UPX源码分析——加壳篇
0x00 前言
UPX作为一个跨平台的著名开源压缩壳,随着Android的兴起,许多开发者和公司将其和其变种应用在.so库的加密防护中。虽然针对UPX及其变种的使用和脱壳都有教程可查,但是至少在中文网络里并没有针对其源码的分析。作为一个好奇宝宝,我花了点时间读了一下UPX的源码并梳理了其对ELF文件的处理流程,希望起到抛砖引玉的作用,为感兴趣的研究者和使用者做出一点微不足道的贡献。
0x01 编译一个debug版本的UPX
UPX for Linux的源码位于其git仓库地址https://github.com/upx/upx.git中,使用git工具或者直接在浏览器中打开页面就可以获取其源码文件。为了方便学习,我编译了一个debug版本的UPX4debug
将UPX源码clone到本地Linux机器上后,我们需要修改/src/Makefile中的BUILD_TYPE_DEBUG := 0 为BUILD_TYPE_DEBUG = 1 ,编译出一个带有符号表的debug版本UPX方便后续的调试。此外,UPX依赖UCL算法库,ZLIB算法库和LZMA算法库。在修改完Makefile返回其根目录下输入make all进行编译时,编译器会报出如下错误提示: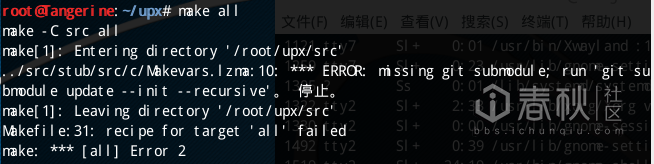
按照提示输入命令 git submodule update --init --recursive后成功下载安装lzma,再次运行make all报错提示依赖项UCL未找到:
UCL库最后一次版本更新为1.03,运行命令
wget http://www.oberhumer.com/opensource/ucl/download/ucl-1.03.tar.gz 下载UCL源码,编译安装成功后再次运行make all,报错提示找不到zlib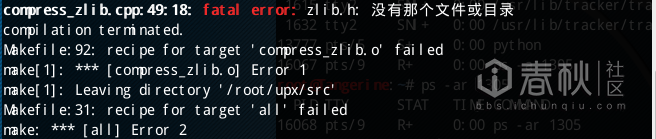
wgethttp://pkgs.fedoraproject.org/re ... /zlib-1.2.11.tar.xz获取最新版本的zlib库并编译安装成功后再次运行make all编译,编译器未报错,在/src/下发现编译成功的结果upx.out
这个upx.out保留了符号,可以被IDA识别,方便后续进行调试。
0x02 UPX源码结构
UPX根目录包含以下文件及文件夹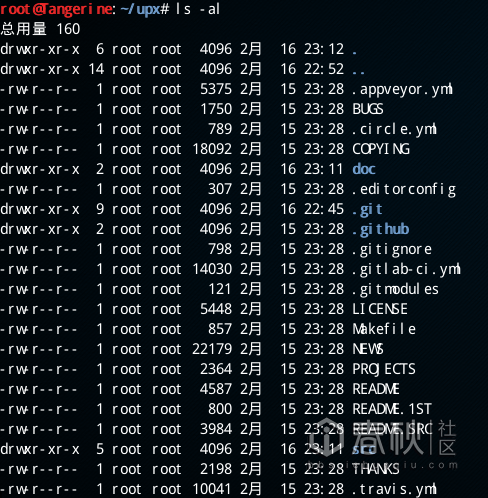
其中,README,LICENSE,THANKS等文件的含义显而易见。在/doc中目前包含了elf-to-mem.txt,filter.txt,loader.txt,Makefile,selinux.txt,upx.pod几项。elf-to-mem.txt说明了解压到内存的原理和条件,filter.txt解释了UPX所采用的压缩算法和filter机制,loader.txt告诉开发者如何自定义loader,selinux.txt介绍了SE Linux中对内存匿名映像的权限控制给UPX造成的影响。这部分文件适用于想更加深入了解UPX的研究者和开发者们,在此我就不多做介绍了。
我们在这个项目中感兴趣的UPX源码都在文件夹/src中,进入该文件夹后我们可以发现其源码由文件夹/src/stub,/src/filter,/lzma-sdk和一系列*.h, *.cpp文件构成。其中/src/stub包含了针对不同平台,架构和格式的文件头定义和loader源码,/src/filter是一系列被filter机制和UPX使用的头文件。其余的代码文件主要可以分为负责UPX程序总体的main.cpp,work.cp和packmast.cpp,负责加脱壳类的定义与实现的p_*.h和p_*.cpp,以及其他起到显示,运算等辅助作用的源码文件。我们的分析将会从main.cpp入手,经过work.cpp,最终跳转到对应架构和平台的packer()类中。
0x03 加壳前的准备工作
在上文中我们提到分析将会从main.cpp入手。main.cpp可以视为整个工程的“入口”,当我们在shell中调用UPX时,main.cpp中的代码将对程序进行初始化工作,包括运行环境检测,参数解析和实现对应的跳转。
我们从位于main.cpp末尾的main函数开始入手。可以看到main函数开头的代码进行了位数检查,参数检查,压缩算法库可用性检查和针对windows平台进行文件名转换。从1516行开始的switch结构针对不同的命令cmd跳转至不同的case其中compress和decompress操作直接break,在1549行注释标注的check options语句块后,1565行出现了一个名为do_files的函数。
|
01
02
03
04
05
06
07
08
09
10
11
|
int __acc_cdecl_main main(int argc, char *argv[]){ ...... /* check options */ ...... /* start work */ set_term(stdout); do_files(i,argc,argv); ...... return exit_code;} |
do_files()的实现位于文件work.cpp中。work.cpp非常简练,只有do_one_file(), unlink_ofile()和do_files()三个函数,而do_files()几乎由for循环和try…catch块构成
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
void do_files(int i, int argc, char *argv[]){ ...... for ( ; i < argc; i++) { infoHeader(); const char *iname = argv; char oname[ACC_FN_PATH_MAX+1]; oname[0] = 0; try { do_one_file(iname,oname); }...... } ......} |
从for循环和iname的赋值我们可以看出UPX具有操作多个文件的功能,每个文件都会调用do_one_file()进行操作。
继续深入do_one_file(),前面的代码对文件名进行处理,并打开了两个自定义的文件流fi和fo,fi读取待操作的文件,fo根据参数创建一个临时文件或创建一个文件,这个参数就是-o. 随后函数获取了PackMaster类的实例pm并调用其成员函数进行操作,在这里我们关心的是pm.pack(&fo)。这个函数的实现位于packmast.cpp中。
packMaster::pack()非常简单,调用了getPacker()获取一个Packer实例,随后调用Packer的成员函数doPack()进行加壳。跳转到getPacker()发现其调用visitAllPakcers()获取Packer
|
1
2
3
4
5
6
7
8
|
Packer *PackMaster::getPacker(InputFile *f){ Packer *pp = visitAllPackers(try_pack, f, opt, f); if (!pp) throwUnknownExecutableFormat(); pp->assertPacker(); return pp;} |
跳转到函数visitAllPackers()中,我们发现获取对应平台和架构的Packer的方法其实是一个遍历操作,以输入文件流fi和不同的Packer类作为参数传递给函数指针类型参数try_pack,通过函数try_pack()进行判断。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
Packer* PackMaster::visitAllPackers(visit_func_t func, InputFile *f, const options_t *o, void *user){ Packer *p = NULL;...... // .exe...... // atari......// linux kernel...... // linux if (!o->o_unix.force_execve){ ...... if ((p = func(new PackLinuxElf64amd(f), user)) != NULL) return p; delete p; p = NULL; if ((p = func(new PackLinuxElf32armLe(f), user)) != NULL) return p; delete p; p = NULL; if ((p = func(new PackLinuxElf32armBe(f), user)) != NULL) return p; delete p; p = NULL; ...... } // psone......// .sys and .com ...... // Mach (MacOS X PowerPC) ...... return NULL;} |
当且仅当其返回true,函数不返回空,此时visitAllPackers()的对应if分支被执行,packer被传递回PackMaster::pack()执行Packer::doPack()开始加壳。
跳转到位于同一个源码文件下的函数try_pack()
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
static Packer* try_pack(Packer *p, void *user){ if (p == NULL) return NULL; InputFile *f = (InputFile *) user; p->assertPacker(); try { p->initPackHeader(); f->seek(0,SEEK_SET); if (p->canPack()) { if (opt->cmd == CMD_COMPRESS) p->updatePackHeader(); f->seek(0,SEEK_SET); return p; } } catch (const IOException&) { } catch (...) { delete p; throw; } delete p; return NULL;} |
try_pack()调用了Packer类的成员函数assertPacker(), initPackHeader(), canPack(), updatePackHeader(),在其中起到关键作用的是canPack().通过查看头文件p_lx_elf.h,p_unix.h和packer.h我们发现PackLinuxElf64amd()位于一条以在packer.h中定义的类Packer为基类的继承链尾端,assertPacker(), initPackHeader()和updatePackHeader()的实现均位于文件packer.cpp中,其功能依次为断言一些UPX信息,初始化和更新一个用于加壳的类PackHeader实例ph.
0x04 Packer的适配和初始化
通过对上一节的分析我们得知Packer能否适配成功最终取决于每一个具体Packer类的成员函数canPack().我们以常用的Linux for AMD 64为例,其实现位于p_lx_elf.cpp的PackLinuxElf64amd::canPack()中,而Linux for x86和Linux for ARM的实现均位于PackLinuxElf32::canPack()中,从visitAllPackers()的代码中我们也可以看到UPX当前并不支持64位ARM平台。
我们接下来将以Linux for AMD 64为例进行代码分析,并在每一个小节的末尾补充Linux for x86和Linux for ARM的不同之处。我们从PackLinuxElf64amd::canPack()开始:
PackLinuxElf64amd::canPack()
{
第一部分代码,该部分代码主要是对ELF文件头Ehdr和程序运行所需的基本单位Segment的信息Phdr进行校验。代码读取了文件中长度为Ehdr+14*Phdr大小的内容,首先通过checkEhdr()将Ehdr中的字段与预设值进行比较,确定Phdr数量大于1且偏移值正确,随后对Ehdr的大小和偏移进行判定,判定Phdr数量是否大于14,最后确定第一个具有PT_LOAD属性的segment是否覆盖了整个文件的头部。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
union { unsigned char buf[sizeof(Elf64_Ehdr) + 14*sizeof(Elf64_Phdr)]; //struct { Elf64_Ehdr ehdr; Elf64_Phdr phdr; } e; } u; COMPILE_TIME_ASSERT(sizeof(u) <= 1024) fi->readx(u.buf, sizeof(u.buf)); fi->seek(0, SEEK_SET); Elf64_Ehdr const *const ehdr = (Elf64_Ehdr *) u.buf; // now check the ELF header if (checkEhdr(ehdr) != 0) return false; // additional requirements for linux/elf386 if (get_te16(&ehdr->e_ehsize) != sizeof(*ehdr)) { throwCantPack("invalid Ehdr e_ehsize; try '--force-execve'"); return false; } if (e_phoff != sizeof(*ehdr)) {// Phdrs not contiguous with Ehdr throwCantPack("non-contiguous Ehdr/Phdr; try '--force-execve'"); return false; } // The first PT_LOAD64 must cover the beginning of the file (0==p_offset). Elf64_Phdr const *phdr = phdri; for (unsigned j=0; j < e_phnum; ++phdr, ++j) { if (j >= 14) return false; if (phdr->T_LOAD64 == get_te32(&phdr->p_type)) { load_va = get_te64(&phdr->p_vaddr); upx_uint64_t file_offset = get_te64(&phdr->p_offset); if (~page_mask & file_offset) { if ((~page_mask & load_va) == file_offset) { throwCantPack("Go-language PT_LOAD: try hemfix.c, or try '--force-execve'"); // Fixing it inside upx fails because packExtent() reads original file. } else { throwCantPack("invalid Phdr p_offset; try '--force-execve'"); } return false; } exetype = 1; break; } } |
第二部分代码,从两段长注释中我们可以看出UPX仅支持对位置无关(PIE)的可执行文件和代码位置无关(PIC)的共享库文件进行加壳处理,然而可执行文件和共享库都(可能)具有ET_DYN属性,理论上没有办法将他们区分开。作者采用了一个巧妙的办法:当文件入口点为
__libc_start_main,__uClibc_main或__uClibc_start_main之一时,说明文件依赖于libc.so.6,该文件为满足PIE的可执行文件。因此该部分通过判定文件是否具有ET_DYN属性,若是则在其重定位表中搜寻以上三个符号,满足则跳转至proceed标号处
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
// We want to compress position-independent executable (gcc -pie) // main programs, but compressing a shared library must be avoided // because the result is no longer usable. In theory, there is no way // to tell them apart: both are just ET_DYN. Also in theory, // neither the presence nor the absence of any particular symbol name // can be used to tell them apart; there are counterexamples. // However, we will use the following heuristic suggested by // Peter S. Mazinger <[email]ps.m@gmx.net[/email]> September 2005: // If a ET_DYN has __libc_start_main as a global undefined symbol, // then the file is a position-independent executable main program // (that depends on libc.so.6) and is eligible to be compressed. // Otherwise (no __libc_start_main as global undefined): skip it. // Also allow __uClibc_main and __uClibc_start_main . if (Elf32_Ehdr::ET_DYN==get_te16(&ehdr->e_type)) { // The DT_STRTAB has no designated length. Read the whole file. alloc_file_image(file_image, file_size); fi->seek(0, SEEK_SET); fi->readx(file_image, file_size); memcpy(&ehdri, ehdr, sizeof(Elf64_Ehdr)); phdri= (Elf64_Phdr *)((size_t)e_phoff + file_image); // do not free() !! shdri= (Elf64_Shdr const *)((size_t)e_shoff + file_image); // do not free() !! //sec_strndx = &shdri[ehdr->e_shstrndx]; //shstrtab = (char const *)(sec_strndx->sh_offset + file_image); sec_dynsym = elf_find_section_type(Elf64_Shdr::SHT_DYNSYM); if (sec_dynsym) sec_dynstr = get_te64(&sec_dynsym->sh_link) + shdri; int j= e_phnum; phdr= phdri; for (; --j>=0; ++phdr) if (Elf64_Phdr:T_DYNAMIC==get_te32(&phdr->p_type)) { dynseg= (Elf64_Dyn const *)(get_te64(&phdr->p_offset) + file_image); break; } // elf_find_dynamic() returns 0 if 0==dynseg. dynstr= (char const *)elf_find_dynamic(Elf64_Dyn:T_STRTAB); dynsym= (Elf64_Sym const *)elf_find_dynamic(Elf64_Dyn:T_SYMTAB); // Modified 2009-10-10 to detect a ProgramLinkageTable relocation // which references the symbol, because DT_GNU_HASH contains only // defined symbols, and there might be no DT_HASH. Elf64_Rela const * rela= (Elf64_Rela const *)elf_find_dynamic(Elf64_Dyn:T_RELA); Elf64_Rela const * jmprela= (Elf64_Rela const *)elf_find_dynamic(Elf64_Dyn:T_JMPREL); for ( int sz = elf_unsigned_dynamic(Elf64_Dyn:T_PLTRELSZ); 0 < sz; (sz -= sizeof(Elf64_Rela)), ++jmprela ) { unsigned const symnum = get_te64(&jmprela->r_info) >> 32; char const *const symnam = get_te32(&dynsym[symnum].st_name) + dynstr; if (0==strcmp(symnam, "__libc_start_main") || 0==strcmp(symnam, "__uClibc_main") || 0==strcmp(symnam, "__uClibc_start_main")) goto proceed; } // 2016-10-09 DT_JMPREL is no more (binutils-2.26.1)? // Check the general case, too. for ( int sz = elf_unsigned_dynamic(Elf64_Dyn:T_RELASZ); 0 < sz; (sz -= sizeof(Elf64_Rela)), ++rela ) { unsigned const symnum = get_te64(&rela->r_info) >> 32; char const *const symnam = get_te32(&dynsym[symnum].st_name) + dynstr; if (0==strcmp(symnam, "__libc_start_main") || 0==strcmp(symnam, "__uClibc_main") || 0==strcmp(symnam, "__uClibc_start_main")) goto proceed; } |
第三部分代码,该部分针对第二部分的“漏网之鱼”,此时将待处理的文件视为共享库文件。共享库文件需要满足PIC——文件中不包含代码重定位信息节DT_TEXTREL。此外,文件最靠前的可执行节地址(通常为.init节代码)必须在重定位信息之后,因为此时链接器ld-linux必须在.init节之前进行重定位,UPX加壳后会将入口点设置在.init节上,必须避免破坏ld-linux所需的信息。若判定通过,变量xct_off将记录下.init段地址(必然不等于0)并作为后续pack函数中对待操作文件是否为共享库的判定条件。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
// Heuristic HACK for shared libraries (compare Darwin (MacOS) Dylib.) // If there is an existing DT_INIT, and if everything that the dynamic // linker ld-linux needs to perform relocations before calling DT_INIT // resides below the first SHT_EXECINSTR Section in one PT_LOAD, then // compress from the first executable Section to the end of that PT_LOAD. // We must not alter anything that ld-linux might touch before it calls // the DT_INIT function. // // Obviously this hack requires that the linker script put pieces // into good positions when building the original shared library, // and also requires ld-linux to behave. if (elf_find_dynamic(Elf64_Dyn:T_INIT)) { if (elf_has_dynamic(Elf64_Dyn:T_TEXTREL)) { throwCantPack("DT_TEXTREL found; re-compile with -fPIC"); goto abandon; } Elf64_Shdr const *shdr = shdri; xct_va = ~0ull; for (j= e_shnum; --j>=0; ++shdr) { if (Elf64_Shdr::SHF_EXECINSTR & get_te32(&shdr->sh_flags)) { xct_va = umin64(xct_va, get_te64(&shdr->sh_addr)); } } // Rely on 0==elf_unsigned_dynamic(tag) if no such tag. upx_uint64_t const va_gash = elf_unsigned_dynamic(Elf64_Dyn:T_GNU_HASH); upx_uint64_t const va_hash = elf_unsigned_dynamic(Elf64_Dyn:T_HASH); if (xct_va < va_gash || (0==va_gash && xct_va < va_hash) || xct_va < elf_unsigned_dynamic(Elf64_Dyn:T_STRTAB) || xct_va < elf_unsigned_dynamic(Elf64_Dyn:T_SYMTAB) || xct_va < elf_unsigned_dynamic(Elf64_Dyn:T_REL) || xct_va < elf_unsigned_dynamic(Elf64_Dyn:T_RELA) || xct_va < elf_unsigned_dynamic(Elf64_Dyn:T_JMPREL) || xct_va < elf_unsigned_dynamic(Elf64_Dyn:T_VERDEF) || xct_va < elf_unsigned_dynamic(Elf64_Dyn:T_VERSYM) || xct_va < elf_unsigned_dynamic(Elf64_Dyn:T_VERNEEDED) ) { throwCantPack("DT_ tag above stub"); goto abandon; } for ((shdr= shdri), (j= e_shnum); --j>=0; ++shdr) { upx_uint64_t const sh_addr = get_te64(&shdr->sh_addr); if ( sh_addr==va_gash || (sh_addr==va_hash && 0==va_gash) ) { shdr= &shdri[get_te32(&shdr->sh_link)]; // the associated SHT_SYMTAB hatch_off = (char *)&ehdri.e_ident[11] - (char *)&ehdri; break; } } ACC_UNUSED(shdr); xct_off = elf_get_offset_from_address(xct_va); goto proceed; // But proper packing depends on checking xct_va. }abandon: return false;proceed: ; } |
第四部分代码,注释中已经说明其调用的是PackUnix::canPack(),函数实现位于p_unix.cpp中。该函数判断待操作文件是否具有可执行权限,大小是否大于4096,并读取最末尾的一部分数据判定是否加壳。
// XXX Theoretically the following test should be first,
// but PackUnix::canPack() wants 0!=exetype ?
if (!super::canPack())
return false;
assert(exetype == 1);
exetype = 0;
// set options
opt->o_unix.blocksize = blocksize = file_size;
return true;
}
至此,UPX对Packer的适配检查就结束了。通过适配的Packer将会被返回到doPack()中,通过调用其函数pack()进行加壳。
Linux for x86和Linux for ARM版本的PackLinuxElf32::canPack()与前例流程几乎一致。不同的是另一个版本的canPack()在第一部分的末尾额外增加了对PT_NOTE段的长度和偏移检测,并对OS ABI类型做了额外的检测。
0x05 对加壳函数的拆解分析
UPX对所有运行在其支持的架构上的Linux ELF文件都使用同一个pack(),该函数的实现位于p_unix.cpp中。pack()将很多具体操作下放到了各个子类分别实现的pack1(), pack2(), pack3(), pack4()函数中,因此其本体源码并不是很长。通过pack()中的注释我们可以发现其加壳流程大致分为初始化文件头,压缩文件本体,添加loader和修补ELF格式四部分。下面我们以pack1()至pack4()四个函数为分界线进行分析。
(1)对pack1()的分析
|
01
02
03
04
05
06
07
08
09
10
|
void PackUnix::pack(OutputFile *fo){...... // set options...... // init compression buffers...... fi->seek(0, SEEK_SET); pack1(fo, ft); // generate Elf header, etc....... |
位于pack()开头的这部分代码完成的主要工作为初始化了一些和加壳相关的变量,设置了区块大小并在I/O流中分配内存用于加壳,随后调用了pack1()。对于AMD 64来说其实现位于p_lx_elf.cpp中的PackLinuxElf64::pack1()中。
|
1
2
3
4
5
6
7
|
void PackLinuxElf64amd::pack1(OutputFile *fo, Filter &ft){ super::pack1(fo, ft); if (0!=xct_off) // shared library return; generateElfHdr(fo, stub_amd64_linux_elf_fold, getbrk(phdri, e_phnum) );} |
这个函数调用了父类的同名函数PackLinuxElf64::pack1()进行处理,随后当文件不为共享库时调用PackLinuxElf64::generateElfHdr()生成一个ELF头,所有的代码都位于文件p_lx_elf.cpp中。
首先分析PackLinuxElf64::pack1(),函数的前半部分读取了ELF头部Ehdr和程序运行时所需的信息Phdr,将标志为PT_NOTE的段保存下来(虽然好像并没有用到),计算了PT_LOAD段的page_size和page_mask。当文件为共享库时,根据前面canPack()处的说明,为了保证信息不被修改,xct_off前面的所有数据被原封不动写到输出文件中,此外写入了一个描述loader的结构体l_info
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
void PackLinuxElf64::pack1(OutputFile *fo, Filter & /*ft*/){ ...... page_size = 1u <<lg2_page; page_mask = ~0ull<<lg2_page; progid = 0; // getRandomId(); not useful, so do not clutter if (0!=xct_off) { // shared library fi->seek(0, SEEK_SET); fi->readx(ibuf, xct_off); sz_elf_hdrs = xct_off; fo->write(ibuf, xct_off); memset(&linfo, 0, sizeof(linfo)); fo->write(&linfo, sizeof(linfo));}...... |
l_info结构体的定义位于/src/stub/src/include/linux.h中
|
1
2
3
4
5
6
7
8
|
struct l_info // 12-byte trailer in header for loader (offset 116){ uint32_t l_checksum; uint32_t l_magic; uint16_t l_lsize; uint8_t l_version; uint8_t l_format;}; |
函数的第二部分是对UPX参数--preserve-build-id的功能实现,使用该参数后将会把.note.gnu.build-id节保存到shdrout中,在pack4()写入输出文件。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
...... // only execute if option present if (opt->o_unix.preserve_build_id) { ...... if (buildid) { unsigned char *data = New(unsigned char, buildid->sh_size); memset(data,0,buildid->sh_size); fi->seek(0,SEEK_SET); fi->seek(buildid->sh_offset,SEEK_SET); fi->readx(data,buildid->sh_size); buildid_data = data; o_elf_shnum = 3; memset(&shdrout,0,sizeof(shdrout)); //setup the build-id memcpy(&shdrout.shdr[1],buildid, sizeof(shdrout.shdr[1])); shdrout.shdr[1].sh_name = 1; //setup the shstrtab memcpy(&shdrout.shdr[2],sec_strndx, sizeof(shdrout.shdr[2])); shdrout.shdr[2].sh_name = 20; shdrout.shdr[2].sh_size = 29; //size of our static shstrtab } ......} |
从该函数中我们可以看到可执行文件此时并没有获得一个文件头,因此PackLinuxElf64::pack1()对可执行文件调用了PackLinuxElf64::generateElfHdr()生成了一个包含有Ehdr和两个Phdr在内的文件头,其中两个segment均为PT_LOAD类型,第一个具有RX属性,第二个则具有RW属性。同样的,在文件头的最后也追加了一个空l_info结构体。该函数 接受了一个名为stub_amd64_linux_elf_fold的数组作为参数,该数组位于/src/stub/amd64-linux.elf-fold.h中,包含了一个预设置了一些字段的Ehdr,两个Phdr和部分数据。
对于x86和ARM来说,其可执行文件所需的PackLinuxElf32::generateElfHdr()和父类的PackLinuxElf32::pack1()与本例大同小异,仅在OS ABI的设置上有一些细节上的差别。显而易见地,子类的pack1()传递给generateElfHdr()的参数也不相同,可以在/src/stub中相对应的*-fold.h中找到。
(2) 对pack2()的分析
在生成了文件头后,pack()向输出文件追加了一个p_info结构体并填入了文件大小和块大小。
......
p_info hbuf;
set_te32(&hbuf.p_progid, progid);
set_te32(&hbuf.p_filesize, file_size);
set_te32(&hbuf.p_blocksize, blocksize);
fo->write(&hbuf, sizeof(hbuf));
该结构体同样位于/src/stub/src/include/linux.h中
|
1
2
3
4
5
6
|
struct p_info // 12-byte packed program header follows stub loader{ uint32_t p_progid; uint32_t p_filesize; uint32_t p_blocksize;}; |
随后调用了pack2()进行文件(实际上是PT_LOAD段)压缩,并在末尾补上一个b_info结构体。
|
1
2
3
4
5
6
7
8
|
// append the compressed body if (pack2(fo, ft)) { // write block end marker (uncompressed size 0) b_info hdr; memset(&hdr, 0, sizeof(hdr)); set_le32(&hdr.sz_cpr, UPX_MAGIC_LE32); fo->write(&hdr, sizeof(hdr)); } ...... |
我们先将目光放在pack2()上,其实现位于p_unix.cpp中的PackLinuxElf64::pack2 ()。将UI实现部分刨去,函数的开头初始化并赋值了三个变量hdr_u_len, total_in和total_out
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
int PackLinuxElf64::pack2(OutputFile *fo, Filter &ft){ Extent x; unsigned k; bool const is_shlib = (0!=xct_off);......// compress extents unsigned hdr_u_len = sizeof(Elf64_Ehdr) + sz_phdrs; unsigned total_in = xct_off - (is_shlib ? hdr_u_len : 0); unsigned total_out = xct_off; uip->ui_pass = 0;ft.addvalue = 0;...... |
计算完变量之后筛选出PT_LOAD段,调用packExtent()进行数据打包和输出到文件。根据注释,PowerPC有时候会给.data段打上可执行标志,而打上该标志的段会被认为是代码段,在packExtent()中会调用compressWithFilters()进行压缩。然而对于过小的.data段compressWithFilters()无法压缩。因此在for循环之前初始化了一个nx标志变量记录PT_LOAD下标。当且仅当带有可执行标志的第一个PT_LOAD段适用于compressWithFilters()。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
......int nx = 0;for (k = 0; k < e_phnum; ++k) if (PT_LOAD64==get_te32(&phdri[k].p_type)) {...... if (0==nx || !is_shlib) packExtent(x, total_in, total_out, ((0==nx && (Elf64_Phdr:F_X & get_te64(&phdri[k].p_flags))) ? &ft : 0 ), fo, hdr_u_len); else total_in += x.size; hdr_u_len = 0; ++nx;}...... |
压缩结束后计算已压缩数据和未压缩数据的和是否等于原文件大小。在此之前补齐文件位数为4的倍数,并把长度记录在变量sz_pack2a中,这个变量将会在pack3()被用到。
|
01
02
03
04
05
06
07
08
09
10
11
12
|
sz_pack2a = fpad4(fo); // MATCH01 ...... // Accounting only; ::pack3 will do the compression and output for (k = 0; k < e_phnum; ++k) { // total_in += find_LOAD_gap(phdri, k, e_phnum); } if ((off_t)total_in != file_size) throwEOFException(); return 0; // omit end-of-compression bhdr for now} |
可以看到pack2()的核心是compressWithFilters(),该函数的实现位于p_unix.cpp的PackUnix::packExtent()。
当传递进来的参数hdr_u_len不为零时说明文件头(Ehdr+Phdrs)未被压缩,读取到hdr_ibuf中等待压缩。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
void PackUnix::packExtent( const Extent &x, unsigned &total_in, unsigned &total_out, Filter *ft, OutputFile *fo, unsigned hdr_u_len){ ...... if (hdr_u_len) { hdr_ibuf.alloc(hdr_u_len); fi->seek(0, SEEK_SET); int l = fi->readx(hdr_ibuf, hdr_u_len); (void)l; }fi->seek(x.offset, SEEK_SET); ...... |
进入for循环,循环读取带压缩的数据进行压缩和输出到文件操作
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
...... for (off_t rest = x.size; 0 != rest; ) { int const filter_strategy = ft ? getStrategy(*ft) : 0; int l = fi->readx(ibuf, UPX_MIN(rest, (off_t)blocksize)); if (l == 0) { break; } rest -= l; // Note: compression for a block can fail if the // file is e.g. blocksize + 1 bytes long // compress ph.c_len = ph.u_len = l; ph.overlap_overhead = 0; unsigned end_u_adler = 0; ...... |
可执行代码适用于compressWithFilters(),否则适用于compress()
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
......if (ft) { // compressWithFilters() updates u_adler _inside_ compress(); // that is, AFTER filtering. We want BEFORE filtering, // so that decompression checks the end-to-end checksum. end_u_adler = upx_adler32(ibuf, ph.u_len, ph.u_adler); ft->buf_len = l; // compressWithFilters() requirements? ph.filter = 0; ph.filter_cto = 0; ft->id = 0; ft->cto = 0; compressWithFilters(ft, OVERHEAD, NULL_cconf, filter_strategy, 0, 0, 0, hdr_ibuf, hdr_u_len);}else { (void) compress(ibuf, ph.u_len, obuf); // ignore return value}...... |
UPX设计的初衷是压缩可执行文件的大小,所以这里对压缩前后的数据进行测试和比较,保留体积较小的部分。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
......if (ph.c_len < ph.u_len) { const upx_bytep tbuf = NULL; if (ft == NULL || ft->id == 0) tbuf = ibuf; ph.overlap_overhead = OVERHEAD; if (!testOverlappingDecompression(obuf, tbuf, ph.overlap_overhead)) { // not in-place compressible ph.c_len = ph.u_len; }}if (ph.c_len >= ph.u_len) { // block is not compressible ph.c_len = ph.u_len; memcpy(obuf, ibuf, ph.c_len); // must update checksum of compressed data ph.c_adler = upx_adler32(ibuf, ph.u_len, ph.saved_c_adler);} ...... |
将结果写回文件。若hdr_u_len不为零,调用upx_compress压缩hdr_ibuf,结果写回,然后将hdr_u_len置零防止重复压缩。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
...... // write block sizes b_info tmp; if (hdr_u_len) { unsigned hdr_c_len = 0; MemBuffer hdr_obuf; hdr_obuf.allocForCompression(hdr_u_len); int r = upx_compress(hdr_ibuf, hdr_u_len, hdr_obuf, &hdr_c_len, 0, ph.method, 10, NULL, NULL); if (r != UPX_E_OK) throwInternalError("header compression failed"); if (hdr_c_len >= hdr_u_len) throwInternalError("header compression size increase"); ph.saved_u_adler = upx_adler32(hdr_ibuf, hdr_u_len, init_u_adler); ph.saved_c_adler = upx_adler32(hdr_obuf, hdr_c_len, init_c_adler); ph.u_adler = upx_adler32(ibuf, ph.u_len, ph.saved_u_adler); ph.c_adler = upx_adler32(obuf, ph.c_len, ph.saved_c_adler); end_u_adler = ph.u_adler; memset(&tmp, 0, sizeof(tmp)); set_te32(&tmp.sz_unc, hdr_u_len); set_te32(&tmp.sz_cpr, hdr_c_len); tmp.b_method = (unsigned char) ph.method; fo->write(&tmp, sizeof(tmp)); b_len += sizeof(b_info); fo->write(hdr_obuf, hdr_c_len); total_out += hdr_c_len; total_in += hdr_u_len; hdr_u_len = 0; // compress hdr one time only } memset(&tmp, 0, sizeof(tmp)); set_te32(&tmp.sz_unc, ph.u_len); set_te32(&tmp.sz_cpr, ph.c_len); if (ph.c_len < ph.u_len) { tmp.b_method = (unsigned char) ph.method; if (ft) { tmp.b_ftid = (unsigned char) ft->id; tmp.b_cto8 = ft->cto; } } fo->write(&tmp, sizeof(tmp)); b_len += sizeof(b_info); if (ft) { ph.u_adler = end_u_adler; } // write compressed data if (ph.c_len < ph.u_len) { fo->write(obuf, ph.c_len); // Checks ph.u_adler after decompression, after unfiltering verifyOverlappingDecompression(ft); } else { fo->write(ibuf, ph.u_len); } total_in += ph.u_len; total_out += ph.c_len; }} |
注意到命名为tmp的b_info结构体变量先于每一个压缩块头部被赋值并写入。b_info的定义同样位于/src/stub/src/include/linux.h
|
1
2
3
4
5
6
7
8
|
struct b_info { // 12-byte header before each compressed block uint32_t sz_unc; // uncompressed_size uint32_t sz_cpr; // compressed_size unsigned char b_method; // compression algorithm unsigned char b_ftid; // filter id unsigned char b_cto8; // filter parameter unsigned char b_unused;}; |
对于x86和ARM来说,他们相对应的pack2()与本例代码完全相同。
(3) 对pack3()的分析
......
pack3(fo, ft); // append loader
......
pack()中对pack3()的注释写着append loader,即添加loader,而实际上pack3()不仅为输出结果添加了一个loader,也将pack2()未处理的其他数据压缩后输出到结果中,并做了一系列调整。我们先从PackLinuxElf64::pack3()入手。
void PackLinuxElf64::pack3(OutputFile *fo, Filter &ft)
{
函数的第一部分调用了父类的pack3(),即PackLinuxElf::pack3()为文件添加loader,我们把对这个函数的关注暂时先放在脑后。接下来是对pack2()遗漏的文件的剩余部分进行压缩输出,随后写入一个b_info结构体。此时该结构体复用为UPX标志,在sz_cpr字段填入!UPX,其余字段清零。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
super::pack3(fo, ft); // loader follows compressed PT_LOADs // Then compressed gaps (including debuginfo.) unsigned total_in = 0, total_out = 0; for (unsigned k = 0; k < e_phnum; ++k) { Extent x; x.size = find_LOAD_gap(phdri, k, e_phnum); if (x.size) { x.offset = get_te64(&phdri[k].p_offset) + get_te64(&phdri[k].p_filesz); packExtent(x, total_in, total_out, 0, fo); } } // write block end marker (uncompressed size 0) b_info hdr; memset(&hdr, 0, sizeof(hdr)); set_le32(&hdr.sz_cpr, UPX_MAGIC_LE32); fo->write(&hdr, sizeof(hdr)); fpad4(fo); |
紧接着函数修改了输出文件中第一个phdr中segment的长度,添加了一个lsize。不难猜出这个lsize为loader长度。
set_te64(&elfout.phdr[0].p_filesz, sz_pack2 + lsize);
set_te64(&elfout.phdr[0].p_memsz, sz_pack2 + lsize);
对于共享库,函数遍历其每个Phdr,当segment具有PT_INTERP属性时挪到最后,具有PT_LOAD属性时调整各项值为loader空出位置,具有PT_DYNAMIC重定位属性时修改DT_INIT项的值,使DT_INIT正确指向原先的.init段地址,并清空Ehdr中关于section的数据,将原.init段地址保存在shoff中。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
if (0!=xct_off) { // shared library Elf64_Phdr *phdr = phdri; unsigned off = fo->st_size(); unsigned off_init = 0; // where in file upx_uint64_t va_init = sz_pack2; // virtual address upx_uint64_t rel = 0; upx_uint64_t old_dtinit = 0; for (int j = e_phnum; --j>=0; ++phdr) { upx_uint64_t const len = get_te64(&phdr->p_filesz); upx_uint64_t const ioff = get_te64(&phdr->p_offset); upx_uint64_t align= get_te64(&phdr->p_align); unsigned const type = get_te32(&phdr->p_type); if (phdr->T_INTERP==type) { // Rotate to highest position, so it can be lopped // by decrementing e_phnum. memcpy((unsigned char *)ibuf, phdr, sizeof(*phdr)); memmove(phdr, 1+phdr, j * sizeof(*phdr)); // overlapping memcpy(&phdr[j], (unsigned char *)ibuf, sizeof(*phdr)); --phdr; set_te16(&ehdri.e_phnum, --e_phnum); continue; } if (phdr->T_LOAD==type) { if (xct_off < ioff) { // Slide up non-first PT_LOAD. // AMD64 chip supports page sizes of 4KiB, 2MiB, and 1GiB; // the operating system chooses one. .p_align typically // is a forward-looking 2MiB. In 2009 Linux chooses 4KiB. // We choose 4KiB to waste less space. If Linux chooses // 2MiB later, then our output will not run. if ((1u<<12) < align) { align = 1u<<12; set_te64(&phdr->p_align, align); } off += (align-1) & (ioff - off); fi->seek(ioff, SEEK_SET); fi->readx(ibuf, len); fo->seek( off, SEEK_SET); fo->write(ibuf, len); rel = off - ioff; set_te64(&phdr->p_offset, rel + ioff); } else { // Change length of first PT_LOAD. va_init += get_te64(&phdr->p_vaddr); set_te64(&phdr->p_filesz, sz_pack2 + lsize); set_te64(&phdr->p_memsz, sz_pack2 + lsize); } continue; // all done with this PT_LOAD } // Compute new offset of &DT_INIT.d_val. if (phdr->T_DYNAMIC==type) { off_init = rel + ioff; fi->seek(ioff, SEEK_SET); fi->read(ibuf, len); Elf64_Dyn *dyn = (Elf64_Dyn *)(void *)ibuf; for (int j2 = len; j2 > 0; ++dyn, j2 -= sizeof(*dyn)) { if (dyn->DT_INIT==get_te64(&dyn->d_tag)) { old_dtinit = dyn->d_val; // copy ONLY, never examined unsigned const t = (unsigned char *)&dyn->d_val - (unsigned char *)ibuf; off_init += t; break; } } // fall through to relocate .p_offset } if (xct_off < ioff) set_te64(&phdr->p_offset, rel + ioff); } if (off_init) { // change DT_INIT.d_val fo->seek(off_init, SEEK_SET); upx_uint64_t word; set_te64(&word, va_init); fo->rewrite(&word, sizeof(word)); fo->seek(0, SEEK_END); } ehdri.e_shnum = 0; ehdri.e_shoff = old_dtinit; // easy to find for unpacking }} |
分析完子类的pack3()后我们将目光转向位于同一个源码文件下的PackLinuxElf::pack3()
这个pack3()的主要工作是为输出文件补充和修正一些字段。
|
01
02
03
04
05
06
07
08
09
10
|
void PackLinuxElf::pack3(OutputFile *fo, Filter &ft){ unsigned disp; unsigned const zero = 0; unsigned len = sz_pack2a; // after headers and all PT_LOAD unsigned const t = (4 & len) ^ ((!!xct_off)<<2); // 0 or 4 fo->write(&zero, t); len += t; |
这部分代码向输出文件中写入两个数值,第一个为输出文件中第一个b_info的偏移,第二个为截至目前为止的输出文件长度,该数值对于可执行文件来说即为loader偏移。
|
1
2
3
4
5
6
|
set_te32(&disp, 2*sizeof(disp) + len - (sz_elf_hdrs + sizeof(p_info) + sizeof(l_info))); fo->write(&disp, sizeof(disp)); // .e_entry - &first_b_info len += sizeof(disp); set_te32(&disp, len); // distance back to beginning (detect dynamic reloc) fo->write(&disp, sizeof(disp)); len += sizeof(disp); |
对于共享库文件,有三个额外的数值会被写入,分别是入口函数地址距第一个PT_LOAD段的偏移,意义未明的hatch_off和.init段地址。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
if (xct_off) { // is_shlib upx_uint64_t const firstpc_va = (jni_onload_va ? jni_onload_va : elf_unsigned_dynamic(Elf32_Dyn:T_INIT) ); set_te32(&disp, firstpc_va - load_va); fo->write(&disp, sizeof(disp)); len += sizeof(disp); set_te32(&disp, hatch_off); fo->write(&disp, sizeof(disp)); len += sizeof(disp); set_te32(&disp, xct_off); fo->write(&disp, sizeof(disp)); len += sizeof(disp); } sz_pack2 = len; // 0 mod 8 |
调用父类的pack3()添加decompressor解压缩器,即UPX的loader,随后更新l_info结构体中的size字段。
|
1
2
3
4
5
6
7
|
super::pack3(fo, ft); // append the decompressor set_te16(&linfo.l_lsize, up4( // MATCH03: up4 get_te16(&linfo.l_lsize) + len - sz_pack2a)); len = fpad4(fo); // MATCH03 ACC_UNUSED(len);} |
最关键的添加loader的函数又加深了一层。。。好吧我们继续看父类的pack3(),即PackUnix::pack3(),位于p_unix.cpp
|
1
2
3
4
5
6
7
8
|
void PackUnix::pack3(OutputFile *fo, Filter &/*ft*/){ upx_byte *p = getLoader(); lsize = getLoaderSize(); updateLoader(fo); patchLoaderChecksum(); fo->write(p, lsize);} |
该函数非常简单,调用了位于packer.cpp的Packer::getLoader(),通过linker获取了loader首字节,调用了位于同一个文件下的Packer::getLoaderSize()获取了loader长度,随后调用位于p_lx_elf.cpp的PackLinuxElf64::updateLoader更新入口点。
|
1
2
3
4
5
|
void PackLinuxElf64::updateLoader(OutputFile * /*fo*/){ set_te64(&elfout.ehdr.e_entry, sz_pack2 + get_te64(&elfout.phdr[0].p_vaddr));} |
调用位于p_unix.cpp的PackUnix::patchLoaderChecksum()更新了l_info信息。
|
01
02
03
04
05
06
07
08
09
10
11
12
|
void PackUnix::patchLoaderChecksum(){ unsigned char *const ptr = getLoader(); l_info *const lp = &linfo; // checksum for loader; also some PackHeader info lp->l_magic = UPX_MAGIC_LE32; // LE32 always set_te16(&lp->l_lsize, (upx_uint16_t) lsize); lp->l_version = (unsigned char) ph.version; lp->l_format = (unsigned char) ph.format; // INFO: lp->l_checksum is currently unused set_te32(&lp->l_checksum, upx_adler32(ptr, lsize));} |
最后将loader写入文件。
对于pack3()来说,x86与AMD64除了loader外并无区别,ARM的PackLinuxElf32::ARM_updateLoader()在入口点的设置上额外加上了_start符号的偏移。
(4) 对pack4()的分析
pack()的最后调用了pack4()对输出文件做最后的修补工作,调用了checckFinalCompressionRadio()检查压缩率。
|
1
2
3
4
5
6
7
8
|
...... pack4(fo, ft); // append PackHeader and overlay_offset; update Elf header // finally check the compression ratio if (!checkFinalCompressionRatio(fo)) throwNotCompressible();} |
对于后者分析的价值不大,我们将重心放在位于p_lx_elf.cpp的PackLinuxElf64::pack4()上
void PackLinuxElf64::pack4(OutputFile *fo, Filter &ft)
{
overlay_offset = sz_elf_hdrs + sizeof(linfo);
当使用了UPX参数--preserve-build-id后保存在pack1()中赋值的数据
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
if (opt->o_unix.preserve_build_id) { // calc e_shoff here and write shdrout, then o_shstrtab //NOTE: these are pushed last to ensure nothing is stepped on //for the UPX structure. unsigned const len = fpad4(fo); set_te64(&elfout.ehdr.e_shoff,len); int const ssize = sizeof(shdrout); shdrout.shdr[2].sh_offset = len+ssize; shdrout.shdr[1].sh_offset = shdrout.shdr[2].sh_offset+shdrout.shdr[2].sh_size; fo->write(&shdrout, ssize); fo->write(o_shstrtab,shdrout.shdr[2].sh_size); fo->write(buildid_data,shdrout.shdr[1].sh_size);}...... |
重写了第一个PT_LOAD段的文件大小和内存个映射大小,为了避免受到SE Linux的影响将两者设置为等同,随后调用了父类的pack4()增补数据PackHeader和overlay_offset
|
1
2
3
4
5
6
7
8
|
...... // Cannot pre-round .p_memsz. If .p_filesz < .p_memsz, then kernel // tries to make .bss, which requires PF_W. // But strict SELinux (or PaX, grSecurity) disallows PF_W with PF_X. set_te64(&elfout.phdr[0].p_filesz, sz_pack2 + lsize); elfout.phdr[0].p_memsz = elfout.phdr[0].p_filesz;super::pack4(fo, ft); // write PackHeader and overlay_offset...... |
重写了ELF文件头,这部分代码用到的数据都已经在pack2()和pack3()中被修改完成了。注意到为了避免SELinux不允许内存页同时具有可写和可执行的限制,作者注释掉了一行修改段属性的代码。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
...... // rewrite Elf header if (Elf64_Ehdr::ET_DYN==get_te16(&ehdri.e_type)) { upx_uint64_t const base= get_te64(&elfout.phdr[0].p_vaddr); set_te16(&elfout.ehdr.e_type, Elf64_Ehdr::ET_DYN); set_te16(&elfout.ehdr.e_phnum, 1); set_te64( &elfout.ehdr.e_entry, get_te64(&elfout.ehdr.e_entry) - base); set_te64(&elfout.phdr[0].p_vaddr, get_te64(&elfout.phdr[0].p_vaddr) - base); set_te64(&elfout.phdr[0].p_paddr, get_te64(&elfout.phdr[0].p_paddr) - base); // Strict SELinux (or PaX, grSecurity) disallows PF_W with PF_X //elfout.phdr[0].p_flags |= Elf64_Phdr:F_W; } fo->seek(0, SEEK_SET); if (0!=xct_off) { // shared library fo->rewrite(&ehdri, sizeof(ehdri)); fo->rewrite(phdri, e_phnum * sizeof(*phdri)); } else { if (Elf64_Phdr:T_NOTE==get_te64(&elfout.phdr[2].p_type)) { upx_uint64_t const reloc = get_te64(&elfout.phdr[0].p_vaddr); set_te64( &elfout.phdr[2].p_vaddr, reloc + get_te64(&elfout.phdr[2].p_vaddr)); set_te64( &elfout.phdr[2].p_paddr, reloc + get_te64(&elfout.phdr[2].p_paddr)); fo->rewrite(&elfout, sz_elf_hdrs); // FIXME fo->rewrite(&elfnote, sizeof(elfnote)); } else { fo->rewrite(&elfout, sz_elf_hdrs); } fo->rewrite(&linfo, sizeof(linfo)); }} |
对父类的pack4(),即位于p_unix.cpp的PackUnix::pack4()进行分析,发现其调用了writePackHeader(),然后写入了一个overlay_offset。从子类的pack4()第一行代码我们得知overlay_offset为新的Ehdr+Phdrs+l_info的长度。我们把目光转向位于p_unix.cpp的
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
PackUnix::writePackHeader()void PackUnix::writePackHeader(OutputFile *fo){ unsigned char buf[32]; memset(buf, 0, sizeof(buf)); const int hsize = ph.getPackHeaderSize(); assert((unsigned)hsize <= sizeof(buf)); // note: magic constants are always le32 set_le32(buf+0, UPX_MAGIC_LE32); set_le32(buf+4, UPX_MAGIC2_LE32); checkPatch(NULL, 0, 0, 0); // reset patchPackHeader(buf, hsize); checkPatch(NULL, 0, 0, 0); // reset fo->write(buf, hsize);} |
函数初始化了一个长度为buf[32]的数组,调用在try_pack()中初始化的PackHeader的成员函数getPackHeaderSize(),该函数位于packhead.cpp,通过对版本和架构的判断给出这个PackHeader的长度,对于Linux来说该长度为32
随后函数调用了位于packer.cpp的Packer::patchPackHeader(),而该函数进行检查后最终调用了位于packhead.cpp的PackHeader::putPackHeader()对该数组进行数据填充。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
void PackHeader::putPackHeader(upx_bytep p) { assert(get_le32(p) == UPX_MAGIC_LE32); if (get_le32(p + 4) != UPX_MAGIC2_LE32) { // fprintf(stderr, "MAGIC2_LE32: %x %x\n", get_le32(p+4), UPX_MAGIC2_LE32); throwBadLoader(); } int size = 0; int old_chksum = 0; // the new variable length header if (format < 128) { ...... } else { size = 32; old_chksum = get_packheader_checksum(p, size - 1); set_le32(p + 16, u_len); set_le32(p + 20, c_len); set_le32(p + 24, u_file_size); p[28] = (unsigned char) filter; p[29] = (unsigned char) filter_cto; assert(n_mru == 0 || (n_mru >= 2 && n_mru <= 256)); p[30] = (unsigned char) (n_mru ? n_mru - 1 : 0); } set_le32(p + 8, u_adler); set_le32(p + 12, c_adler); } else { ...... } p[4] = (unsigned char) version; p[5] = (unsigned char) format; p[6] = (unsigned char) method; p[7] = (unsigned char) level; // header_checksum assert(size == getPackHeaderSize()); // check old header_checksum if (p[size - 1] != 0) { if (p[size - 1] != old_chksum) { // printf("old_checksum: %d %d\n", p[size - 1], old_chksum); throwBadLoader(); } } // store new header_checksum p[size - 1] = get_packheader_checksum(p, size - 1);} |
根据代码很容易整理出一个Linux通用的结构体
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
struct packHeader{ uint32_t magic; uint8_t version; uint8_t format; uint8_t method; uint8_t level; uint32_t u_adler; uint32_t c_adler; uint32_t u_len; uint32_t c_len; uint32_t u_file_size; uint8_t filter; uint8_t filter_cto; uint8_t n_mru; uint16_t checksum;}; |
对于ARM,PackLinuxElf32::pack4()在重写结构时若文件中有jni_onload,同样需要进行重写。
0x06 Loader的获取
至此,我们已经将UPX对输入文件的加壳流程梳理了一遍,但除了我不打算在这篇文章中讲解的其对代码段实现的Filter压缩机制外,我们还有一个问题没解决——loader从哪来?loader作为加壳后文件运行时的自解密代码,其重要性不言而喻。因此在本节中我们将追查loader的来源和构造流程。
在分析PackUnix::pack3()时,函数通过getLoader()获取了loader的首地址写入文件,这个函数位于packer.cpp,调用了linker->getLoader()获取loader,最后我们在linker.cpp中找到了“真正的”getLoader()
|
1
2
3
4
5
|
upx_byte *ElfLinker::getLoader(int *llen) const { if (llen) *llen = outputlen; return output;} |
这里的output和outputlen都是linker类的成员变量。显然,我们需要找到对output进行赋值的函数,满足这个条件的函数只有位于linker.cpp中的ElfLinker::addLoader()
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
int ElfLinker::addLoader(const char *sname) { ...... for (char *sect = begin; sect < end;) { ...... if (sect[0] == '+') // alignment { ...... } else { Section *section = findSection(sect); ...... memcpy(output + outputlen, section->input, section->size); section->output = output + outputlen; // printf("section added: 0x%04x %3d %s\n", outputlen, section->size, section->name); outputlen += section->size; ...... } sect += strlen(sect) + 1; } free(begin); return outputlen;} |
所以我们的关注点应该在于对addLoader()的调用和对Section这个结构体的赋值。
在pack2()的packExtent()中,函数针对可执行的PT_LOAD段调用了compressWithFilters()进行压缩,在compressWithFilters()的末尾有这么一行函数调用。
buildLoader(&best_ft);
函数名已经告诉了我们这个函数想干嘛,并且pack()函数只有在此处compressWithFilters()会被激活,显然这里就是唯一一个生成loader的地方。
让我们更深入地挖掘。对于AMD 64,其实现为p_lx_elf.cpp中的PackLinuxElf64amd::buildLoader()
|
01
02
03
04
05
06
07
08
09
10
11
12
|
void PackLinuxElf64amd::buildLoader(const Filter *ft){ if (0!=xct_off) { // shared library buildLinuxLoader( stub_amd64_linux_shlib_init, sizeof(stub_amd64_linux_shlib_init), NULL, 0, ft ); return; } buildLinuxLoader( stub_amd64_linux_elf_entry, sizeof(stub_amd64_linux_elf_entry), stub_amd64_linux_elf_fold, sizeof(stub_amd64_linux_elf_fold), ft);} |
发现其对于动态库和可执行文件输入buildLinuxLoader()的参数不同,stub_amd64_linux_shlib_init,stub_amd64_linux_elf_entry,stub_amd64_linux_elf_fold分别位于/src/stub/amd64-linux.shlib-init.h,/src/stub/amd64-linux.elf-entry和/src/stub/amd64-linux.elf.fold中。PackLinuxElf64::buildLinuxLoader()位于文件p_lx_elf.cpp中。
函数开头调用了initLoader(),对于共享库,传入的参数为shlib_init,对于可执行文件,参数为elf_entry,我们先跳过这个函数继续分析。
|
01
02
03
04
05
06
07
08
09
10
|
void PackLinuxElf64::buildLinuxLoader( upx_byte const *const proto, unsigned const szproto, upx_byte const *const fold, unsigned const szfold, Filter const *ft){initLoader(proto, szproto);...... |
由于共享库不会传入fold和szfold参数,这个if语句块只对可执行文件有效。这个语句块从elf_fold中提取了ehdr+phdrs+l_info之后的所有内容进行压缩,并在压缩数据块头部补上一个b_info结构体,最后放在名为FOLDEXEC的Section内。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
...... if (0 < szfold) { struct b_info h; memset(&h, 0, sizeof(h)); unsigned fold_hdrlen = 0; cprElfHdr1 const *const hf = (cprElfHdr1 const *)fold; fold_hdrlen = umax(0x80, sizeof(hf->ehdr) + get_te16(&hf->ehdr.e_phentsize) * get_te16(&hf->ehdr.e_phnum) + sizeof(l_info) ); h.sz_unc = ((szfold < fold_hdrlen) ? 0 : (szfold - fold_hdrlen)); h.b_method = (unsigned char) ph.method; h.b_ftid = (unsigned char) ph.filter; h.b_cto8 = (unsigned char) ph.filter_cto; unsigned char const *const uncLoader = fold_hdrlen + fold; h.sz_cpr = MemBuffer::getSizeForCompression(h.sz_unc + (0==h.sz_unc)); unsigned char *const cprLoader = New(unsigned char, sizeof(h) + h.sz_cpr); int r = upx_compress(uncLoader, h.sz_unc, sizeof(h) + cprLoader, &h.sz_cpr, NULL, ph.method, 10, NULL, NULL ); if (r != UPX_E_OK || h.sz_cpr >= h.sz_unc) throwInternalError("loader compression failed"); unsigned const sz_cpr = h.sz_cpr; set_te32(&h.sz_cpr, h.sz_cpr); set_te32(&h.sz_unc, h.sz_unc); memcpy(cprLoader, &h, sizeof(h)); // This adds the definition to the "library", to be used later. linker->addSection("FOLDEXEC", cprLoader, sizeof(h) + sz_cpr, 0); delete [] cprLoader; } else { linker->addSection("FOLDEXEC", "", 0, 0); } ...... |
调用了addStubEntrySections()把sections添加到linker->output中,等待pack3()写入文件。调用relocateLoader()重定位loader。当文件为可执行文件时调用defineSymbols()修改symbols,最后重定位loader
......
addStubEntrySections(ft);
if (0==xct_off)
defineSymbols(ft); // main program only, not for shared lib
relocateLoader();
}
这里提到的sections,symbols和relocateLoader()中提到的relocation records都是什么呢?我们以可执行文件为例,将stub_amd64_linux_elf_entry的内容转换为字符输出,在文件末尾发现了三个表:
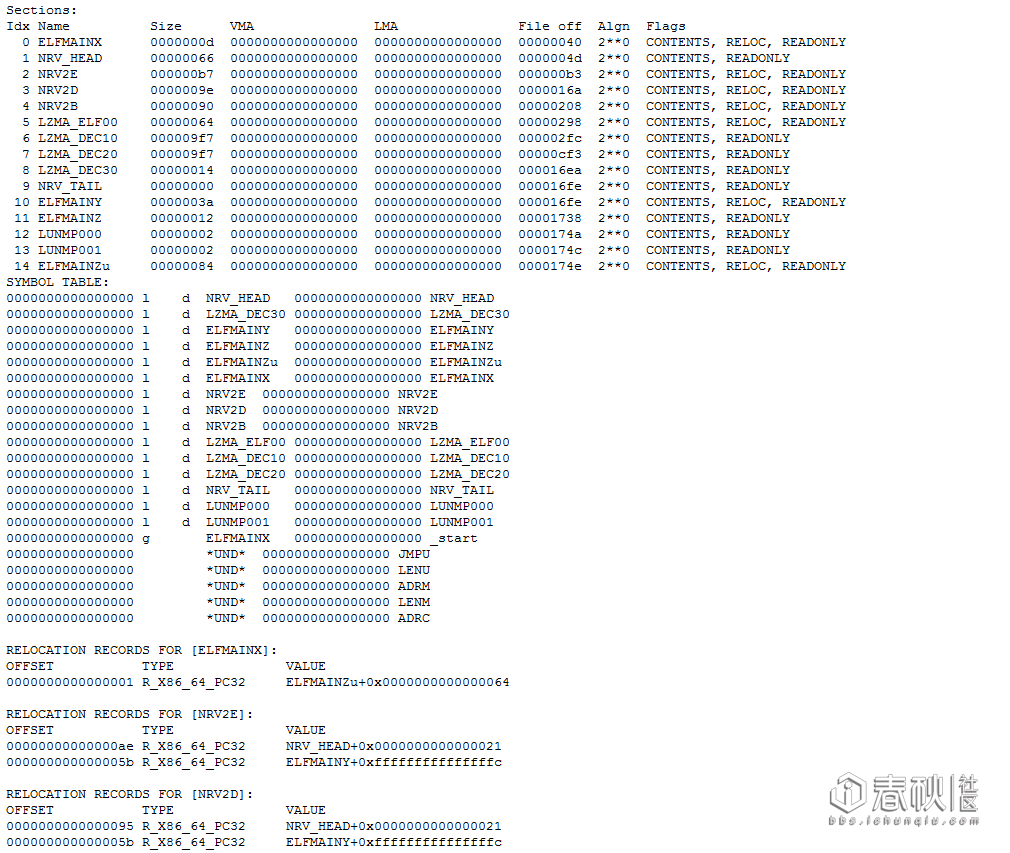
sections表中的File off应该指的是对应的段在stub_amd64_linux_elf_entry中的偏移。为了验证我们的想法,我们用IDA打开一个加壳后的AMD64 ELF文件对比ELFMAINX段

除了call指令的地址需要重定位外,其余的opcode都是一致的。对之后的内容进行验证,发现在这个可执行文件的loader中存在ELFMAINX, NRV_HEAD, NRV2E, NRV_TAIL/ELFMAINY…ELFMAINZ, LUNMP000, ELFMAINZu几个段,其中在ELFMAINY和ELFMAINZ中插入了其他指令。
回到PackLinuxElf64::buildLinuxLoader()中,我们还剩下initLoader(),addStubEntrySections()两个较为重要的函数没看. Packer::initLoader()位于packer.cpp初始化了一个linker,调用了位于linker.cpp中的ELFLinker::init()
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
void ElfLinker::init(const void *pdata_v, int plen) { const upx_byte *pdata = (const upx_byte *) pdata_v; if (plen >= 16 && memcmp(pdata, "UPX#", 4) == 0) { // decompress pre-compressed stub-loader ...... } else { inputlen = plen; input = new upx_byte[inputlen + 1]; if (inputlen) memcpy(input, pdata, inputlen); } input[inputlen] = 0; // NUL terminate output = new upx_byte[inputlen ? inputlen : 0x4000]; outputlen = 0; if ((int) strlen("Sections:\n" "SYMBOL TABLE:\n" "RELOCATION RECORDS FOR ") < inputlen) { int pos = find(input, inputlen, "Sections:\n", 10); assert(pos != -1); char *psections = (char *) input + pos; char *psymbols = strstr(psections, "SYMBOL TABLE:\n"); assert(psymbols != NULL); char *prelocs = strstr(psymbols, "RELOCATION RECORDS FOR "); assert(prelocs != NULL); preprocessSections(psections, psymbols); preprocessSymbols(psymbols, prelocs); preprocessRelocations(prelocs, (char *) input + inputlen); addLoader("*UND*"); }} |
函数通过检测读入内容的标志位判断加壳还是脱壳,如果是加壳则初始化output,最后将全部sections,symbols和relocations读入内存。
再看位于p_lx_elf.cpp的PackLinuxElf::addStubEntrySections()
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
voidPackLinuxElf::addStubEntrySections(Filter const *){ int all_pages = opt->o_unix.unmap_all_pages | is_big; addLoader("ELFMAINX", NULL); if (hasLoaderSection("ELFMAINXu")) { // brk() trouble if static all_pages |= (Elf32_Ehdr::EM_ARM==e_machine && 0x8000==load_va); addLoader((all_pages ? "LUNMP000" : "LUNMP001"), "ELFMAINXu", NULL); } //addLoader(getDecompressorSections(), NULL); addLoader( ( M_IS_NRV2E(ph.method) ? "NRV_HEAD,NRV2E,NRV_TAIL" : M_IS_NRV2D(ph.method) ? "NRV_HEAD,NRV2D,NRV_TAIL" : M_IS_NRV2B(ph.method) ? "NRV_HEAD,NRV2B,NRV_TAIL" : M_IS_LZMA(ph.method) ? "LZMA_ELF00,+80C,LZMA_DEC20,LZMA_DEC30" : NULL), NULL); if (hasLoaderSection("CFLUSH")) addLoader("CFLUSH"); addLoader("ELFMAINY,IDENTSTR,+40,ELFMAINZ", NULL); if (hasLoaderSection("ELFMAINZu")) { addLoader((all_pages ? "LUNMP000" : "LUNMP001"), "ELFMAINZu", NULL); } addLoader("FOLDEXEC", NULL);} |
该函数通过标志位和某些sections是否存在将sections拼接到output中,分析函数流程我们发现其添加顺序为ELFMAINX, NRV_HEAD, NRV2E, NRV_TAIL, ELFMAINY, IDENTSTR, … ELFMAINZ, LUNMP000, ELFMAINZu, FOLDEXEC。除了IDENTSTR和位于stub_amd64_linux_elf_fold的内容,其余sections的顺序和我们在加壳后样本头部找到的sections块和顺序完全一致。至此我们完成了加壳文件的最后一块拼图——loader的拼接。
0x07 总结
通过对加壳部分源码的分析,我们可以整理出一份Linux ELF通用的UPX加壳文件格式,分为可执行文件和共享库总结如下:

ELF共享库(shared library)被UPX加壳后的文件格式

UPX源码分析——加壳篇的更多相关文章
- 鸿蒙内核源码分析(进程镜像篇)|ELF是如何被加载运行的? | 百篇博客分析OpenHarmony源码 | v56.01
百篇博客系列篇.本篇为: v56.xx 鸿蒙内核源码分析(进程映像篇) | ELF是如何被加载运行的? | 51.c.h.o 加载运行相关篇为: v51.xx 鸿蒙内核源码分析(ELF格式篇) | 应 ...
- Hadoop2源码分析-准备篇
1.概述 我们已经能够搭建一个高可用的Hadoop平台了,也熟悉并掌握了一个项目在Hadoop平台下的开发流程,基于Hadoop的一些套件我们也能够使用,并且能利用这些套件进行一些任务的开发.在Had ...
- Hadoop2源码分析-MapReduce篇
1.概述 前面我们已经对Hadoop有了一个初步认识,接下来我们开始学习Hadoop的一些核心的功能,其中包含mapreduce,fs,hdfs,ipc,io,yarn,今天为大家分享的是mapred ...
- JUC源码分析-线程池篇(二)FutureTask
JUC源码分析-线程池篇(二)FutureTask JDK5 之后提供了 Callable 和 Future 接口,通过它们就可以在任务执行完毕之后得到任务的执行结果.本文从源代码角度分析下具体的实现 ...
- 鸿蒙内核源码分析(索引节点篇) | 谁是文件系统最重要的概念 | 百篇博客分析OpenHarmony源码 | v64.01
百篇博客系列篇.本篇为: v64.xx 鸿蒙内核源码分析(索引节点篇) | 谁是文件系统最重要的概念 | 51.c.h.o 文件系统相关篇为: v62.xx 鸿蒙内核源码分析(文件概念篇) | 为什么 ...
- 鸿蒙内核源码分析(编译过程篇) | 简单案例窥视GCC编译全过程 | 百篇博客分析OpenHarmony源码| v57.01
百篇博客系列篇.本篇为: v57.xx 鸿蒙内核源码分析(编译过程篇) | 简单案例窥视编译全过程 | 51.c.h.o 编译构建相关篇为: v50.xx 鸿蒙内核源码分析(编译环境篇) | 编译鸿蒙 ...
- 鸿蒙内核源码分析(重定位篇) | 与国际接轨的对外部发言人 | 百篇博客分析OpenHarmony源码 | v55.01
百篇博客系列篇.本篇为: v55.xx 鸿蒙内核源码分析(重定位篇) | 与国际接轨的对外部发言人 | 51.c.h.o 加载运行相关篇为: v51.xx 鸿蒙内核源码分析(ELF格式篇) | 应用程 ...
- 鸿蒙内核源码分析(静态链接篇) | 完整小项目看透静态链接过程 | 百篇博客分析OpenHarmony源码 | v54.01
百篇博客系列篇.本篇为: v54.xx 鸿蒙内核源码分析(静态链接篇) | 完整小项目看透静态链接过程 | 51.c.h.o 下图是一个可执行文件编译,链接的过程. 本篇将通过一个完整的小工程来阐述E ...
- 鸿蒙内核源码分析(ELF解析篇) | 你要忘了她姐俩你就不是银 | 百篇博客分析OpenHarmony源码 | v53.02
百篇博客系列篇.本篇为: v53.xx 鸿蒙内核源码分析(ELF解析篇) | 你要忘了她姐俩你就不是银 | 51.c.h.o 加载运行相关篇为: v51.xx 鸿蒙内核源码分析(ELF格式篇) | 应 ...
随机推荐
- spring学习 十八 spring的声明事物
1.编程式事务: 1.1 由程序员编程事务控制代码.commit与rollback都需要程序员决定在哪里调用,例如jdbc中conn.setAutoCimmit(false),conn.commit( ...
- PHP字符串大小写转换函数
string strtolower(string $str) 将字符串转换为小写 string strtoupper(string $str) 将字符串转换为大写 $str1 = 'html'; $s ...
- AOP 环绕通知 (Schema-base方式) 和 AspectJ方式在通知中获取切点的参数
环绕通知(Schema- base方式) 1.把前置通知和后置通知都写到一个通知中,组成了环绕通知 2.实现步骤: 2.1 新建一个类实现 MethodInterceptor 接口 public cl ...
- 2018.12.22 spoj7258 Lexicographical Substring Search(后缀自动机)
传送门 samsamsam基础题. 题意简述:给出一个串,询问第kkk大的本质不同的串. 然而这就是弦论的简化版. 我们把samsamsam建出来然后贪心选择就行了. 代码: #include< ...
- 2018.10.24 bzoj3195: [Jxoi2012]奇怪的道路(状压dp)
传送门 f[i][j][k]f[i][j][k]f[i][j][k]表示前iii个点连了jjj条边,第i−K+1i-K+1i−K+1~iii个点连边数的奇偶性为kkk时的方案数. 转移规定只能从后向前 ...
- java常用设计模式五:建造者模式
1.定义 是一种对象构建的设计模式,它可以将复杂对象的建造过程抽象出来(抽象类别),使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象. 产品类:一般是一个较为复杂的对象,也就是说创建对象的 ...
- c++关键字volatile的作用
1.易变性 1.1概念 编译器对volatile修饰的变量,当要读取这个变量时,任何情况下都会从内存中读取,而不会从寄存器缓存中读取(因为每次都从内存中读取体现出变量的“易变”) 1.2测试代码(VS ...
- UVaLive 3641 Leonardo's Notebook (置换)
题意:给定一个置换 B 问是否则存在一个置换 A ,使用 A^2 = B. 析:可以自己画一画,假设 A = (a1, a2, a3)(b1, b2, b3, b4),那么 A^2 = (a1, a2 ...
- 安卓hid驱动触摸屏
在kernel/drivers/hid/ 目录下三个文件中添加usbtouch的pid vid, 文件分别是hid-multitouch.c .hid-ids.h.hid-core.c 具体如何添加可 ...
- noip第34课作业
1. 信息加密 [问题描述] 在传递信息的过程中,为了加密,有时需要按一定规则将文本转换成密文发送出去.有一种加密规则是这样的:1. 对于字母字符,将其转换成其后的第3个字母.例如:A→D,a→ ...