python中同步、多线程、异步IO、多线程对IO密集型的影响
1、常见并发类型
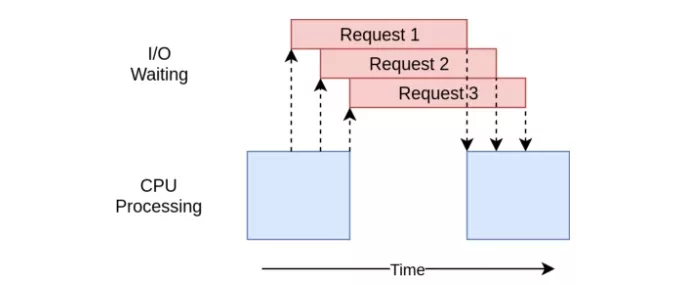
I/ O密集型:

蓝色框表示程序执行工作的时间,红色框表示等待I/O操作完成的时间。此图没有按比例显示,因为internet上的请求可能比CPU指令要多花费几个数量级的时间,所以你的程序可能会花费大部分时间进行等待。
CPU密集型:
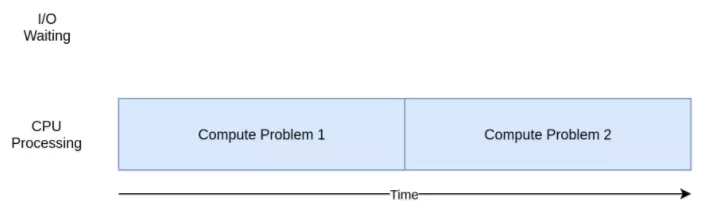
IO密集型程序将时间花在cpu计算上。
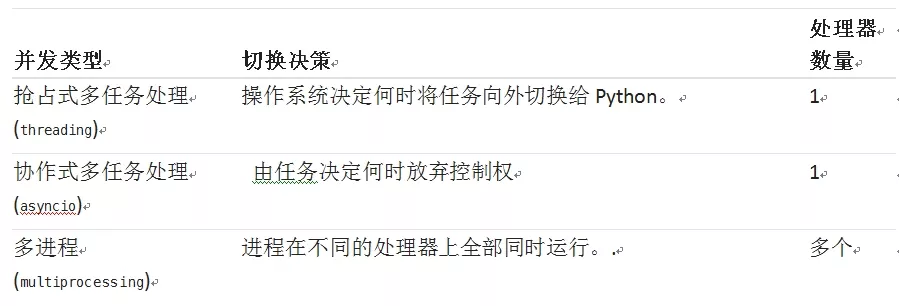
常见并发类型以及区别:
2、同步版本
我们将使用requests访问100个网页,使用同步的方式,requests的请求是同步的,所以代码就很好写了。
同步的版本代码逻辑简单,编写也会很相对容易。
import requests
import time
def download_site(url,session):
with session.get(url) as response:
print(len(response.content)) def download_all_site(sites):
with requests.Session() as session:
for url in sites:
download_site(url,session) if __name__ =="__main__":
sites = ["https://www.baidu.com","https://www.jython.org"] * 50
start_time = time.time()
download_all_site(sites)
end_time = time.time()
print("执行时间:%s" % (end_time - start_time) + "秒")
#download_site()只从一个URL下载内容并打印其大小
#需要知道的是我们这里没有使用requests.get(),而使用了session.get(),我们使用requests.Session()创建了一个Session对象,每次请求使用了session.get(url,因为可以让requests运用一些神奇的网络小技巧,从而真正使程序加速。
#执行时间:33.91123294830322秒
3、多线程
ThreadPoolExecutor,: ThreadPoolExecutor =Thread+Pool+ Executor。
你已经了解了Thread部分。那只是我们之前提到的一个思路。Pool部分是开始变得有趣的地方。这个对象将创建一个线程池,其中的每个线程都可以并发运行。最后,Executor是控制线程池中的每个线程如何以及何时运行的部分。它将在线程池中执行请求。
对我们很有帮助的是,标准库将ThreadPoolExecutor实现为一个上下文管理器,因此你可以使用with语法来管理Threads池的创建和释放。
一旦有了ThreadPoolExecutor,你就可以使用它方便的.map()方法。此方法在列表中的每个站点上运行传入函数。最重要的是,它使用自己管理的线程池自动并发地运行它们。
来自其他语言,甚至Python 2的人可能想知道,在处理threading时,管理你习惯的细节的常用对象和函数在哪里,比如Thread.start()、Thread.join()和Queue。
这些都还在那里,你可以使用它们来实现对线程运行方式的精细控制。但是,从Python 3.2开始,标准库添加了一个更高级别的抽象,称为Executor,如果你不需要精细控制,它可以为你管理许多细节。
本例中另一个有趣的更改是,每个线程都需要创建自己的request . Session()对象。当你查看requests的文档时,不一定就能很容易地看出,但在阅读这个问题(https://github.com/requests/requests/issues/2766 )时,你会清晰地发现每个线程都需要一个单独的Session。
这是threading中有趣且困难的问题之一。因为操作系统可以控制任务何时中断,何时启动另一个任务,所以线程之间共享的任何数据都需要被保护起来,或者说是线程安全的。不幸的是,requests . Session()不是线程安全的。
根据数据是什么以及如何你使用它们,有几种策略可以使数据访问变成线程安全的。其中之一是使用线程安全的数据结构,比如来自 Python的queue模块的Queue。
这些对象使用低级基本数据类型,比如threading.Lock,以确保只有一个线程可以同时访问代码块或内存块。你可以通过ThreadPoolExecutor对象间接地使用此策略。
import requests
import concurrent.futures
import threading
import time #创建线程池
thread_local= threading.local() def get_session():
if not getattr(thread_local,"session",None):
thread_local.session = requests.Session()
return thread_local.session def download_site(url):
session = get_session()
with session.get(url) as response:
print(len(response.content)) def download_all_site(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as exector:
exector.map(download_site,sites) if __name__ =="__main__":
sites = ["https://www.baidu.com","https://www.jython.org"] * 50
start_time = time.time()
download_all_site(sites)
end_time = time.time()
print("执行时间:%s" % (end_time - start_time) + "秒")
#执行时间:6.152076244354248秒
这里要使用的另一种策略是线程本地存储。Threading.local()会创建一个对象,它看起来像一个全局对象但又是特定于每个线程的。在我们的示例中,这是通过threadLocal和get_session()完成的:
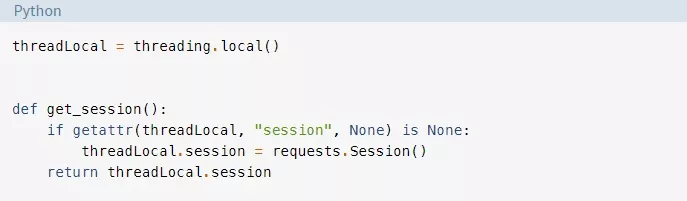
ThreadLocal是threading模块中专门用来解决这个问题的。它看起来有点奇怪,但是你只想创建其中一个对象,而不是为每个线程创建一个对象。对象本身将负责从不同的线程到不同的数据的分开访问。
当get_session()被调用时,它所查找的session是特定于它所运行的线程的。因此,每个线程都将在第一次调用get_session()时创建一个单个的会话,然后在整个生命周期中对每个后续调用使用该会话。
最后,简要介绍一下选择线程的数量。你可以看到示例代码使用了5个线程。随意改变这个数字,看看总时间是如何变化的。你可能认为每次下载只有一个线程是最快的,但至少在我的系统上不是这样。我在5到10个线程之间找到了最快的结果。如果超过这个值,那么创建和销毁线程的额外开销就会抵消程序节省的时间。
这里比较困难的答案是,从一个任务到另一个任务的正确线程数不是一个常量。需要进行一些实验来得到。
注意:request . Session()不是线程安全的。这意味着,如果多个线程使用同一个Session,那么在某些地方可能会发生上面描述的交互类型问题。
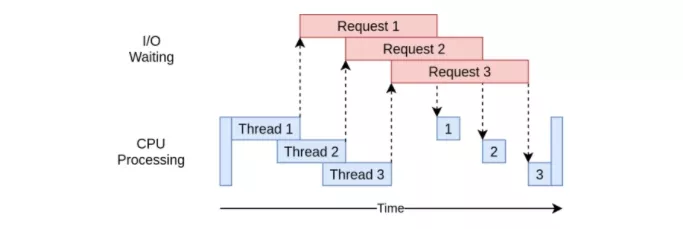
多线程代码的执行时序表:
4、异步IO
asyncio的一般概念是一个单个的Python对象,称为事件循环,它控制每个任务如何以及何时运行。事件循环会关注每个任务并知道它处于什么状态。在实际中,任务可以处于许多状态,但现在我们假设一个简化的只有两种状态的事件循环。
就绪状态将表明一个任务有工作要做,并且已经准备好运行,而等待状态意味着该任务正在等待一些外部工作完成,例如网络操作。
我们简化的事件循环维护两个任务列表,每一个对应这些状态。它会选择一个就绪的任务,然后重新启动它。该任务处于完全控制之中,直到它配合地将控制权交还给事件循环为止。
当正在运行的任务将控制权交还给事件循环时,事件循环将该任务放入就绪或等待列表中,然后遍历等待列表中的每个任务,以查看I/O操作完成后某个任务是否已经就绪。时间循环知道就绪列表中的任务仍然是就绪的,因为它知道它们还没有运行。
一旦所有的任务都重新排序到正确的列表中,事件循环将选择下一个要运行的任务,然后重复这个过程。我们简化的事件循环会选择等待时间最长的任务并运行该任务。此过程会一直重复,直到事件循环结束。
asyncio的一个重要之处在于,如果没有刻意去释放控制权,任务是永远不会放弃控制权的。它们在操作过程中从不会被打断。这使得我们在asyncio中比在threading中能更容易地共享资源。你不必担心代码是否是线程安全的。
import time
import asyncio
from aiohttp import ClientSession
async def download_site(session,url):
global i
try:
async with session.get(url) as response:
i=i+1
print(i)
return await response.read()
except Exception as e:
pass
async def download_all_site(sites):
async with ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.create_task(download_site(session,url))
tasks.append(task)
result = await asyncio.gather(*tasks) #等待一组协程运行结束并接收结果
print(result) if __name__ =="__main__":
i=0
sites = ["http://www.360kuai.com/","https://www.jython.org"] * 50
start_time = time.time()
asyncio.run(download_all_site(sites))
end_time = time.time()
print("执行时间:%s" % (end_time - start_time) + "秒")
#执行时间:5.29184889793396秒
异步IO的执行时序表:
asyncio版本的问题
此时asyncio有两个问题。你需要特殊的异步版本的库来充分利用asycio。如果你只是使用requests下载站点,那么速度会慢得多,因为requests的设计目的不是通知事件循环它被阻塞了。随着时间的推移,这个问题变得微不足道,因为越来越多的库包含了asyncio。
另一个更微妙的问题是,如果其中一个任务不合作,那么协作多任务处理的所有优势都将不存在。代码中的一个小错误可能会导致任务运行超时并长时间占用处理器,使需要运行的其他任务无法运行。如果一个任务没有将控制权交还给事件循环,则事件循环无法中断它。
考虑到这一点,我们来开始讨论一种完全不同的并发性——multiprocessing。
python中同步、多线程、异步IO、多线程对IO密集型的影响的更多相关文章
- IO中同步、异步与阻塞、非阻塞的区别
一.同步与异步同步/异步, 它们是消息的通知机制 1. 概念解释A. 同步所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回. 按照这个定义,其实绝大多数函数都是同步调用(例如si ...
- IO中同步、异步与阻塞、非阻塞的区别(转)
转自:http://blog.chinaunix.net/uid-26000296-id-3754118.html 一.同步与异步同步/异步, 它们是消息的通知机制 1. 概念解释A. 同步所谓同步, ...
- 【Java_基础】并发、并行、同步、异步、多线程的区别
1. 并发:位于同一个处理器上的多个已开启未完成的线程,在任意一时刻系统调度只能让一个线程获得CPU资源运行,虽然这种调度机制有多种形式(大多数是以时间片轮巡为主).但无论如何,都是通过不断切换需要运 ...
- Linux中同步与异步、阻塞与非阻塞概念以及五种IO模型
1.概念剖析 相信很多从事linux后台开发工作的都接触过同步&异步.阻塞&非阻塞这样的概念,也相信都曾经产生过误解,比如认为同步就是阻塞.异步就是非阻塞,下面我们先剖析下这几个概念分 ...
- 谈IO中的阻塞和非阻塞,同步和异步及三种IO模型
什么是同步和异步? 烧水,我们都是通过热水壶来烧水的.在很久之前,科技还没有这么发达的时候,如果我们要烧水,需要把水壶放到火炉上,我们通过观察水壶内的水的沸腾程度来判断水有没有烧开.随着科技的发展,现 ...
- 在JavaScript中同步与异步
在JavaScript中,一个线程执行的时候不依靠其他线程处理完毕我们称为异步,相反一个线程必须等待直到另一个线程处理完毕我们则称为同步.打个比方: (1)同步就是你在煮方便面的时候必须等水开了,你才 ...
- python 37 同步、异步调用
目录 1. 阻塞与非阻塞 2. 同步与异步 2.1 异步调用 2.2 同步调用 2.3 异步调用回收的第一种方式 3. 异步调用+回调函数 3.1 requests模块 3.2 异步调用回收的第二种方 ...
- 转 WCF中同步和异步通讯总结
我这样分个类: WCF中, 以同步.异步角度考虑通讯的方式分为四种:跨进程同步.跨进程异步.发送队列端同步.发送队列端异步.之所以造成这样的结果源于两个因素,一个是传统概念上的同异步,一个是对于WCF ...
- HTTP请求中同步与异步有什么不同
普通的B/S模式就是同步,而AJAX技术就是异步,当然XMLHttpReques有同步的选项. 同步:提交请求->等待服务器处理->处理完毕返回.这个期间客户端浏览器不能干任何事. 异步: ...
随机推荐
- PHP冒泡排序原生代码
//冒泡排序 $arr=array(23,5,26,4,9,85,10,2,55,44,21,39,11,16,55,88,421,226,588); $n =count($arr); //echo ...
- SQL Server 数据库设计、命名、编码规范
https://blog.csdn.net/songguozhi/article/details/5858159 SQL Server 数据库设计.命名.编码规范
- 1-mybatis-概览
mybatis 当前包如下: 1 annotations 注解相关配置 2 binding 绑定 3 builder 建造器, 主要使用的建造者模式 4 cache 缓存相关 5 cursor 游标 ...
- pandas之数据选择
pandas中有三种索引方法:.loc,.iloc和[],注意:.ix的用法在0.20.0中已经不建议使用了 import pandas as pd import numpy as np In [5] ...
- python 连接mysql数据库:pymysql
示例:import pymysql conn=pymysql.connect( host="127.0.0.1", #数据库IP port=3306, #数据库端口 user=&q ...
- 阶段3 3.SpringMVC·_05.文件上传_2 文件上传之传统方式上传代码回顾
先创建表单 enctype选择multipart/form-data 把表单分成几个部分 导入对应的包 解析request拿到上传的文件对象 拿到某个路径的绝对路径 以后什么异常全抛出,改成Excep ...
- Sass简单使用
Sass是成熟.稳定.强大的CSS预处理器,而SCSS是Sass3版本当中引入的新语法特性,完全兼容CSS3的同时继承了Sass强大的动态功能. 特性概览 CSS书写代码规模较大的Web应用时,容易造 ...
- ubuntu下wps的安装
(一)安装 1)下载:WPS For Linux http://community.wps.cn/download/ 下载wps-office_10.1.0.5672~a21_amd64.deb 2) ...
- python programming作业11 Qt designer (打地鼠,不是很完美)
不导包的代码 from PyQt5 import QtCore, QtGui, QtWidgets import sys from PyQt5.QtWidgets import QApplicati ...
- 分布式架构-Redis 从入门到精通 完整案例 附源码
导读 篇幅较长,干货十足,阅读需要花点时间,全部手打出来的字,难免出现错别字,敬请谅解.珍惜原创,转载请注明出处,谢谢~! NoSql介绍与Redis介绍 什么是Redis? Redis是用C语言开发 ...