sklearn6_生成分类数据
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

生成2类数据
n_features :特征个数= n_informative() + n_redundant + n_repeated
n_informative:多信息特征的个数
n_redundant:冗余信息,informative特征的随机线性组合
n_repeated :重复信息,随机提取n_informative和n_redundant 特征
n_classes:分类类别
n_clusters_per_class :某一个类别是由几个cluster构成的
from sklearn import preprocessing
import numpy as np
#生成分类数据的分类器
from sklearn.datasets.samples_generator import make_classification
#自动生成训练数据和测试数据
from sklearn.cross_validation import train_test_split
#导入支持向量模型
from sklearn.svm import SVC
import matplotlib.pyplot as plt x,y=make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22,n_clusters_per_class=1,scale=100) #c=y表示color为黄色
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()

生成4类数据
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 7 15:54:56 2018 @author: Administrator
""" from sklearn import preprocessing
import numpy as np
#生成分类数据的分类器
from sklearn.datasets.samples_generator import make_classification
#自动生成训练数据和测试数据
from sklearn.cross_validation import train_test_split
#导入支持向量模型
from sklearn.svm import SVC
import matplotlib.pyplot as plt #n_classes=4生成4类数据
x,y=make_classification(n_classes=4,n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22,n_clusters_per_class=1,scale=100) #c=y表示color为黄色
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
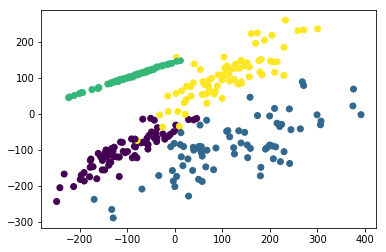
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 7 16:51:38 2018 @author: Administrator
""" import matplotlib.pyplot as plt from sklearn.datasets import make_classification
from sklearn.datasets import make_blobs
from sklearn.datasets import make_gaussian_quantiles
from sklearn.datasets import make_hastie_10_2 plt.figure(figsize=(8, 8))
plt.subplots_adjust(bottom=.05, top=.9, left=.05, right=.95) plt.subplot(421)
plt.title("One informative feature, one cluster per class", fontsize='small')
X1, Y1 = make_classification(n_samples=1000,n_features=2, n_redundant=0, n_informative=1,
n_clusters_per_class=1)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1) plt.subplot(422)
plt.title("Two informative features, one cluster per class", fontsize='small')
X1, Y1 = make_classification(n_samples=1000,n_features=2, n_redundant=0, n_informative=2,
n_clusters_per_class=1)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1) plt.subplot(423)
plt.title("Two informative features, two clusters per class", fontsize='small')
X2, Y2 = make_classification(n_samples=1000,n_features=2, n_redundant=0, n_informative=2)
plt.scatter(X2[:, 0], X2[:, 1], marker='o', c=Y2) plt.subplot(424)
plt.title("Multi-class, two informative features, one cluster",
fontsize='small')
X1, Y1 = make_classification(n_samples=1000,n_features=2, n_redundant=0, n_informative=2,
n_clusters_per_class=1, n_classes=3)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1) plt.subplot(425)
plt.title("Three blobs", fontsize='small')
X1, Y1 = make_blobs(n_samples=1000,n_features=2, centers=3)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1) plt.subplot(426)
plt.title("Gaussian divided into four quantiles", fontsize='small')
X1, Y1 = make_gaussian_quantiles(n_samples=1000,n_features=2, n_classes=4)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1) plt.subplot(427)
plt.title("hastie data ", fontsize='small')
X1, Y1 = make_hastie_10_2(n_samples=1000)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
plt.show()

# -*- coding: utf-8 -*-
"""
Created on Sun Jan 7 16:29:35 2018 @author: Administrator
""" import matplotlib.pyplot as plt from sklearn.datasets import make_classification
from sklearn.datasets import make_blobs
from sklearn.datasets import make_gaussian_quantiles
from sklearn.datasets import make_hastie_10_2 #画布的大小为长20cm高20cm
plt.figure(figsize=(15,10)) #标题,fontsize为标题字体大小
plt.title("Gaussian divided into six quantiles", fontsize='large')
X1, Y1 = make_gaussian_quantiles(n_samples=1000,n_features=2, n_classes=6) #绘制点,X1[:, 0]为点的x列表值, X1[:, 1]为点的y列表值, c=Y1表示颜色,c为color缩写
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
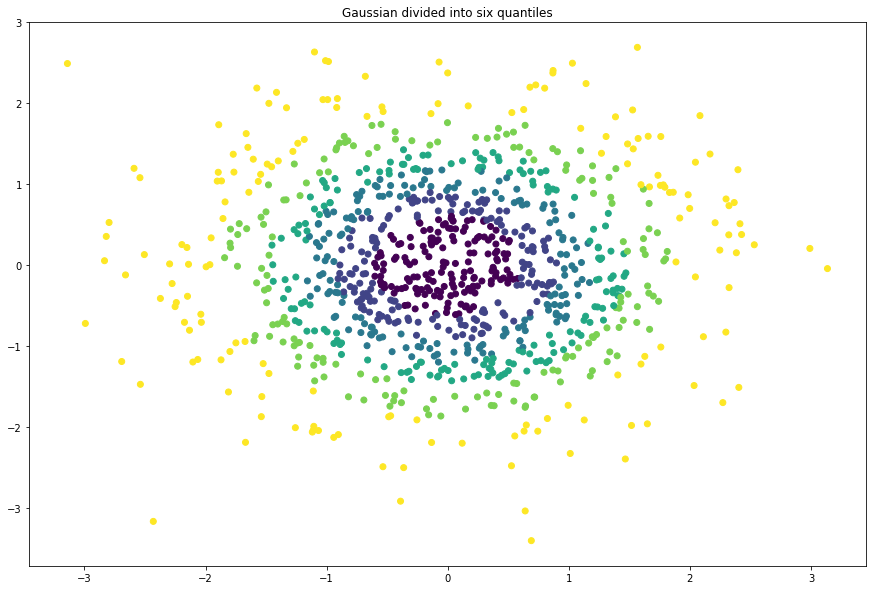
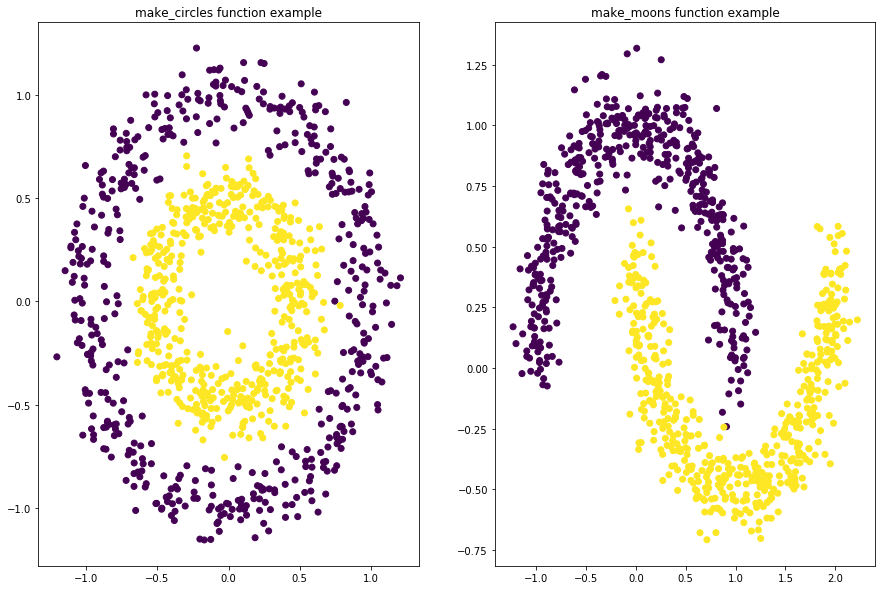
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 7 16:51:38 2018 @author: Administrator
""" from sklearn.datasets import make_circles
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
import numpy as np #画布的大小为长20cm高20cm
plt.figure(figsize=(15,10)) fig=plt.figure(1)
x1,y1=make_circles(n_samples=1000,factor=0.5,noise=0.1)
plt.subplot(121)
plt.title('make_circles function example')
plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1) plt.subplot(122)
x1,y1=make_moons(n_samples=1000,noise=0.1)
plt.title('make_moons function example')
plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1)
plt.show()
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149( 欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章)

sklearn6_生成分类数据的更多相关文章
- Python之机器学习-sklearn生成随机数据
sklearn-生成随机数据 import numpy as np import pandas as pd import matplotlib.pyplot as plt from matplotli ...
- 无限级分类及生成json数据
第一步,先去数据库查询类别数据,然后交给生成json数据的函数处理,代码如下: /*生成类别JSON数据*/ public function wirteJson(){ $dataInfo = \thi ...
- SAP QA32 做使用决策系统报错:分类数据的不一致性=>交易终止
SAP QA32 做使用决策系统报错:分类数据的不一致性=>交易终止 QA32,对如下检验批做处理,系统报错, 试图使用MSC3N去显示这个批次主数据,同样报错, 原因在于批次的分类数据产生后, ...
- flask实战-个人博客-数据库-生成虚拟数据 --
3.生成虚拟数据 为了方便编写程序前台和后台功能,我们在创建数据库模型后就编写生成虚拟数据的函数. 1)管理员 用于生成虚拟管理员信息的fake_admin()函数如下所示: personalBlog ...
- Enterprise Solution 生成实体数据访问接口与实现类型 Code Smith 6.5 模板文件下载
数据库表定义为SalesOrder,用LLBL Gen Pro生成的实体定义是SalesOrderEntity,再用Code Smith生成的数据读写接口是ISalesOrderManager,最后是 ...
- 改用C++生成自动化数据表
改用C++生成自动化数据表 前面的文章中,我们讨论了使用一个基于.NET的第三方程序库来从程序中来生成数据表.在我看来,这整个思路是非常有用的,例如为显示测试结果.我经常会自己在博客中尝试各种像这样的 ...
- SQL Server中公用表表达式 CTE 递归的生成帮助数据,以及递归的典型应用
本文出处:http://www.cnblogs.com/wy123/p/5960825.html 我们在做开发的时候,有时候会需要一些帮助数据,必须需要连续的数字,连续间隔的时间点,连续的季度日期等等 ...
- 公用表表达式(CTE)递归的生成帮助数据
本文的作者辛苦了,版权问题特声明本文出处:http://www.cnblogs.com/wy123/p/5960825.html 工作有时候会需要一些帮助数据,必须需要连续的数字,连续间隔的时间点,连 ...
- TreeView递归绑定无限分类数据
TreeView递归绑定无限分类数据 实现一个动态绑定,无限级分类数据时,需要将数据绑定到TreeView控件,分类表的结构是这样的: 字段 类型 Id int ParentId int Name N ...
随机推荐
- 11.10 (上午)开课二个月零六天(ajax基础,ajax做登录)
test.php <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://ww ...
- MySQL清理慢查询日志slow_log的方法
一.清除原因 因为之前打开了慢查询,导致此表越来越大达到47G,导致磁盘快被占满,使用xtrabackup进行备份的时候文件也超大. mysql> show variables like 'lo ...
- Python学习之路(一)之Python基础1
目录 Python基础初识 1.Python介绍 1.1.Python简介 1.2.Python特点 1.3.Python应用领域 1.4.Python解释器的种类 2.Python基础初识 2.1. ...
- [arc102E]Stop. Otherwise...[容斥+二项式定理]
题意 给你 \(n\) 个完全相同骰子,每个骰子有 \(k\) 个面,分别标有 \(1\) 到 \(k\) 的所有整数.对于\([2,2k]\) 中的每一个数 \(x\) 求出有多少种方案满足任意两个 ...
- 基于spring的redisTemplate的缓存工具类
pom.xml文件添加 <!-- config redis data and client jar --><dependency> <groupId>org.spr ...
- Java和C#基本类库的区别
java.lang java .net Boolean System.Boolean Byte System. Byte Character System.Char Class System.Type ...
- 这可能是最详细的Python文件操作
删除 # ==================删除==================# 只能删除文件,若为目录则报错# 若文件正在使用,Windows下会直接报错,Linux下会在目录表中删除记录, ...
- kafka的简单理解
经典组合: Flume+Kafka+Storm+HDFS/HBase Flume:分布式采集 Kafka:分布式缓存 Kafka简介: 一种分布式的.基于发布/订阅的消息系统(Scala编写的) Ka ...
- 带WIFI模块布局布线要点。
带WIFI模块布局布线要求: 1: RF底部不能铺铜要挖空不能有GND否则RF信号会被耦合掉从而无法发送出去. 2:WIFI模块下方不能打孔尽量不走线不打孔避开其他信号穿过下方,要整体的铺铜 3:连接 ...
- 《杜增强讲Unity之Tanks坦克大战》1-准备工作
0.案例介绍 0.1开始界面 点击Play Now 进入游戏界面 左边的坦克使用ws控制前后移动,ad键左右旋转,空格键开火 右边的坦克使用方向键上下控制前后移动,方向键左右键实现左右旋转 ...