Java后端技术面试汇总(第一套)
面试汇总,整理一波,doc文档可点击【此处下载】
1、基础篇
1.1、Java基础
• 面向对象的特征:继承、封装和多态
• final, finally, finalize 的区别
• Exception、Error、运行时异常与一般异常有何异同
• 请写出5种常见到的runtime exception
常见的几种如下:
NullPointerException - 空指针引用异常
ClassCastException - 类型强制转换异常。
IllegalArgumentException - 传递非法参数异常。
ArithmeticException - 算术运算异常
ArrayStoreException - 向数组中存放与声明类型不兼容对象异常
IndexOutOfBoundsException - 下标越界异常
NegativeArraySizeException - 创建一个大小为负数的数组错误异常
NumberFormatException - 数字格式异常
SecurityException - 安全异常
UnsupportedOperationException - 不支持的操作异常• int 和 Integer 有什么区别,Integer的值缓存范围
-128到127• 包装类,装箱和拆箱
• String、StringBuilder、StringBuffer
• 重载和重写的区别
• 抽象类和接口有什么区别
• 说说反射的用途及实现
• 说说自定义注解的场景及实现
• HTTP请求的GET与POST方式的区别
• Session与Cookie区别
• 列出自己常用的JDK包
java.lang: 这个是系统的基础类,比如String等都是这里面的,这个package是唯一一个可以不用import就可以使用的Package
java.io: 这里面是所有输入输出有关的类,比如文件操作等
java.net: 这里面是与网络有关的类,比如URL,URLConnection等。
java.util : 这个是系统辅助类,特别是集合类Collection,List,Map等。
java.sql: 这个是数据库操作的类,Connection, Statememt,ResultSet等• MVC设计思想
• equals与==的区别
• hashCode和equals方法的区别与联系
• 什么是Java序列化和反序列化,如何实现Java序列化?或者请解释Serializable 接口的作用
• Object类中常见的方法,为什么wait notify会放在Object里边?
这是个设计相关的问题。
回答这些问题要说明为什么把这些方法放在Object类里是有意义的,还有不把它放在Thread类里的原因。
一个很明显的原因是JAVA提供的锁是对象级而不是线程级的,每个对象都有锁,通过线程获得。如果线程需要等待某些锁那么调用对象中的wait()方法就有意义了。如果wait()方法定义在Thread类中,线程正在等待的是哪个锁就不明显了。简单的说,由于wait,notify和notifyAll都是锁级别的操作,所以把他们定义在Object类中因为锁属于对象。• Java的平台无关性如何体现出来的
• JDK和JRE的区别
• Java 8有哪些新特性(What's New in JDK 8)
Java8 新增了非常多的特性:
1. Lambda 表达式 − Lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中。
2. 方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
3. 默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
4. 新工具 − 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。
5. Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
6. Date Time API − 加强对日期与时间的处理。
7. Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
8. Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。1.2、Java常见集合
• List 和 Set 区别
• Set和hashCode以及equals方法的联系
• List 和 Map 区别
• Arraylist 与 LinkedList 区别
• ArrayList 与 Vector 区别
• HashMap 和 Hashtable 的区别
• HashSet 和 HashMap 区别
• HashMap 和 ConcurrentHashMap 的区别
• HashMap 的工作原理及代码实现,什么时候用到红黑树
• 多线程情况下HashMap死循环的问题
• HashMap出现Hash DOS攻击的问题
• ConcurrentHashMap 的工作原理及代码实现,如何统计所有的元素个数
• 手写简单的HashMap
• 看过那些Java集合类的源码
1.3、进程和线程
• 线程和进程的概念、并行和并发的概念
Erlang 之父 Joe Armstrong 用一张5岁小孩都能看懂的图解释了并发与并行的区别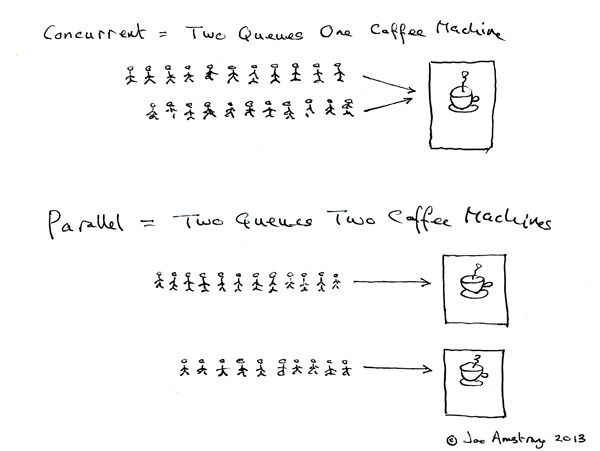
并发是两个队列交替使用一台咖啡机,并行是两个队列同时使用两台咖啡机,如果串行,一个队列使用一台咖啡机,那么哪怕前面那个人便秘了去厕所呆半天,后面的人也只能死等着他回来才能去接咖啡,这效率无疑是最低的。
并发是不是一个线程,并行是多个线程?
答:并发和并行都可以是很多个线程,就看这些线程能不能同时被(多个)cpu执行,如果可以就说明是并行,而并发是多个线程被(一个)cpu 轮流切换着执行。
• 创建线程的方式及实现
• 进程间通信的方式
常见的通信方式:
1. 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2. 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
4. 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5. 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
6. 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
7. 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
8. 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。• 说说 CountDownLatch、CyclicBarrier 原理和区别
• 说说 Semaphore 原理
• 说说 Exchanger 原理
• ThreadLocal 原理分析,ThreadLocal为什么会出现OOM,出现的深层次原理
线程池的一个线程使用完ThreadLocal对象之后,再也不用,由于线程池中的线程不会退出,线程池中的线程的存在,同时ThreadLocal变量也会存在,占用内存!造成OOM溢出!
ThreadLocal的实现是这样的:每个Thread 维护一个 ThreadLocalMap 映射表,这个映射表的 key 是 ThreadLocal实例本身,value 是真正需要存储的 Object。
也就是说 ThreadLocal 本身并不存储值,它只是作为一个 key 来让线程从 ThreadLocalMap 获取 value。值得注意的是图中的虚线,表示 ThreadLocalMap 是使用 ThreadLocal 的弱引用作为 Key 的,弱引用的对象在 GC 时会被回收。
ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用来引用它,那么系统 GC 的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
总的来说就是,ThreadLocal里面使用了一个存在弱引用的map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例。这个Map的确使用了弱引用,不过弱引用只是针对key。每个key都弱引用指向threadlocal。 当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收。
但是,我们的value却不能回收,而这块value永远不会被访问到了,所以存在着内存泄露。
参考:https://blog.csdn.net/bntx2jsqfehy7/article/details/78315161• 讲讲线程池的实现原理
java线程池的实现原理说白了就是一个线程集合workerSet和一个阻塞队列workQueue。当用户向线程池提交一个任务(也就是线程)时,线程池会先将任务放入workQueue中。workerSet中的线程会不断的从workQueue中获取线程然后执行。当workQueue中没有任务的时候,worker就会阻塞,直到队列中有任务了就取出来继续执行。
线程池的几个主要参数的作用
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize: 规定线程池有几个线程(worker)在运行。(the number of threads to keep in the pool, even if they are idle, unless {@code allowCoreThreadTimeOut} is set)
maximumPoolSize: 当workQueue满了,不能添加任务的时候,这个参数才会生效。规定线程池最多只能有多少个线程(worker)在执行。(the maximum number of threads to allow in the pool)
keepAliveTime: 超出corePoolSize大小的那些线程的生存时间,这些线程如果长时间没有执行任务并且超过了keepAliveTime设定的时间,就会消亡。(when the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating.)
unit: 生存时间对于的单位(the time unit for the {@code keepAliveTime} argument)
workQueue: 存放任务的队列(the queue to use for holding tasks before they are executed. This queue will hold only the {@code Runnable} tasks submitted by the {@code execute} method.)
threadFactory: 创建线程的工厂(the factory to use when the executor creates a new thread)
handler: 当workQueue已经满了,并且线程池线程数已经达到maximumPoolSize,将执行拒绝策略。(the handler to use when execution is blocked because the thread bounds and queue capacities are reached)
任务提交后的流程分析
用户通过submit提交一个任务。线程池会执行如下流程:
1. 判断当前运行的worker数量是否超过corePoolSize,如果不超过corePoolSize。就创建一个worker直接执行该任务。—— 线程池最开始是没有worker在运行的
2. 如果正在运行的worker数量超过或者等于corePoolSize,那么就将该任务加入到workQueue队列中去。
3. 如果workQueue队列满了,也就是offer方法返回false的话,就检查当前运行的worker数量是否小于maximumPoolSize,如果小于就创建一个worker直接执行该任务。
4. 如果当前运行的worker数量是否大于等于maximumPoolSize,那么就执行RejectedExecutionHandler来拒绝这个任务的提交。
• 线程池的几种实现方式
• 线程的生命周期,状态是如何转移的
• 可参考:《Java多线程编程核心技术》
1.4、锁机制
• 说说线程安全问题,什么是线程安全,如何保证线程安全
与锁类似的是同步方法或者同步代码块。使用非静态同步方法时,锁住的是当前实例;使用静态同步方法时,锁住的是该类的Class对象;使用静态代码块时,锁住的是synchronized关键字后面括号内的对象• 重入锁的概念,重入锁为什么可以防止死锁
可重入锁,指的是以线程为单位,当一个线程获取对象锁之后,这个线程可以再次获取本对象上的锁,而其他的线程是不可以的。
synchronized 和 ReentrantLock 都是可重入锁。
可重入锁的意义之一在于防止死锁。
实现原理实现是通过为每个锁关联一个请求计数器和一个占有它的线程。当计数为0时,认为锁是未被占有的;线程请求一个未被占有的锁时,JVM将记录锁的占有者,并且将请求计数器置为1 。
如果同一个线程再次请求这个锁,计数器将递增;
每次占用线程退出同步块,计数器值将递减。直到计数器为0,锁被释放。• 产生死锁的四个条件(互斥、请求与保持、不剥夺、循环等待)
• 如何检查死锁(通过jConsole检查死锁)
• volatile 实现原理(禁止指令重排、刷新内存)
• synchronized 实现原理(对象监视器)
• synchronized 与 lock 的区别
两者区别:
1.首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
2.synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
3.synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
4.用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
5.synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可)
6.Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。• AQS同步队列
• CAS无锁的概念、乐观锁和悲观锁
• 常见的原子操作类
• 什么是ABA问题,出现ABA问题JDK是如何解决的
• 乐观锁的业务场景及实现方式
• Java 8并法包下常见的并发类
• 偏向锁、轻量级锁、重量级锁、自旋锁的概念
偏向锁
偏向锁是Java 6之后加入的新锁,它是一种针对加锁操作的优化手段,经过研究发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了减少同一线程获取锁(会涉及到一些CAS操作,耗时)的代价而引入偏向锁。偏向锁的核心思想是,如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,即获取锁的过程,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能。所以,对于没有锁竞争的场合,偏向锁有很好的优化效果,毕竟极有可能连续多次是同一个线程申请相同的锁。但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
轻量级锁
倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的),此时Mark Word 的结构也变为轻量级锁的结构。轻量级锁能够提升程序性能的依据是“对绝大部分的锁,在整个同步周期内都不存在竞争”,注意这是经验数据。需要了解的是,轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间访问同一锁的场合,就会导致轻量级锁膨胀为重量级锁。
重量级锁
内置锁在Java中被抽象为监视器锁(monitor)。在JDK 1.6之前,监视器锁可以认为直接对应底层操作系统中的互斥量(mutex)。这种同步方式的成本非常高,包括系统调用引起的内核态与用户态切换、线程阻塞造成的线程切换等。因此,后来称这种锁为“重量级锁”
自旋锁
轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。这是基于在大多数情况下,线程持有锁的时间都不会太长,如果直接挂起操作系统层面的线程可能会得不偿失,毕竟操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,因此自旋锁会假设在不久将来,当前的线程可以获得锁,因此虚拟机会让当前想要获取锁的线程做几个空循环(这也是称为自旋的原因),一般不会太久,可能是50个循环或100循环,在经过若干次循环后,如果得到锁,就顺利进入临界区。如果还不能获得锁,那就会将线程在操作系统层面挂起,这就是自旋锁的优化方式,这种方式确实也是可以提升效率的。最后没办法也就只能升级为重量级锁了。
• 可参考:《Java多线程编程核心技术》
1.5、JVM
• JVM运行时内存区域划分
• 内存溢出OOM和堆栈溢出SOE的示例及原因、如何排查与解决
• 如何判断对象是否可以回收或存活
• 常见的GC回收算法及其含义
• 常见的JVM性能监控和故障处理工具类:jps、jstat、jmap、jinfo、jconsole等
• JVM如何设置参数
• JVM性能调优
• 类加载器、双亲委派模型、一个类的生命周期、类是如何加载到JVM中的
• 类加载的过程:加载、验证、准备、解析、初始化
• 强引用、软引用、弱引用、虚引用
• Java内存模型JMM
1.6、设计模式
• 常见的设计模式
• 设计模式的的六大原则及其含义
• 常见的单例模式以及各种实现方式的优缺点,哪一种最好,手写常见的单例模式
• 设计模式在实际场景中的应用
• Spring中用到了哪些设计模式
• MyBatis中用到了哪些设计模式
• 你项目中有使用哪些设计模式
• 说说常用开源框架中设计模式使用分析
• 动态代理很重要!!!
1.7、数据结构
• 树(二叉查找树、平衡二叉树、红黑树、B树、B+树)
• 深度有限算法、广度优先算法
• 克鲁斯卡尔算法、普林母算法、迪克拉斯算法
• 什么是一致性Hash及其原理、Hash环问题
https://blog.csdn.net/bntX2jSQfEHy7/article/details/79549368
一致性Hash算法是对2^32取模,将服务节点对2^32取模放入hash环上,然后将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
问题:
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题。
解决方法:
为了解决数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。• 常见的排序算法和查找算法:快排、折半查找、堆排序等
1.8、网络/IO基础
• BIO、NIO、AIO的概念
• 什么是长连接和短连接
• Http1.0和2.0相比有什么区别,可参考《Http 2.0》
• Https的基本概念
• 三次握手和四次挥手、为什么挥手需要四次
为什么要四次挥手呢
TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。TCP是全双工模式,这就意味着,当 Client 发出FIN报文段时,只是表示 Client 已经没有数据要发送了,
Client 告诉 Server,它的数据已经全部发送完毕了;但是,这个时候 Client 还是可以接受来自 Server 的数据;当 Server 返回ACK报文段时,表示它已经知道 Client 没有数据发送了,
但是 Server 还是可以发送数据到 Client 的;当 Server 也发送了FIN报文段时,这个时候就表示 Server 也没有数据要发送了,就会告诉 Client ,我也没有数据要发送了,
之后彼此就会愉快的中断这次TCP连接。如果要正确的理解四次分手的原理,就需要了解四次分手过程中的状态变化。• 从浏览器中输入URL到页面加载的发生了什么?可参考《从输入URL到页面加载发生了什么》
2、数据存储和消息队列
2.1、数据库
• MySQL 索引使用的注意事项
• DDL、DML、DCL分别指什么
• explain命令
• left join,right join,inner join
• 数据库事物ACID(原子性、一致性、隔离性、持久性)
Atomicity 原子性
Consistency 一致性
Isolation 隔离性
Durability 持久性• 事物的隔离级别(读未提交、读以提交、可重复读、可序列化读)
• 脏读、幻读、不可重复读
• 数据库的几大范式
• 数据库常见的命令
• 说说分库与分表设计
• 分库与分表带来的分布式困境与应对之策(如何解决分布式下的分库分表,全局表?)
• 说说 SQL 优化之道
• MySQL遇到的死锁问题、如何排查与解决
• 存储引擎的 InnoDB与MyISAM区别,优缺点,使用场景
• 索引类别(B+树索引、全文索引、哈希索引)、索引的原理
• 什么是自适应哈希索引(AHI)
• 为什么要用 B+tree作为MySQL索引的数据结构
• 聚集索引与非聚集索引的区别
• 遇到过索引失效的情况没,什么时候可能会出现,如何解决
• limit 20000 加载很慢怎么解决
• 如何选择合适的分布式主键方案
• 选择合适的数据存储方案
• 常见的几种分布式ID的设计方案
• 常见的数据库优化方案,在你的项目中数据库如何进行优化的
2.2、Redis
• Redis 有哪些数据类型,可参考《Redis常见的5种不同的数据类型详解》
• Redis 内部结构
• Redis 使用场景
• Redis 持久化机制,可参考《使用快照和AOF将Redis数据持久化到硬盘中》
• Redis 集群方案与实现
• Redis 为什么是单线程的?
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;• 缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级
缓存雪崩:所有缓存在同一时间内失效,所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决思路:
1、直接写个缓存刷新页面,上线时手工操作下;
2、数据量不大,可以在项目启动的时候自动进行加载;
3、定时刷新缓存;
• 使用缓存的合理性问题
• Redis常见的回收策略
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据2.3、消息队列
• 消息队列的使用场景
• 消息的重发补偿解决思路
• 消息的幂等性解决思路
• 消息的堆积解决思路
• 自己如何实现消息队列
• 如何保证消息的有序性
3、开源框架和容器
3.1、SSM/Servlet
• Servlet的生命周期
• 转发与重定向的区别
• BeanFactory 和 ApplicationContext 有什么区别
• Spring Bean 的生命周期
• Spring IOC 如何实现
• Spring中Bean的作用域,默认的是哪一个
• 说说 Spring AOP、Spring AOP 实现原理
• 动态代理(CGLib 与 JDK)、优缺点、性能对比、如何选择
• Spring 事务实现方式、事务的传播机制、默认的事务类别
• Spring 事务底层原理
• Spring事务失效(事务嵌套),JDK动态代理给Spring事务埋下的坑,可参考《JDK动态代理给Spring事务埋下的坑!》
• 如何自定义注解实现功能
• Spring MVC 运行流程
• Spring MVC 启动流程
• Spring 的单例实现原理
• Spring 框架中用到了哪些设计模式
• Spring 其他产品(Srping Boot、Spring Cloud、Spring Secuirity、Spring Data、Spring AMQP 等)
• 有没有用到Spring Boot,Spring Boot的认识、原理
• MyBatis的原理
https://www.cnblogs.com/luoxn28/p/6417892.html
https://blog.csdn.net/u014297148/article/details/78696096• 可参考《为什么会有Spring》
• 可参考《为什么会有Spring AOP》
3.2、Netty
• 为什么选择 Netty
• 说说业务中,Netty 的使用场景
• 原生的 NIO 在 JDK 1.7 版本存在 epoll bug
• 什么是TCP 粘包/拆包
TCP粘包:socket读取时,读到了实际意义上的两个或多个数据包的内容,同时将其作为一个数据包进行处理。
TCP拆包:socket读取时,没有完整地读取一个数据包,只读取一部分。• TCP粘包/拆包的解决办法
1.数据段定长处理,位数不足的空位补齐。
2.消息头+消息体,消息头中一般会包含消息体的长度,消息类型等信息,消息体为实际数据体。
3.特殊字符(如:回车符)作为消息数据的结尾,以实现消息数据的分段。
4.复杂的应用层协议,这种方式使用的相对较少,耦合了网络层与应用层。• Netty 线程模型
• 说说 Netty 的零拷贝
• Netty 内部执行流程
• Netty 重连实现
3.3、Tomcat
• Tomcat的基础架构(Server、Service、Connector、Container)
• Tomcat如何加载Servlet的
• Pipeline-Valve机制
• 可参考:《四张图带你了解Tomcat系统架构!》
4、分布式
4.1、Nginx
• 请解释什么是C10K问题或者知道什么是C10K问题吗?
• Nginx简介,可参考《Nginx简介》
• 正向代理和反向代理.
• Nginx几种常见的负载均衡策略
• Nginx服务器上的Master和Worker进程分别是什么
• 使用“反向代理服务器”的优点是什么?
4.2、分布式其他
• 谈谈业务中使用分布式的场景
• Session 分布式方案
• Session 分布式处理
• 分布式锁的应用场景、分布式锁的产生原因、基本概念
• 分布是锁的常见解决方案
• 分布式事务的常见解决方案
• 集群与负载均衡的算法与实现
• 说说分库与分表设计,可参考《数据库分库分表策略的具体实现方案》
• 分库与分表带来的分布式困境与应对之策
4.3、Dubbo
• 什么是Dubbo,可参考《Dubbo入门》
• 什么是RPC、如何实现RPC、RPC 的实现原理,可参考《基于HTTP的RPC实现》
• Dubbo中的SPI是什么概念
• Dubbo的基本原理、执行流程
5、微服务
5.1、微服务
• 前后端分离是如何做的?
• 微服务哪些框架
• Spring Could的常见组件有哪些?可参考《Spring Cloud概述》
• 领域驱动有了解吗?什么是领域驱动模型?充血模型、贫血模型
• JWT有了解吗,什么是JWT,可参考《前后端分离利器之JWT》
• 你怎么理解 RESTful
• 说说如何设计一个良好的 API
• 如何理解 RESTful API 的幂等性
• 如何保证接口的幂等性
• 说说 CAP 定理、BASE 理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写,BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。接下来我们着重对BASE中的三要素进行详细讲解。
基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性——但请注意,这绝不等价于系统不可用,以下两个就是“基本可用”的典型例子。
响应时间上的损失:正常情况下,一个在线搜索引擎需要0.5秒内返回给用户相应的查询结果,但由于出现异常(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据听不的过程存在延时。
最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性
亚马逊首席技术官Werner Vogels在于2008年发表的一篇文章中对最终一致性进行了非常详细的介绍。他认为最终一致性时一种特殊的弱一致性:系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问都能够胡渠道最新的值。同时,在没有发生故障的前提下,数据达到一致状态的时间延迟,取决于网络延迟,系统负载和数据复制方案设计等因素。
在实际工程实践中,最终一致性存在以下五类主要变种。
因果一致性:
因果一致性是指,如果进程A在更新完某个数据项后通知了进程B,那么进程B之后对该数据项的访问都应该能够获取到进程A更新后的最新值,并且如果进程B要对该数据项进行更新操作的话,务必基于进程A更新后的最新值,即不能发生丢失更新情况。与此同时,与进程A无因果关系的进程C的数据访问则没有这样的限制。
读己之所写:
读己之所写是指,进程A更新一个数据项之后,它自己总是能够访问到更新过的最新值,而不会看到旧值。也就是说,对于单个数据获取者而言,其读取到的数据一定不会比自己上次写入的值旧。因此,读己之所写也可以看作是一种特殊的因果一致性。
会话一致性:
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现“读己之所写”的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
单调读一致性:
单调读一致性是指如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。
单调写一致性:
单调写一致性是指,一个系统需要能够保证来自同一个进程的写操作被顺序地执行。
以上就是最终一致性的五类常见的变种,在时间系统实践中,可以将其中的若干个变种互相结合起来,以构建一个具有最终一致性的分布式系统。事实上,可以将其中的若干个变种相互结合起来,以构建一个具有最终一致性特性的分布式系统。事实上,最终一致性并不是只有那些大型分布式系统才设计的特性,许多现代的关系型数据库都采用了最终一致性模型。在现代关系型数据库中,大多都会采用同步和异步方式来实现主备数据复制技术。在同步方式中,数据的复制国耻鞥通常是更新事务的一部分,因此在事务完成后,主备数据库的数据就会达到一致。而在异步方式中,备库的更新往往存在延时,这取决于事务日志在主备数据库之间传输的时间长短,如果传输时间过长或者甚至在日志传输过程中出现异常导致无法及时将事务应用到备库上,那么狠显然,从备库中读取的的数据将是旧的,因此就出现了不一致的情况。当然,无论是采用多次重试还是认为数据订正,关系型数据库还是能搞保证最终数据达到一致——这就是系统提供最终一致性保证的经典案例。
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统事务的ACID特性使相反的,它完全不同于ACID的强一致性模型,而是提出通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性与BASE理论往往又会结合在一起使用。• 怎么考虑数据一致性问题
• 说说最终一致性的实现方案
• 微服务的优缺点,可参考《微服务批判》
• 微服务与 SOA 的区别
• 如何拆分服务、水平分割、垂直分割
• 如何应对微服务的链式调用异常
• 如何快速追踪与定位问题
• 如何保证微服务的安全、认证
5.2、安全问题
• 如何防范常见的Web攻击、如何方式SQL注入
• 服务端通信安全攻防
• HTTPS原理剖析、降级攻击、HTTP与HTTPS的对比
5.3、性能优化
• 性能指标有哪些
• 如何发现性能瓶颈
• 性能调优的常见手段
• 说说你在项目中如何进行性能调优
6、其他
6.1、设计能力
• 说说你在项目中使用过的UML图
• 你如何考虑组件化、服务化、系统拆分
• 秒杀场景如何设计
• 可参考:《秒杀系统的技术挑战、应对策略以及架构设计总结一二!》
6.2、业务工程
• 说说你的开发流程、如何进行自动化部署的
• 你和团队是如何沟通的
• 你如何进行代码评审
• 说说你对技术与业务的理解
• 说说你在项目中遇到感觉最难Bug,是如何解决的
• 介绍一下工作中的一个你认为最有价值的项目,以及在这个过程中的角色、解决的问题、你觉得你们项目还有哪些不足的地方
6.3、软实力
• 说说你的优缺点、亮点
• 说说你最近在看什么书、什么博客、在研究什么新技术、再看那些开源项目的源代码
• 说说你觉得最有意义的技术书籍
• 工作之余做什么事情、平时是如何学习的,怎样提升自己的能力
• 说说个人发展方向方面的思考
• 说说你认为的服务端开发工程师应该具备哪些能力
• 说说你认为的架构师是什么样的,架构师主要做什么
• 如何看待加班的问题
Java后端技术面试汇总(第一套)的更多相关文章
- Java后端技术面试汇总(第二套)
1.Java相关 • Arraylist与LinkedList默认空间是多少:• Arraylist与LinkedList区别与各自的优势List 和 Map 区别:• 谈谈HashMap,哈希表解决 ...
- Java后端技术面试汇总(第五套)
1.Java相关 • 乐观悲观锁的设计,如何保证原子性,解决的问题:• char和double的字节,以及在内存的分布是怎样:• 对象内存布局,然后讲下对象的死亡过程?• 对象头,详细讲下:• syn ...
- Java后端技术面试汇总(第四套)
1.Java基础 • 为什么JVM调优经常会将-Xms和-Xmx参数设置成一样:• Java线程池的核心属性以及处理流程:• Java内存模型,方法区存什么:• CMS垃圾回收过程:• Full GC ...
- Java后端技术面试汇总(第三套)
1.基础题 • 怎么解决Hash冲突:(开放地址法.链地址法.再哈希法.建立公共溢出区等)• 写出一个必然会产生死锁的伪代码:• Spring IoC涉及到的设计模式:(工厂模式.单利模式..)• t ...
- Java后端技术微信交流群!工作、学习、技术、资源等!期待你的加入!
<Java后端技术>专注Java相关技术:SSM.Spring全家桶.微服务.MySQL.MyCat.集群.分布式.中间件.Linux.网络.多线程,偶尔讲点运维Jenkins.Nexus ...
- 4000字干货长文!从校招和社招的角度说说如何准备Java后端大厂面试?
插个题外话,为了写好这篇文章内容,我自己前前后后花了一周的时间来总结完善,文章内容应该适用于每一个学习 Java 的朋友!我觉得这篇文章的很多东西也是我自己写给自己的,比如从大厂招聘要求中我们能看到哪 ...
- Java后端技术书单
写博客记录技术上使用的各种问题,这个只能算是一个打游击. 如果要把一个知识学透,最有效的方式就是系统学习,而系统学习就是看书,书本上有清晰的学习路线以及相应的技术栈. 下面是我收集的Java后端的技术 ...
- Java技术面试汇总
1.servlet执行流程 客户端发出http请求,web服务器将请求转发到servlet容器,servlet容器解析url并根据web.xml找到相对应的servlet,并将request.resp ...
- java后端技术
技术概论:Springmvc+mybatis+shiro+Dubbo+ZooKeeper+Redis+KafKa j2ee分布式架构 我在恒生工作,主要开发金融互联网第三方平台的对接项目.目前已经对接 ...
随机推荐
- IntelliJ IDEA工具增加test测试方法,报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing错误
是因为我在IntelliJ IDEA中,通过plugins增加 插件的时候,在 增加的测试类是junit4.12,改版本的jar包不再包含hamcrest-library.jar .我是通过将自己的项 ...
- Word文档怎么从第二页加页码
1.首先将光标放到首页的最后位置 2.“页面布局”—“分隔符”—“下一页” 3.“插入”—“页码”—选一种样式的页码 4.将光标定位到第二页的页脚处,“设计”—取消“链接到前一条页眉” 5.将第二页的 ...
- 【Java笔试】OYO校招Java工程师|牛客平台,算法:字符串翻转。附选择题解析
文章目录 1.Java笔试算法题:字符串翻转 2.单选题: 2.1.同一进程下的多个线程可以共享哪一种资源:data section 2.2.一个树形的叶结点在前序遍历和后序遍历下,可以相同的相对位置 ...
- Spring Annotations
@Bean 这是一个方法注解,作用是实例化一个Bean并使用该方法的名臣命名.
- 如何修改phpstorm的缓存目录
相信使用phpstorm的人们都被缓存目录的大小困扰过.怎么修改到其它地方呢? 1. 找到 idea.properties 文件,配置信息都在此文件中,F:\Program Files\JetBrai ...
- 简单说 JavaScript实现雪花飘落效果
说明 这次实现的雪花飘落的效果很简单,主要是为了练习练习JavaScript中的定时器,setTimeout 和 setInterval. 效果图 解释setTimeout() setTimeout函 ...
- Django之缓存配置
01-什么是缓存 缓存(cache),其作用是缓和较慢存储的高频次请求,简单来说,就是加速满存储的访问效率. 02-几种缓存配置 # 内存缓存:local-memory caching CACHES ...
- 作为web开发人员,你必须要知道的问题! (持续更新)
GET 和 POST 的区别 GET请注意,查询字符串(名称/值对)是在 GET 请求的 URL 中发送的:/test/demo_form.asp?name1=value1&name2=val ...
- Java爬虫爬取京东商品信息
以下内容转载于<https://www.cnblogs.com/zhuangbiing/p/9194994.html>,在此仅供学习借鉴只用. Maven地址 <dependency ...
- 阶段3 3.SpringMVC·_03.SpringMVC常用注解_4 HiddentHttpMethodFilter过滤器
此文只做了解!! 过滤器 ,了解即可 请求设置为post的方式 换成put的方式 浏览器模拟发送PUT请求 ,不大好模拟.顾虑器可以帮助我们发送不同的请求 过滤器会拿到这个请求 详情可以看文档,此处不 ...