Linux内存简单汇总
Linux内存主要用来存储系统和应用程序的指令,数据,缓存等
一,内存映射
1,内核给每个进程提供一个独立的虚拟机地址空间,并且这个地址空间是连续的
2,虚拟地址空间内部又被分为内核空间和用户空间
3,32位和64位系统的虚拟地址空间
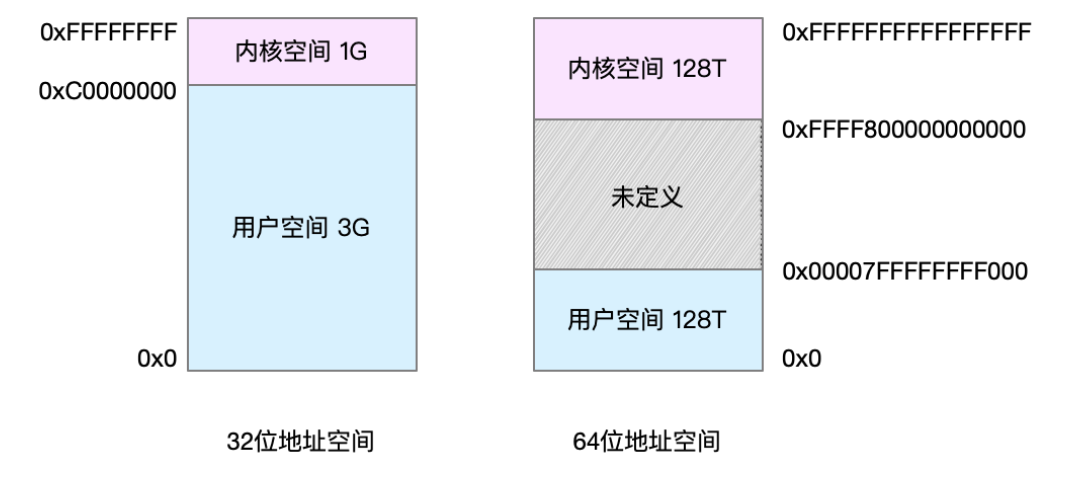 32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间。而 64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的
32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间。而 64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的
4,进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存
5,只有实际使用的虚拟内存才会被分配物理内存,通过内存映射来管理
6,内存映射,就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张 表,记录虚拟地址与物理地址的映射关系
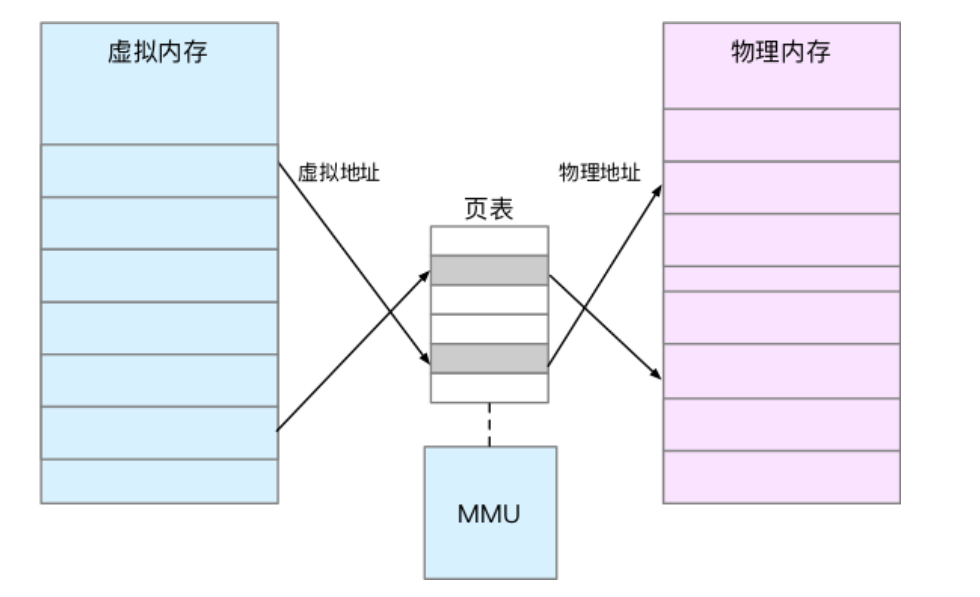
7,页表存储在内存管理单元[MMU](https://blog.csdn.net/u010442934/article/details/79900449)中
8,进程访问虚拟地址在页表中查不到时,系统会产生一个缺页异常
9,TLB(Translation Lookaside Buffer,转译后备缓冲器)会影响 CPU 的内存访问性能 ,TLB是MMU中页表的高速缓存,。于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少 TLB 的刷新次数,就可以提高 TLB 缓存的使用率,进而提高 CPU 的内存访问性能
10,MMU 并不以字节为单位来管理内存,而是规定了一个内存映射的最小单位,也就是页,通常是 4 KB 大小,每一次内存映射,都需要关联 4 KB 或者 4KB整数倍的内存空间
11, 为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)
多级页表
多级页表是把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移,由于虚拟内存空间通常只使用了一小部分,那么多级页表就只保存这些使用中的区块,这样就可以减少页表的项数
其中Linux就用了四级页表来管理内存页
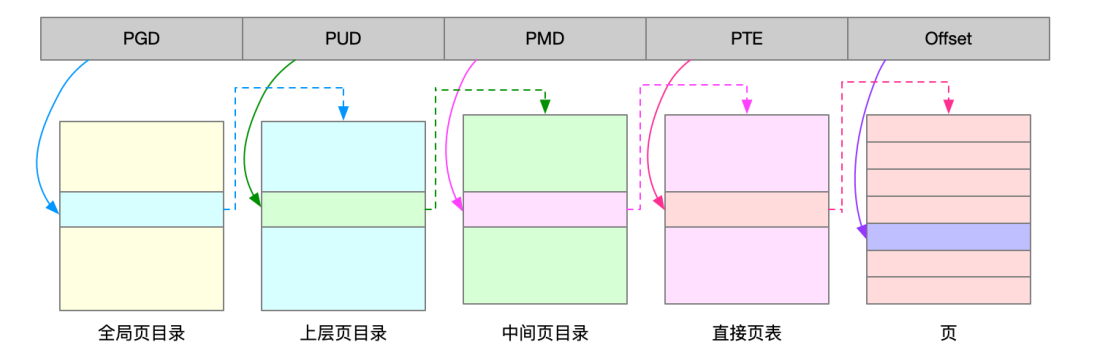
虚拟地址被分了5部分,前四个表项用于选择页,最后一部分用于页内偏移
大页
就是比普通页更大的内存块,常见的大小有 2MB 和 1GB。大页通常用在使用大量内存的进程上,比如 Oracle、DPDK 等
大页内存使用相关指令
cat /sys/devices/system/node/node*/meminfo | fgrep Huge
#查看各个numa节点的大页内存情况。
grep Huge /proc/meminfo
#查看大页内存使用情况
numactl --hradware
#查看系统numa架构,cpu分配情况
echo 64 > /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages
#为numa0节点分配64个2m的大页
mkdir -p /mnt/huge
mount -t hugetlbfs nodev /mnt/huge
#挂载大页,重启后失效
#永久挂在大页内存
vim /etc/fstab
nodev /mnt/huge hugetlbfs defaults 0 0 #挂载2M大页
nodev /mnt/huge_1GB hugetlbfs pagesize=1GB 0 0 #挂载1G的大页
#查看大页内存挂载情况
cat /proc/mounts
#查找正在使用大页的进程
find /proc/*/smaps | xargs grep -ril "anon_hugepage"
#取消挂载
umount /dev/hugepages
umount /mnt/huge
参考 linux大页内存
二,虚拟内存空间分布
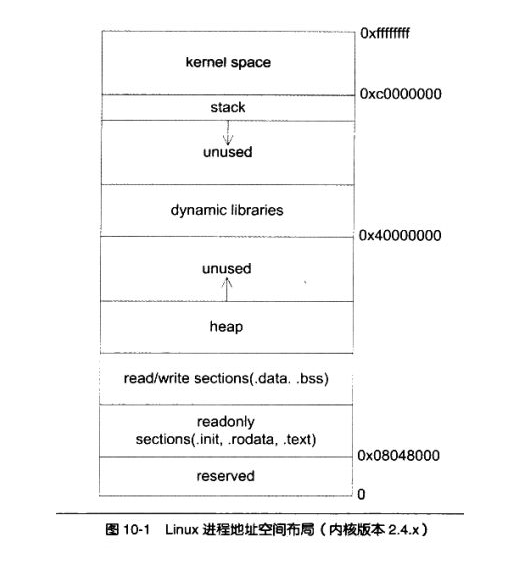
1,32 位系统 内存地址空间分布
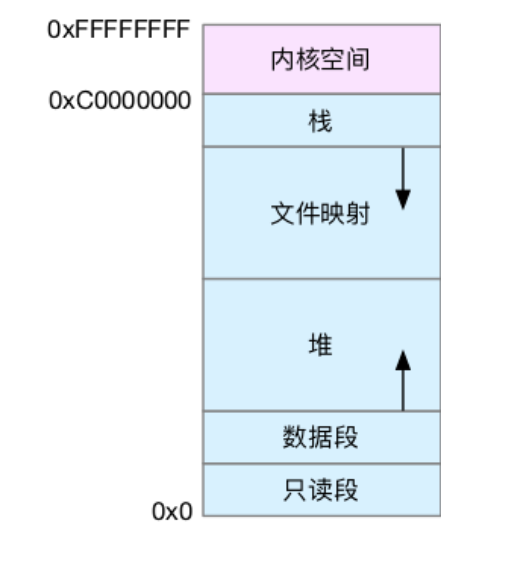
用户空间内存,从低到高分别是五种不同的内存段
- 只读段:包括代码和常量等。
- 数据段:包括全局变量等。
- 堆:包括动态分配的内存,从低地址开始向上增长。
- 文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
- 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB
在这五个内存段中,堆和文件映射段的内存是动态分配的。使用 C 标准库的malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存
其他地方有以下的布局介绍
2,代码段
代码段中存放可执行的指令,在内存中,为了保证不会因为堆栈溢出被覆盖,将其放在了堆栈段下面。通常来讲代码段是共享的,这样多次反复执行的指令只需要在内存中驻留一个副本即可,比如 C 编译器,文本编辑器等。代码段一般是只读的,程序执行时不能随意更改指令,也是为了进行隔离保护。
3、初始化数据段
初始化数据段有时就称之为数据段。数据段是一个程序虚拟地址空间的一部分,包括一全局变量和静态变量,这些变量在编程时就已经被初始化。数据段是可以修改的,不然程序运行时变量就无法改变了,这一点和代码段不同。
数据段可以细分为初始化只读区和初始化读写区。这一点和编程中的一些特殊变量吻合。比如全局变量 int global n = 1就被放在了初始化读写区,因为 global 是可以修改的。而 const int m = 2 就会被放在只读区,很明显,m 是不能修改的。
4、未初始化数据段
未初始化数据段有时称之为 BSS 段,BSS 是英文 Block Started by Symbol 的简称,BSS 段属于静态内存分配。存放在这里的数据都由内核初始化为 0。未初始化数据段从数据段的末尾开始,存放有全部的全局变量和静态变量并被,默认初始化为 0,或者代码中没有显式初始化。比如 static int i; 或者全局 int j; 都会被放到BSS段。
5、栈
栈 (stack) 是现代计算机程序里最为重要的概念之一,几乎每一个程序都使用了栈,没有栈就没有函数,没有局部变量,也就没有我们如今能够看见的所有的计算机语言。在
传统的栈的定义:
在经典的计算机科学中,栈被定义为一个特殊的容器,用户可以将数据压入栈中(入栈,push,也可以将已经压入栈中的数据弹出(出栈, pop),但栈这个容器必须遵守一条规则:先入栈的数据后出栈(First In Last Out, FIFO),多多少少像叠成一叠的书:先叠上去的书在最下面:因此要最后才能取出。
在计算机系统中,栈则是一个具有以上属性的动态内存区域。程序可以将数据压入栈中,也可以将数据从栈顶弹出。压栈操作使得栈增大,而弹出操作使栈减小
在i386下,栈顶由称为 esp 的寄存器进行定位。压栈的操作使栈顶的地址减小,弹出的操作使栈顶地址增大。
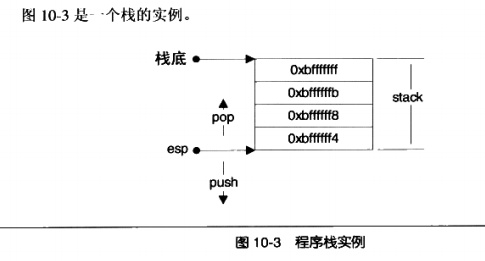
这里栈底的地址是 0xbffff,而 esp 寄存器标明了栈顶,地址为 0xbifff4。
在栈上压入数据会导致 esp 减小,弹出数据使得 esp 增大。
栈在程序运行中具有举足轻重的地位。最重要的,栈保存了一个函数调用所需要的维护信息,这常常被称为堆栈帧(Stack Frame)或活动记录(Activate Record),堆栈帧一般包括如下几方面内容:
1、函数的返回地址和参数。
2、临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量。
3、保存的上下文:包括在函数调用前后需要保持不变的寄存器。
6、堆
相对于栈,堆这片内存面临着一个稍微复杂的行为模式:在任意时刻,程序可能发出请求,要么申请一段内存,要么释放一段已经申请过的内存,而且申请的大小从几个字节到数 GB 都是有可能的,我们不能假设程序会一次申请多少堆空间,因此,堆的管理显得较为复杂。
为什么需要堆?
光有栈,对于面向过程的程序设计还远远不够,因为栈上的数据在函数返回的时候就会被释放掉,所以无法将数据传递至函数外部。而全局变量没有办法动态地产生,只能在编译的时候定义,有很多情况下缺乏表现力,在这种情况下,堆(Heap)是一种唯一的选择。
堆是一款巨大的内存空间,常常占据整个虚拟空间的绝大部分,在这片空间里,程序可以请求一块连续的内存,并自由地使用,这块内存在程序主动放弃之前都活一直保持有效,下面是一个申请堆空间最简单的例子:
int main()
{
char* p = (char*) malloc(233);
free(p);
return 0;
}
在第 3 行用 malloc 申请了 233 个字节的空间之后,程序可以自由地使用这 233个字节,直到程序用free函数释放它。
那么 malloc 到底是怎么实现的呢?
有一种做法是,把进程的内存管理交给操作系统内核去做,既然内核管理着进程的地址空间,那么如果它提供一个系统调用,可以让程序使用这个系统调用申请内存,不就可以了吗?
当然这是一种理论上可行的做法,但实际上这样做的性能比较差,原因在于每次程序申请或者释放堆空间都需要进行系统调用。
我们知道系统调用的性能开销是很大的,当程序对堆的操作比较频繁时,这样做的结果是会严重影响程序的性能的。
比较好的做法就是:程序向操作系统申请一块适当大小的堆空间,然后由程序自己管理这块空间,而具体来讲,管理着堆空间分配的往往是程序的运行库。
运行库相当于是向操作系统 “批发” 了一块较大的堆空间,然后 “零售” 给程序用。
当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。
当然运行库在向程序零售堆空间时,必须管理它批发来的堆空间,不能把同一块地址出售两次,导致地址的冲突。
7、Linux 进程堆管理
进程的地址空间中,除了可执行文件,共享库和栈之外,剩余的未分配的空间都可以用来作为堆空间。
Linux 系统下,提供两种堆空间分配方式,两个系统调用:brk() 系统调用 和 mmap() 系统调用
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准 C 库中,提供了malloc/free函数分配释放内存,这两个函数底层是由 brk,mmap,munmap 这些系统调用实现的。
brk() 系统调用
C 语言形式声明:int brk() {void* end_data_segment;}
brk() 的作用实际上就是设置进程数据段的结束地址,即它可以扩大或者缩小数据段(Linux 下数据段和 BBS 合并在一起统称数据段)。
如果我们将数据段的结束地址向高地址移动,那么扩大的那部分空间就可以被我们使用,把这块空间拿过来使用作为堆空间是最常见的做法。
mmap() 系统调用
和 Windows 系统下的 VirtualAlloc 很相似,它的作用就是向操作系统申请一段虚拟地址空间,(堆和栈中间,称为文件映射区域的地方)这块虚拟地址空间可以映射到某个文件。
glibc 的 malloc 函数是这样处理用户的空间请求的:对于小于 128KB 的请求来说,它会在现有的堆空间里面,按照堆分配算法为它分配一块空间并返回;对于大于128KB 的请求来说,它会使用 mmap() 函数为它分配一块匿名空间,然后在这个匿名空间中为用户分配空间。
声明如下:
void* mmap{
void* start;
size_t length;
int prot;
int flags;
int fd;
off_t offset;
}
mmap 前两个参数分别用于指定需要申请的空间的起始地址和长度,如果起始地址设置 0,那么 Linux 系统会自动挑选合适的起始地址。
prot/flags 参数:用于设置申请的空间的权限(可读,可写,可执行)以及映射类型(文件映射,匿名空间等)。
最后两个参数用于文件映射时指定的文件描述符和文件偏移的。
了解了 Linux 系统对于堆的管理之后,可以再来详细这么一个问题,那就是 malloc 到底一次能够申请的最大空间是多少?
为了回答这个问题,就不得不再回头仔细研究一下之前的图一。我们可以看到在有共享库的情况下,留给堆可以用的空间还有两处。第一处就是从 BSS 段结束到 0x40 000 000 即大约 1GB 不到的空间;
第二处是从共享库到栈的这块空间,大约是 2GB 不到。这两块空间大小都取决于栈、共享库的大小和数量。
于是可以估算到 malloc 最大的申请空间大约是 2GB 不到。(Linux 内核 2.4 版本)。
还有其它诸多因素会影响 malloc 的最大空间大小,比如系统的资源限制(ulimit),物理内存和交换空间的总和等。mmap 申请匿名空间时,系统会为它在内存或交换空间中预留地址,但是申请的空间大小不能超过空闲内存+空闲交换空间的总和。
内存分配与回收
分配
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即brk() 和 mmap()。、
对小块内存(小于 128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
而大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去。
brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是 malloc 只对大块内存使用 mmap 的原因。
当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
回收
系统也不会任由某个进程用完所有内 存,在发现内存紧张时,系统就会通过一系列机制来回收内存,比如下面这三种方式
1,回收缓存。比如使用LRU算法,回收最近使用最少的内存页
2,回收不常访问的内存,把不常用的内存通过交换分区写进磁盘
3,杀死进程,内存紧张时系统通过OOM,直接杀死占用大量的内存的进程
如何查看内存使用情况
1,free

free 输出的是一个表格,其中的数值都默认以字节为单位。表格总共有两行六列,这两行分别是物理内存 Mem 和交换分区 Swap 的使用情况,而六列中,每列数据的含义分别为:
第一列,total 是总内存大小;
第二列,used 是已使用内存的大小,包含了共享内存;
第三列,free 是未使用内存的大小;
第四列,shared 是共享内存的大小;
第五列,buff/cache 是缓存和缓冲区的大小;
最后一列,available 是新进程可用内存的大小
最后一列的可用内存 available 。available 不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。不过,并不是所有缓存都可以回收,因为有些缓存可能正在使用中
2,top
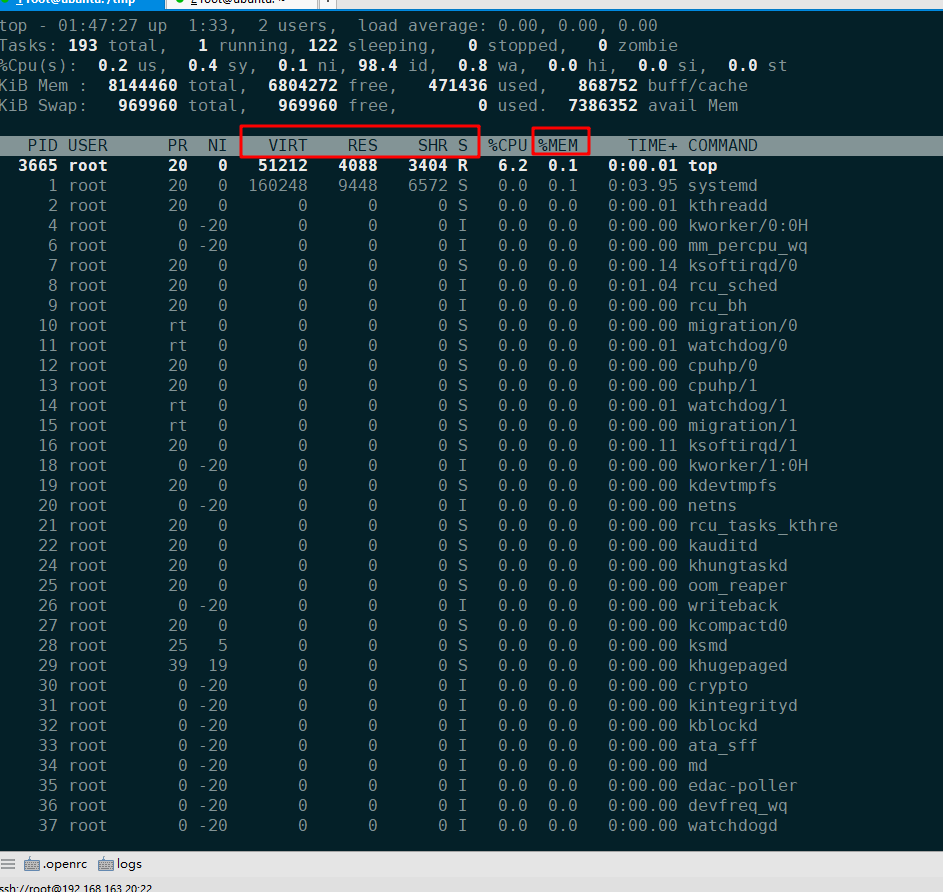
top 输出界面的顶端,也显示了系统整体的内存使用情况,这些数据跟 free 类似,我就不再重复解释。我们接着看下面的内容,跟内存相关的几列数据,比如 VIRT、RES、SHR 以及 %MEM 等。这些数据,包含了进程最重要的几个内存使用情况:
VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
%MEM 是进程使用物理内存占系统总内存的百分比
另外还需要注意:
第一,虚拟内存通常并不会全部分配物理内存。从上面的输出,你可以发现每个进程的虚拟内存都比常驻内存大得多。
第二,共享内存SHR并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在SHR里。当然,SHR也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的SHR 直接相加得出结果。
本文来源
1,https://zhuanlan.zhihu.com/p/77122692
2,极客时间-Linux性能优化
Linux内存简单汇总的更多相关文章
- [svc]Linux中Swap与Memory内存简单介绍
swap区域是干嘛的 cpu 内存(不常用到的进程swap区) 磁盘 当内存没有可用的,就必须要把内存中不经常运行的程序给踢出去.但是踢到哪里去,这时候swap就出现了. 背景介绍 对于Linux来说 ...
- Linux中Swap与Memory内存简单介绍
1.背景介绍 这篇文章介绍一下Linux中swap与memory.对于memory没什么可说的就是机器的物理内存,读写速度低于cpu一个量级,但是高于磁盘不止一个量级.所以,程序和数据如果在内存的 ...
- Linux中Swap与Memory内存简单介绍 (转)
https://blog.csdn.net/zwan0518/article/details/12059213 一.背景介绍 对于Linux来说,其在服务器市场的使用已经占据了绝对的霸主地位,不可动摇 ...
- linux内存管理
一.Linux 进程在内存中的数据结构 一个可执行程序在存储(没有调入内存)时分为代码段,数据段,未初始化数据段三部分: 1) 代码段:存放CPU执行的机器指令.通常代码区是共享的,即其它执行程 ...
- Linux内存管理原理
本文以32位机器为准,串讲一些内存管理的知识点. 1. 虚拟地址.物理地址.逻辑地址.线性地址 虚拟地址又叫线性地址.linux没有采用分段机制,所以逻辑地址和虚拟地址(线性地址)(在用户态,内核态逻 ...
- Linux面试题汇总答案
转自:小女生的Linux技术~~~Linux面试题汇总答案~~ 一.填空题:1. 在Linux系统中,以 文件 方式访问设备 .2. Linux内核引导时,从文件 /etc/fstab 中读取要加载的 ...
- Linux内存管理原理【转】
转自:http://www.cnblogs.com/zhaoyl/p/3695517.html 本文以32位机器为准,串讲一些内存管理的知识点. 1. 虚拟地址.物理地址.逻辑地址.线性地址 虚拟地址 ...
- 73条日常Linux shell命令汇总,总有一条你需要!
转载: 73条日常Linux shell命令汇总,总有一条你需要! 1.检查远程端口是否对bash开放: echo >/dev/tcp/8.8.8.8/53 && echo &q ...
- Windows内存管理和linux内存管理
windows内存管理 windows 内存管理方式主要分为:页式管理,段式管理,段页式管理. 页式管理的基本原理是将各进程的虚拟空间划分为若干个长度相等的页:页式管理把内存空间按照页的大小划分成片或 ...
随机推荐
- 7.控制计划任务crontab命令
at 命令是针对仅运行一次的任务,循环运行的例行性计划任务,linux系统则是由 cron (crond) 这个系统服务来控制的Linux 系统上面原本就有非常多的计划 性工作,因此这个系统服务是默认 ...
- MongoDB本地安装与启用(windows 7/10)
MongoDB的安装与MongoDB服务配置 Mongo DB 是目前在IT行业非常流行的一种非关系型数据库(NoSql),其灵活的数据存储方式备受当前IT从业人员的青睐.Mongo DB很好的实现了 ...
- P2664 树上颜色统计 点分治 虚树 树上差分 树上莫队
树上差分O(n)的做法 考虑每种颜色对每个点的贡献,如果对于每种颜色我们把当前颜色的点删除,那么原来的树就会分成几个子树,对于一个点,当前颜色在和他同子树的点的点对路径上是不会出现的.考虑到有多种颜色 ...
- Summer training #7
B:读懂题意模拟 #include <bits/stdc++.h> #include <cstring> #include <iostream> #include ...
- mysqltuner对数据库的优化
主要用于对mysql配置及my.cnf配置检查,提供详细信息,为进一步优化mysql做参考. 下载地址: (1)http://mysqltuner.com/ (2)脚本获取# wget -c http ...
- hadoop中的JournalNode
1.在HADOOP扮演的角色 JournalNode是在MR2也就是Yarn中新加的,journalNode的作用是存放EditLog的, 在MR1中editlog是和fsimage存放在一起的然后S ...
- jQuery和vue 设置ajax全局请求
一个很常见的问题,如果用户登录网站session过期,需要用户返回登录页面重新登录. 如果是http请求可以在后台设置拦截器,统一拦截并跳转.但是ajax方法并不能通过后台直接跳转. 所以我们可以写一 ...
- JAVA之StringUtils工具类
StringUtils 方法的操作对象是 java.lang.String 类型的对象,是对 JDK 提供的 String 类型操作方法的补充,并且是 null 安全的(即如果输入参数 String ...
- mysql:navcat导入导出
导入: use database: source d:/database/yourdb.sql; 导出 1.右键,转储sql文件,直接保存文件,不能设置执行选项. 2.右键,数据传输:完成各个选项设置 ...
- PHP基础教程-APACHE
兄弟连:如何配置APACHE.首先,安装并配置PHP3 1.解开压缩包到你喜欢的目录如:C:PHP3 2.把C:php3php3.ini-inst文件改名成PHP3.INI并拷贝到C:windows ...