《MySQL技术内幕 InnoDB存储引擎 》学习笔记
第1章 MySQL体系结构和存储引擎
1.3 MySQL存储引擎
数据库和文件系统最大的区别在于:数据库是支持事务的
InnoDB存储引擎:
MySQL5.5.8之后默认的存储引擎,主要面向OLTP(联机事务处理,面向基本的、日常的事务处理)
支持事务,支持外键、支持行锁(有的情况下也会锁住整个表)、非锁定读(默认读取操作不会产生锁)
通过使用MVCC来获取高并发性,并且实现sql标准的4种隔离级别,默认为可重复读级别
使用一种被称成next-key locking的策略来避免幻读(phantom)现象
还提供了插入缓存(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)等高性能技术。
表数据采用聚集方式,每张表的存储都按主键的顺序进行存放。
MyISAM存储引擎:
不支持事务、支持全文索引,表锁设计,主要面向一些OLAP(联机分析处理,数据仓库的主要应用)。
它的缓冲池只缓冲索引文件,而不缓冲数据文件.
该存储引擎表由MYD和MYI组成,MYD用来存放数据文件,MYI用来存放索引文件.
NDB:
是一个集群存储引擎,其特点是数据全部放在内存中。
因此主键查找速度极快,并通过添加NDB数据库存储节点可以线性提高数据库性能,是高可用,高性能的集群系统。
Memory:
将表中的数据存放在内存中,如果数据库重启或发生崩溃,表中的数据都将消失。
它非常适合存储临时数据的临时表.默认采用哈希索引。
只支持表锁,并发性较差。
第5章 索引与算法
5.1 InnoDB存储引擎索引概述
Innodb存储引擎支持以下几种常见的索引:
B+树索引
全文索引
哈希索引
自适应哈希索引特性:InnoDB存储引擎会根据表的使用情况自动为表生成哈希索引,不能人为干预是否在表中生成哈希索引。
B+树索引并不能找到一个给定键值的具体行。B+树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
5.3 B+树
为磁盘或其他存取辅助设备设计的一种平衡查找树。
所有记录点按大小顺序存放在同一层的叶子节点上。
各叶子节点由指针进行连接。
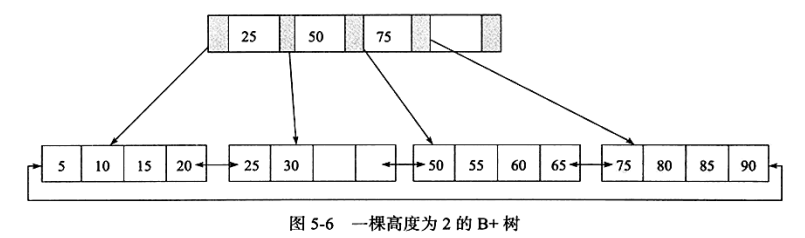
5.4 B+树索引
B+索引在数据库中有一个特点是高扇出性
B+树的高度一般在2~4层,这也就是说查找某一键值的行记录时最多只需要2到4次IO。
扇入:指直接调用该模块的上级模块的个数。
扇出:是指该模块直接调用的下级模块的个数。
B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),但是不管是聚集还是辅助索引,其内部都是B+树的,即高度平衡的,叶子节点存放着所有的数据。
聚集索引和辅助索引不同的是,叶子节点存放的是否是一整行的信息。
聚集索引:
聚集索引就是按照每张表的主键构造一棵B+树。
叶子节点中存放的是整张表的行记录数据,叶子节点也成称为数据页。
索引组织表中数据也是索引的一部分。同B+树数据结构一样,每个数据页通过一个双向链表来进行链接。
聚集索引能够特别快的访问针对范围值的查询。
很多文档写着:聚集索引按照顺序,物理地存储数据。
但是这本书上写的是:聚集索引的存储并不是物理上连续的,而是逻辑上连续的。(我也不知道哪个是对的)
这其中的两点:一是前面说过的页通过双向链表链接,页是按照主键的顺序排序;
另一点是每个页中的记录也是通过双向链表进行维护的,物理存储上可以同样不按照主键存储。
聚集索引的另外一个好处是,它对于主键的排序查找和范围查找速度非常快。
辅助索引(非聚集索引):
叶子节点并不包含行记录的全部数据。
叶子节点除了包含键值外,每个叶子节点中的索引行中还包含了一个书签(bookmark)。
该书签用来告诉innodb存储引擎哪里可以找到与索引相对于的行数据。
辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。
当通过辅助索引来寻找数据时,innodb存储引擎会遍历辅助索引并通过页基本的指针获得指向主键索引的主键,然后再通过主键索引来找到一个完整的行记录。
B+树索引的管理:
ALTER TABLE 表名 ADD [ UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名(属性名 [ (长度) ] [ ASC | DESC]);
CREATE INDEX index_test2 on table_test(age);
创建唯一性索引
ALTER TABLE index14 ADD UNIQUE INDEX index14_id ( course_id(100) ) ;
创建全文索引
ALTER TABLE index15 ADD FULLTEXT INDEX index15_info ( info ) ;
创建空间索引
ALTER TABLE index18 ADD SPATIAL INDEX index18_line( line ) ;
创建多列索引
ALTER TABLE index17 ADD INDEX index17_na( name, address ) ;
CREATE INDEX一个语句一次只能建立一个索引,ALTER TABLE可以在一个语句建立多个,如:
ALTER TABLE HeadOfState ADD PRIMARY KEY (ID), ADD INDEX (LastName,FirstName);
只有ALTER TABLE 才能创建主键
查看索引: SHOW INDEX FROM 表名
5.6 B+树索引的使用
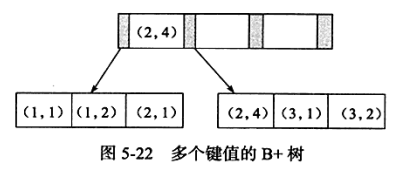
联合索引:
有多个索引列
KEY idx_a_b(a,b) where a =xxx and b=xxx 以及 where a =xxx 都能使用该索引
但是where b =xxx 没发使用该索引,因为如图,1,2,1,4,1,2不是有序的
索引覆盖:
Innodb存储引擎支持索引覆盖,即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。
使用索引覆盖的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。
全文检索:
是将存储在数据库中的整篇文章中的任意内容信息查找出来的技术
InnoDB1.2.x从开始,支持全文检索
第6章 锁
6.3 InnoDB存储引擎中的锁
锁的类型:
InnoDB存储引擎实现了如下两种标准的行级锁:
- 共享锁(读锁 或 S LOCK),允许事务读一行数据
- 排它锁(写锁 或 X LOCK),允许事务删除或者更新一行数据
当一个事务已经获得了行r的共享锁,那么另外的事务可以立即获得行r的共享锁,因为读取并没有改变行r的数据,我们称这种情况为锁兼容。
但如果有事务想获得行r的排它锁,则它必须等待事务释放行r上的共享锁——这种情况我们成为锁不兼容。
InnoDB存储引擎支持多粒度锁定,这种锁定允许在行级上的锁和表级上的锁同时存在。为了支持在不同粒度上进行加锁操作,InnoDB存储引擎支持一种额外的锁方式,我们称之为意向锁。
意向锁是表级别的锁,其设计目的主要是为了在一个事务中揭示下一行将被请求的锁的类型。
- 意向共享锁(IS Lock),事务想要获得一个表中某几行的共享锁。
- 意向排它锁(IX Lock),事务想要获得一个表中某几行的排它锁。
因为InnoDB支持的是行级别的锁,所以意向锁其实不会阻塞除全表扫以外的任何请求。
一致性的非锁定读操作:
是指InnoDB存储引擎通过行多版本并发控制(MVCC)的方式来读取当前执行时间数据库中行的数据。
如果读取的行正在执行DELETE、UPDATE操作,这时读取操作不会因此等待行上的锁释放,相反,存储引擎会去读取一个快照数据。
快照数据是指该行之前版本的数据,该实现是通过Undo段来实现。而Undo用来在事务中回滚数据,因而快照数据本身是没有额外的开销。此外,读取快照数据是不必要上锁的,因为没有必要对历史的数据进行修改。
在Read Comitted事务隔离级别下,对于快照数据,总是读取被锁定行的最新一份快照数据。
在Repeatable Read事务隔离级别下,对于快照数据,总是读取事务开始时的行数据版本。
所以,对于Read Commited的事务隔离级别而言,其实违反了事务的隔离性。
锁定读操作:
SELECT…FOR UPDATE 对读取的行记录加一个X锁。其他事务想在这些行上加任何锁都会被阻塞。
SELECT…LOCK IN SHARE MODE 对读取的行记录加一个S锁。其他事务可以向锁定的记录加S锁,但是对于加X锁,则会被阻塞。
6.4 锁的算法
行锁的3种算法:
InnoDB存储引擎有3种行锁的算法设计:
- Record Lock:单个行记录上的锁,锁定的对象是索引,而不是数据。
- Gap Lock:间隙锁,锁定一个范围的索引,但不包含记录本身
- Next-Key Lock: Gap Lock + Record Lock,锁定一个范围的索引,并且锁定记录本身。
Record Lock总是会锁住索引记录,如果InnoDB存储引擎建立的时候没有设置任何一个索引,这时InnoDB存储引擎会使用隐式的主键来进行锁定。
比如:`SELECT * FROM t WHERE a < 6 lock in share mode,该语句会锁定(-oo, 6)这个数值区间的所有数值。
解决幻读问题:
InnoDB存储引擎采用Next-Key Locking机制来避免幻读。
幻读:同一事务下,连续执行两次同样的SQL语句可能导致不同的结果。第二次SQL语句可能会返回之前不存在的行。
假如表t由1,2,5三个值组成, where a > 2 ,被锁住的不仅是5这个值,而是(2,+∞)这个范围加了X锁
在读提交级别下,仅采用Record Lock
6.5 锁问题
脏读:
即一个事务可以读到另一个事务中未提交的数据,违反了数据库的隔离性。发生条件:READ UNCOMMITED,这个隔离级别在Mysql中不使用。
不可重复读:
一个事务两次读同一数据,结果不一样。(另一个事务修改了改数据并提交)
不可重复读和脏读的区别是:脏读是读到未提交的数据;而不可重复读读到的确实是已经提交的数据,但是其违反了数据库事务一致性的要求。
InnoDB的默认事务隔离级别是READ REPEATABLE,采用Next-Key Lock算法,解决了不可重复读(幻读)问题。
在Next-Key Lock 算法下,不仅仅是锁住扫描到的索引,而且还锁住这些索引覆盖的范围(gap)。因此对于这个范围内的插入都是不允许的。
6.7 死锁
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种相互等待的现象。
超时机制:当一个事务等待超时,则对它进行回滚。但是有可能回滚的这个事务的时间要比另一个事务要多。(就是还不如回滚另一个没超时的)
InnoDB采用wait-for graph(等待图)的方式来进行死锁检测。
6.7 锁升级
指将当前锁的粒度降低,比如1000个行锁升级为一个页锁,或者将页锁升级为表锁。
InnoDB不存在锁升级的问题。
其根据每个事务访问的每个页对锁进行管理,采用的是位图的方式。
不管事务锁住页中的一个记录还是多个记录,其开销是一样的。
第7章 事务
7.1 认识事务
事务是访问并更新数据库的一个程序执行单元。
ACID:
Atomicity 原子性: 数据库事务是不可分割的工作单位, 要么都做, 要么都不做.
Consistency 一致性: 事务不会破坏事务的完整性约束. 事务将数据库从一个一致状态转变为另一个一致状态
Isolation 隔离性: 事务之间相互分离, 在提交之前相互不可见.
Durability 持久性: 事务一旦提交, 其产生的效果就是永久的
分类
- 扁平事务
- 带保存点的扁平事务
- 链事务
- 嵌套事务 (nested transactions)
- 分布式事务
扁平事务
使用最为频繁
- 以
BEGIN [WORK]/START TRANSACTION开始 - 以
COMMIT [WORK]成功提交ROLLBACK [WORK]回滚
带保存点的扁平事务
就是可以不会滚全部,只回滚一部分
- 使用
SAVE WORK新增保存点 - 扁平事务默认带着一个事务开始时的保存点
7.2 事务的实现
事务的隔离性由锁实现
原子性,一致性,持久性 由 redo log / undo log 实现
undo log 保证事务的一致性, 逻辑日志, 根据每行记录进行记录,帮助事务回滚及MVCC
redo log(重做日志): 保证事务的原子性和持久性, 物理日志
redo log:
由两部分组成:内存中的重做日志缓冲,易失的
重做日志文件,持久的
事务提交时,必须将事务的的所有日志写入重做日志进行持久化。
undo log:
记录的是 SQL, undo 之后底层物理文件格式可能会改变
当前事务通过undo读取之前的行版本信息,来实现非锁定读
undo log 会产生redo log,因为undo log也需要持久性的保护
purge:
删除并没有删除原数据,只是delete flag置为1
若该行记录已经不被其他事务引用,则purge完成真正的删除
7.6 事务隔离级别
READ UNCOMMITTED(读未提交):事务隔离最低的级别,但是存在脏读的问题
READ COMMITED(读提交):ORACLE和SQL SERVER默认的隔离级别,解决了脏读,但是一个事务多次读取的内容不同,出现了不可重复读的问题。
READ REPEATABLE(可重复读):innodb引擎的默认事务隔离级别,解决了不可重复读的问题,但是产生了幻读,innodb通过Next-key lock解决了幻读。
SERIALIZABLE(可串行化):通过强制事务排序解决幻读问题,会降低性能。
可串行化中,InnoDB会对每个select语句后加上LOCK IN SHARE MODE,也就是为每个读加上共享锁。该级别主要用于分布式事务。
7.7 分布式事务
指允许多个独立的事务资源参与到一个全局的事务中。
全局事务要求在其中所有参与的事务要么都提交,要么都回滚。
InnoDB的隔离级别要设置为可串行化。
7.8 不好的习惯
在循环中提交事务
不要开启自动提交事务 set auto_commit = 0
使用自动回滚,存储过程中使用 declare exit handlerfor sqlexception rollback
《MySQL技术内幕 InnoDB存储引擎 》学习笔记的更多相关文章
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
- PHP-会员登录与注册例子解析-学习笔记
1.开始 最近开始学习李炎恢老师的<PHP第二季度视频>中的“章节5:使用OOP注册会员”,做一个学习笔记,通过绘制基本页面流程和UML类图,来对加深理解. 2.基本页面流程 3.通过UM ...
- 2014年暑假c#学习笔记目录
2014年暑假c#学习笔记 一.C#编程基础 1. c#编程基础之枚举 2. c#编程基础之函数可变参数 3. c#编程基础之字符串基础 4. c#编程基础之字符串函数 5.c#编程基础之ref.ou ...
- JAVA GUI编程学习笔记目录
2014年暑假JAVA GUI编程学习笔记目录 1.JAVA之GUI编程概述 2.JAVA之GUI编程布局 3.JAVA之GUI编程Frame窗口 4.JAVA之GUI编程事件监听机制 5.JAVA之 ...
- seaJs学习笔记2 – seaJs组建库的使用
原文地址:seaJs学习笔记2 – seaJs组建库的使用 我觉得学习新东西并不是会使用它就够了的,会使用仅仅代表你看懂了,理解了,二不代表你深入了,彻悟了它的精髓. 所以不断的学习将是源源不断. 最 ...
- CSS学习笔记
CSS学习笔记 2016年12月15日整理 CSS基础 Chapter1 在console输入escape("宋体") ENTER 就会出现unicode编码 显示"%u ...
- HTML学习笔记
HTML学习笔记 2016年12月15日整理 Chapter1 URL(scheme://host.domain:port/path/filename) scheme: 定义因特网服务的类型,常见的为 ...
- DirectX Graphics Infrastructure(DXGI):最佳范例 学习笔记
今天要学习的这篇文章写的算是比较早的了,大概在DX11时代就写好了,当时龙书11版看得很潦草,并没有注意这篇文章,现在看12,觉得是跳不过去的一篇文章,地址如下: https://msdn.micro ...
- ucos实时操作系统学习笔记——任务间通信(消息)
ucos另一种任务间通信的机制是消息(mbox),个人感觉是它是queue中只有一个信息的特殊情况,从代码中可以很清楚的看到,因为之前有关于queue的学习笔记,所以一并讲一下mbox.为什么有了qu ...
随机推荐
- pgm5
这部分讨论 inference 里面基本的问题,即计算 这类 query,这一般可以认为等价于计算 ,因为我们只需要重新 normalize 一下关于 的分布就得到了需要的值,特别是像 MAP 这类 ...
- 【刷题】LOJ 6012 「网络流 24 题」分配问题
题目描述 有 \(n\) 件工作要分配给 \(n\) 个人做.第 \(i\) 个人做第 \(j\) 件工作产生的效益为 \(c_{ij}\) .试设计一个将 \(n\) 件工作分配给 \(n\) ...
- Fake or True(HNOI2018)
闲话 或许有人会问博主蒟蒻:ZJOI爆0记呢? 博主太弱了,刚刚去ZJ做了个梦回来,又得马不停蹄地准备HNOI 于是就成了烂坑 不过至少比某某更强更fake的xzz的游记要好一些 其实ZJOI挺值得回 ...
- 【bzoj3489】 A simple rmq problem
http://www.lydsy.com/JudgeOnline/problem.php?id=3489 (题目链接) 题意 在线求区间不重复出现的最大的数. Solution KDtree竟然能够处 ...
- Qt QGraphicsItem 绕中心旋转、放缩
最近用到了QGraphicsItem,可以通过QGraphicsItemAnimation使其产生动画效果. QGraphicsItemAnimation自带了setPosAt().setRotati ...
- 8: springMVC ModelAndView 作用与功能解析
Spring mvc视图机制 所有的web应用的mvc框架都有它定位视图的方式.Spring提供了视图解析器供你在浏览器中显示模型数据,而不必被拘束在特定的视图技术上. Spring的控制器Contr ...
- IAR ------ 基本使用
1.编译结果: 6 887 bytes of readonly code memory 621 bytes of readonly data memory 331 bytes of readwrite ...
- python的面向对象-类的数据属性和实例的数据属性相结合-无命名看你懵逼不懵逼系列
1. class Chinese: country='China' def __init__(self,name): self.name=name def play_ball(self,ball): ...
- Kubernetes Service
目录 基本概念 服务发现与负载均衡 配置Service 创建一个ClusterIP类型的Service 创建一个指定ClusterIP的Service 创建一个headless service 创建一 ...
- 鸟哥的Linux私房菜——第十九章:例行命令的建立
视频链接:http://www.bilibili.com/video/av11008859/ 1. 什么是例行性命令 (分为两种,一种是周期性的,一种是突发性的)1.1 Linux 工作排程的种类: ...