com/artifact/commons-net/commons-net/3.6 <!-- ht ...
- Spark快速大数据分析之RDD基础
Spark 中的RDD 就是一个不可变的分布式对象集合.每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上.RDD 可以包含Python.Java.Scala中任意类型的对象,甚至可以包含 ...