SpringCloud之Ribbon负载均衡配置
一、负载均衡解决方案分类及特征
业界主流的负载均衡解决方案有:
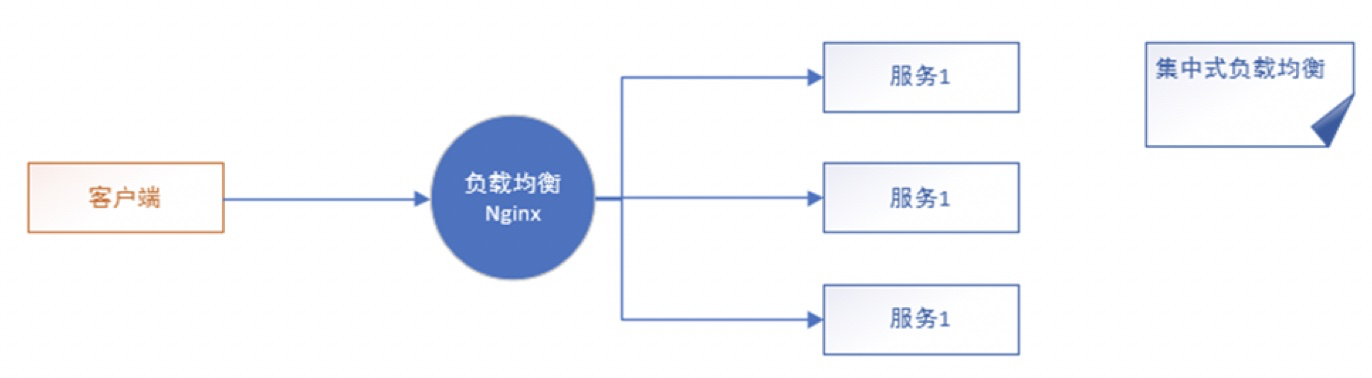
1.1 集中式负载均衡
即在客户端和服务端之间使用独立的负载均衡设施(可以是硬件,如F5, 也可以是软件,如nginx), 由该设施负责把访问请求通过某种策略转发至服务端。
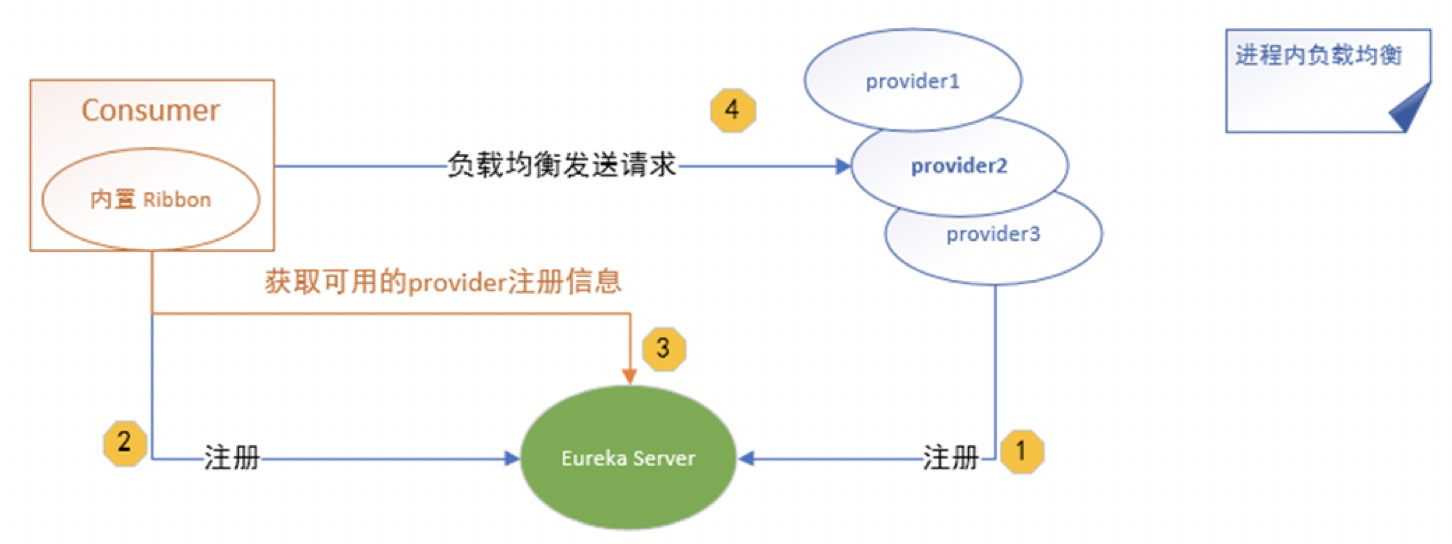
1.2 进程内负载均衡
将负载均衡逻辑集成到客户端组件中,客户端组件从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选择出一个合适的服务端发起请求。Ribbon就是一个进程内的负载均衡实现。
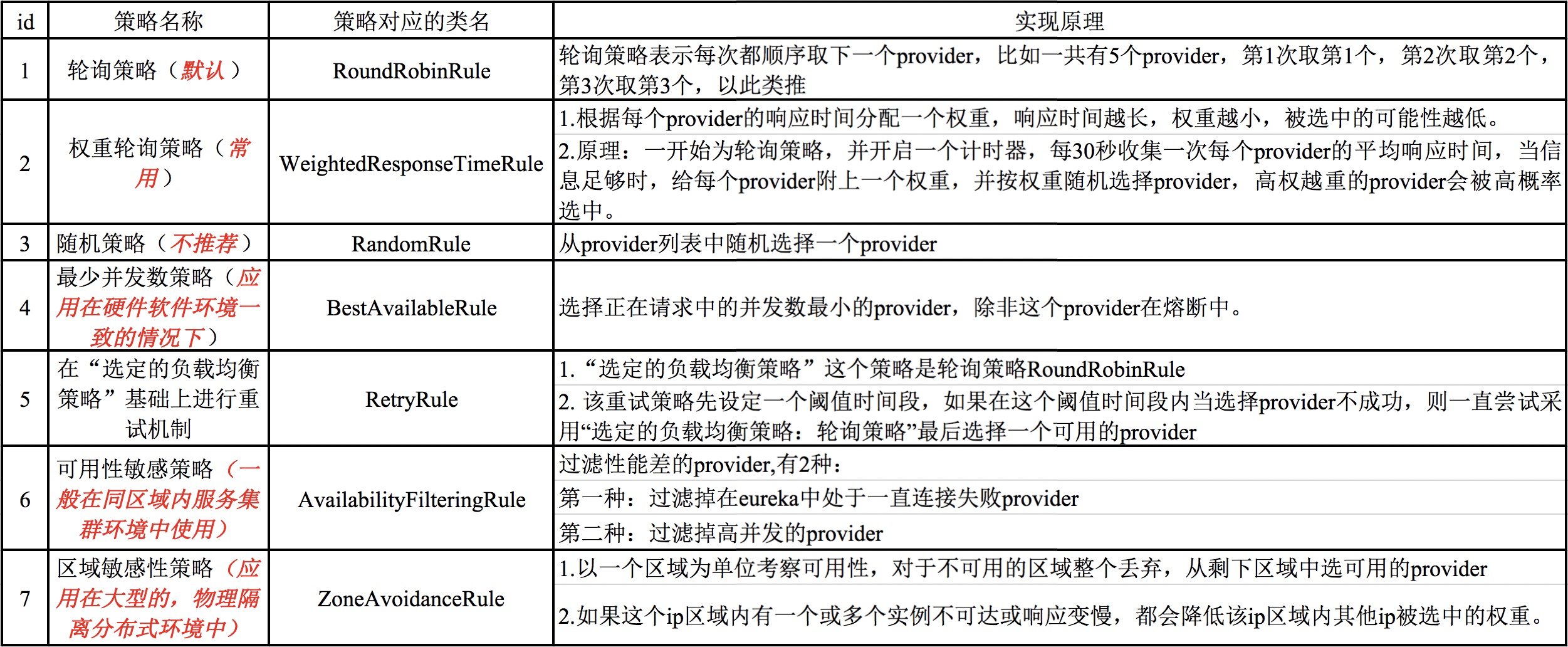
二、Ribbon常用负载均衡策略
Ribbon就属于进程内负载均衡,它只是一个类库,集成于Eureka Client进程,Eureka Client进程通过访问注册中心Eureka Server发现服务列表,发现的服务列表信息是由ribbon来管理的。当访问Application Service的时候,Application Client会通过ribbon来找到合适的Application Service地址信息,并发起远程调用请求。
Ribbon的负载均衡策略是通过不同的类型来实现的,下表详细介绍一些常用负载均衡策略及对应的Ribbon策略类。
三、指定负载均衡策略
可以通过全局配置文件来改变当前环境中使用的Ribbon负载均衡策略。在Ribbon中没有通用的负载均衡策略配置方案。
#设置负载均衡策略 eureka-application-service为调用的服务的名称
eureka-application-service.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RandomRule
四、 点对点直连测试
在商业开发中,经常会更新或升级部分服务。当系统某服务出现bug后,需要修改并再次测试。如果还是通过生产环境中的注册中心来注册发现服务,那么影响面太大。这个时候可以考虑将Application Service注册到一个测试Eureka Server上,使用点对点直连的方式让Application Client直接访问Application Service,打到测试的目的。
使用点对点直连测试很容器。只要在启动的时候避免注册和发现服务(删除启动类上的@EnableEurekaClient注解),并在全局配置文件中配置下述内容即可。(全局配置文件中关于Eureka Server的配置可删除)。
spring.application.name=eureka-application-client
server.port=8080 # 点对点直连是不发现服务,不是不注册服务。
# 任何Eureka Client都必须注册。如果没有配置Eureka Server节点列表,则注册失败。Eureka client无法正常启动。
eureka.client.serviceUrl.defaultZone=http://eurekaserver1:111111@eurekaserver1:8761/eureka/,http://eurekaserver2:222222@eurekaserver2:8761/eureka/ #点对点直连测试配置
# 关闭ribbon访问注册中心Eureka Server发现服务,但是服务依旧会注册。
ribbon.eureka.enabled=false
# 配置服务列表,其中eureka-application-service代表要访问的服务的应用名,如果有多个服务结点组成集群,多个节点的配置信息使用逗号','分隔。
# 配置服务列表,需要配置要调用的服务的名字和服务所在的位置。
# 服务的名字,就是Application Service中配置的spring.application.name。
# 服务的位置,就是服务的所在ip和端口。
# 如果服务位置有多个,也就是服务集群,那么使用逗号','分割多个服务列表信息。
eureka-application-service.ribbon.listOfServers=localhost:8083
SpringCloud之Ribbon负载均衡配置的更多相关文章
- spring-cloud: eureka之:ribbon负载均衡配置(一)
spring-cloud: eureka之:ribbon负载均衡配置(一) 比如我有: 一个eureka服务:8761 两个user用户服务: 7900/7901端口 一个movie服务:8010 1 ...
- Spring-cloud之Ribbon负载均衡的使用及负载均衡策略配置(与Eurka配合使用)
什么是Ribbon,ribbon有什么用,个人先总结一下(不正确请提出讨论):Ribbon是基于客户端的负载均衡器,为我们提供了多样的负载均衡的方案,比如轮询,最小的并发请求的server,随机ser ...
- SpringCloud系列——Ribbon 负载均衡
前言 Ribbon是一个客户端负载均衡器,它提供了对HTTP和TCP客户端的行为的大量控制.我们在上篇(猛戳:SpringCloud系列——Feign 服务调用)已经实现了多个服务之间的Feign调用 ...
- 浅谈SpringCloud (三) Ribbon负载均衡
什么是负载均衡 当一台服务器的单位时间内的访问量越大时,服务器压力就越大,大到超过自身承受能力时,服务器就会崩溃.为了避免服务器崩溃,让用户有更好的体验,我们通过负载均衡的方式来分担服务器压力. 我们 ...
- SpringCloud:Ribbon负载均衡
1.概述 Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端 负载均衡的工具. 简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客 ...
- 四(2)、springcloud之Ribbon负载均衡
2.Ribbon负载均衡 Ribbon在工作时分成两步第一步先选择 EurekaServer ,它优先选择在同一个区域内负载较少的server. 第二步再根据用户指定的策略,在从server取到的 ...
- spring cloud: zuul(三): ribbon负载均衡配置
zuul的routes配置下path/url组合不支持负载均衡 下面介绍zuul的routes配置下的path/serviceId负载均衡配置 spring-boot-user微服务开启了:7901, ...
- SpringCloud之Ribbon负载均衡及Feign消费者调用服务
目的: 微服务调用Ribbon Ribbon负载均衡 Feign简介及应用 微服务调用Ribbon Ribbon简介 1. 负载均衡框架,支持可插拔式的负载均衡规则 2. 支持多种协议,如HTTP.U ...
- Spring-Cloud之Ribbon负载均衡-3
一.负载均衡是指将负载分摊到多个执行单元上,常见的负载均衡有两种方式.一种是独立进程单元,通过负载均衡策略,将请求转发到不同的执行单元上,例如 Ngnix .另一种是将负载均衡逻辑以代码的形式封装到服 ...
随机推荐
- nginx ssl
SSL 私钥/etc/pki/CA/ (umask 077;openssl genrsa -out private/cakey.pem 2048) 自签证书 openssl req -new -x50 ...
- 读取yml 文件中的参数
第一种方法: yml 文件: spring: main: allow-bean-definition-overriding: true cloud: consul: host: 192.168.1.1 ...
- uni-app 使用Vuex+ (强制)登录
一.在项目的根目录下新建一个store文件夹,然后在文件夹下新建一个index.js文件 二.在新建的index.js下引入vue和vuex,具体如下: //引入vue和vuex import Vue ...
- ffprobe读取音视频元数据信息,json格式输出
命令格式: ffprobe -v quiet -show_format -show_streams -print_format json F:\temp\test1566606924822.wav 输 ...
- jeecg启动报错“com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server.”的解决办法
在运行"maven build"-->"tomcat:run"之后,报如下错误: com.mysql.jdbc.exceptions.jdbc4.MySQ ...
- iOS-上传头像的使用
static NSString *const uploadSuccess = @"更改头像成功"; @interface DMAccountInformationViewContr ...
- 《Java语言程序设计》
课堂测试:用户需求:英语的26 个字母的频率在一本小说中是如何分布的?某类型文章中常出现的单词是什么?某作家最常用的词汇是什么?<Harry Potter> 中最常用的短语是什么,等等. ...
- 模板引擎doT.js用法详解
作为一名前端攻城师,经常会遇到从后台ajax拉取数据再显示在页面的情境,一开始我们都是从后台拉取再用字符串拼接的方式去更达到数据显示在页面! <!-- 显示区域 --> <div i ...
- [Cometoj#4 B]奇偶性_打表
奇偶性 题目链接:https://cometoj.com/contest/39/problem/B?problem_id=1577 数据范围:略. 题解: 因为$f$的构造原因,很容易找到规律. 进而 ...
- [转帖]三款Nehalem至强5500塔式服务器横评对决(4)
三款Nehalem至强5500塔式服务器横评对决(4) http://tech.sina.com.cn/b/2009-12-14/05051172233_4.shtml 可以看到两路服务器的设置 基本 ...