[Spark RDD_1] RDD 基本概念
0. 说明
RDD 概述 && 创建 RDD 的方式 && RDD 编程 API(Transformation 和 Action Operations) && RDD 的依赖关系
1. RDD 概述
Spark 围绕弹性分布式数据集(RDD)的概念展开,RDD 是可以并行操作的容错的容错集合。
resilient distributed dataset,弹性分布式数据集。
不可变集合,可以进行并行操作的分区化数据集合。
该类包含了 RDD 常见操作,比如 map、filter、persist 等。
对于 key-value 的 RDD,会自动转换成(隐式转换)PairRDDFunction,该类提供了所有的 ByKey 操作。
内部,每个 RDD 主要含有 5 个主要属性:
- 分区列表(轻量级数据集合,没有实际数据)
- 计算每个切片的计算函数
- 和其他RDD的依赖列表
- 针对 K-V 类型 RDD,还有一个分区类(可选)
- 计算每个切片的首选位置列表(可选)
2. 创建 RDD 的方式
创建 RDD 有两种方法
【方法一】
并行化 驱动程序中的现有集合。
例子如下

【方法二】
引用外部存储系统中的数据集,例如共享文件系统,HDFS,HBase 或提供 Hadoop InputFormat 的任何数据源。
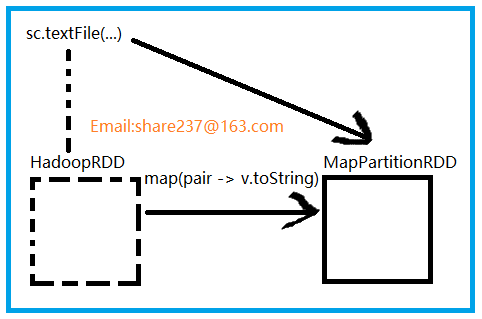
textFile() 方法最初创建的是 HadoopRDD,HadoopRDD 提供了读取 HDFS 文件核心功能。
sc.textFile()
产生了两个 RDD
HadoopRDD -> MapPartitionRDD
3. RDD 编程 API(Transformation 和 Action Operations)
【变换 Transformation】
返回值为新的 RDD
map
flatMap
filter()
reduceByKey()
【动作 Actions】
返回值为具体的值
collect()
save()
reduce()
count()
4. RDD 的依赖关系
【依赖】
RDD 的依赖是 子 RDD 上的每个分区和父 RDD 分区数量上的对应关系
Dependency
|----ShuffleDependency (宽依赖)
|----NarrowDependency (窄依赖:子 RDD 的每个分区依赖少量的父 RDD 分区)
|-----One2OneDependency (一对一依赖)
|-----RangeDependency(范围依赖)
|-----PruneDependency(Prune 依赖)
【说明】
构造 RDD 时使用的是 One2OneDependency
[Spark RDD_1] RDD 基本概念的更多相关文章
- 【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Spark RDD基本概念与基本用法
1. 什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合.RDD具 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- Spark中的一些概念
最近工作用到Spark,这里记一些自己接触到的Spark基本概念和知识. 本文链接:https://www.cnblogs.com/hhelibeb/p/10288915.html 名词 RDD:在高 ...
- spark中RDD的转化操作和行动操作
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- Spark之RDD的定义及五大特性
RDD是分布式内存的一个抽象概念,是一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,能横跨集群所有节点并行计算,是一种基于工作集的应用抽象. RDD底层存储原理:其数据分布存储于多台机器上 ...
随机推荐
- mysql 查找在另一张表不存在的数据
有两个表Phone_book, Call: Phone_book +----+------+--------------+ | id | name | phone_number | +----+--- ...
- 制作openstack使用的Ubuntu镜像
一.环境准备 OS:Ubuntu-14.04 制作镜像版本:Ubuntu-14.04.4-server-amd64.iso 查看是否支持虚拟化(有输出代表支持,否则在BIOS页面中设置即可): egr ...
- 在使用Git提交代码的时候犯了个低级错误
今天在使用git提交代码的时候,犯了个很低级的错误,按照一切流程当我add并commit提交代码,最后使用push到远程仓库, 接下来奇怪的事情发生了,push之后,查看远程仓库代码并没有发现提交记录 ...
- HDU 1535 Invitation Cards(逆向思维+邻接表+优先队列的Dijkstra算法)
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=1535 Problem Description In the age of television, n ...
- webpack3新特性简介
6月20号webpack推出了3.0版本,官方也发布了公告.根据公告介绍,webpack团队将未来版本的改动聚焦在社区提出的功能需求,同时将保持一个快速.稳定的发布节奏.本文主要依据公告内容,简单介绍 ...
- Extjs4处理后台json数据中日期和时间的方法
当ASP.NET后台使用JavaScriptSerializer这个组件将对象序列化为json,或者使用ScriptMethod特性的json [ScriptMethod(ResponseFormat ...
- JOffice中的权限管理--功能粒度的权限管理配置
JOffice中的权限管理是基于角色的管理策略,采用Spring Security2的配置方式,同时能够结合EXT3来进行整个系统的权限管理,通过使用配置文件,进行整个系统的功能集中管理,包括系统左边 ...
- 【ibatis】IBatis的动态SQL的写法
Ⅰ .动态SQL的写法 开始 <dynamic 条件成立时前面要加的字符串 prepend ="字符串"> prepend="字符串" 判断条件的对 ...
- Java 支付宝支付,退款,单笔转账到支付宝账户(单笔转账到支付宝账户)
上次分享了支付宝订单退款的代码,今天分享一下支付宝转账的操作. 现在是有一个余额提现的功能,本来是打算做提现到银行卡的,但是客户嫌麻烦不想注册银联的开放平台账户,就说先提现到支付宝就行,二期再做银行 ...
- 大菲波数(Fibonacci)java大数(hdu1715)
大菲波数 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submissio ...