[机器学习&数据挖掘]SVM---核函数
1、核函数概述:
核函数通俗的来说是通过一个函数将向量的低维空间映射到一个高维空间,从而将低维空间的非线性问题转换为高维空间的线性问题来求解,从而再利用之前说的一系列线性支持向量机,常用的核函数如下:
多项式核函数:
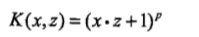
高斯核函数:
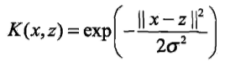
比如硬间隔种的目标函数为:

而核函数替换后的目标函数为:
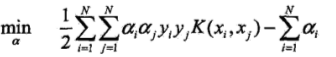
从这个两个目标函数找共同点,其实会发现核函数是作用在特征向量上,开始的目标函数一次计算是利用了两个特征向量,而接下来的核函数是对两个特征向量做函数运算,假如将核函数利用在一次运算利用三个特征向量的计算,这时核函数就会对这三个特征向量做核函数,其实就是一个替换的问题,将两个特征向量点积运算换成一个核函数的值,仅此而已。
2、SMO算法概述:
因此接下来的处理还是求解拉格朗日乘子、w、b,因此引入SMO(序列最小最优化算法)
首先SMO算法要解决的对偶问题如下:

SMO算法是一种启发式算法,基本思路:如果所有变量的解都满足此最优化问题的KKT条件,那么这个最优化的问题的解就得到了,SMO算法其实就是在求解拉格朗日算子。SMO算法子问题:先选择两个变量,然后固定其他变量,针对此两个变量构建二次规划问题,子问题由两个变量,一个是违反KKT条件最严重的变量,另一个由约束条件自动确定,然后对此子问题求解,当此两个变量都满足KKT条件,则子问题求解完成。SMO算法就是将问题不断的分解为此子问题,直到所有的变量的解都满足此问题的KKT条件,从而结束算法
通过以上的对偶问题可以将子问题写成(此处假定选择两个变量alpha1、alpha2):
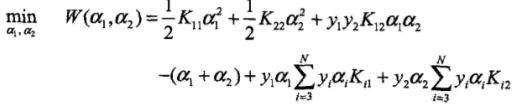

注意:此子问题的目标函数是从上面的对偶问题得来,在推导的过程中会发现有一些项没有,是因为这个时候只有alpha1和alpha2是变量,其他的都看作固定的值,就类似求min(f(x))和min(f(x)+C)的解x是一样的(C为常数)
3、alpha计算公式:
接下来几个公式用于每次计算:
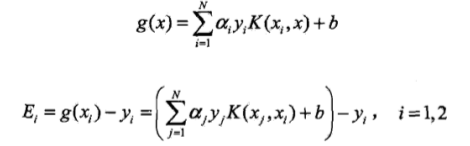
注:Ei是g(x)对xi的预测值对yi的值之差
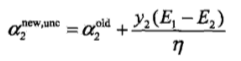
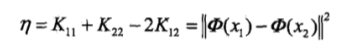
此计算的是alpha2未经过处理的值,因为各个alpha都由一个范围的,具体如下分段函数:

通过alpha2可以求得alpha1的新值如下:
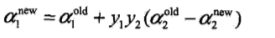
4、变量选择:
(1)首先面临的是第一个变量的选择,在SMO算法的概述中我也介绍过,就是最不满足此问题的KKT条件,KKT条件为何看如下(KKT是相对于每个样本点来说的即(xi,yi)):
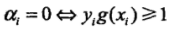
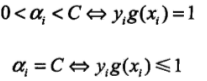 g(xi)如上述的式子
g(xi)如上述的式子
第一个变量的选择是SMO的外层循环,在检验过程中,首先遍历所有满足0<alpha<C条件的样本点,即在间隔边界上的支持向量点,检验其是否满足KKT条件,如果都满足,则遍历整个训练集是否满足KKT条件,选择最不满足的点为第一个变量。
(2)其次是第二个变量的选择:第二个变量的选择是SMO的内层循环,首先假定已经选定了第一个变量,第二个变量的选择是希望能使alpha2有足够大的变化,一种简单的做法是其对应的|E1-E2|最大。在特殊的情况下,通过以上方法不能使目标函数有足够的下降,则采用向下启发规则继续选择alpha2,遍历所有的间隔边界上的支持向量点,依次将其作为alpha2试用,直到目标函数有足够的下降,若找不到则便利整个训练集;若仍找不到,则放弃alpha1,通过外层循环继续选择另外的alpha1.
(3)计算b和差值Ei
因为在每次完成两个变量的优化之后,都需要重新计算b和Ei,主要是Ei的计算需要用的b,公式如下:


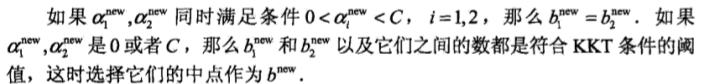
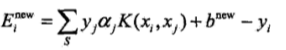
[机器学习&数据挖掘]SVM---核函数的更多相关文章
- 【机器学习】SVM核函数
知识预备 1. 回顾:logistic回归出发,引出了SVM,即支持向量机[续]. 2. Mercer定理:如果函数K是上的映射(也就是从两个n维向量映射到实数域).那么如果K是一个有效核函数(也称 ...
- 机器学习:SVM(核函数、高斯核函数RBF)
一.核函数(Kernel Function) 1)格式 K(x, y):表示样本 x 和 y,添加多项式特征得到新的样本 x'.y',K(x, y) 就是返回新的样本经过计算得到的值: 在 SVM 类 ...
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- 常用的机器学习&数据挖掘知识点【转】
转自: [基础]常用的机器学习&数据挖掘知识点 Basis(基础): MSE(Mean Square Error 均方误差),LMS(LeastMean Square 最小均方),LSM(Le ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
- 常见的机器学习&数据挖掘知识点
原文:http://blog.csdn.net/heyongluoyao8/article/details/47840255 常见的机器学习&数据挖掘知识点 转载请说明出处 Basis(基础) ...
- 机器学习四 SVM
目录 引言 SVM 线性可分SVM 线性不可分SVM Hinge Loss 非线性SVM 核函数 总结 参考文献 引言 在深度神经网终(Deep Neural Network, DNN) 大热之前, ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- [resource-]Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
reference: http://www.52nlp.cn/python-%e7%bd%91%e9%a1%b5%e7%88%ac%e8%99%ab-%e6%96%87%e6%9c%ac%e5%a4% ...
随机推荐
- 利用十字链表压缩稀疏矩阵(c++)-- 数据结构
题目: 7-1 稀疏矩阵 (30 分) 如果一个矩阵中,0元素占据了矩阵的大部分,那么这个矩阵称为“稀疏矩阵”.对于稀疏矩阵,传统的二维数组存储方式,会使用大量的内存来存储0,从而浪费大量内存.为 ...
- PAT甲题题解-1121. Damn Single (25)-水题
博主欢迎转载,但请给出本文链接,我尊重你,你尊重我,谢谢~http://www.cnblogs.com/chenxiwenruo/p/6789787.html特别不喜欢那些随便转载别人的原创文章又不给 ...
- Linux内核分析——第八周学习笔记
实验作业:进程调度时机跟踪分析进程调度与进程切换的过程 20135313吴子怡.北京电子科技学院 [第一部分]理解Linux系统中进程调度的时机 1.Linux的调度程序是一个叫schedule()的 ...
- 20135327郭皓--Linux内核分析第四周 扒开系统调用的三层皮(上)
Linux内核分析第四周 扒开系统调用的三层皮(上) 郭皓 原创作品转载请注明出处 <Linux内核分析>MOOC课程 http://mooc.study.163.com/course/U ...
- “人向猿进阶”之软件工程第三课----WORDCOUNT.EXE统计程序
---恢复内容开始--- WC项目要求 这个项目要求写一个命令行程序,模仿已有的wc.exe的功能,并加以扩充,给出某程序设计源语言文件的字符数.单词数和行数.给实现一个统计程序,它能正确统计程序文件 ...
- Spring源码学习:DefaultAopProxyFactory
/* * Copyright 2002-2015 the original author or authors. * * Licensed under the Apache License, Vers ...
- Activiti源码学习:ExecutionListener与TaskListener的区别
/** Callback interface to be notified of execution events like starting a process instance, * ending ...
- [转帖][Bash Shell] Shell学习笔记
[Bash Shell] Shell学习笔记 http://www.cnblogs.com/maybe2030/p/5022595.html 阅读目录 编译型语言 解释型语言 5.1 作为可执行程序 ...
- BZOJ5462 APIO2018新家(线段树+堆)
一个显然的做法是二分答案后转化为查询区间颜色数,可持久化线段树记录每个位置上一个同色位置,离线后set+树状数组套线段树维护.这样是三个log的. 注意到我们要知道的其实只是是否所有颜色都在该区间出现 ...
- 「TJOI / HEOI2016」字符串
「TJOI / HEOI2016」字符串 题目描述 佳媛姐姐过生日的时候,她的小伙伴从某东上买了一个生日礼物.生日礼物放在一个神奇的箱子中.箱子外边写了一个长为 \(n\) 的字符串 \(s\),和 ...