python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述
以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ 。此网页中的最新、精华下面的内容是由JavaScript动态生成的。审查网页元素与网页源码是不同。
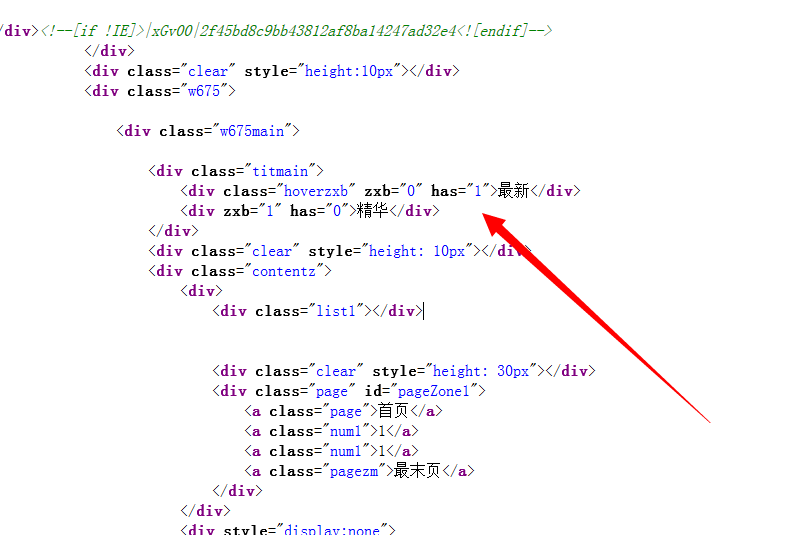
以下是网页源码
以上是审查网页元素
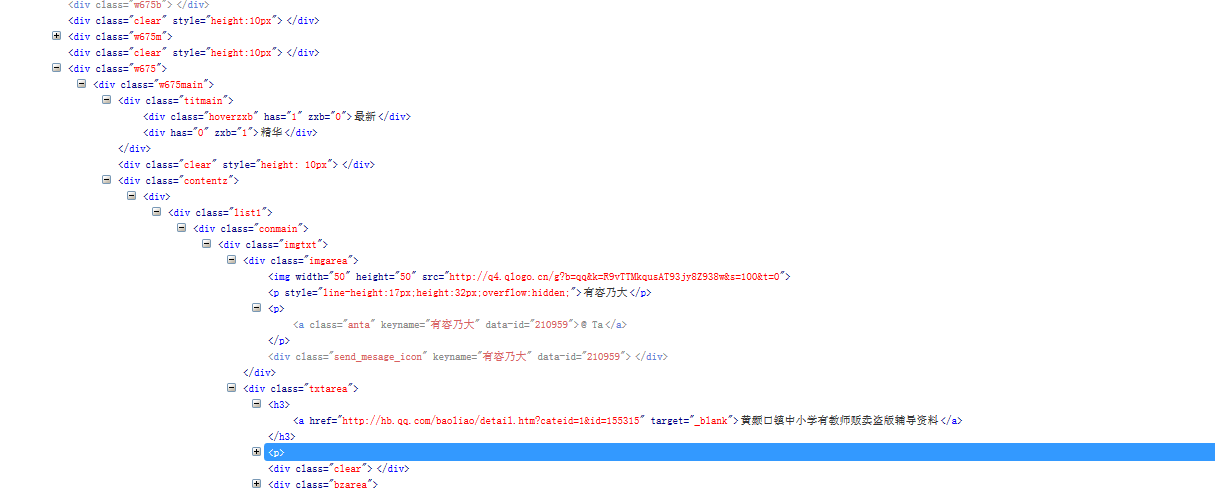
所以此处不能简单的使用正则表达式来获取内容。
以下是完整的获取内容并存储到数据库的思路及源码。
实现思路:
抓取实际访问的动态页面的url – 使用正则表达式获取需要的内容 – 解析内容 – 存储内容
以上部分过程文字解释:
抓取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/report/NewIndexReportsList/cityid/18/num/20/pageno/1?callback=jQuery183019859437816181613_1440723895018&_=1440723895472
正则表达式:
正则表达式的使用有两种思路,可以参考个人有关其简述:python实现简单爬虫以及正则表达式简述
更多的细节介绍可以参考网上资料,搜索关键词: 正则表达式 python
json:
参考网上有关json的介绍,搜索关键词: json python
存储到数据库:
参考网上的使用介绍,搜索关键词: 1,mysql 2,mysql python
源码及注释
注意:使用python的版本是 2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*- #导入python库
import urllib
import urllib2
import re
import MySQLdb
import json #定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content #连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password=""
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB #创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName #数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")" DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully' url="http://baoliao.hb.qq.com/api/report/NewIndexReportsList/cityid/18/num/20/pageno/1?callback=jQuery183019859437816181613_1440723895018&_=1440723895472" #正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"' #实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S) html_need=json.loads(html_jason[0]) print len(html_need)
print len(html_need['data']['list']) table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
python网络爬虫抓取动态网页并将数据存入数据库MySQL的更多相关文章
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- python网络爬虫抓取网站图片
本文介绍两种爬取方式: 1.正则表达式 2.bs4解析Html 以下为正则表达式爬虫,面向对象封装后的代码如下: import urllib.request # 用于下载图片 import os im ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
随机推荐
- SQL Server 用户'NT AUTHORITY\IUSR' 登录失败
今天打开网站时,突然报这个错误,平时都好好的 Cannot open database "JMECC" requested by the login. The login fail ...
- JAVA虚拟机体系结构JAVA虚拟机的生命周期
一个运行时的Java虚拟机实例的天职是:负责运行一个java程序.当启动一个Java程序时,一个虚拟机实例也就诞生了.当该程序关闭退出,这个虚拟机实例也就随之消亡.如果同一台计算机上同时运行三个Jav ...
- 搭建json-server本地接口
这里我们来搭建一下json-server的本地接口,来让我们的网页能够对里面的数据进行增删改查 第一步,安装json-server的全局:Linux和windows在终端或者git中里面输入以下指令, ...
- linux中jdk的安装与配置
一.卸载系统已有的JDK 1.查看已安装的jdk rpm -qa|grep jdk 2.卸载jdk rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1. ...
- Linux CPU实时监控工具
注:ubuntu需要安装sysstat: sudo apt install sysstat [root@testDb ~]# mpstat 1 10 ---显示操作系统内核版本 以及硬件配置 ...
- 计算机网络 之 TCP和UDP的端口号解析
前言:今天了解一下tcp和udp报文的端口.发现一直以来都只是知道端口用于区分同一IP的服务器的不同服务,已经端口的大小.在查找traceroute的资料的时候,才了解到一些之前没注意到的东西. (一 ...
- 把 Elasticsearch 当数据库使:聚合后排序
使用 https://github.com/taowen/es-monitor 可以用 SQL 进行 elasticsearch 的查询.有的时候分桶聚合之后会产生很多的桶,我们只对其中部分的桶关心. ...
- Android:异步处理之Handler、Looper、MessageQueue之间的恩怨(三)
前言 如果你在阅读本文之前,你不知道Handler在Android中为何物,我建议你先看看本系列的第一篇博文<Android:异步处理之Handler+Thread的应用(一)>:我们都知 ...
- zend studio 9.0.2 破解-注册-汉化流程
1.运行 ZendStudio-9.0.2.msi :注意安装后不要启动: 附其下载地址:下载9.0.2版本的Zend StudioZend Studio 9.0.2下载地址:http://www.g ...
- 安装的Android SDK下无doc文件夹问题 以及关联Android帮助文档和查看文档 以及查看在线文档
参考连接:https://blog.csdn.net/fangzicheng/article/details/78344521 https://jingyan.baidu.com/article/29 ...