Spring框架是怎么解决Bean之间的循环依赖的 (转)
问题:
循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。如下图:

如何理解“依赖”呢,在Spring中有:
- 构造器循环依赖
- field属性注入循环依赖
直接上代码:
构造器循环依赖
@Service
public class A {
public A(B b) { }
} @Service
public class B {
public B(C c) {
}
} @Service
public class C {
public C(A a) { }
}
结果:项目启动失败,发现了一个cycle
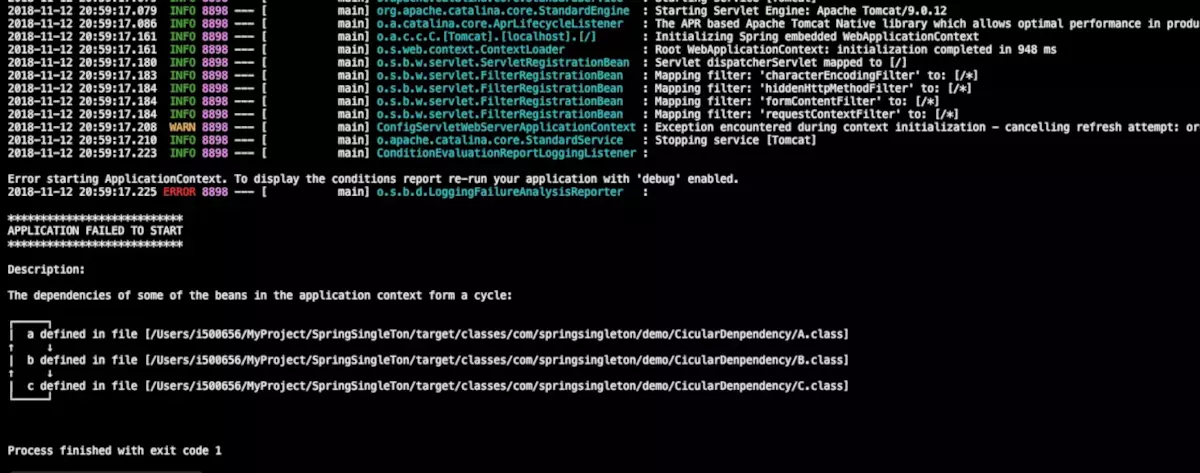
2.field属性注入循环依赖
@Service
public class A1 {
@Autowired
private B1 b1;
} @Service
public class B1 {
@Autowired
public C1 c1;
} @Service
public class C1 {
@Autowired public A1 a1;
}
结果:项目启动成功

3.field属性注入循环依赖(prototype)
@Service
@Scope("prototype")
public class A1 {
@Autowired
private B1 b1;
} @Service
@Scope("prototype")
public class B1 {
@Autowired
public C1 c1;
} @Service
@Scope("prototype")
public class C1 {
@Autowired public A1 a1;
}
结果:项目启动失败,发现了一个cycle。

现象总结:同样对于循环依赖的场景,构造器注入和prototype类型的属性注入都会初始化Bean失败。因为@Service默认是单例的,所以单例的属性注入是可以成功的。
我们先看看Spring在使用set方法注入时,是怎样实例化一个Bean和Bean的合作者的:

在A中有一个setB方法用来接收B对象的实例。那么Spring实例化A对象的过程如下:
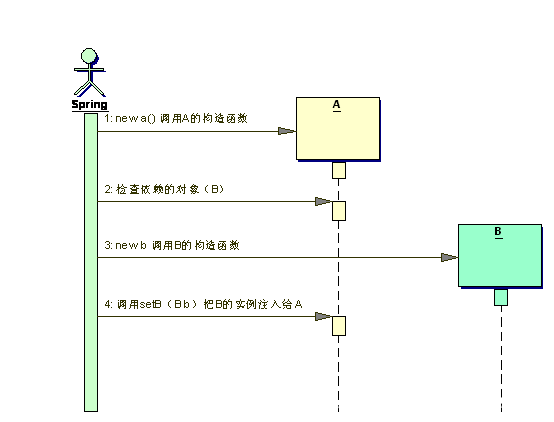
在不考虑Bean的初始化方法和一些Spring回调的情况下,Spring首先去调用A对象的构造函数实例化A,然后查找A依赖的对象本例子中是B(合作者)。一但找到合作者,Spring就会调用合作者(B)的构造函数实例化B。如果B还有依赖的对象Spring会把B上依赖的所有对象都按照相同的机制实例化然后调用A对象的setB(B b)把b对象注入给A。
因为Spring调用一个对象的set方法注入前,这个对象必须先被实例化。所以在"使用set方法注入"的情况下Spring会首先调用对象的构造函数。
我们在来看通过构造函数注入的过程:
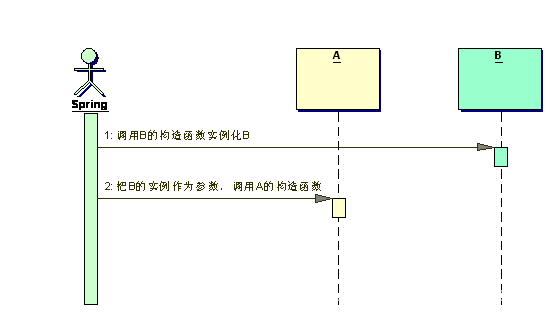
如果发现配置了对象的构造注入,那么Spring会在调用构造函数前把构造函数需要的依赖对象都实例化好,然后再把这些实例化后的对象作为参数去调用构造函数。
通过set方法注入的方式表达了2个对象间较弱的依赖关系:聚合关系。就像一辆车,如果没有车内音像车也时可以工作的。当你不要求合作者于自己被创建 时,“set方法注入”注入比较合适。
使用构造函数依赖注入时,Spring保证所有一个对象所有依赖的对象先实例化后,才实例化这个对象。(没有他们就没有我原则)
使用set方法依赖注入时,Spring首先实例化对象,然后才实例化所有依赖的对象。
Spring如何解决循环依赖
spring中循环依赖有三种情况:
1、构造器注入形成的循环依赖。也就是beanB需要在beanA的构造函数中完成初始化,beanA也需要在beanB的构造函数中完成舒适化,这种情况的结果就是两个bean都不能完成初始化,循环依赖难以解决。
2、setter注入构成的循环依赖。beanA需要在beanB的setter方法中完成初始化,beanB也需要在beanA的setter方法中完成初始化,spring设计的机制主要就是解决这种循环依赖,也是今天下文讨论的重点。
3、prototype作用域bean的循环依赖。这种循环依赖同样无法解决,因为spring不会缓存‘prototype’作用域的bean,而spring中循环依赖的解决正是通过缓存来实现的。
下面主要说明第二种情况中循环依赖的解决方案
步骤一:beanA进行初始化,并且将自己进行初始化的状态记录下来,并提前向外暴露一个单例工程方法,从而使其他bean能引用到该bean(可能读完这一句,您仍然心存疑惑,没关系,继续往下读)
步骤二:beanA中有beanB的依赖,于是开始初始化beanB。
步骤三:初始化beanB的过程中又发现beanB依赖了beanA,于是又进行beanA的初始化,这时发现beanA已经在进行初始化了,程序发现了存在的循环依赖,然后通过步骤一中暴露的单例工程方法拿到beanA的引用(注意,此时的beanA只是完成了构造函数的注入但为完成其他步骤),从而beanB拿到beanA的引用,完成注入,完成了初始化,如此beanB的引用也就可以被beanA拿到,从而beanA也就完成了初始化。
spring进行bean的加载的时候,首先进行bean的初始化(调用构造函数),然后进行属性填充。在这两步中间,spring对bean进行了一次状态的记录,也就是说spring会把指向只完成了构造函数初始化的bean的引用通过一个变量记录下来,明白这一点对之后的源码理解至关重要。
源码角度观看循环依赖的解决步骤
步骤一中首先进行beanA的创建
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
进入getSingleton中,spirng会记录当前beanA正在创建中
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
并且将注册一个工厂方法来解决循环依赖
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
这里: addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
主要就是addSingletonFactory,这句就完成了工厂方法的注册,这个方法可以返回一个只完成了构造函数初始化的beanA,也许大家想知道他是如何返回的,我们进入getEarlyBeanReference方法
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
可以看到这个方法中,除了对后处理器的调用,没有进行任何动作,而是直接返回了我们参数传入的bean,那么这个bean是哪来的呢?其实在这之前,spring先调用了beanA的构造函数,并拿到了只完成了构造函数初始化的一个实例,并把他记录了下来。
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper.getWrappedInstance();
这就是这个bean的由来。然后当我们进行到步骤三的时候,就会检查是否允许循环依赖(即使是Singleton类型的bean也可以通过参数设置,禁止循环依赖),如果允许的话,就会通过这个工厂方法拿到beanA的引用。从而完成beanA和beanB的加载。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
这里: singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
也可以看这篇 : Spring如何解决循环依赖的问题
在关于Spring的面试中,我们经常会被问到一个问题,就是Spring是如何解决循环依赖的问题的。这个问题算是关于Spring的一个高频面试题,因为如果不刻意研读,相信即使读过源码,面试者也不一定能够一下子思考出个中奥秘。本文主要针对这个问题,从源码的角度对其实现原理进行讲解。
1. 过程演示
关于Spring bean的创建,其本质上还是一个对象的创建,既然是对象,读者朋友一定要明白一点就是,一个完整的对象包含两部分:当前对象实例化和对象属性的实例化。在Spring中,对象的实例化是通过反射实现的,而对象的属性则是在对象实例化之后通过一定的方式设置的。这个过程可以按照如下方式进行理解:
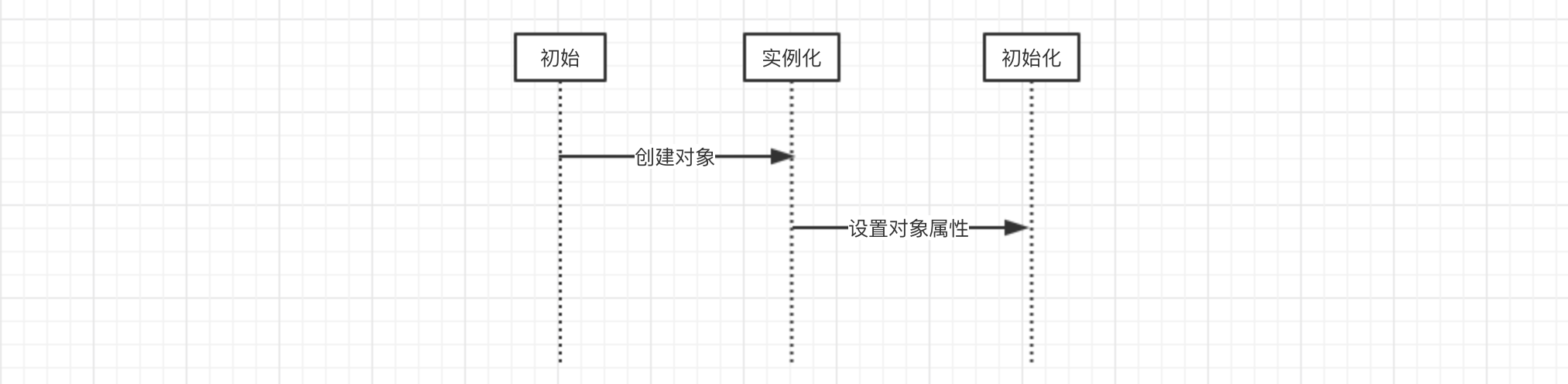
理解这一个点之后,对于循环依赖的理解就已经帮助一大步了,我们这里以两个类A和B为例进行讲解,如下是A和B的声明:
@Component
public class A { private B b; public void setB(B b) {
this.b = b;
}
}
@Component
public class B { private A a; public void setA(A a) {
this.a = a;
}
}
可以看到,这里A和B中各自都以对方为自己的全局属性。这里首先需要说明的一点是,Spring实例化bean是通过ApplicationContext.getBean()方法来进行的。如果要获取的对象依赖了另一个对象,那么其首先会创建当前对象,然后通过递归的调用ApplicationContext.getBean()方法来获取所依赖的对象,最后将获取到的对象注入到当前对象中。这里我们以上面的首先初始化A对象实例为例进行讲解。首先Spring尝试通过ApplicationContext.getBean()方法获取A对象的实例,由于Spring容器中还没有A对象实例,因而其会创建一个A对象,然后发现其依赖了B对象,因而会尝试递归的通过ApplicationContext.getBean()方法获取B对象的实例,但是Spring容器中此时也没有B对象的实例,因而其还是会先创建一个B对象的实例。读者需要注意这个时间点,此时A对象和B对象都已经创建了,并且保存在Spring容器中了,只不过A对象的属性b和B对象的属性a都还没有设置进去。在前面Spring创建B对象之后,Spring发现B对象依赖了属性A,因而此时还是会尝试递归的调用ApplicationContext.getBean()方法获取A对象的实例,因为Spring中已经有一个A对象的实例,虽然只是半成品(其属性b还未初始化),但其也还是目标bean,因而会将该A对象的实例返回。此时,B对象的属性a就设置进去了,然后还是ApplicationContext.getBean()方法递归的返回,也就是将B对象的实例返回,此时就会将该实例设置到A对象的属性b中。这个时候,注意A对象的属性b和B对象的属性a都已经设置了目标对象的实例了。读者朋友可能会比较疑惑的是,前面在为对象B设置属性a的时候,这个A类型属性还是个半成品。但是需要注意的是,这个A是一个引用,其本质上还是最开始就实例化的A对象。而在上面这个递归过程的最后,Spring将获取到的B对象实例设置到了A对象的属性b中了,这里的A对象其实和前面设置到实例B中的半成品A对象是同一个对象,其引用地址是同一个,这里为A对象的b属性设置了值,其实也就是为那个半成品的a属性设置了值。下面我们通过一个流程图来对这个过程进行讲解:
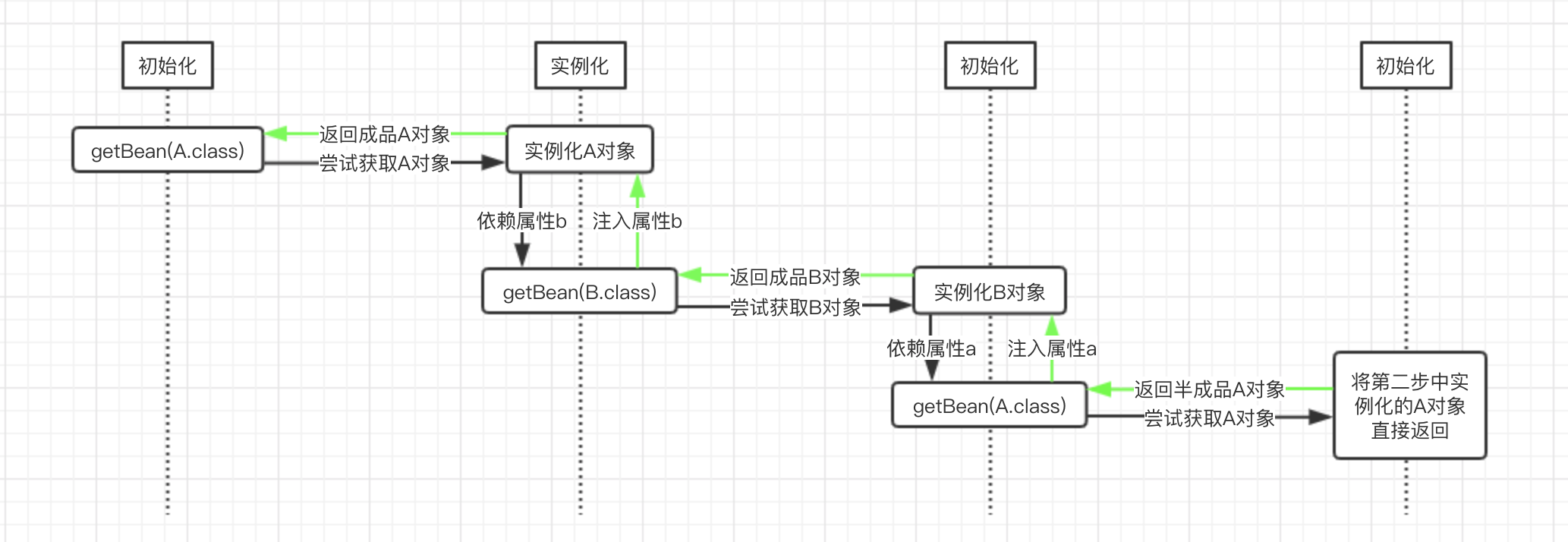
图中getBean()表示调用Spring的ApplicationContext.getBean()方法,而该方法中的参数,则表示我们要尝试获取的目标对象。图中的黑色箭头表示一开始的方法调用走向,走到最后,返回了Spring中缓存的A对象之后,表示递归调用返回了,此时使用绿色的箭头表示。从图中我们可以很清楚的看到,B对象的a属性是在第三步中注入的半成品A对象,而A对象的b属性是在第二步中注入的成品B对象,此时半成品的A对象也就变成了成品的A对象,因为其属性已经设置完成了。
2. 源码讲解
对于Spring处理循环依赖问题的方式,我们这里通过上面的流程图其实很容易就可以理解,需要注意的一个点就是,Spring是如何标记开始生成的A对象是一个半成品,并且是如何保存A对象的。这里的标记工作Spring是使用ApplicationContext的属性Set<String> singletonsCurrentlyInCreation来保存的,而半成品的A对象则是通过Map<String, ObjectFactory<?>> singletonFactories来保存的,这里的ObjectFactory是一个工厂对象,可通过调用其getObject()方法来获取目标对象。在AbstractBeanFactory.doGetBean()方法中获取对象的方法如下:
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
// 尝试通过bean名称获取目标bean对象,比如这里的A对象
Object sharedInstance = getSingleton(beanName); // 我们这里的目标对象都是单例的
if (mbd.isSingleton()) {
// 这里就尝试创建目标对象,第二个参数传的就是一个ObjectFactory类型的对象,这里是使用Java8的lamada
// 表达式书写的,只要上面的getSingleton()方法返回值为空,则会调用这里的getSingleton()方法来创建
// 目标对象
sharedInstance = getSingleton(beanName, () -> {
try {
// 尝试创建目标对象
return createBean(beanName, mbd, args);
} catch (BeansException ex) {
throw ex;
}
});
}
return (T) bean;
}
这里的doGetBean()方法是非常关键的一个方法(中间省略了其他代码),上面也主要有两个步骤,第一个步骤的getSingleton()方法的作用是尝试从缓存中获取目标对象,如果没有获取到,则尝试获取半成品的目标对象;如果第一个步骤没有获取到目标对象的实例,那么就进入第二个步骤,第二个步骤的getSingleton()方法的作用是尝试创建目标对象,并且为该对象注入其所依赖的属性。
这里其实就是主干逻辑,我们前面图中已经标明,在整个过程中会调用三次doGetBean()方法,第一次调用的时候会尝试获取A对象实例,此时走的是第一个getSingleton()方法,由于没有已经创建的A对象的成品或半成品,因而这里得到的是null,然后就会调用第二个getSingleton()方法,创建A对象的实例,然后递归的调用doGetBean()方法,尝试获取B对象的实例以注入到A对象中,此时由于Spring容器中也没有B对象的成品或半成品,因而还是会走到第二个getSingleton()方法,在该方法中创建B对象的实例,创建完成之后,尝试获取其所依赖的A的实例作为其属性,因而还是会递归的调用doGetBean()方法,此时需要注意的是,在前面由于已经有了一个半成品的A对象的实例,因而这个时候,再尝试获取A对象的实例的时候,会走第一个getSingleton()方法,在该方法中会得到一个半成品的A对象的实例。然后将该实例返回,并且将其注入到B对象的属性a中,此时B对象实例化完成。然后将实例化完成的B对象递归的返回,此时就会将该实例注入到A对象中,这样就得到了一个成品的A对象。我们这里可以阅读上面的第一个getSingleton()方法:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 尝试从缓存中获取成品的目标对象,如果存在,则直接返回
Object singletonObject = this.singletonObjects.get(beanName);
// 如果缓存中不存在目标对象,则判断当前对象是否已经处于创建过程中,在前面的讲解中,第一次尝试获取A对象
// 的实例之后,就会将A对象标记为正在创建中,因而最后再尝试获取A对象的时候,这里的if判断就会为true
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 这里的singletonFactories是一个Map,其key是bean的名称,而值是一个ObjectFactory类型的
// 对象,这里对于A和B而言,调用图其getObject()方法返回的就是A和B对象的实例,无论是否是半成品
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 获取目标对象的实例
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
这里我们会存在一个问题就是A的半成品实例是如何实例化的,然后是如何将其封装为一个ObjectFactory类型的对象,并且将其放到上面的singletonFactories属性中的。这主要是在前面的第二个getSingleton()方法中,其最终会通过其传入的第二个参数,从而调用createBean()方法,该方法的最终调用是委托给了另一个doCreateBean()方法进行的,这里面有如下一段代码:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException { // 实例化当前尝试获取的bean对象,比如A对象和B对象都是在这里实例化的
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
} // 判断Spring是否配置了支持提前暴露目标bean,也就是是否支持提前暴露半成品的bean
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences
&& isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 如果支持,这里就会将当前生成的半成品的bean放到singletonFactories中,这个singletonFactories
// 就是前面第一个getSingleton()方法中所使用到的singletonFactories属性,也就是说,这里就是
// 封装半成品的bean的地方。而这里的getEarlyBeanReference()本质上是直接将放入的第三个参数,也就是
// 目标bean直接返回
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
} try {
// 在初始化实例之后,这里就是判断当前bean是否依赖了其他的bean,如果依赖了,
// 就会递归的调用getBean()方法尝试获取目标bean
populateBean(beanName, mbd, instanceWrapper);
} catch (Throwable ex) {
// 省略...
} return exposedObject;
}
到这里,Spring整个解决循环依赖问题的实现思路已经比较清楚了。对于整体过程,读者朋友只要理解两点:
- Spring是通过递归的方式获取目标bean及其所依赖的bean的;
- Spring实例化一个bean的时候,是分两步进行的,首先实例化目标bean,然后为其注入属性。
结合这两点,也就是说,Spring在实例化一个bean的时候,是首先递归的实例化其所依赖的所有bean,直到某个bean没有依赖其他bean,此时就会将该实例返回,然后反递归的将获取到的bean设置为各个上层bean的属性的。
3. 小结
本文首先通过图文的方式对Spring是如何解决循环依赖的问题进行了讲解,然后从源码的角度详细讲解了Spring是如何实现各个bean的装配工作的。
出处:
https://cloud.tencent.com/developer/article/1455953
https://www.jianshu.com/p/8bb67ca11831
另一篇文章关于Spring的循环依赖分析: 图解Spring解决循环依赖
前言
Spring如何解决的循环依赖,是近两年流行起来的一道Java面试题。
其实笔者本人对这类框架源码题还是持一定的怀疑态度的。
如果笔者作为面试官,可能会问一些诸如“如果注入的属性为null,你会从哪几个方向去排查”这些场景题。
那么既然写了这篇文章,闲话少说,发车看看Spring是如何解决的循环依赖,以及带大家看清循环依赖的本质是什么。
正文
通常来说,如果问Spring内部如何解决循环依赖,一定是单默认的单例Bean中,属性互相引用的场景。
比如几个Bean之间的互相引用:
甚至自己“循环”依赖自己:
先说明前提:原型(Prototype)的场景是不支持循环依赖的,通常会走到AbstractBeanFactory类中下面的判断,抛出异常。
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
原因很好理解,创建新的A时,发现要注入原型字段B,又创建新的B发现要注入原型字段A...
这就套娃了, 你猜是先StackOverflow还是OutOfMemory?
Spring怕你不好猜,就先抛出了BeanCurrentlyInCreationException
基于构造器的循环依赖,就更不用说了,官方文档都摊牌了,你想让构造器注入支持循环依赖,是不存在的,不如把代码改了。
那么默认单例的属性注入场景,Spring是如何支持循环依赖的?
Spring解决循环依赖
首先,Spring内部维护了三个Map,也就是我们通常说的三级缓存。
笔者翻阅Spring文档倒是没有找到三级缓存的概念,可能也是本土为了方便理解的词汇。
在Spring的DefaultSingletonBeanRegistry类中,你会赫然发现类上方挂着这三个Map:
singletonObjects 它是我们最熟悉的朋友,俗称“单例池”“容器”,缓存创建完成单例Bean的地方。
singletonFactories 映射创建Bean的原始工厂
earlySingletonObjects 映射Bean的早期引用,也就是说在这个Map里的Bean不是完整的,甚至还不能称之为“Bean”,只是一个Instance.
后两个Map其实是“垫脚石”级别的,只是创建Bean的时候,用来借助了一下,创建完成就清掉了。
所以笔者前文对“三级缓存”这个词有些迷惑,可能是因为注释都是以Cache of开头吧。
为什么成为后两个Map为垫脚石,假设最终放在singletonObjects的Bean是你想要的一杯“凉白开”。
那么Spring准备了两个杯子,即singletonFactories和earlySingletonObjects来回“倒腾”几番,把热水晾成“凉白开”放到singletonObjects中。
闲话不说,都浓缩在图里。
上面的是一张GIF,如果你没看到可能还没加载出来。三秒一帧,不是你电脑卡。
笔者画了17张图简化表述了Spring的主要步骤,GIF上方即是刚才提到的三级缓存,下方展示是主要的几个方法。
当然了,这个地步你肯定要结合Spring源码来看,要不肯定看不懂。
如果你只是想大概了解,或者面试,可以先记住笔者上文提到的“三级缓存”,以及下文即将要说的本质。
循环依赖的本质
上文了解完Spring如何处理循环依赖之后,让我们跳出“阅读源码”的思维,假设让你实现一个有以下特点的功能,你会怎么做?
- 将指定的一些类实例为单例
- 类中的字段也都实例为单例
- 支持循环依赖
举个例子,假设有类A:
public class A {
private B b;
}
类B:
public class B {
private A a;
}
说白了让你模仿Spring:假装A和B是被@Component修饰,
并且类中的字段假装是@Autowired修饰的,处理完放到Map中。
其实非常简单,笔者写了一份粗糙的代码,可供参考:
import java.lang.reflect.Field;
import java.util.HashMap;
import java.util.Map; public class SpringTest { private static Map<String, Object> cacheMap = new HashMap<String, Object>(2); public static void main(String[] args) throws Exception {
// 假装扫描出来的对象
Class[] classes = {A.class, B.class}; for(Class aClass : classes) {
getBean(aClass);
} // check
System.out.println(getBean(B.class).getA() == getBean(A.class));
System.out.println(getBean(A.class).getB() == getBean(B.class));
} private static <T> T getBean(Class<T> beanClass) throws Exception{
// 本文用类名小写 简单代替bean的命名规则
String beanName = beanClass.getSimpleName().toLowerCase(); // 如果已经是一个bean,则直接返回
if (cacheMap.containsKey(beanName)) {
return (T) cacheMap.get(beanName);
} // 将对象本身实例化
Object object = beanClass.getDeclaredConstructor().newInstance(); // 放入缓存
cacheMap.put(beanName, object); // 把所有字段当成需要注入的bean,创建并注入到当前bean中
Field[] fields = object.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
// 获取需要注入字段的class
Class<?> fieldClass = field.getType();
String fieldBeanName = fieldClass.getSimpleName().toLowerCase(); // 如果需要注入的bean,已经在缓存Map中,那么把缓存Map中的值注入到该field即可
// 如果缓存没有 继续创建
field.set(object, cacheMap.containsKey(fieldBeanName)
? cacheMap.get(fieldBeanName) : getBean(fieldClass));
}
// 属性填充完成,返回
return (T) object;
} } class A {
private B b; public B getB() {
return b;
} public void setB(B b) {
this.b = b;
} } class B {
private A a; public A getA() {
return a;
} public void setA(A a) {
this.a = a;
}
}
这段代码的效果,其实就是处理了循环依赖,并且处理完成后,cacheMap中放的就是完整的“Bean”了
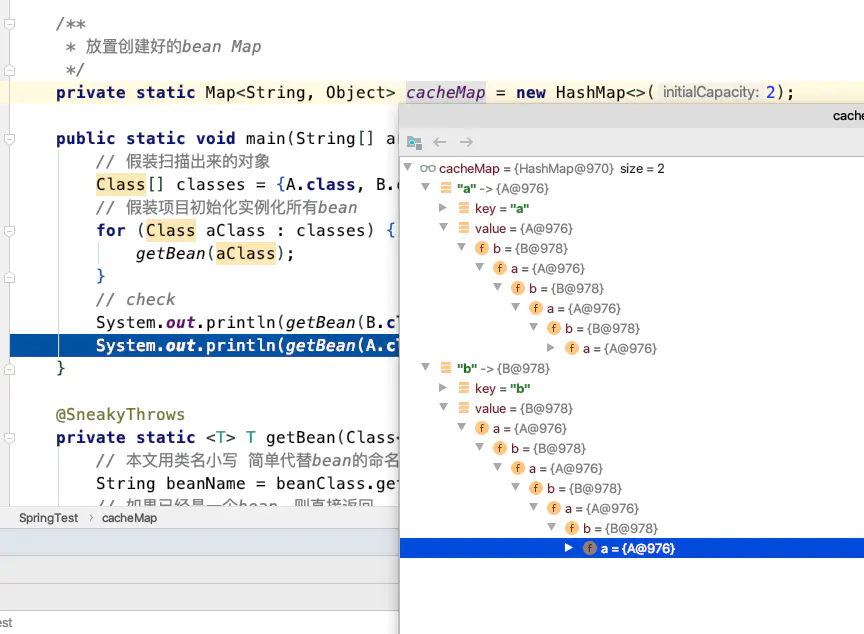
这就是“循环依赖”的本质,而不是“Spring如何解决循环依赖”。
之所以要举这个例子,是发现一小部分盆友陷入了“阅读源码的泥潭”,而忘记了问题的本质。
为了看源码而看源码,结果一直看不懂,却忘了本质是什么。
如果真看不懂,不如先写出基础版本,逆推Spring为什么要这么实现,可能效果会更好。
what?问题的本质居然是two sum!
看完笔者刚才的代码有没有似曾相识?没错,和two sum的解题是类似的。
不知道two sum是什么梗的,笔者和你介绍一下:
two sum是刷题网站leetcode序号为1的题,也就是大多人的算法入门的第一题。
常常被人调侃,有算法面的公司,被面试官钦定了,合的来。那就来一道two sum走走过场。
问题内容是:给定一个数组,给定一个数字。返回数组中可以相加得到指定数字的两个索引。
比如:给定nums = [2, 7, 11, 15], target = 9
那么要返回 [0, 1],因为2 + 7 = 9
这道题的优解是,一次遍历+HashMap:
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement)) {
return new int[] { map.get(complement), i };
}
map.put(nums[i], i);
}
throw new IllegalArgumentException("No two sum solution");
}
}
先去Map中找需要的数字,没有就将当前的数字保存在Map中,如果找到需要的数字,则一起返回。
和笔者上面的代码是不是一样?
先去缓存里找Bean,没有则实例化当前的Bean放到Map,如果有需要依赖当前Bean的,就能从Map取到。
结尾
如果你是上文笔者提到的“陷入阅读源码的泥潭”的读者,上文应该可以帮助到你。
可能还有盆友有疑问,为什么一道“two-sum”,Spring处理的如此复杂?
这个想想Spring支持多少功能就知道了,各种实例方式..各种注入方式..各种Bean的加载,校验..各种callback,aop处理等等..
Spring可不只有依赖注入,同样Java也不仅是Spring。如果我们陷入了某个“牛角尖”,不妨跳出来看看,可能会更佳清晰哦。
Spring框架是怎么解决Bean之间的循环依赖的 (转)的更多相关文章
- Spring解决bean之间的循环依赖
转自链接:https://blog.csdn.net/lyc_liyanchao/article/details/83099675通过前几节的分析,已经成功将bean实例化,但是大家一定要将bean的 ...
- Spring里bean之间的循环依赖解决与源码解读
通过前几节的分析,已经成功将bean实例化,但是大家一定要将bean的实例化和完成bean的创建区分开,bean的实例化仅仅是获得了bean的实例,该bean仍在继续创建之中,之后在该bean实例的基 ...
- Spring框架(3)---IOC装配Bean(注解方式)
IOC装配Bean(注解方式) 上面一遍文章讲了通过xml来装配Bean,那么这篇来讲注解方式来讲装配Bean对象 注解方式需要在原先的基础上重新配置环境: (1)Component标签举例 1:导入 ...
- Spring Ioc源码分析系列--自动注入循环依赖的处理
Spring Ioc源码分析系列--自动注入循环依赖的处理 前言 前面的文章Spring Ioc源码分析系列--Bean实例化过程(二)在讲解到Spring创建bean出现循环依赖的时候并没有深入去分 ...
- Spring框架知识总结-注入Bean的各类异常
近日整合sping和hibernate框架时遇到了一系列的异常,本次主要说明一下spring框架可能出现的异常及解决方案. 我们借助sping强大的bean容器管理机制,通过BeanFactory轻松 ...
- Spring框架几种创建bean的方式
Spring框架下,Bean的创建和装配非常的灵活,提供了三种主要的方式,并且相互见可以互相看见,也就是你可以随意地采用你喜欢且合适的方式创建Bean,而不用担心他们之间的兼容问题. 一.使用XML显 ...
- Spring框架(2)---IOC装配Bean(xml配置方式)
IOC装配Bean (1)Spring框架Bean实例化的方式提供了三种方式实例化Bean 构造方法实例化(默认无参数,用的最多) 静态工厂实例化 实例工厂实例化 下面先写这三种方法的applicat ...
- Spring 框架基础(02):Bean的生命周期,作用域,装配总结
本文源码:GitHub·点这里 || GitEE·点这里 一.装配方式 Bean的概念:Spring框架管理的应用程序中,由Spring容器负责创建,装配,设置属性,进而管理整个生命周期的对象,称为B ...
- Spring对加载的bean之间循环依赖的处理
根据下面文档的叙述,简言之: 对于相互之间通过构造函数注入相互循环依赖的情况,Spring会抛出BeanCurrentlyInCreationException错误. 如果AB两个beans是通过属性 ...
随机推荐
- 教程:myeclipse在线安装svn插件
SVN 版本控制,相信开发过程中都很多有用到,今天在myeclipse 在线安装了SVN插件.下面是具体步骤,记录下,希望对有需要的朋友提供帮助. 要求: Myeclispe,电脑能连接互联网 步骤: ...
- MERGE INTO 解决大数据量复杂操作更新慢的问题
现我系统中有一条复杂SQL,由于业务复杂需要关联人员的工作离职三个表,并进行分支判断,再计算人员的字段信息,由于人员多,分支多,计算复杂等原因,一次执行需要5min,容易卡死,现在使用MERGE IN ...
- canvas基础知识点(一)
给canvas设置宽高: canvas标签的宽高默认是300*150,是一个行内块元素 可以在canvas标签上通过width,height来设置 可以在js中给dom对象设置: mycanvas.w ...
- python 购物车+用户认证程序
创建文件a.txt,b.txt.c.txt用于存放应该持续保存的信息 a.txt :用户密码输入错误3次就锁定 b.txt :购物时的活动,每个用户只能参与一次 c:txt :购物完后的发票在这里查看 ...
- centos的KVM初级安装
什么是KVM虚拟化技术?KVM(Kernel-based Virtual Machine),主流虚拟化技术之一,集成与Linux2.6之后版本中,通过linux内核提供任务调度及管理.kvm,在实现虚 ...
- Linux性能分析之上下文切换
而在每个任务运行前,CPU 都需要知道任务从哪里加载.又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器 CPU 寄存器,是 CPU 内置的容量小.但速度极快的内存.而程序 ...
- 阶段3 3.SpringMVC·_03.SpringMVC常用注解_7 ModelAttribute注解
这个注解可以作用在方法上,也可以作用在参数上 演示 user里面有三个属性, 表单只提交了两个属性.缺少了date属性 date没有获取到值因为也没提交这个值. 下面返回的user对象.上面就会拿到 ...
- 对js原型对象、实例化对象及prototype属性的一些见解
什么是原型对象? 请看下面的代码,我们以各种姿势,创建了几个方法! function fn1() { } var fn2 = function () { } var fn3 = new Functio ...
- Spring体系
1.Spring简介 Spring是一个轻量级Java开发框架,最早有Rod Johnson创建,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题.它是一个分层的JavaSE/JavaEE ...
- ORACLE 更新 和 插入多条 数据
--插入语句INSERT INTO OA_W_BAOXIAOMXYWB (ID,DONGTAITABLEPARENTSN,CHANPINNAMEGKFK,CHANPINJITIGKFK,CHANPIN ...