DS博客作业04--树大作业
1.树的存储结构

本组采用的树的存储结构为链式结构,选择如图所示的结构体
Name为结点的名称
LevelNum为孩子节点的个数
*Children[20]用来指向不同的孩子结点(类似于二叉树的结构体,且数组大小这里取20,不够可以再增加)
2.树的函数说明
1.void Creatstr(string *str,int &length) 读取并分割文件中的字符串

strtok是字符串分割函数,作用是将ch字符串中的字符串分割,分割的规则是在ch碰到与split变量有关的符号,都会将其改成‘\0’
例如 split = "<>"
ch = <html>
用strtok分割后ch就变成了html,注意split中若有空格,ch中的空格也会被改成'\0',而且不是碰到 <> 在一起时才会将其改成'\0',只要字符串中含有 < 或者 > 都会被其改成'/0'
void Creatstr(string *str,int &length)利用这个函数strtok()对读取到的文件中的字符串进行分割并且存入一个字符串数组中
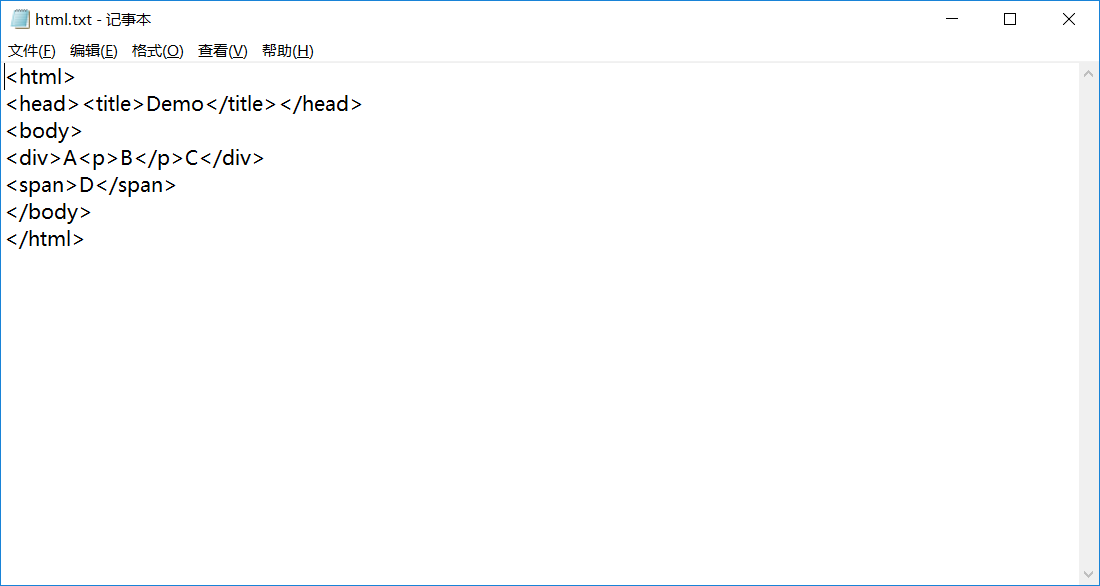
比如 文件中的内容如下
<html>
<head><title>Demo</title></head>
<body>
<div>A<p>B</p>C</div>
<span>D</span>
</body>
</html>
利用Creatstr(string *str,int &length)进行处理后str字符串数组中
str[0] = html
str[1] = head
str[2] = title
str[3] = Demo
str[4] = /title
......依次类推
而length就是字符串数组str的大小
2.void CreatTree(string *str,BTNode *&T,int length) 建立多叉树

利用Creatstr()函数得到的字符串数组str[ ]以及其长度length进行建树,建树方法如下
建立两个类型为<BTNode*>的栈 s1,s2
for i=0 to length-1 //遍历str
{
若str[i][0]!='/' 建立一个结点,结点的名称为str[i],进s1栈
若str[i][0]=='/' (在s1栈中找到与之匹配的元素,例如 /html 对应html (在下方有解释))
{
while (不匹配) { s1.top()进s2栈且s1.pop() }
找到匹配元素后(经过while循环后匹配元素此时在s1.top())
{
BTNode* T=s1.top() s1.pop() //用指针T存放栈顶元素然后让栈顶出栈
T对应的结点的孩子结点个数即为栈s2的长度 即T->LevelNum=s2.size()
将s2的元素依次出栈直到栈空,并且依次存放到T->Children[ ]中
最后将T入s1栈
}
}
}
然后这里是配对的操作 即代码中的1 2 3步骤
str2=str[i]
str2.erase(str2.begin())
用str2保存str[i],再用erase函数去除'/'字符
str2.begin()是指向str2字符串的第一个字符,str.erase(p)就是删去str中p对应的字符
所以str2.erase(str2.begin())是将str2字符串中的第一个字符串删去例如 str2=/htmel,经过erase()函数处理后就变成了 html
然后再去找s1中配对的元素
3.int FindPositionCode(BTNode *T,string name,int *a,int flag,int &flag2)

该函数有5个参数BTNode *T为树,
str name所查找元素的名称,
int *a为数组的头地址,且a[ ]数组中的元素全部为-1
int flag为孩子结点Children[ ]对应的下标,头节点没有对应下标就用 -1
int &flag2为了判断所查找的元素是否存在,存在时返回0,不存在时返回1
该函数运行结果会把位置编码储存再数组a[ ]中
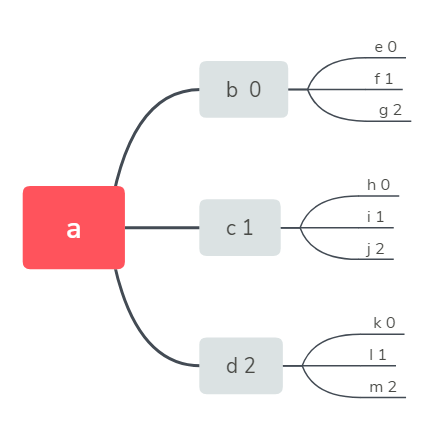
而位置编码由上面的树状图来解释
例如元素e的位置就为00,f的为01,g的为02,h的为10.....
但是经过该函数处理后的数组a[ ]中a[0]一定为-1,后面的元素也都会是-1
所以数组a有用的部分就是 for a[1] to a[i] (a[i]的下一个元素a[i+1]=-1)
例如e的位置编码为00,则数组a[10]将会是-1 0 0 -1 -1 -1 -1 -1 -1 -1
f的位置编码为01,则数组a[10]将会是-1 0 1 -1 -1 -1 -1 -1 -1 -1
4.void FindPosition(BTNode *T,int *a) 按格式输出元素路径

该函数利用上面FindPositionCode()函数得到的数组a[ ],然后进行处理,最后按格式输出路径
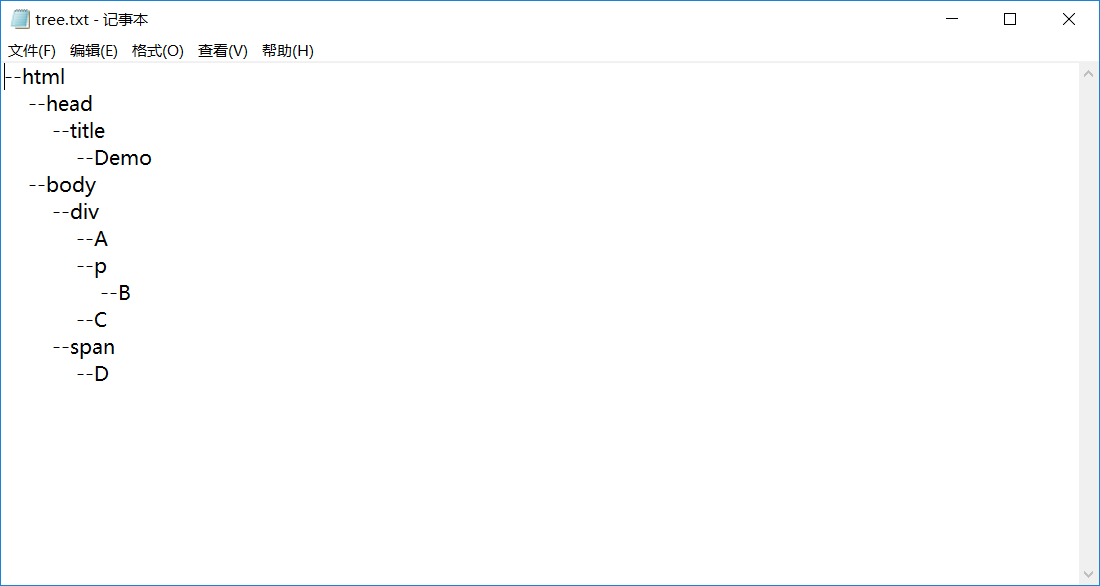
5.void CreatFileTree(BTNode *T,int i,FILE *fp) 建立文档树并写入tree.txt文件中
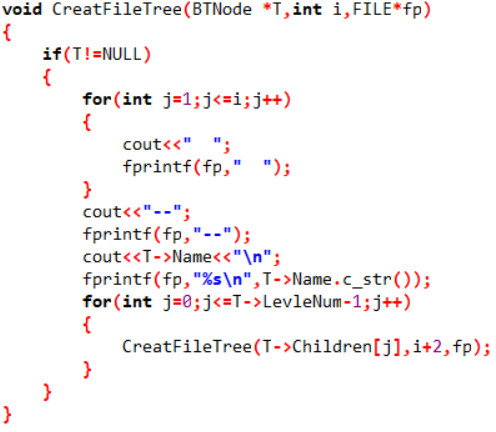
用递归遍历树T,然后再按照格式输出文档树
(类似于线序遍历,看代码慢慢体会)
3.树结果演示
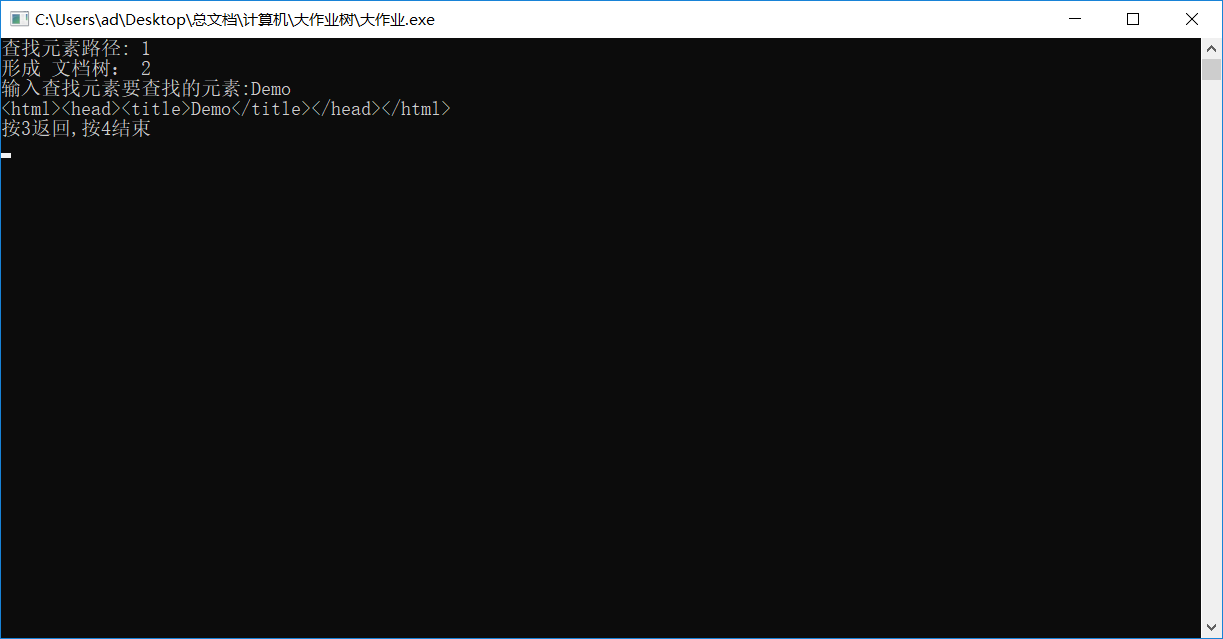


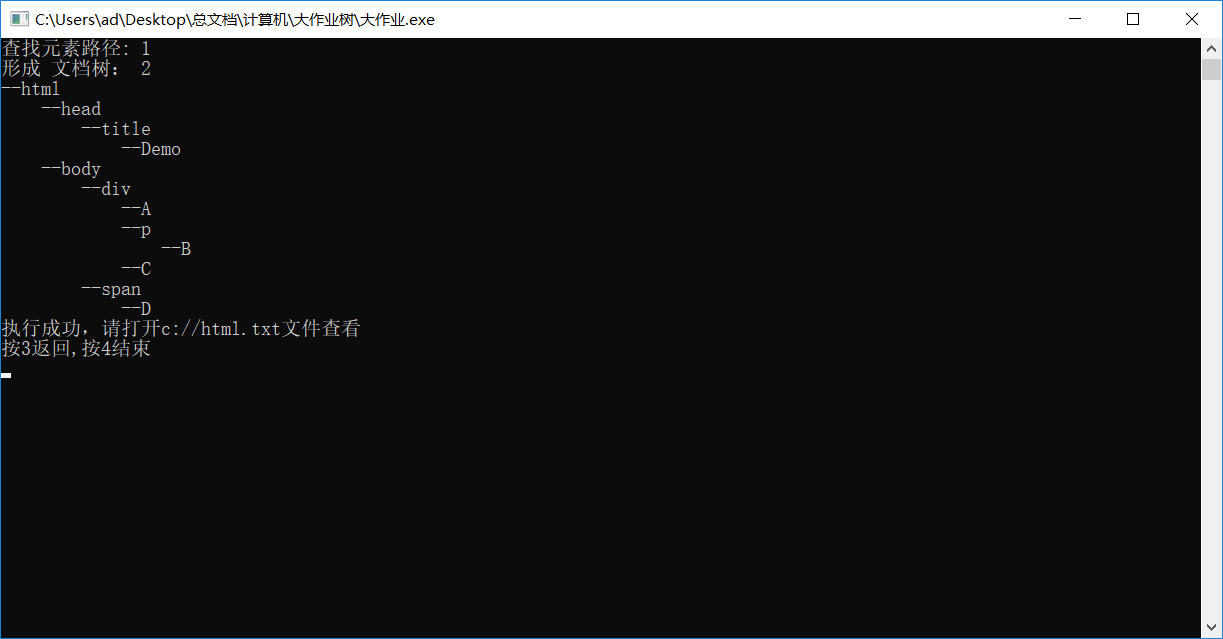
4.碰到问题
1.选择树的结构体上花费较多时间
2.建树算法为本小组自创的非递归算法,在设计过程中花费较多时间,最后参考算术表达式转化成中缀表达式的算法设计出来
3.在设计输出路径的功能中,采取先获取位置编码然后再进行输出处理的做法也是本小组自创,在设计过程中也花费较多时间
4.在调式上,因为传参时忘了加符号&,导致程序崩溃
5.小结
1.虽然采用了比较不同的结构体,但是采取该结构体后可能会造成空间上的浪费
2.采用该结构体在遍历时时间复杂度比较高,而且建树过程较为复杂
3.好处就是建树的模型比较清晰做法比较独特
6.小组成员分配说明
main()函数:刘羽 1.5分
Creatstr()函数:阮承南 1.5分
CreatTree()函数:唐洪俊 2分
FindPositionCode()函数:沈宇涛 2分
FindPositionCode()函数:沈宇涛
CreatFileTree()函数:蔡丰俊 2分
博客园:张明海 1分
DS博客作业04--树大作业的更多相关文章
- DS博客大作业--树(李天明组)
DS博客大作业--树 大作业博客要求 (10分) 1.树的存储结构说明 .树采用的是链式存储结构. .这段代码中定义了两个结构体.第一个是自定义为Name类型的结构体,里面的成员有字符串str和类型为 ...
- DS博客作业——树
DS博客作业--树 1.本周学习总结 1.思维导图 2.谈谈你对树结构的认识及学习体会. 在树这一章节,我们学习的是二叉树的算法. 树的构建:一种是直接给树的顺序存储结构的字符串,一种是通过先序遍历和 ...
- DS博客作业08--课程总结
DS博客作业08--课程总结 1.当初你是如何做出选择计算机专业的决定的? 1.1 经过一年学习,你的看法改变了么,为什么? 1.2 你觉得计算机是你喜欢的领域吗,它是你擅长的领域吗? 为什么? 1. ...
- DS博客作业--07查找
目录 DS博客作业--07查找 1.本周学习总结(0--2分) 1.思维导图 2.谈谈你对查找运算的认识及学习体会. 2.PTA实验作业(6分) 2.1.题目1:6-1 二叉搜索树的操作集 (30 分 ...
- DS博客作业05--查找
这个作业属于哪个班级 数据结构--网络2011/2012 这个作业的地址 DS博客作业05--查找 这个作业的目标 学习查找的相关结构 姓名 黄静 目录 0.PTA得分截图 1.本周学习总结 1.1 ...
- DS博客作业03--树
这个作业属于哪个班级 数据结构--网络2011/2012 这个作业的地址 DS博客作业03--树 这个作业的目标 学习树结构设计及运算操作 姓名 黄静 目录 0. PTA得分截图 1. 本周学习总结 ...
- DS博客作业05--树
1.本周学习总结 1.思维导图 2.谈谈你对树结构的认识及学习体会 学完树之后,最大的感觉就是在处理节点之间的兄弟父亲关系的时候真的挺好用的,一目了然.不过,树令人比较头疼的就是要用递归,大致能懂递归 ...
- DS博客作业04--图
这个作业属于哪个班级 数据结构--网络2011/2012 这个作业的地址 DS博客作业04--图 这个作业的目标 学习图结构设计及相关算法 姓名 黄静 目录 0.PTA得分截图 1.本周学习总结 1. ...
- DS博客作业01--日期抽象数据类型
1.思维导图及学习体会(2分) 1.1第一章绪论知识点思维导图 1.2学习体会 从暑假看视频到开学的预习,我感觉数据结构与c语言比起来更加抽象,更加难理解,那些概念也只能理解一些字面意思,对时间复杂度 ...
- DS博客大作业--树
1.树的存储结构说明 树节点结构体 data:文件名 brother:兄弟节点 child:孩子节点 type:节点的类型,0为文件,1为目录 h:节点所在的层次 2.树的函数说明 头文件 函数1:C ...
随机推荐
- C++ STL 之 内建函数对象
STL 内建了一些函数对象.分为:算数类函数对象,关系运算类函数对象,逻辑运算类仿函数.这些仿函数所产生的对象,用法和一般函数完全相同,当然我们还可以产生无名的临时对象来履行函数功能.使用内建函数对象 ...
- BootStrap【三、组件】
特有标签属性 role 用于浏览器识别 aria-label 用于浏览器识别 tabIndex 用于浏览器识别 data- 自定义数据属性 图标 直接引用官方图标库中的class 官方图标库 Demo ...
- shell脚本编写之Hello World
Linux下编写第一个Shell脚本 //创建一个.sh文件 vi demo1.sh //按i进入编辑模式 echo "Hello World !" //按esc→shift+:→ ...
- (备忘)Nodepad++常用快捷键
Ctrl-H 打开Find / Replace 对话框 Ctrl-D 复制当前行 Ctrl-L 删除当前行 Ctrl-T 上下行交换 F3 找下一个 Shift-F3 找上一个 Ctrl-Shift- ...
- c#读取文件路径并保存在textBox2中
private void button1_Click_1(object sender, EventArgs e) { OpenFileDialog openFileDialog1 = new Open ...
- Python3学习笔记37-LeetCode刷题
LeetCode中国官网一个用来刷编程题的网站,收录了很多面试题.感觉还是学习到很多.记录一下思路.代码还是要多敲. 建议编写完后直接在LeetCode上运行和提交.提交时会有不同的测试用例来测试代码 ...
- Python数据库连接池 -组件 DBUtils
DBUtils是Python的一个用于实现数据库连接池的模块 此连接池有两种连接模式: DBUtils提供两种外部接口: PersistentDB :提供线程专用的数据库连接,并自动管理连接. Poo ...
- 基于STM32调试工具STM-STUDIO-STM32的使用
手上有stlink下载器,正好看到官网有这个工具,可以在运行中实时查看变量的数据.这一点和ucos的ucprobe很类似. 参考https://mp.weixin.qq.com/s?src=11&am ...
- Modbus通讯协议
<ignore_js_op> O1CN01P1wxTI1dCdw5nAeMO_!!85243700.jpg (287.43 KB, 下载次数: 0) 下载附件 保存到相册 2019-6- ...
- vue 后退不刷新,前进刷新 keep-alive
最近在开发中遇到了这样的一个问题: A.B.C三个页面,有如下这样的场景: (1)从页面A离开进入B或C的时候,缓存A页面的数据,并且返回到A后,能保持A页面的跳转前职位 (2)离开B进入C的时候,缓 ...