在 R 中估计 GARCH 参数存在的问题(续)
在 R 中估计 GARCH 参数存在的问题(续)
本文承接《在 R 中估计 GARCH 参数存在的问题》
在之前的博客《在 R 中估计 GARCH 参数存在的问题》中,Curtis Miller 讨论了 fGarch 包和 tseries 包估计 GARCH(1, 1) 模型参数的稳定性问题,结果不容乐观。本文承接之前的博客,继续讨论估计参数的稳定性,这次使用的是前文中提到,但没有详尽测试的 rugarch 包。
rugarch 包的使用
rugarch 包中负责估计 GARCH 模型参数的最主要函数是 ugarchfit,不过在调用该函数值前要用函数 ugarchspec 创建一个特殊对象,用来固定 GARCH 模型的阶数。
srs = ...
garch_mod = ugarchspec(
variance.model = list(
garchOrder = c(1, 1)),
mean.model = list(
armaOrder = c(0, 0),
include.mean = FALSE))
g <- ugarchfit(spec = garch_mod, data = srs)
需要注意的是 g 是一个 S4 类。
简单实验
首先用 1000 个模拟样本,
library(rugarch)
library(ggplot2)
library(fGarch)
set.seed(110117)
x <- garchSim(
garchSpec(
model = list(
"alpha" = 0.2, "beta" = 0.2, "omega" = 0.2)),
n.start = 1000,
n = 1000)
plot(x)

garch_spec = ugarchspec(
variance.model = list(garchOrder = c(1, 1)),
mean.model = list(
armaOrder = c(0, 0), include.mean = FALSE))
g_all <- ugarchfit(
spec = garch_spec, data = x)
g_50p <- ugarchfit(
spec = garch_spec, data = x[1:500])
g_20p <- ugarchfit(
spec = garch_spec, data = x[1:200])
结果同样不容乐观,
coef(g_all)
# omega alpha1 beta1
# 2.473776e-04 9.738059e-05 9.989026e-01
coef(g_50p)
# omega alpha1 beta1
# 2.312677e-04 4.453120e-10 9.989998e-01
coef(g_20p)
# omega alpha1 beta1
# 0.03370291 0.09823614 0.79988068
再用 10000 个模拟样本试试,如果使用日线级别的数据的话,这相当于 40 年长度的数据量,
set.seed(110117)
x <- garchSim(
garchSpec(
model = list(
"alpha" = 0.2, "beta" = 0.2, "omega" = 0.2)),
n.start = 1000, n = 10000)
plot(x)
g_all <- ugarchfit(
spec = garch_spec, data = x)
g_50p <- ugarchfit(
spec = garch_spec, data = x[1:5000])
g_20p <- ugarchfit(
spec = garch_spec, data = x[1:2000])
coef(g_all)
# omega alpha1 beta1
# 0.1955762 0.1924522 0.1967614
coef(g_50p)
# omega alpha1 beta1
# 0.2003755 0.1919633 0.1650453
coef(g_20p)
# omega alpha1 beta1
# 1.368689e-03 6.757177e-09 9.951920e-01
看来数据量极端大的时候,估计才可能是合理的、稳定的。
rugarch 参数估计的行为
首先使用 1000 个模拟样本做连续估计,样本数从 500 升至 1000。
library(doParallel)
cl <- makeCluster(detectCores() - 1)
registerDoParallel(cl)
set.seed(110117)
x <- garchSim(
garchSpec(
model = list(alpha = 0.2, beta = 0.2, omega = 0.2)),
n.start = 1000, n = 1000)
params <- foreach(
t = 500:1000,
.combine = rbind,
.packages = c("rugarch")) %dopar%
{
getFitDataRugarch(x[1:t])
}
rownames(params) <- 500:1000
params_df <- as.data.frame(params)
params_df$t <- as.numeric(rownames(params))
ggplot(params_df) +
geom_line(
aes(x = t, y = beta1)) +
geom_hline(
yintercept = 0.2, color = "blue") +
geom_ribbon(
aes(x = t,
ymin = beta1 - 2 * beta1.se,
ymax = beta1 + 2 * beta1.se),
color = "grey", alpha = 0.5) +
ylab(expression(hat(beta))) +
scale_y_continuous(
breaks = c(0, 0.2, 0.25, 0.5, 1)) +
coord_cartesian(ylim = c(0, 1))
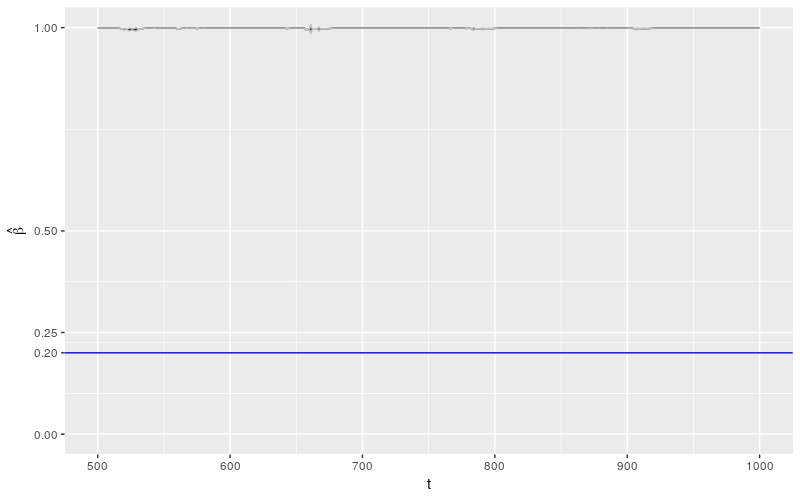
几乎所有关于 \(\beta\) 的估计都非常肯定的被认为是 1!这个结果相较于 fGarch 包来说,更加糟糕。
让我们看看其他参数的行为。
library(reshape2)
library(plyr)
library(dplyr)
param_reshape <- function(p)
{
p <- as.data.frame(p)
p$t <- as.integer(rownames(p))
pnew <- melt(p, id.vars = "t", variable.name = "parameter")
pnew$parameter <- as.character(pnew$parameter)
pnew.se <- pnew[grepl("*.se", pnew$parameter), ]
pnew.se$parameter <- sub(".se", "", pnew.se$parameter)
names(pnew.se)[3] <- "se"
pnew <- pnew[!grepl("*.se", pnew$parameter), ]
return(
join(
pnew, pnew.se,
by = c("t", "parameter"),
type = "inner"))
}
ggp <- ggplot(
param_reshape(params),
aes(x = t, y = value)) +
geom_line() +
geom_ribbon(
aes(ymin = value - 2 * se,
ymax = value + 2 * se),
color = "grey",
alpha = 0.5) +
geom_hline(yintercept = 0.2, color = "blue") +
scale_y_continuous(
breaks = c(0, 0.2, 0.25, 0.5, 0.75, 1)) +
coord_cartesian(ylim = c(0, 1)) +
facet_grid(. ~ parameter)
print(ggp + ggtitle("solnp Optimization"))

这种现象不仅限于 \(\beta\),\(\omega\) 和 \(\alpha\) 也表现出极端不良行为。
极端大样本
下面将样本总数扩充至 10000,连续估计的样本数从 5000 升至 10000,情况有会怎么样?
set.seed(110117)
x <- garchSim(
garchSpec(
model = list(alpha = 0.2, beta = 0.2, omega = 0.2)),
n.start = 1000, n = 10000)
params10k <- foreach(
t = seq(5000, 10000, 100),
.combine = rbind,
.packages = c("rugarch")) %dopar%
{
getFitDataRugarch(x[1:t])
}
rownames(params10k) <- seq(5000, 10000, 100)
params10k_df <- as.data.frame(params10k)
params10k_df$t <- as.numeric(rownames(params10k))
ggplot(params10k_df) +
geom_line(
aes(x = t, y = beta1)) +
geom_hline(
yintercept = 0.2, color = "blue") +
geom_ribbon(
aes(x = t,
ymin = beta1 - 2 * beta1.se,
ymax = beta1 + 2 * beta1.se),
color = "grey", alpha = 0.5) +
ylab(expression(hat(beta))) +
scale_y_continuous(
breaks = c(0, 0.2, 0.25, 0.5, 1)) +
coord_cartesian(ylim = c(0, 1))

结果堪称完美!之前的猜测是对的,样本要极端大才能保证估计的质量。
其他参数的行为。
ggp10k <- ggplot(
param_reshape(params10k),
aes(x = t, y = value)) +
geom_line() +
geom_ribbon(
aes(ymin = value - 2 * se,
ymax = value + 2 * se),
color = "grey",
alpha = 0.5) +
geom_hline(yintercept = 0.2, color = "blue") +
scale_y_continuous(
breaks = c(0, 0.2, 0.25, 0.5, 0.75, 1)) +
coord_cartesian(ylim = c(0, 1)) +
facet_grid(. ~ parameter)
print(ggp10k + ggtitle("solnp Optimization"))
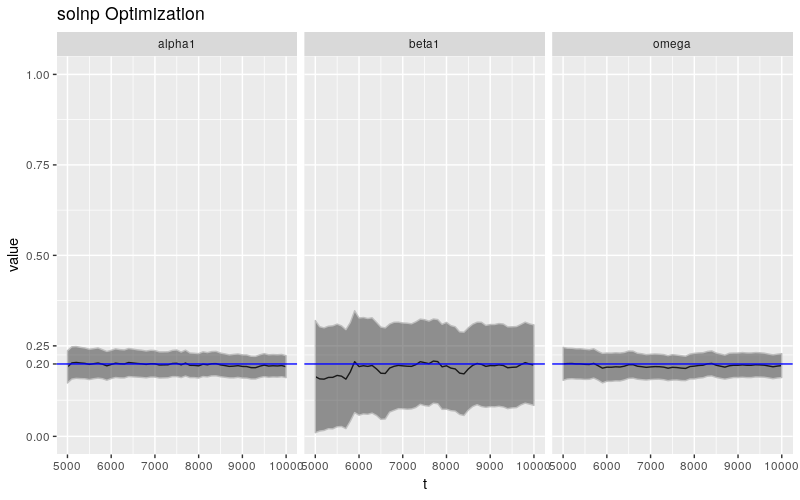
相较于 \(\beta\),\(\omega\) 和 \(\alpha\) 的估计值更加稳定,这一节论和之前文章中的结论大体一致,参数估计的不稳定性集中体现在 \(\beta\) 身上。
结论
在一般大小样本量的情况下,rugarch 和 fGarch 的表现都不好,即使改变函数的最优化算法(相关代码未贴出)也于事无补。不过当样本量极端大时,rugarch 的稳定性大幅改善,这似乎印证了机器学习中的一个常见观点,即大样本 + 简单算法胜过小样本 + 复杂算法。
为了解决非大样本情况下估计的稳定性问题,有必要找到一种 bootstrap 方法,人为扩充现实问题中有限的样本量;或者借鉴机器学习的思路,对参数施加正则化约束。
在 R 中估计 GARCH 参数存在的问题(续)的更多相关文章
- 在 R 中估计 GARCH 参数存在的问题(基于 rugarch 包)
目录 在 R 中估计 GARCH 参数存在的问题(基于 rugarch 包) 导论 rugarch 简介 指定一个 \(\text{GARCH}(1, 1)\) 模型 模拟一个 GARCH 过程 拟合 ...
- 在 R 中估计 GARCH 参数存在的问题
目录 在 R 中估计 GARCH 参数存在的问题 GARCH 模型基础 估计 GARCH 参数 fGarch 参数估计的行为 结论 译后记 在 R 中估计 GARCH 参数存在的问题 本文翻译自< ...
- R语言命令行参数
批量画图任务中,需要在R中传入若干参数,之前对做法是在perl中每一个任务建立一个Rscript,这种方式超级不cool,在群里学习到R的@ARGV调用方式,差不多能够达到批量任务的要求: a ...
- 使用RStudio调试(debug)基础学习(二)和fGarch包中的garchFit函数估计GARCH模型的原理和源码
一.garchFit函数的参数--------------------------------------------- algorithm a string parameter that deter ...
- R中的par()函数的参数
把R中par()函数的主要参数整理了一下(另外本来还整理了每个参数的帮助文档中文解释,但是太长,就分类之后,整理为图表,excel不便放上来,就放了这些表的截图)
- shell中调用R语言并传入参数的两种步骤
shell中调用R语言并传入参数的两种方法 第一种: Rscript myscript.R R脚本的输出 第二种: R CMD BATCH myscript.R # Check the output ...
- R中的参数传递函数:commandArgs(),getopt().
1.commandArgs(),是R自带的参数传递函数,属于位置参数. ##test.R args=commandArgs(T) print (args[1])##第一个外部参数 print (arg ...
- 简单介绍一下R中的几种统计分布及常用模型
统计学上分布有很多,在R中基本都有描述.因能力有限,我们就挑选几个常用的.比较重要的简单介绍一下每种分布的定义,公式,以及在R中的展示. 统计分布每一种分布有四个函数:d――density(密度函数) ...
- R中的统计模型
R中的统计模型 这一部分假定读者已经对统计方法,特别是回归分析和方差分析有一定的了解.后面我们还会假定读者对广义线性模型和非线性模型也有所了解.R已经很好地定义了统计模型拟合中的一些前提条件,因此我们 ...
随机推荐
- ArcGIS JavaScript API 4.x中热度图渲染的使用注意事项
要使用ArcGIS JavaScript API 4.x的热度图渲染器来渲染要素图层,需要注意几点前提条件: 1.需要使用ArcGIS Server 10.6.1或更高版本发布GIS服务. 2.只支持 ...
- terminate called after throwing an instance of 'std::bad_alloc'
这个错误,网上搜索到的资料大多是指向内存不足或者内存碎片问题,如下链接 http://bbs.csdn.net/topics/330000462 http://stackoverflow.com/qu ...
- python基础一数据类型之字符串
摘要: python基础一中有字符串,所以这篇主要讲字符串. 一,字符串的注释 二,字符串的索引与切片 三,字符串的方法 一,字符串的注释 单引号 双引号 三引号都可以用户定义字符串.三引号不仅可以定 ...
- Oracle EBS AR 其他API
DECLARE L_CR_ID NUMBER; L_ATTRIBUTE_REC AR_RECEIPT_API_PUB.ATTRIBUTE_REC_TYPE; L_GLOBAL_ATT_REC AR_R ...
- 初识java内存区域
目录: 1.运行时数据区域 2.对象的创建 3.对象的内存布局 4.对象的访问定位 一.运行时数据区域 基本的java虚拟机运行时数据区如下图: 下面我们就来逐个认识这几个运行时的数据区域 1.程序计 ...
- sha256sum和 md5sum 命令之间的区别
Short answer: For verifying ISOs, there is no practical difference, use whichever you want, as long ...
- Spark 集群搭建
0. 说明 Spark 集群搭建 [集群规划] 服务器主机名 ip 节点配置 s101 192.168.23.101 Master s102 192.168.23.102 Worker s103 19 ...
- FinalShell使用---Xshell的良心国产软件
最近发现了一款同类产品FinalShell,还是一块良心国货.初步体验了一下,确实是良心之作.且免费(通用版),支持国货. FinalShell是一体化的的服务器,网络管理软件,不仅是ssh客户端,还 ...
- django中url 和 path 的区别
django中 url 和 path 都是配置路径,有什么不同? django.urls path django.conf.urls url path 与 url 是两个不同的模块,效果都是响应返回 ...
- 关于在Win10的Windows功能中没有IE11的问题
大概是用Win7的时候把IE关掉了,升级Win10之后就发现IE不见了,在Windows功能里面也没有:最近因为某些原因需要用到IE,还是用的虚拟机. 网上找到的方法普遍是执行命令:FORFILES ...