SQL Server 行列相互转换命令:PIVOT和UNPIVOT使用详解
一、使用PIVOT和UNPIVOT命令的SQL Server版本要求
1.数据库的最低版本要求为SQL Server 2005 或更高。
2.必须将数据库的兼容级别设置为90 或更高。
3.查看我的数据库版本及兼容级别。
如果不知道怎么看数据库版本或兼容级别的话可以在SQL Server Management Studio新建一个查询窗口输入:print @@version,运行之后在我的本机上得到:
Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600.1 (Intel X86)
Apr 2 2010 15:53:02
Copyright (c) Microsoft Corporation
Express Edition with Advanced Services on Windows NT 5.2 <X86> (Build 3790: Service Pack 2)
然后我们选择一个数据库然后右键-属性 选择[选项]得到下图的信息。

在确认数据库的版本和兼容级别符合1,2点的要求后你才可以接着继续往下学习。
二、使用PIVOT 实现数据表的列转行
1.在这里我们先构建一个测试数据表(这里使用的是临时表,以方便我们在退出会话的时候自动删除表及其数据)
首先我们先设计一个表架构为#Student { 学生编号[PK], 姓名, 性别, 所属班级 }的表,然后编写如下T-SQL
--创建临时表(仅演示,表结构的不合理还请包涵)
CREATE TABLE #Student ([学生编号] INT IDENTITY(1, 1) PRIMARY KEY, [姓名] NVARCHAR(20), [性别] NVARCHAR(1), [所属班级] NVARCHAR(20))
--给临时表插入数据
INSERT INTO #Student ([姓名], [性别], [所属班级])
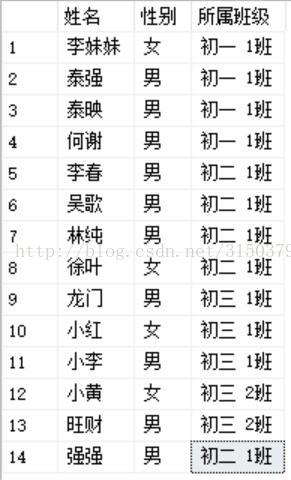
SELECT '李妹妹', '女', '初一 1班' UNION ALL
SELECT '泰强', '男', '初一 1班' UNION ALL
SELECT '泰映', '男', '初一 1班' UNION ALL
SELECT '何谢', '男', '初一 1班' UNION ALL
SELECT '李春', '男', '初二 1班' UNION ALL
SELECT '吴歌', '男', '初二 1班' UNION ALL
SELECT '林纯', '男', '初二 1班' UNION ALL
SELECT '徐叶', '女', '初二 1班' UNION ALL
SELECT '龙门', '男', '初三 1班' UNION ALL
SELECT '小红', '女', '初三 1班' UNION ALL
SELECT '小李', '男', '初三 1班' UNION ALL
SELECT '小黄', '女', '初三 2班' UNION ALL
SELECT '旺财', '男', '初三 2班' UNION ALL
SELECT '强强', '男', '初二 1班';
以下是查询的结果:
2.查询各班级的总人数
SELECT [所属班级] AS [班级], COUNT(1) AS [人数] FROM #Student GROUP BY [所属班级] ORDER BY [人数] DESC 班级 人数
-------- -----------
初二 1班 5
初一 1班 4
初三 1班 3
初三 2班 2
好了,在这里我希望把上面的表{ 班级, 人数 } 由 班级[行] 的显示转换为 班级[列] 的显示格式!
在此你会看到第一个PIVOT示例。是否很期待??
3.编写第一个PIVOT示例
SELECT '班级总人数:' AS [总人数], [初一 1班], [初一 2班], [初二 1班], [初三 1班], [初三 2班]
FROM (
SELECT [所属班级] AS [班级], [姓名] FROM #Student) AS [SourceTable]
PIVOT (COUNT([姓名]) FOR [班级] IN ([初一 1班], [初一 2班], [初二 1班], [初三 1班], [初三 2班]) ) AS [PivotTable] 总人数 初一 1班 初一 2班 初二 1班 初三 1班 初三 2班
----------- ----------- ----------- ----------- ----------- -----------
班级总人数: 4 0 5 3 2
在结果表中我们看到了对于不存在的班级初一2班它的总人数为0,这符合我们预期的结果!
解释:使用POVIT首先你需要在FROM子句内定义2个表:
A.一个称为源表(SourceTable)。
B.另一个称为数据透视表(PivotTable)。
语法:
SELECT <未透视的列>,
[第一个透视列] AS <列别名>,
[第二个透视列] AS <列别名>,
...
[最后一个透视列] AS <列别名>
FROM (<SELECT查询>) AS <源表> PIVOT (<聚合函数>(<转换后列的值>) FOR [<需要转换为行的列>] IN ([第一个透视列], [第二个透视列],... [最后一个透视列])) AS <数据透视表>
<可选的ORDER BY子句>;
以上的PIVOT子句内的第1…n个透视列的值均为需要转换为行的列的常量值,需要用[]括起,支持GUID,字符串及各种数字!
4.下面演示一个较为高级的行转列的应用示例
--使用PIVOT查询班级内的男女学生人数及总人数
SELECT [所属班级] AS [班级], [男] AS [男生人数], [女] AS [女生人数], [男] + [女] AS [总人数]
FROM (
SELECT [姓名], [所属班级], [性别] FROM #Student) AS [SourceTable]
PIVOT (COUNT([姓名]) FOR [性别] IN ([男], [女])) AS [PivotTable]
ORDER BY [总人数] DESC 班级 男生人数 女生人数 总人数
-------- ----------- ----------- -----------
初二 1班 4 1 5
初一 1班 3 1 4
初三 1班 2 1 3
初三 2班 1 1 2
三、使用UNPIVOT 实现的功能其实与PIVOT恰恰相反
1.语法同PIVOT但是UNPIVOT的子句没有聚合函数
SELECT
<未逆透视的列>,
[合并后的列] AS <列别名>,
[行值的列名] AS <列别名>
FROM (
<SELECT查询>
) AS <源表>
UNPIVOT (
<行值的列名>
FOR <将原来多个列合并到单个列的列名> IN (
[第一个合并列], [第二个合并列],
...
[最后一个合并列]
)
) AS <数据逆透视表>
<可选的ORDER BY子句>;
2.看上面的语法感觉很浮云,不怕,这里带例子(继续使用II中用到的PIVOT表)
--源表
SELECT '班级总人数:' AS [总人数], [初一 1班], [初一 2班], [初二 1班], [初三 1班], [初三 2班]
INTO #PivotTable --为了使表达意图更清晰,我把PIVOT处理后的表放到一个临时表当中
FROM (
SELECT
[所属班级] AS [班级],
[学生编号]
FROM #Student
) AS [SourceTable]
PIVOT (COUNT([学生编号]) FOR [班级] IN ([初一 1班], [初一 2班], [初二 1班], [初三 1班], [初三 2班] ) ) AS [PivotTable]

将多个列合并到单个列的转换的语句!!!
--结果
SELECT [班级], [总人数]
FROM (
SELECT [初一 1班], [初一 2班],[初二 1班], [初三 1班], [初三 2班]
FROM #PivotTable ) AS [s]
UNPIVOT ([总人数],[初一 1班],[初一 2班],[初二 1班],[初三 1班], [初三 2班])) AS [un_p]

执行下面代码:
SELECT [所属班级] AS [班级],[男] AS [男生人数],[男] + [女] AS [总人数]
INTO #PivotTable2 --放到临时表方便查询
FROM (
SELECT [学生编号], [所属班级], [性别] FROM #Student) AS [SourceTable]
PIVOT (COUNT([学生编号]) FOR [性别] IN ([男], [女])) AS [PivotTable]
ORDER BY [总人数] DESC
SELECT [班级],[男生或女生人数],[性别],[总人数]
FROM (
SELECT [班级], [男生人数], [女生人数], [总人数] FROM #PivotTable2) AS [s]
UNPIVOT ([男生或女生人数]FOR [性别] IN ([男生人数],[女生人数])) AS [un_p]

或者将性别和人数合并到一个列当中:
SELECT [班级],[性别] + ': ' + CAST([男生或女生人数] AS NVARCHAR(1)) AS [男生或女生人数],[总人数]
FROM (SELECT [班级], [男生人数], [女生人数], [总人数] FROM #PivotTable2) AS [s]
UNPIVOT ([男生或女生人数] FOR [性别] IN ([男生人数], [女生人数])) AS [un_p]

SQL Server 行列相互转换命令:PIVOT和UNPIVOT使用详解的更多相关文章
- SQL Server中通用数据库角色权限的处理详解
SQL Server中通用数据库角色权限的处理详解 前言 安全性是所有数据库管理系统的一个重要特征.理解安全性问题是理解数据库管理系统安全性机制的前提. 最近和同事在做数据库权限清理的事情,主要是删除 ...
- SQL Server中排名函数row_number,rank,dense_rank,ntile详解
SQL Server中排名函数row_number,rank,dense_rank,ntile详解 从SQL SERVER2005开始,SQL SERVER新增了四个排名函数,分别如下:1.row_n ...
- T-SQL行列相互转换命令:PIVOT和UNPIVOT使用详解
最近在维护一个ERP 做二次开发 ,在查找数据源的时候看到前辈写的SQL ,自己能力有限 ,就在网上找找有关这几个关键字的使用方法.做出随笔以做学习之用 T-SQL语句中,PIVOT命令可以实现数据表 ...
- SQL Server 表的管理_关于完整性约束的详解(案例代码)
SQL Server 表的管理之_关于完整性约束的详解 一.概述: ●约束是SQL Server提供的自动保持数据库完整性的一种方法, 它通过限制字段中数据.记录中数据和表之间的数据来保证数据的完整性 ...
- 转:SQL Server中服务器角色和数据库角色权限详解
当几个用户需要在某个特定的数据库中执行类似的动作时(这里没有相应的Windows用户组),就可以向该数据库中添加一个角色(role).数据库角色指定了可以访问相同数据库对象的一组数据库用户. 数据库角 ...
- sql server 存储过程 output 和return的使用 方法,详解
SQL Server目前正日益成为WindowNT操作系统上面最为重要的一种数据库管理系统,随着 SQL Server2000的推出,微软的这种数据库服务系统真正地实现了在WindowsNT/2000 ...
- SQL Server:排名函数row_number,rank,dense_rank,ntile详解
1.Row_Number函数 row_number函数大家比较熟悉一些,因为它的用途非常的广泛,我们经常在分页与排序中用到它,它的功能就是在每一行中生成一个连续的不重复的序号 例如: select S ...
- PIVOT和UNPIVOT使用详解
一.使用PIVOT实现数据表的列转行 建表语句: DROP TABLE STUDENT; CREATE TABLE STUDENT ( 学生编号 BYTE) NULL , 姓名 BYTE) NULL ...
- SQL Server 2008 R2:error 26 开启远程连接详解
远程连接sql server 2008 数据库,出现下面的错误: <--在与 SQL Server 建立连接时出现与网络相关的或特定于实例的错误. 未找到或无法访问服务器.请验证实例名称是 ...
随机推荐
- 如何测试Oracle并行执行的并行度状况
如何测试Oracle并行执行的并行度状况: 可以通过如下的脚本,来查看要求的并行度,和实际获得的并行度. 脚本来自: http://askdba.org/weblog/forums/topic/que ...
- Ubuntu16.04上用源代码安装ICE
ubuntu16.04上用源代码安装ICE
- [LOJ#2878]. 「JOISC 2014 Day2」邮戳拉力赛[括号序列dp]
题意 题目链接 分析 如果走到了下行车站就一定会在前面的某个车站走回上行车站,可以看成是一对括号. 我们要求的就是 类似 代价最小的括号序列匹配问题,定义 f(i,j) 表示到 i 有 j 个左括号没 ...
- Js_数组操作
用 js有很久了,但都没有深究过js的数组形式.偶尔用用也就是简单的string.split(char).这段时间做的一个项目,用到数组的地方很多,自以为js高手的自己居然无从下手,一下狠心,我学!呵 ...
- python代码实现经典排序算法
排序算法在程序中有至关重要的作用, 不同算法的时间复杂度和空间复杂度都有所区别, 这影响着程序运行的效率和资源占用的情况, 经常对一些算法多加练习, 强化吸收, 可以提高对算法的理解, 进而运用到实践 ...
- jmeter-如何在JDBC Request中添加多条语句执行
1.JDBC Connection Configuration中配置Database URL时在URL后面添加 ?allowMultiQueries=true 2.JDBC Request中添加语句 ...
- IT简历
对很多IT毕业生来说,写简历投简历是必不可少的.一个好的简历已是面试成功的一半. 简历的目的是为了引人注意,争取让HR主动联系你去面试,不可避免的在简历中掺杂着一些水分,但是能争取到面试机会,再与HR ...
- 机器学习初入门02 - Pandas的基本操作
之前的numpy可以说是一个针对矩阵运算的库,这个Pandas可以说是一个实现数据处理的库,Pandas底层的许多函数正是基于numpy实现的 一.Pandas数据读取 1.pandas.read_c ...
- web安全入门课程笔记——网站基础与信息搜集
2-1 网站的基本概念 URL统一资源定位符 这是一个动态页面 ?ID 查询条件 后台数据库最有可能:ACCESS Web容器(web容器是一种服务程序,在服务器一个端口就有一个提供相应服务的程序,而 ...
- JS高级程序设计学习笔记1
javascript产生的原因: 在拨号上网时代,表单数据必须发送到服务器端才能验证输入值得有效性,JavaScript的研发就是为了解决这个问题,以便在客户端就验证输入值的有效性. ECMAScri ...