ML.Net Model Builder
ML.Net Model Builder
ML.NET技术研究系列1-入门篇
近期团队在研究机器学习,希望通过机器学习实现补丁发布评估,系统异常检测。业务场景归纳一下:
- 收集整理数据(发布相关的异常日志、告警数据),标识出补丁发布情况(成功、失败)
- 选择一个机器学习的Model进行Train训练
- 基于训练出的模型(准确度要高)进行最新补丁发布情况预测
典型的机器学习-监督学习的场景。作为.Net的忠实用户,最近火热的ML.NET务必要尝试、应用一把。今天这篇文章作为一个入门,分享给大家。
先拉个提纲吧:
1. ML.Net Model Builder 介绍及安装部署
2. 典型场景示例
一、ML.Net Model Builder介绍及安装部署
首先,ML.Net Model Builder是什么?它有什么作用?
https://marketplace.visualstudio.com/items?itemName=MLNET.07
Model Builder是一个简单的UI工具,供开发人员在其应用程序中构建,培训和发布自定义机器学习模型。
没有ML专业知识的开发人员可以使用这个简单的可视化界面连接到存储在文件或SQL Server中的数据,训练模型并生成用于模型培训和消费的代码。
一句话总结一下:机器学习建模工具,通过一个VS Designer 可视化构建一个机器学习模型。同时生成一个示例和向导代码,可重复使用。
1. 安装部署
官方的推荐是:Visual Studio 2017 15.9.12 or later
我本机安装了VS2019和VS2017 Enterprise版,直接通过https://marketplace.visualstudio.com/items?itemName=MLNET.07 下线了VS扩展插件MLNET_Model_Builder.vsix。双击安装:
VSIXInstaller.NoApplicableSKUsException: This extension is not installable on any currently installed products.
当前安装的VS无法安装这个扩展,一顿google,https://github.com/dotnet/machinelearning-samples/issues/451 依旧解决不了。重新安装了VS2017和VS2019 然并卵。
最后,找到官方的推荐的VS:Visual Studio 2017 15.9.12 or later 安装了VS2017的 vs_community__425161747.1541050689
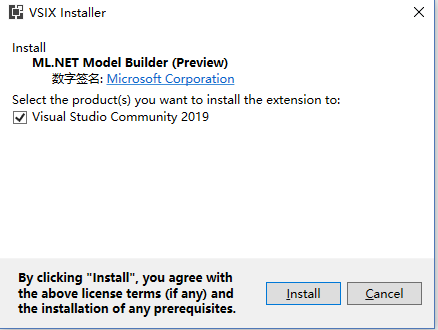
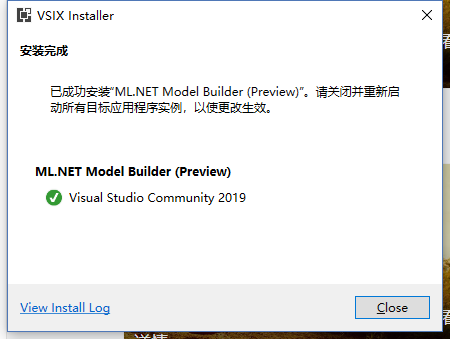
终于安装成功。
2. 新建一个 .Net Core控制台Project,添加Machine Learning项目
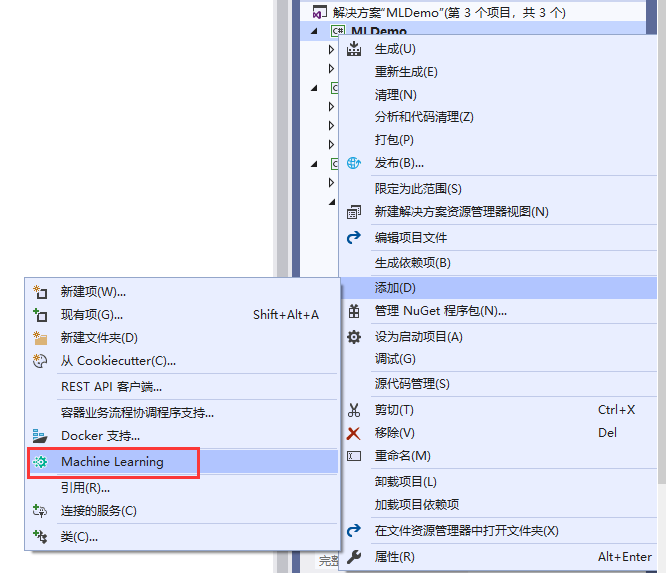
弹出 ML.Net Model Builder设计器,说明可以开始机器学习建模了。
3. 开始机器学习建模
微软将机器学习建模的典型场景进行了抽象和分类,主要有以下三种:
regression:回归类机器学习模型:典型场景有:价格预测、销售额预测等等
binary classification:二元分类机器学习模型,典型场景有:用户评论情感分析(消极 or 积极)、交易风险预测(是 or 否)
multi-classification:多维分类机器学习模型。典型场景有:用户画像、数据分类
另外,ML.Net 还支持自定义建模。

4. 准备Train 机器学习训练需要的样本数据
通过微软提供的示例样本数据和场景下,目前机器学习训练的样本数据都是结构化的数据,确定的维度、值。同时,需要对要预测的维度数据进行Label标识和标注。
总结概况一下:
- 样本数据必须是结构化的数据,确定的列和值
- 样本数据由各个维度列和一个预测维度列组成
- 样本数据中预测维度列的值需要手工标注,以便进行机器学习训练
从上面的总结可以看出,ML.NET 属于监督学习这一类。
样本数据的格式:支持CSV(逗号间隔)、TSV(Tab间隔)和SQL Server。
至于怎么另存为TSV文件,其实很简单,Copy示例数据到文本编辑器,另存为**.tsv文件即可。https://raw.githubusercontent.com/dotnet/machinelearning/master/test/data/wikipedia-detox-250-line-data.tsv
选择输入结构化的样本数据后,要指定一个机器学习要预测的列。
5. Train训练、评估
指定输入的数据和要预测的列,进行训练。训练的过程会评估AutoML中提供的各种算法的准确度。
Train训练的时间,随数据量的不同而不同
训练完成后,会输出一个最佳准确度的算法,同时生产一个模型文件,MLModel.zip, 供后续预测使用。
6. 生成可重复执行的代码
即将ML.NET Model Builder 设计器向导的配置,生成可重复执行的代码:两个C# Project,一个Model的Project,一个Console的Project。
二、典型场景示例
第一大章节,我们将整个ML.NET的建模过程做了梳理,现在我们以微软的示例代码,做一个实践应用。
这次我们选择用户反馈情感分析这个场景,这几天我想了一下,这个场景的实际价值是:线上爬取指定产品的用户评论和反馈,通过机器学习预测出产品的热度、问题,后续进行产品完善和市场活动。
话不多说,开始吧。
1. 准备TSV数据
这个非常简单:https://raw.githubusercontent.com/dotnet/machinelearning/master/test/data/wikipedia-detox-250-line-data.tsv,这个文本拷贝到Sublime Text中,另存为data.tsv文件
2. 新建.Net Core Console 应用,右键添加 Machine Learning项目
在选择场景步骤中,我们选择第一个,“情感分析”
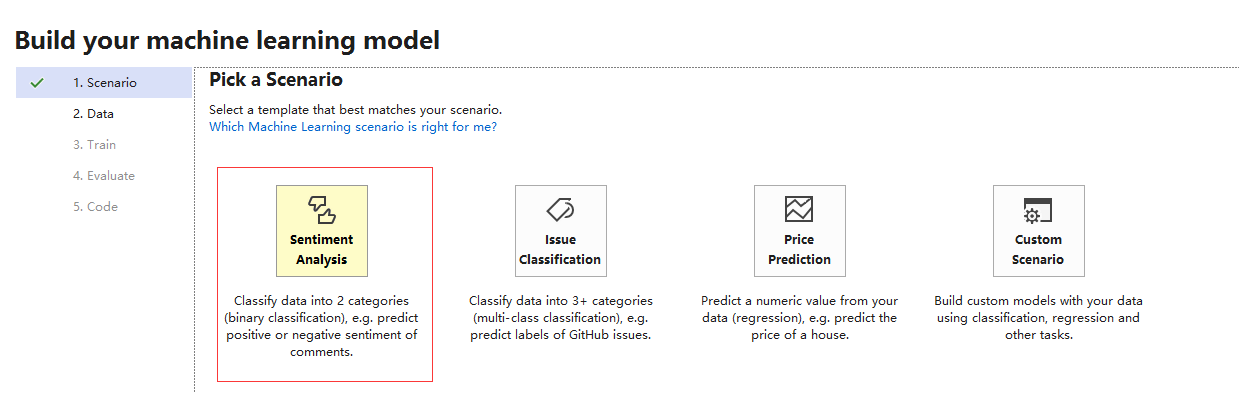
2. 选择样本数据,进行训练,预测
选择第一步我们准备好的data.tsv文件,指定一个要预测的列Sentiment
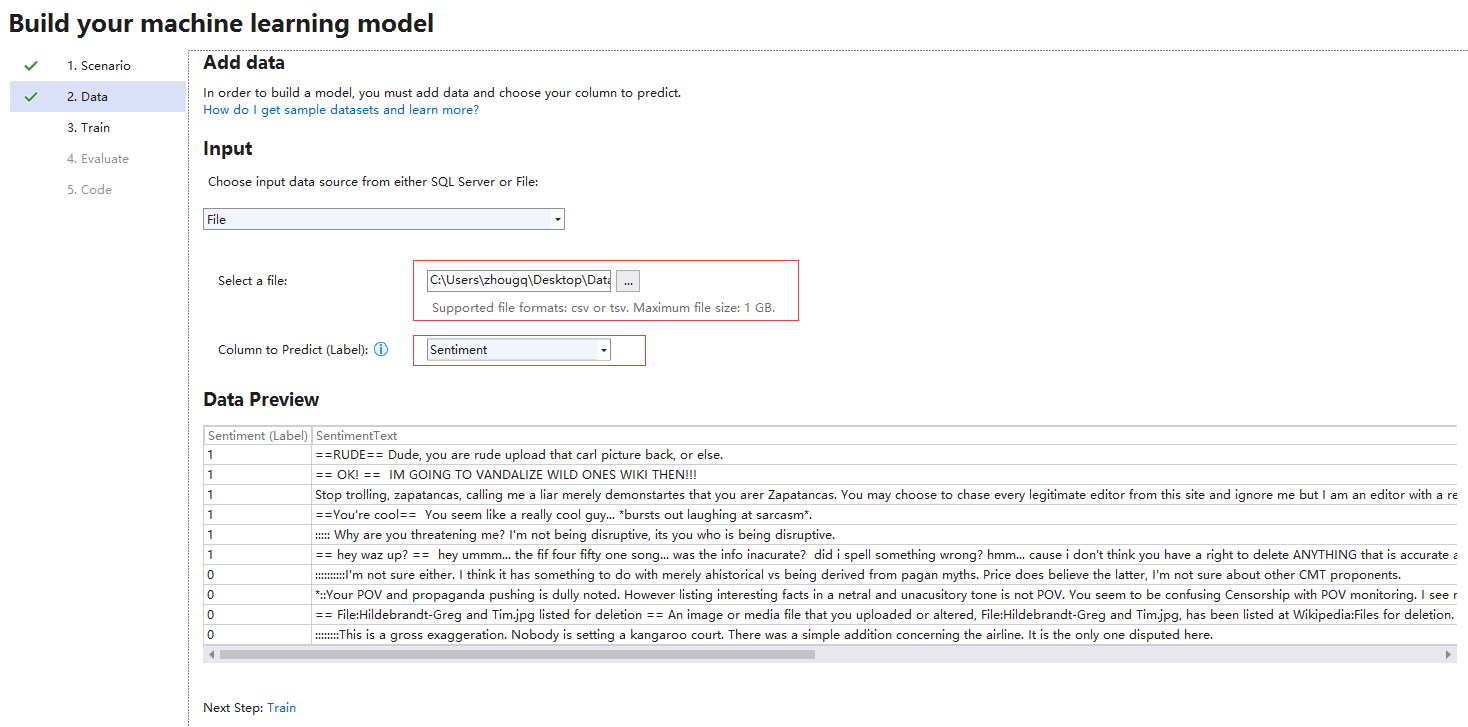
3. 开始样本数据的训练
训练的时间和数据量有关系,一般的:
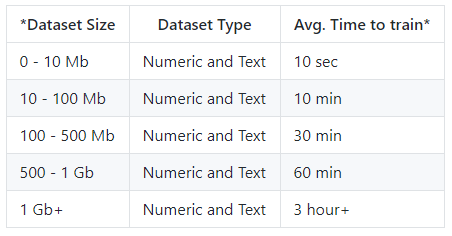
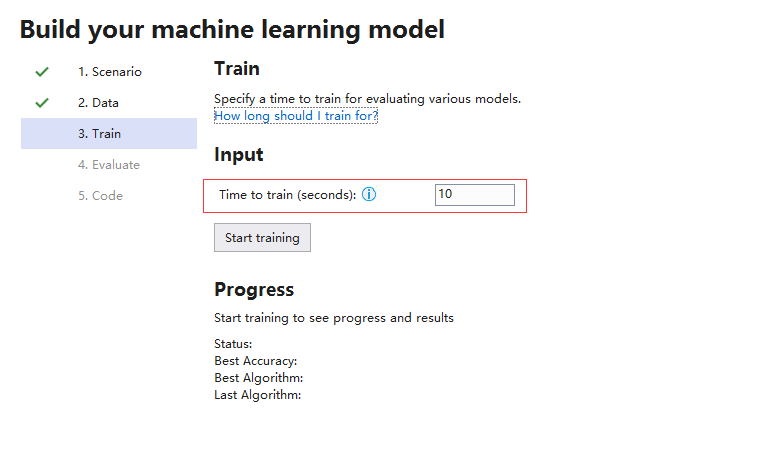
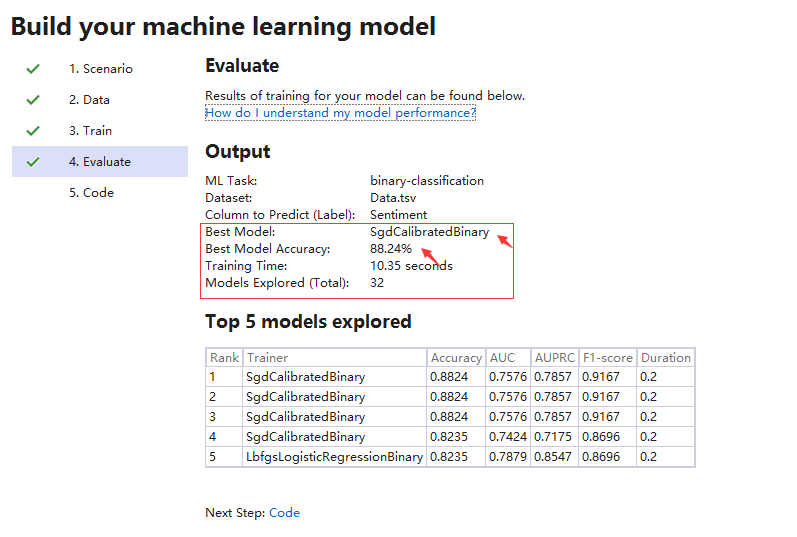
这里我们尝试了10s和30s,最近算法和准确度没有变化,只是尝试机器学习训练的算法要多:
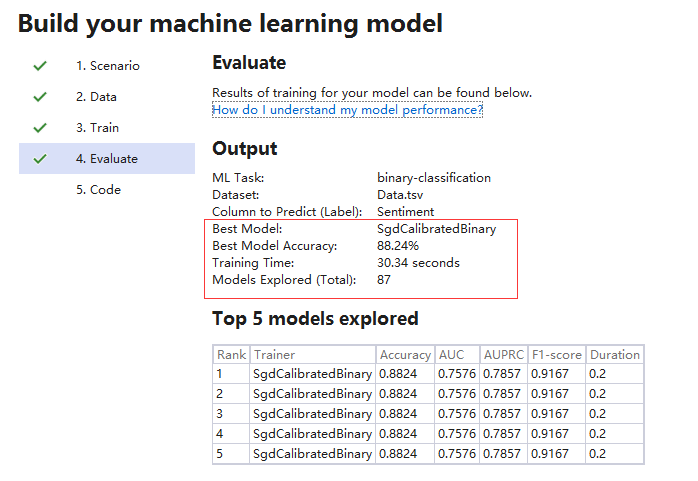
5. 生成可重复执行的代码工程

生成代码后,会在当前解决方案中多了两个Project,一个是Model的Project,一个Console的Project,我们深入看一下
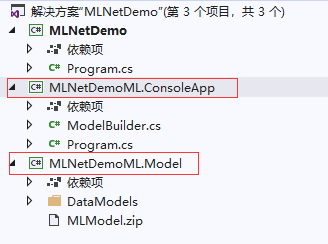
其中Model Project中主要包含:
模型的输入类和输出类,其中:
- 输入类ModelInput是对我们输入数据的结构化描述
- 输出类ModelOutput是包含预测列和评估准确度
还有一个机器学习样本数据训练完成后的MLModel.zip文件,供后续数据预测用。
Console Project中,主要形成了一个可重复执行的代码:重点看Main函数的代码:

1 //Machine Learning model to load and use for predictions
2 private const string MODEL_FILEPATH = @"MLModel.zip";
3
4 //Dataset to use for predictions
5 private const string DATA_FILEPATH = @"C:\Users\zhougq\Desktop\Data.tsv";
6
7 static void Main(string[] args)
8 {
9 MLContext mlContext = new MLContext();
10
11 // Training code used by ML.NET CLI and AutoML to generate the model
12 //ModelBuilder.CreateModel();
13
14 ITransformer mlModel = mlContext.Model.Load(GetAbsolutePath(MODEL_FILEPATH), out DataViewSchema inputSchema);
15 var predEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(mlModel);
16
17 // Create sample data to do a single prediction with it
18 ModelInput sampleData = CreateSingleDataSample(mlContext, DATA_FILEPATH);
19
20 // Try a single prediction
21 ModelOutput predictionResult = predEngine.Predict(sampleData);
22
23 Console.WriteLine($"Single Prediction --> Actual value: {sampleData.Sentiment} | Predicted value: {predictionResult.Prediction}");
24
25 Console.WriteLine("=============== End of process, hit any key to finish ===============");
26 Console.ReadKey();
27 }
上面的代码解读一下:
- 构建一个MLContext
- MLContext上加载训练好的模型(MLModel.zip)
- 输入要预测的数据
- 预测,输出结果(ModelOutput)
上面的代码是一个点睛之笔,我们可以想象一下:
1. 每天正常的机器学习、训练,优化模型
2. 线上数据,通过Kafka、文本等数据源,实时接入数据,进行预测
3. 对预测的结果进行评估、对样本数据再纠正和标注,直至模型的准确率更高
4. 作用与线上业务决策
5. Loop
是不是很赞,很简单,很容易理解,简化了我们对机器学习的建模、算法选择和评估。生产力工具,技术普惠。
给ML.NET 点赞。
后续我们将基于ML.NET实现更多的业务场景,逐步分享给大家。
ML.Net Model Builder的更多相关文章
- ML.NET Model Builder 更新
ML.NET是面向.NET开发人员的跨平台机器学习框架,而Model Builder是Visual Studio中的UI工具,它使用自动机器学习(AutoML)轻松地允许您训练和使用自定义ML.NET ...
- Chisel3 - model - Builder
https://mp.weixin.qq.com/s/THqyhoLbbuXXAtdQXRQDdA 介绍构建硬件模型的Builder. 1. DynamicContext 动态上下文 ...
- Model Builder中Table2Table中字段映射的问题
ArcGIS10中使用过程中,Bug不少.尽管有了SP3,但模型耦合的深层次的应用中还是错误不少.目前只是遇到一个,利用躲避的方法解决一个.例如,从NetCDF中抽出的数据表,必须在内存和数据库中都存 ...
- ML.NET技术研究系列1-入门篇
近期团队在研究机器学习,希望通过机器学习实现补丁发布评估,系统异常检测.业务场景归纳一下: 收集整理数据(发布相关的异常日志.告警数据),标识出补丁发布情况(成功.失败) 选择一个机器学习的Model ...
- .NET开发人员如何开始使用ML.NET
随着谷歌,Facebook发布他们的工具机器学习工具Tensorflow 2和PyTorch ,微软的CNTK 2.7之后不再继续更新(https://docs.microsoft.com/zh-cn ...
- 微软发布ML.NET 1.0
原文地址:https://devblogs.microsoft.com/dotnet/announcing-ml-net-1-0/ 我们很高兴地宣布今天发布ML.NET 1.0. ML.NET是一个 ...
- 使用ML.NET进行自定义机器学习
ML.NET是Microsoft最近发布的用于机器学习的开源,跨平台,代码优先的框架.尽管对我们来说是一个新的框架,但该框架的根源是Microsoft Research,并且在过去十年中已被许多内部团 ...
- 关于ML.NET v1.0 的发布说明
今天,我们很高兴宣布发布 ML.NET 1.0.ML.NET 是一个免费的.跨平台的开源机器学习框架,旨在将机器学习(ML)的强大功能引入.NET 应用程序. ML.NET GitHub:https: ...
- C#中的深度学习(五):在ML.NET中使用预训练模型进行硬币识别
在本系列的最后,我们将介绍另一种方法,即利用一个预先训练好的CNN来解决我们一直在研究的硬币识别问题. 在这里,我们看一下转移学习,调整预定义的CNN,并使用Model Builder训练我们的硬币识 ...
随机推荐
- PHP流程控制之if语句多种嵌套
王思总同学我们在最开始的故事中讲到了他有两个秘书:一个生活秘书.一个工作秘书. 王思总同学在出行和项目中也是极度有计划性.他给自己的生活秘书和工作秘书分别指派了出差的行程:大理石平台支架 生活上: 先 ...
- 基础 | BIO、NIO与AIO
本文链接:https://blog.csdn.net/bingbeichen/article/details/83617163 Java中的IO部分比较复杂,具体可参看书籍<Java NIO&g ...
- [Luogu] 送花
https://www.luogu.org/problemnew/show/2073 自己yy,明显错 #include <bits/stdc++.h> using namespace s ...
- 爬虫(十五):scrapy中的settings详解
Scrapy设定(settings)提供了定制Scrapy组件的方法.你可以控制包括核心(core),插件(extension),pipeline及spider组件.设定为代码提供了提取以key-va ...
- 数据结构实验之查找三:树的种类统计(SDUT 3375)
C: #include <stdio.h> #include <stdlib.h> #include <string.h> struct node { char d ...
- centos7 浏览器(firefox)中文乱码
主要问题在于firefox用了系统没有的字体 百度的方案: 通过yum安装中文字体 (找不到对应的库) 修改firefox的默认字体(尴尬.不知道改哪个才有效) 粗暴的解决方案: 把 windows ...
- maven引入第三方jar包
maven有两种文件解析和分配策略,也就是我们常说的artifacts(依赖). 第一种是本地仓库,这是你缓存在本地的依赖.默认在${user.home}/.m2/repository目录下;当mav ...
- harukaの收藏夹
#include<map> 比较好的图论作图网站 heap Sth About EXCRT OI-Wiki 数学 树形dp入门 开开心心学背包 一起复习qwq 模板库(非原创) LaTex ...
- Lucene4.2源码解析之fdt和fdx文件的读写(续)——fdx文件存储一个个的Block,每个Block管理着一批Chunk,通过docID读取到document需要完成Segment、Block、Chunk、document四级查询,引入了LZ4算法对fdt的chunk docs进行了实时压缩/解压
2 索引读取阶段 当希望通过一个DocId得到Doc的全部内容,那么就需要对fdx/fdt文件进行读操作了.具体的代码在CompressingStoredFieldsReader类里面.与 ...
- WORD转HTML-python第三方包Mammoth(官方文档翻译)
Mammoth 官方 Mammoth可用于将.docx文档(比如由Microsoft Word创建的)转换为HTML.Mammoth致力于通过文档中的语义信息生成简洁的HTML,而忽略一些其他细节.例 ...