《浏览器工作原理与实践》<03>HTTP请求流程:为什么很多站点第二次打开速度会很快?
一个 TCP 连接过程包括了建立连接、传输数据和断开连接三个阶段。
而 HTTP 协议,正是建立在 TCP 连接基础之上的。HTTP 是一种允许浏览器向服务器获取资源的协议,是 Web 的基础,通常由浏览器发起请求,用来获取不同类型的文件,例如 HTML 文件、CSS 文件、JavaScript 文件、图片、视频等。此外,HTTP 也是浏览器使用最广的协议,所以要想学好浏览器,就要先深入了解 HTTP。
不知道你是否有过下面这些疑问:
1.为什么通常在第一次访问一个站点时,打开速度很慢,当再次访问这个站点时,速度就很快了?
2.当登录过一个网站之后,下次再访问该站点,就已经处于登录状态了,这是怎么做到的呢?
这一切的秘密都隐藏在 HTTP 的请求过程中。所以,在今天这篇文章中,我将通过分析一个 HTTP 请求过程中每一步的状态来带你了解完整的 HTTP 请求过程,希望你看完这篇文章后,能够对 HTTP 协议有个全新的认识。
浏览器端发起 HTTP 请求流程
1. 构建请求
首先,浏览器构建请求行信息(如下所示),构建好后,浏览器准备发起网络请求。
GET /index.html HTTP1.1
2. 查找缓存
在真正发起网络请求之前,浏览器会先在浏览器缓存中查询是否有要请求的文件。其中,浏览器缓存是一种在本地保存资源副本,以供下次请求时直接使用的技术。当浏览器发现请求的资源已经在浏览器缓存中存有副本,它会拦截请求,返回该资源的副本,并直接结束请求,而不会再去源服务器重新下载。这样做的好处有:
缓解服务器端压力,提升性能(获取资源的耗时更短了);
对于网站来说,缓存是实现快速资源加载的重要组成部分。
当然,如果缓存查找失败,就会进入网络请求过程了。
3. 准备 IP 地址和端口
不过,先不急,在了解网络请求之前,我们需要先看看 HTTP 和 TCP 的关系。因为浏览器使用 HTTP 协议作为应用层协议,用来封装请求的文本信息;并使用 TCP/IP 作传输层协议将它发到网络上,所以在 HTTP 工作开始之前,浏览器需要通过 TCP 与服务器建立连接。也就是说 HTTP 的内容是通过 TCP 的传输数据阶段来实现的,你可以结合下图更好地理解这二者的关系。

那接下来你可以思考这么“一连串”问题:
1. HTTP 网络请求的第一步是做什么呢?结合上图看,是和服务器建立 TCP 连接。
2. 那建立连接的信息都有了吗?建立 TCP 连接的第一步就是需要准备 IP 地址和端口号。
3. 那怎么获取 IP 地址和端口号呢?这得看看我们现在有什么,我们有一个 URL 地址,那么是否可以利用 URL 地址来获取 IP 和端口信息呢?
数据包都是通过 IP 地址传输给接收方的。由于 IP 地址是数字标识,比如 39.106.233.176, 它难以记忆,域名(就好记多了,所以基于这个需求又出现了一个服务,负责把域名和 IP 地址做一一映射关系。这套域名映射为 IP 的系统就叫做“域名系统”,简称 DNS(Domain Name System)。所以,这样一路推导下来,你会发现在第一步浏览器会请求 DNS 返回域名对应的 IP。当然浏览器还提供了 DNS 数据缓存服务,如果某个域名已经解析过了,那么浏览器会缓存解析的结果,以供下次查询时直接使用,这样也会减少一次网络请求。拿到 IP 之后,接下来就需要获取端口号了。通常情况下,如果 URL 没有特别指明端口号,那么 HTTP 协议默认是 80 端口。
4. 等待 TCP 队列
现在已经把端口和 IP 地址都准备好了,那么下一步是不是可以建立 TCP 连接了呢?答案依然是“不行”。Chrome 有个机制,同一个域名同时最多只能建立 6 个 TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。
当然,如果当前请求数量少于 6,会直接进入下一步,建立 TCP 连接。
5. 建立 TCP 连接
排队等待结束之后,终于可以快乐地和服务器握手了,在 HTTP 工作开始之前,浏览器通过 TCP 与服务器建立连接
6. 发送 HTTP 请求
一旦建立了 TCP 连接,浏览器就可以和服务器进行通信了。而 HTTP 中的数据正是在这个通信过程中传输的。你可以结合下图来理解,浏览器是如何发送请求信息给服务器的。
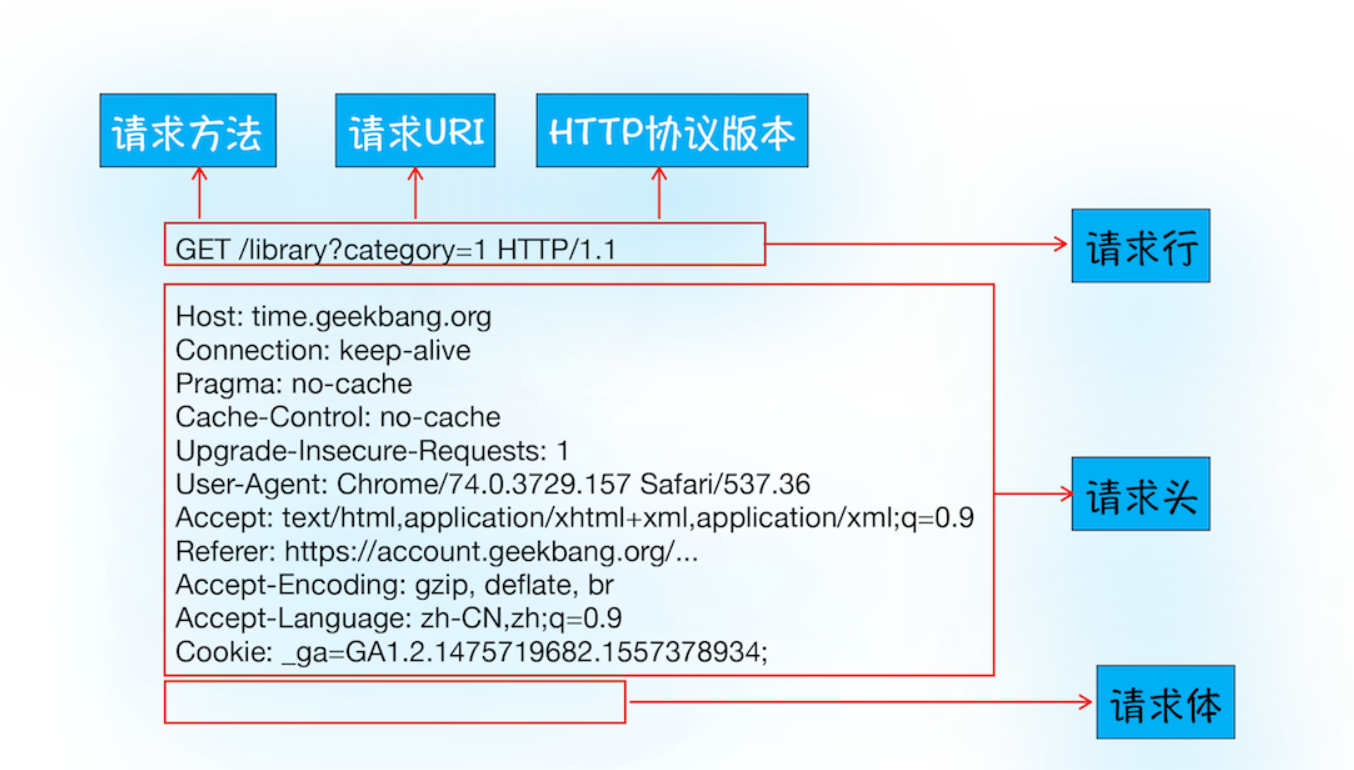
首先浏览器会向服务器发送请求行,它包括了请求方法、请求 URI(Uniform Resource Identifier)和 HTTP 版本协议。
发送请求行,就是告诉服务器浏览器需要什么资源,最常用的请求方法是 Get。比如,直接在浏览器地址栏键入极客时间的域名(time.geekbang.org),这就是告诉服务器要 Get 它的首页资源。
另外一个常用的请求方法是 POST,它用于发送一些数据给服务器,比如登录一个网站,就需要通过 POST 方法把用户信息发送给服务器。如果使用 POST 方法,那么浏览器还要准备数据给服务器,这里准备的数据是通过请求体来发送。
在浏览器发送请求行命令之后,还要以请求头形式发送其他一些信息,把浏览器的一些基础信息告诉服务器。比如包含了浏览器所使用的操作系统、浏览器内核等信息,以及当前请求的域名信息、浏览器端的 Cookie 信息,等等。
服务器端处理 HTTP 请求
流程历经千辛万苦,HTTP 的请求信息终于被送达了服务器。接下来,服务器会根据浏览器的请求信息来准备相应的内容。
1. 返回请求
一旦服务器处理结束,便可以返回数据给浏览器了。你可以通过工具软件 curl 来查看返回请求数据,具体使用方法是在命令行中输入以下命令:
curl -i https://time.geekbang.org/
注意这里加上了-i是为了返回响应行、响应头和响应体的数据,返回的结果如下图所示,你可以结合这些数据来理解服务器是如何响应浏览器的。
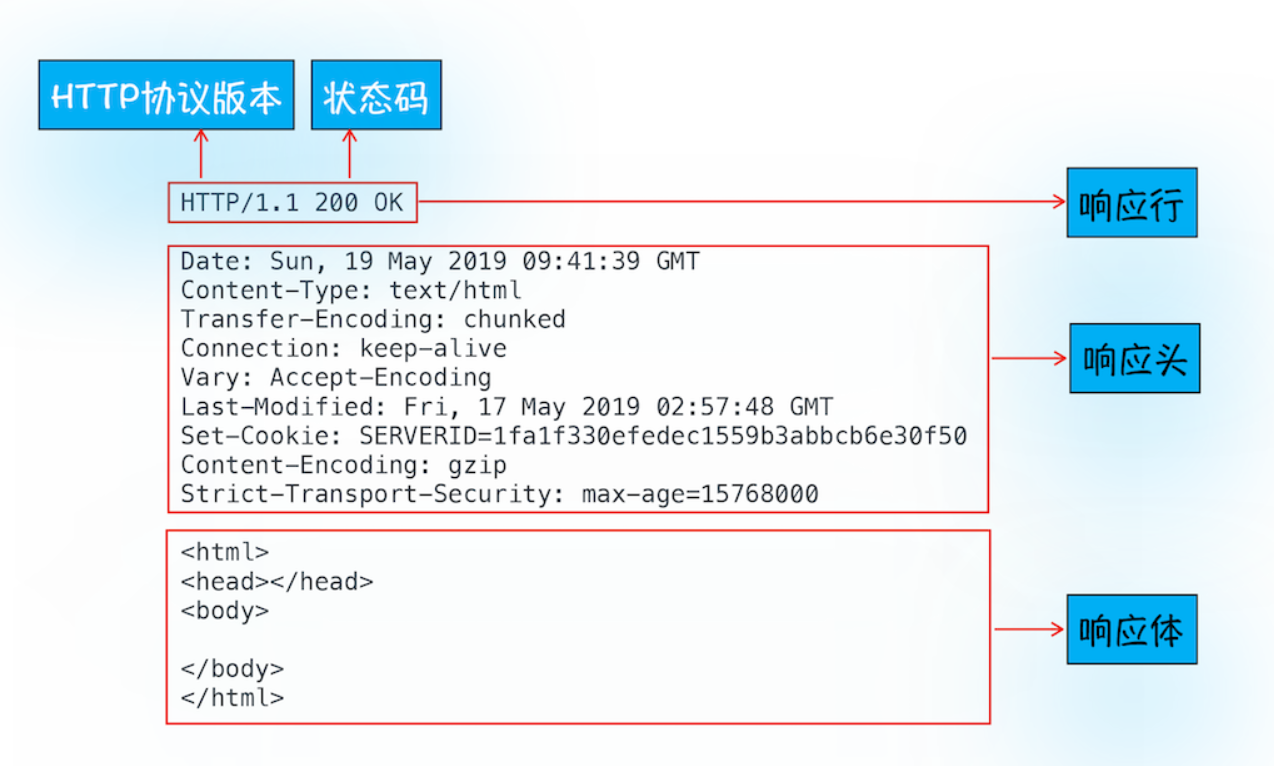
首先服务器会返回响应行,包括协议版本和状态码。但并不是所有的请求都可以被服务器处理的,那么一些无法处理或者处理出错的信息,怎么办呢?服务器会通过请求行的状态码来告诉浏览器它的处理结果,比如:
最常用的状态码是 200,表示处理成功;如果没有找到页面,则会返回 404。
随后,正如浏览器会随同请求发送请求头一样,服务器也会随同响应向浏览器发送响应头。响应头包含了服务器自身的一些信息,比如服务器生成返回数据的时间、返回的数据类型(JSON、HTML、流媒体等类型),以及服务器要在客户端保存的 Cookie 等信息。
发送完响应头后,服务器就可以继续发送响应体的数据,通常,响应体就包含了 HTML 的实际内容。
以上这些就是服务器响应浏览器的具体过程。
2. 断开连接
通常情况下,一旦服务器向客户端返回了请求数据,它就要关闭 TCP 连接。不过如果浏览器或者服务器在其头信息中加入了:
Connection:Keep-Alive
那么 TCP 连接在发送后将仍然保持打开状态,这样浏览器就可以继续通过同一个 TCP 连接发送请求。保持 TCP 连接可以省去下次请求时需要建立连接的时间,提升资源加载速度。比如,一个 Web 页面中内嵌的图片就都来自同一个 Web 站点,如果初始化了一个持久连接,你就可以复用该连接,以请求其他资源,而不需要重新再建立新的 TCP 连接。
3. 重定向
到这里似乎请求流程快结束了,不过还有一种情况你需要了解下,比如当你在浏览器中打开 geekbang.org 后,你会发现最终打开的页面地址是 https://www.geekbang.org。这两个 URL 之所以不一样,是因为涉及到了一个重定向操作。跟前面一样,你依然可以使用 curl 来查看下请求 geekbang.org 会返回什么内容?在控制台输入如下命令:
curl -I geekbang.org
注意这里输入的参数是-I,和-i不一样,-I表示只需要获取响应头和响应行数据,而不需要获取响应体的数据,最终返回的数据如下图所示:

从图中你可以看到,响应行返回的状态码是 301,状态 301 就是告诉浏览器,我需要重定向到另外一个网址,而需要重定向的网址正是包含在响应头的 Location 字段中,接下来,浏览器获取 Location 字段中的地址,并使用该地址重新导航,这就是一个完整重定向的执行流程。这也就解释了为什么输入的是 geekbang.org,最终打开的却是 https://www.geekbang.org 了。
不过也不要认为这种跳转是必然的。如果你打开 https://12306.cn,你会发现这个站点是打不开的。这是因为 12306 的服务器并没有处理跳转,所以必须要手动输入完整的 https://www.12306.cn 才能打开页面。
问题解答
1. 为什么很多站点第二次打开速度会很快?
如果第二次页面打开很快,主要原因是第一次加载页面过程中,缓存了一些耗时的数据。
那么,哪些数据会被缓存呢?从上面介绍的核心请求路径可以发现,DNS 缓存和页面资源缓存这两块数据是会被浏览器缓存的。
其中,DNS 缓存比较简单,它主要就是在浏览器本地把对应的 IP 和域名关联起来,这里就不做过多分析了。我们重点看下浏览器资源缓存,下面是缓存处理的过程:
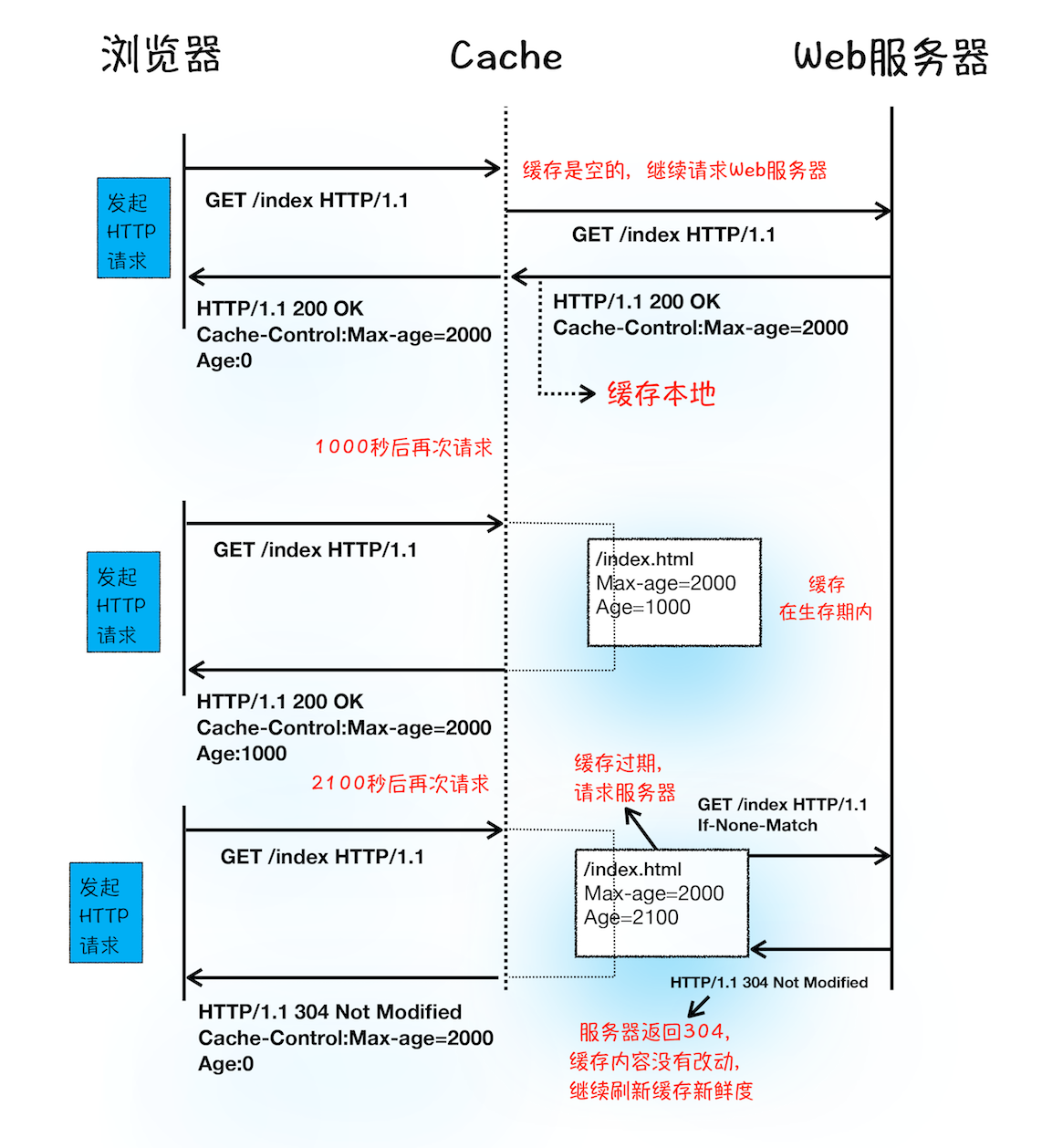
首先,我们看下服务器是通过什么方式让浏览器缓存数据的?
从上图的第一次请求可以看出,当服务器返回 HTTP 响应头给浏览器时,浏览器是通过响应头中的 Cache-Control 字段来设置是否缓存该资源。通常,我们还需要为这个资源设置一个缓存过期时长,而这个时长是通过 Cache-Control 中的 Max-age 参数来设置的,比如上图设置的缓存过期时间是 2000 秒。
Cache-Control:Max-age=2000
这也就意味着,在该缓存资源还未过期的情况下, 如果再次请求该资源,会直接返回缓存中的资源给浏览器。
但如果缓存过期了,浏览器则会继续发起网络请求,并且在 HTTP 请求头中带上:
If-None-Match:"4f80f-13c-3a1xb12a"
服务器收到请求头后,会根据 If-None-Match 的值来判断请求的资源是否有更新。
1.如果没有更新,就返回 304 状态码,相当于服务器告诉浏览器:“这个缓存可以继续使用,这次就不重复发送数据给你了。
2.如果资源有更新,服务器就直接返回最新资源给浏览器。
简要来说,很多网站第二次访问能够秒开,是因为这些网站把很多资源都缓存在了本地,浏览器缓存直接使用本地副本来回应请求,而不会产生真实的网络请求,从而节省了时间。同时,DNS 数据也被浏览器缓存了,这又省去了 DNS 查询环节。
2. 登录状态是如何保持的?
通过上面的介绍,你已经了解了缓存是如何工作的。下面我们再一起看下登录状态是如何保持的。
用户打开登录页面,在登录框里填入用户名和密码,点击确定按钮。点击按钮会触发页面脚本生成用户登录信息,然后调用 POST 方法提交用户登录信息给服务器。
服务器接收到浏览器提交的信息之后,查询后台,验证用户登录信息是否正确,如果正确的话,会生成一段表示用户身份的字符串(token),并把该字符串写到响应头的 Set-Cookie 字段里,如下所示,然后把响应头发送给浏览器。
Set-Cookie: UID=3431uad;
浏览器在接收到服务器的响应头后,开始解析响应头,如果遇到响应头里含有 Set-Cookie 字段的情况,浏览器就会把这个字段信息保存到本地。比如把UID=3431uad保持到本地。
当用户再次访问时,浏览器会发起 HTTP 请求,但在发起请求之前,浏览器会读取之前保存的 Cookie 数据,并把数据写进请求头里的 Cookie 字段里(如下所示),然后浏览器再将请求头发送给服务器。
Cookie: UID=3431uad;
服务器在收到 HTTP 请求头数据之后,就会查找请求头里面的“Cookie”字段信息,当查找到包含UID=3431uad的信息时,服务器查询后台,并判断该用户是已登录状态,然后生成含有该用户信息的页面数据,并把生成的数据发送给浏览器。
浏览器在接收到该含有当前用户的页面数据后,就可以正确展示用户登录的状态信息了。
好了,通过这个流程你可以知道浏览器页面状态是通过使用 Cookie 来实现的。Cookie 流程可以参考下图:

简单地说,如果服务器端发送的响应头内有 Set-Cookie 的字段,那么浏览器就会将该字段的内容保持到本地。当下次客户端再往该服务器发送请求时,客户端会自动在请求头中加入 Cookie 值后再发送出去。服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到该用户的状态信息。
总结
送上一张"HTTP 请求示意图”,用来展现浏览器中的 HTTP 请求所经历的各个阶段。
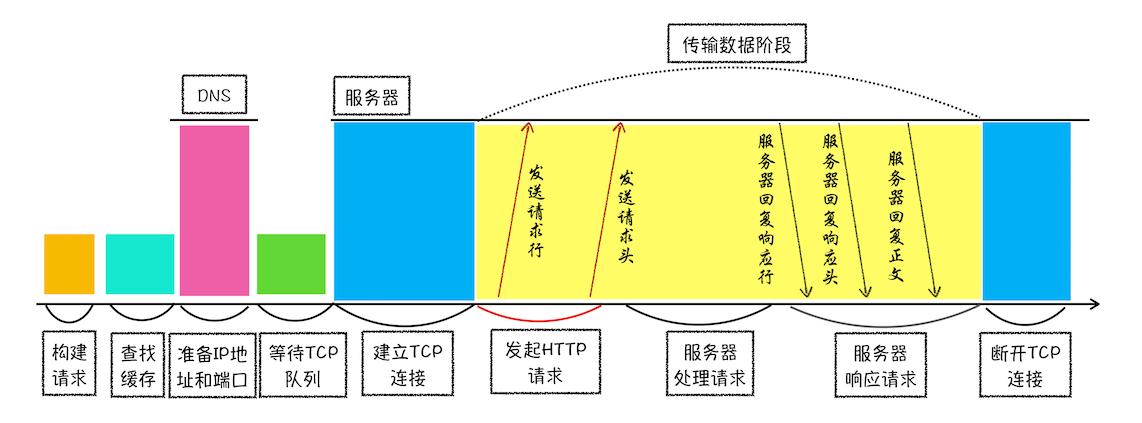
从图中可以看到,浏览器中的 HTTP 请求从发起到结束一共经历了如下八个阶段:构建请求、查找缓存、准备 IP 和端口、等待 TCP 队列、建立 TCP 连接、发起 HTTP 请求、服务器处理请求、服务器返回请求和断开连接。
然后我还通过 HTTP 请求路径解答了两个经常会碰到的问题,一个涉及到了 Cache 流程,另外一个涉及到如何使用 Cookie 来进行状态管理。
注: 本文出自极客时间(浏览器工作原理与实践),请大家多多支持李兵老师。如有侵权,请及时告知。
《浏览器工作原理与实践》<03>HTTP请求流程:为什么很多站点第二次打开速度会很快?的更多相关文章
- 《浏览器工作原理与实践》<06>渲染流程(下):HTML、CSS和JavaScript,是如何变成页面的?
在上篇文章中,我们介绍了渲染流水线中的 DOM 生成.样式计算和布局三个阶段,那今天我们接着讲解渲染流水线后面的阶段. 这里还是先简单回顾下上节前三个阶段的主要内容:在 HTML 页面内容被提交给渲染 ...
- 《浏览器工作原理与实践》<05>渲染流程(上):HTML、CSS和JavaScript,是如何变成页面的?
在上一篇文章中我们介绍了导航相关的流程,那导航被提交后又会怎么样呢?就进入了渲染阶段.这个阶段很重要,了解其相关流程能让你“看透”页面是如何工作的,有了这些知识,你可以解决一系列相关的问题,比如能熟练 ...
- 《浏览器工作原理与实践》<04>从输入URL到页面展示,这中间发生了什么?
“在浏览器里,从输入 URL 到页面展示,这中间发生了什么? ”这是一道经典的面试题,能比较全面地考察应聘者知识的掌握程度,其中涉及到了网络.操作系统.Web 等一系列的知识. 在面试应聘者时也必问这 ...
- 《浏览器工作原理与实践》<02>TCP协议:如何保证页面文件能被完整送达浏览器?
前言: 在衡量 Web 页面性能的时候有一个重要的指标叫“FP(First Paint)”,是指从页面加载到首次开始绘制的时长.这个指标直接影响了用户的跳出率,更快的页面响应意味着更多的 PV.更高的 ...
- 《浏览器工作原理与实践》 <12>栈空间和堆空间:数据是如何存储的?
对于前端开发者来说,JavaScript 的内存机制是一个不被经常提及的概念 ,因此很容易被忽视.特别是一些非计算机专业的同学,对内存机制可能没有非常清晰的认识,甚至有些同学根本就不知道 JavaSc ...
- 《浏览器工作原理与实践》<11>this:从JavaScript执行上下文的视角讲清楚this
在上篇文章中,我们讲了词法作用域.作用域链以及闭包,接下来我们分析一下这段代码: var bar = { myName:"time.geekbang.com", printName ...
- 《浏览器工作原理与实践》<10>作用域链和闭包 :代码中出现相同的变量,JavaScript引擎是如何选择的?
在上一篇文章中我们讲到了什么是作用域,以及 ES6 是如何通过变量环境和词法环境来同时支持变量提升和块级作用域,在最后我们也提到了如何通过词法环境和变量环境来查找变量,这其中就涉及到作用域链的概念. ...
- 《浏览器工作原理与实践》<09>块级作用域:var缺陷以及为什么要引入let和const?
在前面我们已经讲解了 JavaScript 中变量提升的相关内容,正是由于 JavaScript 存在变量提升这种特性,从而导致了很多与直觉不符的代码,这也是 JavaScript 的一个重要设计缺陷 ...
- 《浏览器工作原理与实践》<08>调用栈:为什么JavaScript代码会出现栈溢出?
在上篇文章中,我们讲到了,当一段代码被执行时,JavaScript 引擎先会对其进行编译,并创建执行上下文.但是并没有明确说明到底什么样的代码才算符合规范. 那么接下来我们就来明确下,哪些情况下代码才 ...
随机推荐
- Jmeter 逻辑控制器 之 ForEach 控制器
一.认识 ForEach 控制器 如下,创建一个 ForEach 控制器 设置界面如下: 输入变量前缀:要进行循环读取的变量前缀 Start index for loop (exclusive):循环 ...
- 亿级mongodb数据迁移
1. 预先准备有效数据单号池,通过单号拉取数据处理 单号表默认为1 01 使用findAndModify 更新单号表状态为 2 读取单号 循环读取100 条 02 通过运单号批量查询 Aladin_W ...
- 【VS开发】Return与Exit的区别
1. exit用于结束正在运行的整个程序,它将参数返回给OS,把控制权交给操作系统:而return 是退出当前函数,返回函数值,把控制权交给调用函数. 2. exit是系统调用级别,它表示一个进程的结 ...
- redis 获取方式和安装(windows)
Windows redis :https://github.com/MSOpenTech/redis/releases Linux redis :https://github.com/phpredis ...
- Linux selinux 防火墙
cat /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take ...
- Optional的理解和使用
1.Optional 到底是什么? Optional 是一个包装类.类中包装的对象可以为 NULL 或非 NULL.简单说就是把 NULL 包了一层,防止直接对 NULL 操作报NPE. 2.Opti ...
- [转帖].NET导出Excel的四种方法及评测
.NET导出Excel的四种方法及评测 https://www.cnblogs.com/sdflysha/p/20190824-dotnet-excel-compare.html 导出Excel是.N ...
- Kubernetes组件-DaemonSet
⒈简介 Replicationcontroller和ReplicaSet都用于在Kubermetes集群上部署运行特定数量的pod.但是,当某些情况下我们希望在集群中的每个节点上运行同一个指定的pod ...
- C++ Primer练习题day1
/* 练习1.1略 练习1.2.改写程序,让他返回-1. 练习1.3.编写程序,在标准的输出上打印Hello,World. */ #include<iostream> int main() ...
- c++ vector容器
https://www.runoob.com/w3cnote/cpp-vector-container-analysis.html