关于sortedlist 中值的添加,删除,索引测试.
SortedList 类代表了一系列按照键来排序的键/值对,这些键值对可以通过键和索引来访问。
排序列表是数组和哈希表的组合。它包含一个可使用键或索引访问各项的列表。如果您使用索引访问各项,则它是一个动态数组(ArrayList),如果您使用键访问各项,则它是一个哈希表(Hashtable)。集合中的各项总是按键值排序。
总结:用于坐标删除删除的是排序好的队列.跟删除数组差不多.
在项目两个列进行合并时可以使用这种方式,时间当键, 码当值,自动排序打印.但不能用sortedlist 因为键是唯一的,不能重复.
项目要做两个txt内容比对.比如 a b 两个txt
本来有这么个设想,
读取a txt 文件 一条数据,开着文件流不关闭.
读取b txt文件内容,文件流开着,每次读取比如十个数.达到20数后清空前十个,保留后十个作为继续让a的数据比对,因为数据相同的位置相差不多.比如a文件有个值100,假如b文件也有这个100的话,那b文件的100这个值在这个文件中的位置跟A中100的位置差不多,项目是两个读码器同时读一条线的数据,作为相互补充,上道读码器和下道读码器中间隔着一米左右,最终所以想优化成这个效果.
使用soredlist 删除读取的btxt slist时,比如删除5个
用到
for (int i = 0; i < 5; i++)
{
//把即将删除的添加到另一个队列.作为即将保存的
differlist.Add(n_readlist.GetKey(i), n_readlist.GetByIndex(i));
//开始删除
n_readlist.RemoveAt(i);
}
1:错误1:上边这种方法是不适合这种项目需求的.
因为add之后,里边的值是按照序列排序了,位置变化了.所以本来想删除第一个加进来的,可能把别的值删除掉了
2:错误2: 上边的循环写法错误,因为每次删除之后,循序上移,原先的1位置的值移到了0位置.循环到第二次的时候删除的值实际是 最开始的第三个值,而第二个值被漏掉了.
如图:循环到第二次时, 实际要求删除第一个值.如图删除前

删除后第一个值还存在,第二个值没了.
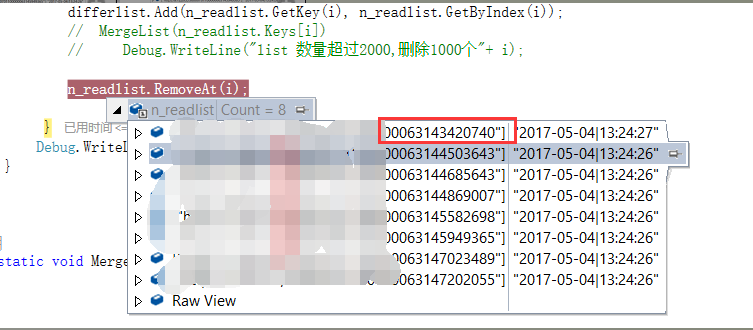
而下边是字典dictionary 加入的数值之后的数据结构,两列中间用逗号隔开,起边多了一项排序数值,而且数据顺序没有变化.

关于sortedlist 中值的添加,删除,索引测试.的更多相关文章
- mysql添加删除索引,查看某个表的建表语句
查看某个表的建表语句 :show create table data_statdata; drop index ts on data_statdata; 索引是加速查询的主要手段,特别对于涉及多个表的 ...
- Mysql使用Java UUID作为唯一值时使用前缀索引测试
Mysql可以使用字符串前缀 作为索引 以节约空间. 下面我们以 Java的UUID 生成的 32位(移除UUID中的 中划线)字符串 来做一下 测试. 表结构: CREATE TABLE `test ...
- mysql建立索引 删除索引
建立索引 1.添加PRIMARY KEY(主键索引) mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) 2.添加UNIQUE ...
- 动态添加删除网卡 - 每天5分钟玩转 OpenStack(156)
这是 OpenStack 实施经验分享系列的第 6 篇. 在项目实施过程中,经常会有添加删除网卡的需求.比如一个运行数据库的 instance,初始只有一个网卡,数据库服务和备份共用这块网卡,后来为提 ...
- jquery中找到元素在数组中位置,添加或者删除元素的新方法
一:查找元素在数组中的位置 jQuery.inArray()函数用于在数组中搜索指定的值,并返回其索引值.如果数组中不存在该值,则返回 -1. jQuery.inArray( value, array ...
- MySQL 添加索引,删除索引及其用法
一.索引的作用 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重. 在数据 ...
- MySQL添加、删除索引
1.索引类型 UNIQUE(唯一索引):不可以出现相同的值,可以有NULL值: INDEX(普通索引):允许出现相同的索引内容: PROMARY KEY(主键索引):不允许出现相同的值: fullte ...
- 分享知识-快乐自己:MySQL中的约束,添加约束,删除约束,以及一些其他修饰
创建数据库: CREATE DATABASES 数据库名: 选择数据库: USE 数据库名: 删除数据库: DROP DATAVBASE 数据库名: 创建表: CREATE TABLE IF NOT ...
- phoenix中添加二级索引
Phoenix创建Hbase二级索引 官方文档 1. 配置Hbase支持Phoenix创建二级索引 1. 添加如下配置到Hbase的Hregionserver节点的hbase-site.xml ...
随机推荐
- 最干净,最便捷的卸载Mysql
由于没有卸干净Mysql,用一下就崩溃了,使用这个步骤,都不用重装系统 1,停止Mysql服务,卸载MySQL 2,删除安装目录及数据存放目录 注: 默认安装路径:C:\Program Files\M ...
- Java复习 之流
在Java程序中 对于数据的输入/输出操作以“流”方式进行:提供了各种各样的流类,用以获取各种不同的种类的数据,程序中通过标准的方法输入或输出数据 Inputstream 例子1: 但是中文会乱码 应 ...
- Structs复习 Action传递参数
Structs传递参数通常有三种方式 下面我来一个个介绍 1.属性 Jar包 web.xml <?xml version="1.0" encoding="UTF-8 ...
- SQL--结构化的查询语言
SQL--结构化的查询语言T-SQL:Transact-SQL (SQL的增强版) 逻辑运算符 and && or || not ! 关系运算符 等于 = 不等于<>或!= ...
- ESET官方下载地址
官方远程下载 ESET NOD32 Antivirus(32位) ESET NOD32 Antivirus(64位) ESET Smart Security(32位) ESET Smart Secur ...
- platform 系统是windows还是liunx
import platform # 判断当前代码运行的系统是windows还是liunx print(platform.architecture()) print(platform.platform( ...
- spark 学习_rdd常用操作
[spark API 函数讲解 详细 ]https://www.iteblog.com/archives/1399#reduceByKey [重要API接口,全面 ] http://spark.apa ...
- 构建缓存gradle
结合Kotlin使用Gradle build cache 宛丘之上兮 关注 2018.03.11 00:21* 字数 1177 阅读 505评论 5喜欢 4 在2017年4月,Gradle发布了bui ...
- scrapy爬虫的编写步骤
scrapy的步骤: a.编写item,爬取的各个属性 b.编写spider,name 要和 scrapy crawl xxspider一致,里面编写parse的信息,就是xpath获取item的各个 ...
- VSC KeyNote
[VSC KeyNote] 1.前后跳转. Alt + LeftArrow, Alt + RightArrow 2.缩进问题. vsc默认缩进为4,但js代码里缩进依旧是2. 因为vscode默认启用 ...