多线程(5) — JDK的并发容器
JDK提供了一些高效的并发容器,下面介绍几个
- ConcurrentHashMap:这是个高效的并发HashMap,可以理解为一个线程安全的HashMap。
- CopyOnWriteArrayList:这是一个List,从名字看就知道它和ArrayList是一族的,在读多写少的场合,这个List的性能非常好,远远优于Vector。
- ConcurrentLinkedQueue:高效的并发队列,使用链表实现,可以看作一个线程安全的LinkedList。
- BlockingQueue:这是一个接口,JDK内部通过链表、数组等方式实现了这个接口,表示阻塞队列,非常适合作为数据共享的通道。
- ConcurrentSkipListMap:跳表的实现,这是个map,使用跳表的数据结构进行快速查找。
1. 线程安全的HashMap
Collections.synchronizedMap()方法包装我们的HashMap,可以产生一个线程安全的HashMap。
public static Map map = Collections.synchronizedMap(new HashMap());
Collections.synchronizedMap()产生一个SynchronizedMap的Map,它使用委托将自己所有Map相关的功能交给传入的HashMap实现,而自己主要负责保证线程安全。
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L; private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap里包装了一个map,通过mutex实现对这个map的互斥操作,实现线程的安全,其中的一些实现方法如下:
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map<? extends K, ? extends V> map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
这个包装的Map可以满足线程安全的要求,但是在多线程的性能表现里不是很好,无论对map是读是写都要获得mutex锁,导致对map的操作全部进入等待状态,并发不高的情况下是可以的,如果高并发的话,我们可以使用另外一个类ConcurrentHashMap。这个的线程是绝对安全的,并且并发的效率还很高。
2. 线程安全的List
Vector是线程安全的,而ArrayList和LinkedList不是线程安全的,可以使用Collections.synchronizedList()方法包裹任意List:
public static List list = Collections.synchronizedList(new ArrayList<String>());
这样生成的List就是安全的了
3. 高效读写的队列:深度剖析ConcurrentLinkedQueue类
这个队列使用链表作为数据结构,是高并发环境中性能最好的队列,线程安全完全是由CAS操作和队列的算法来保证的。作为一个链表,自然定义链表内节点,node如下:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
item是用来表示目标元素的。next表示下一个节点,这样就环环相扣了。对Node的进行操作时,使用CAS。
boolean casItem(E cmp, E val) { //cmp是期望值,val是目标值,当前值等于cmp时会将目标值设置为val
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
方法castItem()表示设置当前Node的item值,他需要俩参数,第一个值为参数的期望值,第二个参数是设置目标值,也就是当前值等于cmp期望值时就会将目标设置为val,同样casNext方法也是类似,但是用于next字段,而不是item字段。
ConcurrentLinkedQueue类内部有两个重要的字段,head和tail,分别表示链表的头和尾,他们都是Node类型。对于head,不会是null,通过head和succ()后继方法一定能完整遍历整个链条。对于tail,表示队列的末尾。但是这个类在运行时允许链表处于多个不同状态,拿tail来说,tail的更新并不是及时的,可能产生拖延
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p 是最后一个节点
if (p.casNext(null, newNode)) {
// CAS成功了的话,e会成为队列中的一个节点,newNode会活化
if (p != t) // 每两次更新一个tail
casTail(t, newNode); // Failure is OK.
return true;
}
// 竞争失败会再次尝试
}
else if (p == q)
// 遇到哨兵节点从head开始遍历,但如果tail被修改,则使用tail(因为可能被修改正确了)
p = (t != (t = tail)) ? t : head;
else
// 取下一个节点或者最后一个节点
p = (p != t && t != (t = tail)) ? t : q;
}
}
整个方法的核心是一个没有出口的 for 循环,直到尝试成功才会退出,这符合CAS操作流程。当第一个元素进来时,队列是空的,p.next()为null。将p的next节点赋值为newNode,也就是将新的元素加入队列中。此时p==t成立,不会执行更新tail末尾。如果casNext()方法成功,则程序直接返回,如果失败,则再进行一次循环尝试,直到成功,因此增加一个元素后,tail不会更新。
当程序增加第2个元素时,由于t还在head的位置,p.next指向第一个元素,因此q不等于null不是最后的节点,于是程序会取下一个节点直到取到最后一个节点,此时它的next是null,故在下次循环时q==null是true,会更新自己next,如果更新成功,那么此时 p != t,会更新t所在位置,将t移动到链表的最后。
p==q的情况其实当遇到哨兵节点时的处理,所谓哨兵节点就是next指向自己的节点,这种节点存在的意义不大,主要表示删除的节点或者空节点,因为通过next无法取到后续节点,所以直接返回head,从头开始遍历。一旦在执行的过程中发送tail被其他线程修改的情况,则进行一次打赌,使用新的tail作为链表的末尾。
下面这段代码在理解上给说明一下:
p = (t != (t = tail)) ? t : head;
首先“!=”并不是原子性操作,也是可以被中断的,也就是说,在执行“!=”时,程序会先取得 t 的值,再执行t=tail,再取得t的新值,然后比较这两个值是否相等。单线程环境下这个肯定不会成立,但是在高并发情况下,在获得左边的 t 后,右边的 t 被其他线程修改了,这样 t != t 就成立了。在比较过程中tail被其他线程修改,当再次赋值给t的时候,导致了左右不等了,这时候就用新的tail作为链表的尾部。
4. 高效读取:不变模式下的CopyonWriteArrayList类
如果某个系统的读取操作很多,那么 每次读取都加锁势必会造成资源的很大浪费,因为读读之间不冲突的,但是写操作会阻塞读操作和写操作的。为了将读取的性能发挥到极致,CopyOnWriteArrayList类在读读之间,读写之间不加锁,只在写写之间加锁,这样性能就提升很多了,实现原理是:在写如操作时进行一次自我复制,也就是在List修改时,不修改原有内容而对数据进行一次复制,将修改的内容写入副本,再用修改后的副本替换原来的数据,这样就保证了写操作不会影响读。
下面代码是读取的实现,可见读取操作没有任何同步控制和锁操作,原因是array不会发生修改,只会被另外一个array替换,因此可以保证数据安全。
private volatile transient Object[] array;
final Object[] getArray() {
return array;
}
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}
写入操作就比较麻烦一些了,加了锁操作,仅用于控制写-写情况。代码内部会对array完整复制,可生成一个新的数组newElements,将新元素加入新数组,再用这个新的替换老的数组,修改完成,整个过程不会影响读取,修改完成后,读取线程会立即察觉array的变化,因为array是volatile类型的。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
5. 随机数据结构:跳表(SkipList)
跳表可以用来快速查找的数据结构,类似平衡树。区别是:平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整而跳表的插入和删除只需要对整个数据结构的局部进行操作即可。这样在高并发情况下,平衡树需要一个全局锁保证安全,而跳表只要部分锁就可以了。这样跳表在高并发环境下性能会提高。跳表另外一个特点就是随机算法,其本质是同时维护多个链表,并且链表是分层的。
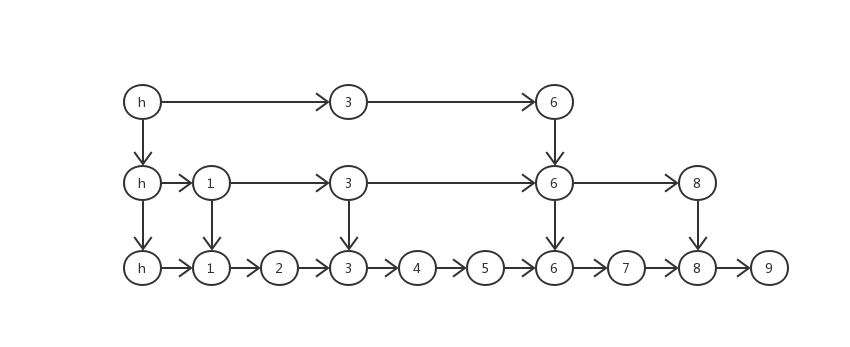
跳表内所有元素都是排序的,查找时先从顶级链表开始找,一旦发现当前链表的取值所在范围就会进入下一层。比如上图中查找7的话,从顶层开始因此可以快速跳过小于7的,第二层8大于7,所以从6进入下一层,这样在第三层找到了7。此外跳表内所有元素都是有序的,实现这一数据结构类是ConcurrentSkipListMap。内部实现由几个关键的数据结构组成,首先是Node,一个Node一个节点,里面有key和value俩元素,每个Node还会指向下一个Node,因此还有个Next
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
对node操作使用CAS方法,CASValue()用来设置value的值,casNext()方法用来设置next字段。
boolean casValue(Object cmp, Object val) {
return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);
}
boolean casNext(Node<K,V> cmp, Node<K,V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
另外一个重要的数据结构是index,顾名思义,这个索引内部包装Node,同时增加了向下和向右的引用。整个跳表就是根据Index进行全网组织的
static class Index<K,V> {
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right;
此外,对于每一层的表头还需要记录当前处于哪一层,还需要一个HeadIndex的数据结构,表示链表头部的第一个Index,继承自Index
static final class HeadIndex<K,V> extends Index<K,V> {
final int level;
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
多线程(5) — JDK的并发容器的更多相关文章
- JDK的并发容器
除了提供诸如同步控制,线程池等基本工具外,为了提高开发人员的效率,JDK已经为我们准备了一大批好用的并发容器,这些容器都是线程安全的,可以大大减少开发工作量.你可以在里面找到链表.Hash ...
- JAVA 多线程随笔 (三) 多线程用到的并发容器 (ConcurrentHashMap,CopyOnWriteArrayList, CopyOnWriteArraySet)
1.引言 在多线程的环境中,如果想要使用容器类,就需要注意所使用的容器类是否是线程安全的.在最早开始,人们一般都在使用同步容器(Vector,HashTable),其基本的原理,就是针对容器的每一个操 ...
- java多线程系列五、并发容器
一.ConcurrentHashMap 1.为什么要使用ConcurrentHashMap 在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,HashMap在 ...
- Java并发—同步容器和并发容器
简述同步容器与并发容器 在Java并发编程中,经常听到同步容器.并发容器之说,那什么是同步容器与并发容器呢?同步容器可以简单地理解为通过synchronized来实现同步的容器,比如Vector.Ha ...
- 多线程之并发容器ConcurrentHashMap(JDK1.6)
简介 ConcurrentHashMap 是 util.concurrent 包的重要成员.本文将结合 Java 内存模型,分析 JDK 源代码,探索 ConcurrentHashMap 高并发的具体 ...
- 多线程并发容器CopyOnWriteArrayList
原文链接: http://ifeve.com/java-copy-on-write/ Copy-On-Write简称COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容 ...
- Java多线程(六) —— 线程并发库之并发容器
参考文献: http://www.blogjava.net/xylz/archive/2010/07/19/326527.html 一.ConcurrentMap API 从这一节开始正式进入并发容器 ...
- 多线程六 同步容器&并发容器
同步容器(使用的是synchronized,并且不一定是百分百安全) 本篇续 -- 线程之间的通信 ,介绍java提供的并发集合,既然正确的使用wait和notify比较困难,java平台为我们提供了 ...
- Java多线程-并发容器
Java多线程-并发容器 在Java1.5之后,通过几个并发容器类来改进同步容器类,同步容器类是通过将容器的状态串行访问,从而实现它们的线程安全的,这样做会消弱了并发性,当多个线程并发的竞争容器锁的时 ...
随机推荐
- 在默认使用apache中央仓库时, 报错 protocol_version
https://cloud.tencent.com/developer/ask/136221/answer/241408 2018年6月,为了提高安全性和符合现代标准,不安全的TLS 1.0和1.1协 ...
- 1059 Prime Factors(25 分)
Given any positive integer N, you are supposed to find all of its prime factors, and write them in t ...
- 前端逼死强迫症系列之javascript续集
一.javascript函数 1.普通函数 function func(){ } 2.匿名函数 setInterval(function(){ console.log(123); },5000) 3. ...
- c++ 珊格画椭圆
#ifndef _TEST_H #define _TEST_H #include <iostream> #include <math.h> using namespace st ...
- Hive和Hadoop
我最近研究了hive的相关技术,有点心得,这里和大家分享下. 首先我们要知道hive到底是做什么的.下面这几段文字很好的描述了hive的特性: 1.hive是基于Hadoop的一个数据仓库工具,可以将 ...
- ngx.shared.DICT.incr 详解
ngx.shared.DICT.incr 原文: ngx.shared.DICT.incr syntax: newval, err, forcible? = ngx.shared.DICT:incr( ...
- chrome浏览器备忘
记录日常使用Chrome遇到的问题. audio控件播放音频问题 打开http://www.cdfive.com,发现音乐没有自动播放,F12打开控制台发现有如下报错: Uncaught (in pr ...
- 关于Vue.use()详解
问题 相信很多人在用Vue使用别人的组件时,会用到 Vue.use() .例如:Vue.use(VueRouter).Vue.use(MintUI).但是用 axios时,就不需要用 Vue.use( ...
- OpenJudge计算概论-奥运奖牌计数
/*===================================================================== 奥运奖牌计数 总时间限制: 1000ms 内存限制: 6 ...
- Angular中的routerLink 跳转页面和默认路由
1.创建新项目 2.创建home news newscontent 组件 3.找到app-rounting-moudle.ts配置路由 1)引入组件 import { HomeComponent } ...