推荐系统系列(三):FNN理论与实践
背景
在FM之后出现了很多基于FM的升级改造工作,由于计算复杂度等原因,FM通常只对特征进行二阶交叉。当面对海量高度稀疏的用户行为反馈数据时,二阶交叉往往是不够的,三阶、四阶甚至更高阶的组合交叉能够进一步提升模型学习能力。如何能在引入更高阶的特征组合的同时,将计算复杂度控制在一个可接受的范围内?
参考图像领域CNN通过相邻层连接扩大感受野的做法,使用DNN来对FM显式表达的二阶交叉特征进行再交叉,从而产生更高阶的特征组合,加强模型对数据模式的学习能力 [1]。这便是本文所要介绍的FNN(Factorization Machine supported Neural Network)模型,下面将对FNN进行详细介绍。
分析
1. FNN 结构
FNN的思想比较简单,直接在FM上接入若干全连接层。利用DNN对特征进行隐式交叉,可以减轻特征工程的工作,同时也能够将计算时间复杂度控制在一个合理的范围内。
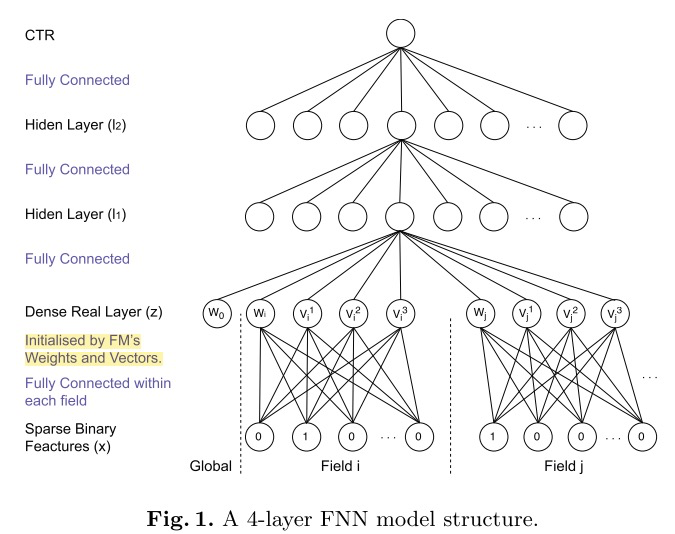
为了加速模型的收敛,充分利用FM的特征表达能力,FNN采用了两阶段训练方式。首先,针对任务构建FM模型,完成模型参数的学习。然后,将FM的参数作为FNN底层参数的初始值。这种两阶段方式的应用,是为了将FM作为先验知识加入到模型中,防止因为数据稀疏带来的歧义造成模型参数偏差。
However, according to [21], if the observational discriminatory information is highly ambiguous (which is true in our case for ad click behaviour), the posterior weights (from DNN) will not deviate dramatically from the prior (FM).
通过结构图可以看到,在特征进行输入之前首先进行分域操作,这种方式也成了后续处理高维稀疏性数据的通用做法,目的是为了减少模型参数量,与FM计算过程保持一致。
模型中的 \(Dense Real Layer\) 将FM产出的低维稠密特征向量进行简单拼接,作为下一全连接层的输入,采用 \(tanh\) 激活函数,最终使用 \(sigmoid\) 将输出压缩至0~1之间作为预测。
2. 优缺点
优点:
- 引入DNN对特征进行更高阶组合,减少特征工程,能在一定程度上增强FM的学习能力。这种尝试为后续深度推荐模型的发展提供了新的思路(相比模型效果而言,个人感觉这种融合思路意义更大)。
缺点:
- 两阶段训练模式,在应用过程中不方便,且模型能力受限于FM表征能力的上限。
- FNN专注于高阶组合特征,但是却没有将低阶特征纳入模型。
仔细分析下这种两阶段训练的方式,存在几个问题:
1)FM中进行特征组合,使用的是隐向量点积。将FM得到的隐向量移植到DNN中接入全连接层,全连接本质是将输入向量的所有元素进行加权求和,且不会对特征Field进行区分,也就是说FNN中高阶特征组合使用的是全部隐向量元素相加的方式。说到底,在理解特征组合的层面上FNN与FM是存在Gap的,而这一点也正是PNN对其进行改进的动力。
2)在神经网络的调参过程中,参数学习率是很重要的。况且FNN中底层参数是通过FM预训练而来,如果在进行反向传播更新参数的时候学习率过大,很容易将FM得到的信息抹去。个人理解,FNN至少应该采用Layer-wise learning rate,底层的学习率小一点,上层可以稍微大一点,在保留FM的二阶交叉信息的同时,在DNN上层进行更高阶的组合。
3. 参数调优
根据论文中的实验来看,性能影响最大的超参数为:1)DNN部分的网络结构;2)dropout比例;
个人认为,该论文中超参数对比试验做的并不严谨,以下结论仅供参考。
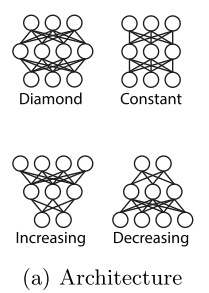
1)DNN部分的网络结构
对比四种网络结构,最佳的网络结构为 \(Diamond\) .
2)dropout比例
Dropout的效果要比L2正则化更好,且FNN最佳dropout比例为0.8左右。

实验
依旧使用 \(MovieLens100K dataset\) ,核心代码如下。
class FNN(object):def __init__(self, vec_dim=None, field_lens=None, lr=None, dnn_layers=None, dropout_rate=None, lamda=None):self.vec_dim = vec_dimself.field_lens = field_lensself.field_num = len(field_lens)self.lr = lrself.dnn_layers = dnn_layersself.dropout_rate = dropout_rateself.lamda = float(lamda)self.l2_reg = tf.contrib.layers.l2_regularizer(self.lamda)assert dnn_layers[-1] == 1self._build_graph()def _build_graph(self):self.add_input()self.inference()def add_input(self):self.x = [tf.placeholder(tf.float32, name='input_x_%d'%i) for i in range(self.field_num)]self.y = tf.placeholder(tf.float32, shape=[None], name='input_y')self.is_train = tf.placeholder(tf.bool)def inference(self):with tf.variable_scope('fm_part'):emb = [tf.get_variable(name='emb_%d'%i, shape=[self.field_lens[i], self.vec_dim], dtype=tf.float32, regularizer=self.l2_reg) for i in range(self.field_num)]emb_layer = tf.concat([tf.matmul(self.x[i], emb[i]) for i in range(self.field_num)], axis=1)x = emb_layerin_node = self.field_num * self.vec_dimwith tf.variable_scope('dnn_part'):for i in range(len(self.dnn_layers)):out_node = self.dnn_layers[i]w = tf.get_variable(name='w_%d'%i, shape=[in_node, out_node], dtype=tf.float32, regularizer=self.l2_reg)b = tf.get_variable(name='b_%d'%i, shape=[out_node], dtype=tf.float32)x = tf.matmul(x, w) + bif out_node == 1:self.y_logits = xelse:x = tf.layers.dropout(tf.nn.relu(x), rate=self.dropout_rate, training=self.is_train)in_node = out_nodeself.y_hat = tf.nn.sigmoid(self.y_logits)self.pred_label = tf.cast(self.y_hat > 0.5, tf.int32)self.loss = -tf.reduce_mean(self.y*tf.log(self.y_hat+1e-8) + (1-self.y)*tf.log(1-self.y_hat+1e-8))reg_variables = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)if len(reg_variables) > 0:self.loss += tf.add_n(reg_variables)self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
reference
[1] Zhang, Weinan, Tianming Du, and Jun Wang. "Deep learning over multi-field categorical data." European conference on information retrieval. Springer, Cham, 2016.
知识分享
个人知乎专栏:https://zhuanlan.zhihu.com/c_1164954275573858304
欢迎关注微信公众号:SOTA Lab
专注知识分享,不定期更新计算机、金融类文章

推荐系统系列(三):FNN理论与实践的更多相关文章
- 慢牛系列三:React Native实践
上次发布了我的慢牛股票APP之后,有园友反馈有点卡,这个APP是基于Sencha Touch + Cordova开发的,Sencha本身是一个比较重的框架,在Chrome里运行性能还是不错的,但是在A ...
- 计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践
计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践 2018年06月13日 16:38:11 轻春 阅读数 6004更多 分类专栏: 机器学习 机器学习荐货情报局 版 ...
- 推荐系统系列(四):PNN理论与实践
背景 上一篇文章介绍了FNN [2],在FM的基础上引入了DNN对特征进行高阶组合提高模型表现.但FNN并不是完美的,针对FNN的缺点上交与UCL于2016年联合提出一种新的改进模型PNN(Produ ...
- Java 理论与实践: 流行的原子——新原子类是 java.util.concurrent 的隐藏精华(转载)
简介: 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 java.util.concurrent 中添加原子变量类之后,这种情况发生了变化.请跟随并 ...
- DDD(领域驱动设计)理论结合实践
DDD(领域驱动设计)理论结合实践 写在前面 插一句:本人超爱落网-<平凡的世界>这一期,分享给大家. 阅读目录: 关于DDD 前期分析 框架搭建 代码实现 开源-发布 后记 第一次听 ...
- 高翔《视觉SLAM十四讲》从理论到实践
目录 第1讲 前言:本书讲什么:如何使用本书: 第2讲 初始SLAM:引子-小萝卜的例子:经典视觉SLAM框架:SLAM问题的数学表述:实践-编程基础: 第3讲 三维空间刚体运动 旋转矩阵:实践-Ei ...
- Java 理论与实践: 修复 Java 内存模型,第 2 部分(转载)
在 JSR 133 中 JMM 会有什么改变? 活跃了将近三年的 JSR 133,近期发布了关于如何修复 Java 内存模型(Java Memory Model, JMM)的公开建议.在本系列文章的 ...
- Java 理论与实践: 流行的原子
Java 理论与实践: 流行的原子 新原子类是 java.util.concurrent 的隐藏精华 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 ...
- ARM NEON指令集优化理论与实践
ARM NEON指令集优化理论与实践 一.简介 NEON就是一种基于SIMD思想的ARM技术,相比于ARMv6或之前的架构,NEON结合了64-bit和128-bit的SIMD指令集,提供128-bi ...
随机推荐
- 怎样设置 MySQL 远程连接
允许用户 root 在 任何IP 上都可以远程连接 所有 mysql数据库 并具有操作数据库的 所有权限, 密码为: myPassword mysql -u root -p grant all PRI ...
- 怎样理解 Vue 项目的目录结构?
Vue 项目的目录结构如下, 我们将会在后面逐个去了解它们的作用: 01. build - 存储项目构建相关的代码, 比如 webpack. 02. config - Vue 的配置目录,包括端口 ...
- docker-compose.yml 部署Nginx、Java项目、MySQL、Redis
version: "3.7" services: nginx: image: nginx restart: always container_name: nginx environ ...
- UDP通信简单 小结
Android手机版和电脑版 效果图: 通过WiFi局域网 电脑和手机连接通信. 电脑版本和手机版本使用了相同的消息发送头协议, 可以相互接收消息. 若有做的不好的地方还希望大家指导一下. 1. 手机 ...
- linux mint ubuntu 安装virtualbox
安装虚拟机:virtualbox 1.打开终端而且切换到root帐号,然后输入安装命令: apt-get install virtualbox 2.安装推荐的软件包:(必须安装这个包.不然看不到应用程 ...
- JavaScript函数式编程——柯里化
柯里化原理 如何实现柯里化 柯里化的应用 一.柯里化原理 柯里化:在数学和计算机科学中,柯里化是一种使用多个参数的一个函数转换成一系列使用一个参数的函数的技术. 前端使用柯里化的用途主要就应该是简化代 ...
- Angular 开发环境搭建
Angular 是一款开源 JavaScript 框架,由Google 维护,用来协助单一页面应用程序运行的.它的目标是增强基于浏览器的应用,使开发和测试变得更加容易.目前最新的 Angular 版本 ...
- 简单聊聊服务发现(redis, zk,etcd, consul)(转载)
服务发现并没有怎样的高深莫测,它的原理再简单不过.只是市面上太多文章将服务发现的难度妖魔化,读者被绕的云里雾里,顿觉自己智商低下不敢高攀. 服务提供者是什么,简单点说就是一个HTTP服务器,提供了AP ...
- CentOS7.2安装Airflow
1 安装pip yum -y install epel-release yum install python-pip 2 更新pip pip install --upgrade pip pip ins ...
- C++实例 分解质因数
分解质因数: 每个合数都可以写成几个质数相乘的形式.其中每个质数都是这个合数的因数,叫做这个合数的分解质因数.分解质因数只针对合数. 分解质因数的算式叫短除法.求一个数分解质因数,要从最小的质数除起, ...