python全栈开发第6天
作业一:
1) 开启Linux系统前添加一块大小为15G的SCSI硬盘

2) 开启系统,右击桌面,打开终端
3) 为新加的硬盘分区,一个主分区大小为5G,剩余空间给扩展分区,在扩展分区上划分1个逻辑分区,大小为5G
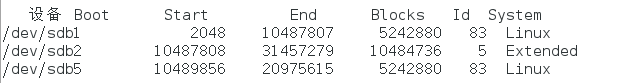
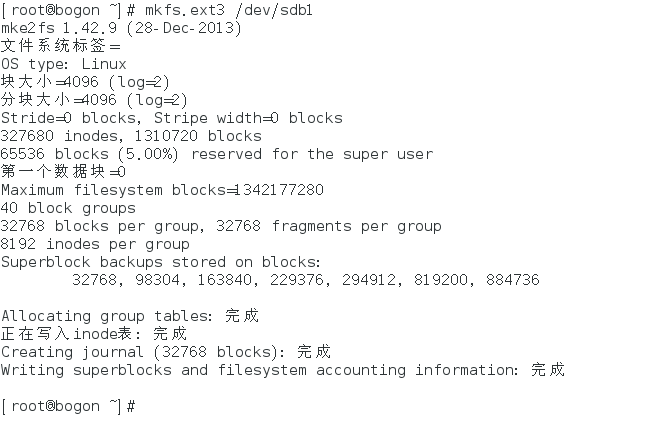
4) 格式化主分区为ext3系统
5) 将逻辑分区设置为交换分区

6) 启用上一步的交换分区

7) 查看交换分区的状态

作业二:free命令查看内存

整理buffer与cache的作用
Mem:表示物理内存统计
-/+ buffers/cached:表示物理内存的缓存统计
Swap:表示硬盘上交换分区的使用情况(这里我们不去关心)
系统的总物理内存:255268Kb(256M),但系统当前真正可用的内存并不是第一行free 标记的 16936Kb,它仅代表未被分配的内存。
我们使用total1、used1、free1、used2、free2 等名称来代表上面统计数据的各值,1、2 分别代表第一行和第二行的数据。
total1: 表示物理内存总量。
used1: 表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。
free1: 未被分配的内存。
shared1: 共享内存,一般系统不会用到,这里也不讨论。
buffers1: 系统分配但未被使用的buffers 数量。
cached1: 系统分配但未被使用的cache 数量。buffer 与cache 的区别见后面。
used2: 实际使用的buffers 与cache 总量,也是实际使用的内存总量。
free2: 未被使用的buffers 与cache 和未被分配的内存之和,这就是系统当前实际可用内存。
可以整理出如下等式:
total1 = used1 + free1
total1 = used2 + free2
used1 = buffers1 + cached1 + used2
free2 = buffers1 + cached1 + free1
CentOS 6及以前
$ free
total used free shared buffers cached
Mem: 4040360 4012200 28160 0 176628 3571348
-/+ buffers/cache: 264224 3776136
Swap: 4200956 12184 4188772
$
内存的使用分作4部分:
- A. 程序使用的;
- B. 未被分配的;
- C. Buffers (buffer cache)
- D. Cached (page cache)
- 第一行(Mem):Buffers和Cached被算作used。也就是说,它的free是指 B (未被分配的);它的used是指 A + C + D;
- 第二行(-/+ buffers/cache):Buffers和Cached被算作free。也就是说,它的used是指 A (程序使用的);它的free是指 B + C + D;行名称“-/+ buffers/cache”的含义就是“把Buffers和Cached从used减下来,加到free里”。
- A=264224
- B=28160
- C=176628
- D=3571348
- total=A + B + C + D
- 第一行used = A + C + D
- 第二行free = B + C + D
CentOS 7
# free
total used free shared buff/cache available
Mem: 507368 284868 48140 4348 174360 181424
Swap: 6291448 3452 6287996
- MemAvailable: An estimate of how much memory is available for starting new applications, without swapping.也就是一个新启动的应用最大能使用的内存。
前面说过,当程序需要时,可以回收C (Buffers)和D (Cached),那么MemAvailabe不就是B+C+D吗?当程序需要时可以回收C和D,这句话以前是正确,但是现在就不精确了:因为, 现在,C和D中不是所有的内存都可以被回收。所以,大致可以这么理解,MemAvailable = B (未被分配的) + C (Buffers) + D (Cached) - 不可回收的部分。哪些不可回收呢?共享内存段,tmpfs,ramfs等。详细的介绍如下:
ago,
memory
a large
into swap,
"low"watermarks
internals
we only
计算真实的内存使用率
# free
total used free shared buff/cache available
Mem: 507368 284868 48140 4348 174360 181424
Swap: 6291448 3452 6287996
根据我的内存使用数据来说应该是这样计算内存的使用率的:
内存的使用率=(used+buff/cache)/total=(284868+174360)/507368=90.5%
作业三:dd命令测试硬盘速度

作业四:查找一个名为firewall的进程,并且将其强制杀死
用命令:ps aux | grep firewall

用命令:kell -9 11006 强制杀死进程

作业五:rpm命令
1) 挂载光盘文件到/media目录

2) 进去/media目录下的Packages目录

3) 查看系统已安装的所有rpm包
使用命令:rpm -qa

4) 查看系统是否安装dhcp软件包
使用命令:rpm -qa | grep dhcp

5) 安装dhcp软件包

6) 查看dhcp软件包的信息

7) 查看dhcp软件包中所包含的所有文件
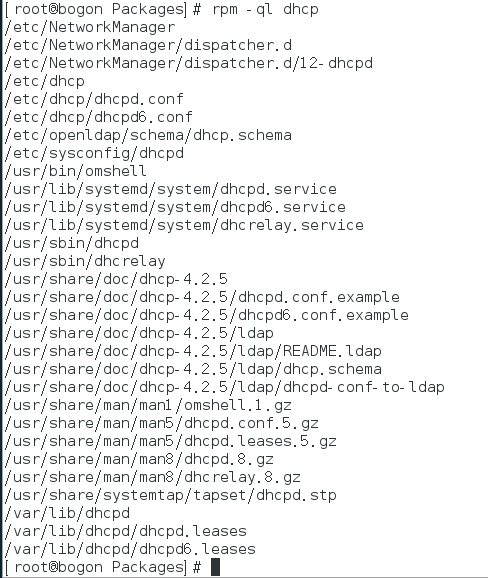
8) 查看/bin/ls文件是由哪个软件包产生

9) 卸载dhcp软件包

作业六:yum命令
1) 自定义yum仓库:createrepo
2) 自定义repo文件
- 在根目录下建立createrepo目录,命令为:
mkdir /createrepo
2.将在/media/Packages/目录下找到图片中红颜色名称的安装包用cp命令拷贝到库文件夹/createrepo中;

3.进入/etc/yum.repos.d目录,将里面所有的文件移动到/repos.bak目录中,这里需要说明一下,因为我们在公司里面需要保障软件版本的可靠性、稳定性及兼容性的问题,所以,这里我建议要将系统自己带的yum源文件移动到其他的位置,采用我们自己定制的源,这样我们才能很好的把软件的版块控制好,才能保障客户使用软件的稳定性;
4.在当前目录下建立并编写文件Local.repo,用此命令:vim Local.repo。
编辑文件内容为:

5.正式创建我们的安装库:
createrepo /createrepo

3) 使用yum命令安装httpd软件包
yum -y install httpd

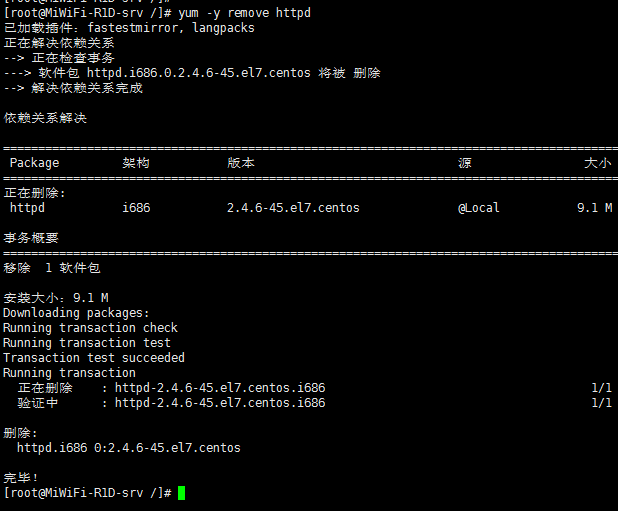
4) 卸载httpd软件包:yum –y remove 软件名
5) 使用yum安装组件'KDE 桌面':yum –y groupinstall 组件名
使用的命令为:yum -y groupinstall KDE 桌面,
由于我的系统版本比较新,这里我用的命令为:
yum -y groups install KDE 桌面


由于所安装的文件过多,这里不一一截图了。
6) 掌握使用yum删除组件‘KDE 桌面’:yum –y groupremove 组件名
这里我的命令为:yum -y groups remove KDE 桌面

7) 掌握清除yum缓存:yum clean all
yum clean, yum clean all (= yum clean packages; yum clean oldheaders) 清除缓存目录下的软件包及旧的headers
8) 使用yum查找软件包:yum search 软件包名

作业七:源码安装python
1.解压文件
本人将Python-3.6.0.tgz的源代码文件全部解压到/usr/Python-3.6.0目录中。
2.我们可以在Python-3.6.0目录中找到configure文件进行vim编辑,对prefix字段后面的等号对应的路径(定制用户的安装路径)进行编辑,这里我们不做改动,保持默认,如图:

3.使用./configure 命令检查一下软件的依赖关系,然后用make命令编译Python-3.6.0的源码,然后用make install安装,这里我们可以合并成为一步操作,命令为:
运行./configure后提示如图:
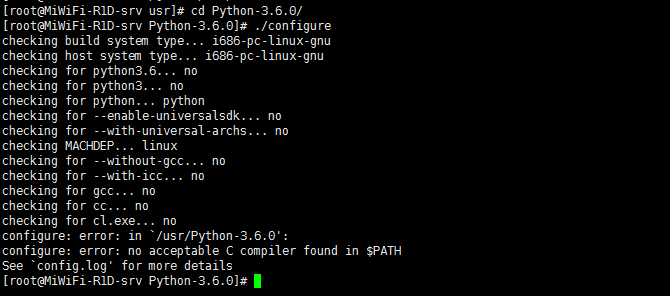
这里提示我们需要安装开发工具,所以,我们运行命令进行安装:
yum -y groups install 开发工具
安装完成后的结果

再次执行./configure的结果如图:

make && make install
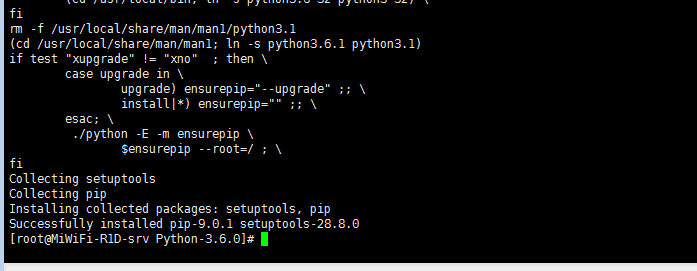
安装完成。
但是我们要试验一下是否正确的安装,让我来实验一条命令:
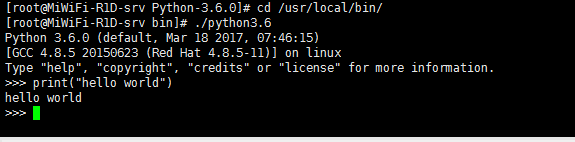
但是我们如果想要在任何目录下都能运行此Python3.6的话,我们需要修改一下环境变量:
1、用vim /etc/profile 命令后,在文件的末尾加上两行内容为:
PATH=/usr/local/bin/:$PATH
export PATH
保存退出,然后我们再根目录下运行一下python3.6,如图,显然成功了:

python全栈开发第6天的更多相关文章
- Python全栈开发【面向对象进阶】
Python全栈开发[面向对象进阶] 本节内容: isinstance(obj,cls)和issubclass(sub,super) 反射 __setattr__,__delattr__,__geta ...
- Python全栈开发【面向对象】
Python全栈开发[面向对象] 本节内容: 三大编程范式 面向对象设计与面向对象编程 类和对象 静态属性.类方法.静态方法 类组合 继承 多态 封装 三大编程范式 三大编程范式: 1.面向过程编程 ...
- Python全栈开发【模块】
Python全栈开发[模块] 本节内容: 模块介绍 time random os sys json & picle shelve XML hashlib ConfigParser loggin ...
- Python全栈开发【基础四】
Python全栈开发[基础四] 本节内容: 匿名函数(lambda) 函数式编程(map,filter,reduce) 文件处理 迭代器 三元表达式 列表解析与生成器表达式 生成器 匿名函数 lamb ...
- Python全栈开发【基础三】
Python全栈开发[基础三] 本节内容: 函数(全局与局部变量) 递归 内置函数 函数 一.定义和使用 函数最重要的是减少代码的重用性和增强代码可读性 def 函数名(参数): ... 函数体 . ...
- Python全栈开发【基础二】
Python全栈开发[基础二] 本节内容: Python 运算符(算术运算.比较运算.赋值运算.逻辑运算.成员运算) 基本数据类型(数字.布尔值.字符串.列表.元组.字典) 其他(编码,range,f ...
- Python全栈开发【基础一】
Python全栈开发[第一篇] 本节内容: Python 的种类 Python 的环境 Python 入门(解释器.编码.变量.input输入.if流程控制与缩进.while循环) if流程控制与wh ...
- python 全栈开发之路 day1
python 全栈开发之路 day1 本节内容 计算机发展介绍 计算机硬件组成 计算机基本原理 计算机 计算机(computer)俗称电脑,是一种用于高速计算的电子计算机器,可以进行数值计算,又可 ...
- Python全栈开发
Python全栈开发 一文让你彻底明白Python装饰器原理,从此面试工作再也不怕了. 一.装饰器 装饰器可以使函数执行前和执行后分别执行其他的附加功能,这种在代码运行期间动态增加功能的方式,称之为“ ...
- 老男孩最新Python全栈开发视频教程(92天全)重点内容梳理笔记 看完就是全栈开发工程师
为什么要写这个系列博客呢? 说来讽刺,91年生人的我,同龄人大多有一份事业,或者有一个家庭了.而我,念了次985大学,年少轻狂,在大学期间迷信创业,觉得大学里的许多课程如同吃翔一样学了几乎一辈子都用不 ...
随机推荐
- Linux下Mysql 不能访问新数据文件夹问题
新挂载的盘,打算将数据文件夹配置到 /data/mysql,却无法启动mysqld. 除了将目录授权给mysql用户和组以外 chown -R mysql:mysql /data/mysql 太需要将 ...
- celery:强大的定时任务模块
什么是celery 还是一个老生常谈的话题,假设用户注册,首先注册信息入库,然后要调用验证码服务接口,然后根据手机号发送验证码,最后再返回响应给浏览器.但显然调用接口.发送验证码之后成功再给浏览器响应 ...
- 8.6.zookeeper应用案例_分布式共享锁的简单实现
1.分布式共享锁的简单实现 在分布式系统中如何对进程进行调度,假设在第一台机器上挂载了一个资源,然后这三个物理分布的进程都要竞争这个资源,但我们又不希望他们同时 进行访问,这时候我们就需要一个协调器, ...
- java 权限控制
网上或参考书中,对于java权限控制大多给出一张看似很整齐很好记实则不好理解的表格,我整理了一个2.0升级版,自认为会好理解很多,希望可以有所帮助. 同一包内 不同包内 修饰符 当前类 非当前类(含子 ...
- cubase 音频的淡入淡出
- 关于GRPC的讲解
gRPC服务发现&负载均衡 https://segmentfault.com/a/1190000008672912?utm_source=tag-newest GRPC编程指南 gRPC 介绍 ...
- Linux之vi文本编辑器
vi的基本概念 基本上vi可以分为三种状态,分别是命令模式(command mode).输入模式(Insert mode)和末行模式(last line mode),各模式的功能区分如下: 1) 命令 ...
- Mac下 CMD常用命令
1.常用命令 pwd 当前工作目录 cd(不加参数) 进root cd(folder) 进入文件夹 cd .. 上级目录 cd ~ 返回root cd - 返 ...
- Autoprefixer:一个以最好的方式处理浏览器前缀的后处理程序
Autoprefixer解析CSS文件并且添加浏览器前缀到CSS规则里,使用Can I Use的数据来决定哪些前缀是需要的. 所有你需要做的就是把它添加到你的资源构建工具(例如 Grunt)并且可 ...
- spark 三种数据集的关系(二)
一个Dataset是一个分布式的数据集,而且它是一个新的接口,这个新的接口是在Spark1.6版本里面才被添加进来的,所以要注意DataFrame是先出来的,然后在1.6版本才出现的Dataset,提 ...