Flink简介
Flink简介
Flink的核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以方便用户编写分布式任务:
1. DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便的采用Flink提供的各种操作符对分布式数据集进行各种操作,支持Java,Scala和Python。
2. DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便的采用Flink提供的各种操作符对分布式数据流进行各种操作,支持Java和Scala。
3. Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过Flink提供的类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
此外,Flink还针对特定的应用领域提供了领域库,例如:
1. Flink ML,Flink的机器学习库,提供了机器学习Pipelines API以及很多的机器学习算法实现。
2. Gelly,Flink的图计算库,提供了图计算的相关API以及很多的图计算算法实现。
Flink的技术栈如下图所示:
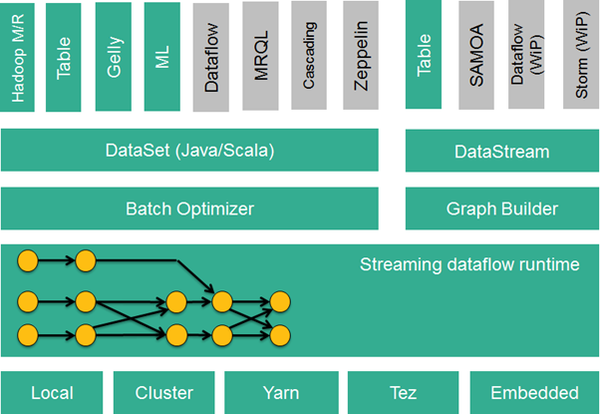
Flink技术栈
此外,Flink也可以方便地和其他的Hadoop生态圈的项目集成,例如,Flink可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式的数据源,直接重用MapReduce/Storm代码,或是通过YARN申请集群资源等等。
链接:https://zhuanlan.zhihu.com/p/20585530
Spark 和 Flink 比较
Flink简介的更多相关文章
- (转)Flink简介
1. Flink的引入 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河 ...
- flink01--------1.flink简介 2.flink安装 3. flink提交任务的2种方式 4. 4flink的快速入门 5.source 6 常用算子(keyBy,max/min,maxBy/minBy,connect,union,split+select)
1. flink简介 1.1 什么是flink Apache Flink是一个分布式大数据处理引擎,可以对有限数据流(如离线数据)和无限流数据及逆行有状态计算(不太懂).可以部署在各种集群环境,对各种 ...
- Flink简介及使用
一.Flink概述 官网:https://flink.apache.org/ mapreduce-->maxcompute HBase-->部门 quickBI DataV Hive--& ...
- Apache 流框架Flink简介
1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提供 API来像Spark ...
- Flink学习之路(一)Flink简介
一.什么是Flink? Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能. 二.Flink特点 1.现有的开源计算方案,会把流处 ...
- Flink(一)Flink的入门简介
一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河 ...
- [转帖]Flink(一)Flink的入门简介
Flink(一)Flink的入门简介 https://www.cnblogs.com/frankdeng/p/9400622.html 一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的 ...
- Flink流处理(一)- 状态流处理简介
1. Flink 简介 Flink 是一个分布式流处理器,提供直观且易于使用的API,以供实现有状态的流处理应用.它能够以fault-tolerant的方式高效地运行在大规模系统中. 流处理技术在当今 ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
随机推荐
- CSS 样式表{二}
1 选择器的优先级 选择器的优先主要考虑选择器的权重 可以将各种选择器的权重以数值来表示,数值越大,优先级越高 选择器 权重值 标签selector 1 类选择器 10 ID选择器 100 行内样式 ...
- Dubbo:1
Dubbo能解决什么问题 怎么去维护url:通过注册中心去维护url(zookeeper.redis.memcache…). F5硬件负载均衡器的单点压力比较大:软负载均衡. 怎么去整理出服务之间的依 ...
- Image Processing and Analysis_21_Scale Space:Feature Detection with Automatic Scale Selection——1998
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- 跟着minium官网介绍学习minium-----(三)
注意:程序运行时在微信开发者工具当前页面为主,而不是每次运行都是从home页面开始 一 获取单个元素 get_element():在当前页面查询控件, 如果匹配到多个结果, 则返回第一个匹配到的结果 ...
- centos6/7启动故障排错
centos6启动流程修复: 实验一:删除initramfs-2.6.32-754.el6.x86_64.img进行恢复 该文件很重要initramfs-2.6.32-754.el6.x86_64.i ...
- Hosts 长期更新【已停】
修改hosts篇 [2018.1.3] 由于google的对应的hosts更新过于频繁,再加上上次(18+1)大之后,国家政策原因,网上hosts更新基本上都停了,github的项目也陆续挂掉了. 还 ...
- Kinect for Windows SDK开发入门(三):基础知识 下
原文来自:http://www.cnblogs.com/yangecnu/archive/2012/04/02/KinectSDK_Application_Fundamentals_Part2.htm ...
- sqlserver 拼接字符串
SELECT CAST(USER_ID AS VARCHAR) + ',' FROM dbo.AUTH_USER FOR XML PATH('');
- sql/pl 安装并连接Oracle数据库
1,首先,先下载pl/sql devloper 安装包.下载对应版本的安装包 下载地址 https://www.allroundautomations.com/bodyplsqldevreg.htm ...
- 【python】使用xlrd,xlwt来操作已存在的excel表
import xlrd import xlwt from xlutils.copy import copy # 打开想要更改的excel文件 old_excel = xlrd.open_workboo ...