【3】Kafka安装及部署
一、环境准备
- Linux操作系统
- Java运行环境(1.6或以上)
- zookeeper 集群环境,可参照Zookeeper集群部署 。
- 服务器列表:
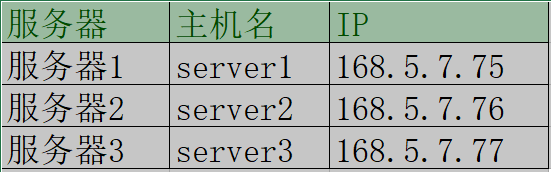
配置主机名映射。
vi /etc/hosts
##添加如下内容
168.5.7.75 server1
168.5.7.76 server2
168.5.7.77 server3
二、kafka集群部署及启动
2.1、介质准备
分别登录server1、server2、server3执行,操作、配置相同:
##更新或安装wget命令
yum -y install wget
##创建安装目录
mkdir -p /usr/local/services/kafka
##获取安装包kafka_2.11-2.3.0.tgz
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.0/kafka_2.11-2.3.0.tgz
##解压缩kafka_2.11-2.3.0.tgz
tar -zxvf kafka_2.11-2.3.0.tgz
2.2、配置环境变量
分别登录server1、server2、server3执行,操作、配置相同:
export KAFKA_HOME=/usr/local/services/kafka/kafka_2.11-2.3.0
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
说明:再任一路径下输入 kafka 按 Tab 键后会补全 Kafka 相关脚本.sh,即Kafka 环境变量配置成功。 因 Kafka 脚本运行时会加载 /config 路径下的相关配置文件,故当不在 Kafka 安装目录 bin 下执行相关脚本时, 需要指定配置文件绝对路径。
2.3、修改配置文件
登录server1执行操作:
cd $KAFKA_HOME/config
cp server.properties server.properties.$(date +%Y%m%d)
vi server.properties
##修改文件内配置如下
broker.id=1
log.dirs=/opt/data/kafka-logs
port=9093
zookeeper.connect=server1:2181,server2:2181,server3:2181
登录server2执行操作:
cd $KAFKA_HOME/config
cp server.properties server.properties.$(date +%Y%m%d)
vi server.properties
##修改文件内配置如下
broker.id=2
log.dirs=/opt/data/kafka-logs
port=9093
zookeeper.connect=server1:2181,server2:2181,server3:2181
登录server3执行操作:
cd $KAFKA_HOME/config
cp server.properties server.properties.$(date +%Y%m%d)
vi server.properties
##修改文件内配置如下
broker.id=3
log.dirs=/opt/data/kafka-logs
port=9093
zookeeper.connect=server1:2181,server2:2181,server3:2181
说明:broker.id 用于指定代理的 id,需保证同一个集群下 broker.id 要唯一;log.dirs 指定日志存储路径。
2.4、启动服务
分别登录server1、server2、server3执行,操作、配置相同:
cd $KAFKA_HOME/bin
## -daemon :守护进程方式启动
kafka-server-start.sh -daemon ../config/server.properties
连接测试
#登录 ZooKeeper
cd /usr/local/services/zookeeper/zookeeper-3.4.13/bin
./zkCli.sh -server server1:2181
ls /
日志查看
##查看 KafkaServer 启动 日志
cat $KAFKA_HOME/logs/server.log
参考资料
参考书籍:Kafka入门与实践
DeepInThought
出处:
https://www.cnblogs.com/DeepInThought
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
【3】Kafka安装及部署的更多相关文章
- Kafka安装及部署
安装及部署 一.环境配置 操作系统:Cent OS 7 Kafka版本:0.9.0.0 Kafka官网下载:请点击 JDK版本:1.7.0_51 SSH Secure Shell版本:XShell 5 ...
- kafka安装和部署
阅读目录 一.环境配置 二.操作过程 Kafka介绍 安装及部署 回到顶部 一.环境配置 操作系统:Cent OS 7 Kafka版本:0.9.0.0 Kafka官网下载:请点击 JDK版本:1.7. ...
- kafka系列一、kafka安装及部署、集群搭建
一.环境准备 操作系统:Cent OS 7 Kafka版本:kafka_2.10 Kafka官网下载:请点击 JDK版本:1.8.0_171 zookeeper-3.4.10 二.kafka安装配置 ...
- Kafka的安装和部署及测试
1.简介 大数据分析处理平台包括数据的接入,数据的存储,数据的处理,以及后面的展示或者应用.今天我们连说一下数据的接入,数据的接入目前比较普遍的是采用kafka将前面的数据通过消息的方式,以数据流的形 ...
- Kafka安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上 下载kafka_2.11-1.1.0.tgz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploa ...
- zookeeper与kafka安装部署及java环境搭建(发布订阅模式)
1. ZooKeeper安装部署 本文在一台机器上模拟3个zk server的集群安装. 1.1. 创建目录.解压 cd /usr/ #创建项目目录 mkdir zookeeper cd zookee ...
- Logstash安装及部署
安装及部署 一.环境配置 操作系统:Cent OS 7 Logstash版本:2.1.1.tar.gz JDK版本:1.7.0_51 SSH Secure Shell版本:XShell 5 二.操作过 ...
- Kafka集群部署
一. 关于kafka Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键 ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
随机推荐
- AutoHome项目的学习
1.自定义UITabBar #import <UIKit/UIKit.h> @interface XHQTabBarViewController : UITabBarController ...
- 用例建模 Use Case Modeling
用例建模 以您的工程实践项目为例,在理解项目需求的基础上进行用例建模,抽取Abstract use case,画出用例图,并确定每一个用例的范围High level use case,对关键用例进一步 ...
- postman--接口网站测试
直接在官网下载安装即可 https://www.getpostman.com/downloads/
- 金士顿U盘PS2251-07东芝闪存白片量产CDROM成功教程-群联量产教程-U盘量产网
之前我们发布过金士顿DT100 G3的黑片量产工具教程,因为白片的MPALL量产工具无法量产,所有版本的Phison_MPALL都爆红,最近出了新的白片MPALL V5.03.0A版本,所以试了一下结 ...
- SpringEl表达式解析
应用场景: 1.用户日志 2.缓存处理 3........... import org.springframework.expression.EvaluationContext; import org ...
- AndroidStudio下载安装教程(图文教程)
场景 Android Studio 中文社区: http://www.android-studio.org/ 下载安装包,这里选择64位Windows 等待下载完成. 注: 博客: https://b ...
- Win10修改字体
先将自己喜欢的字体下载下来. 把自己喜欢的字体下载之后,一般会是一个压缩包,将其解,格式是ttf. 点击解压后的字体文件,将其安装在windows系统之中. 键盘上先按住win,在按R,出现一个窗口, ...
- C++版 归并排序
在原作者基础上加入注释 原作者:https://www.cnblogs.com/agui521/p/6918229.html 归并排序:归并排序(英语:Merge sort,或mergesort),是 ...
- Equations HDU - 1496(哈希的应用)
Problem Description Consider equations having the following form: a*x1^2+b*x2^2+c*x3^2+d*x4^2=0 a, b ...
- Thinkphp5+Layui上传图片
ThinkPHP是一个免费开源的,快速.简单的面向对象的轻量级PHP开发框架,是为了敏捷WEB应用开发和简化企业应用开发而诞生的.ThinkPHP从诞生以来一直秉承简洁实用的设计原则,在保持出色的性能 ...