开源通用爬虫框架YayCrawler-运行与调试
本节我将向大家介绍如何运行与调试YayCrawler。该框架是采用SpringBoot开发的,所以可以通过java –jar xxxx.jar的方式运行,也可以部署在tomcat等容器中运行。
首先让我们介绍一下运行环境:
1、jdk8
2、安装mysql数据库,用作存储解析规则等数据,需要创建一个“yayCrawler”的数据库实例,并执行quartz相关的数据库脚本:quartz.sql(见发布包或源码)。
3、安装redis,用作任务队列
4、安装mongoDB用于存放结果数据
5、安装ftp服务器软件ftpserver(可选,用于存放下载图片)
一、运行发布包
首先从https://github.com/liushuishang/YayCrawler.Release.git获取release包,目录如下:
每个文件夹里面的文件结构是一样的,以admin文件夹为例
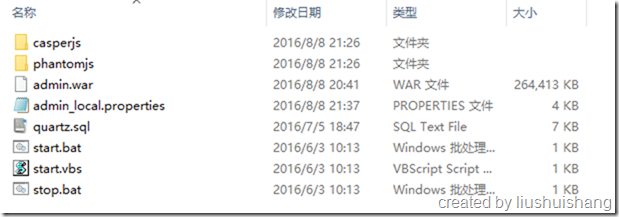
casperjs和phantomjs两个文件夹是为了执行某些特殊操作准备的,这里先不用理会。xxx_local.properties是一个服务配置文件,里面有配置端口、数据库连接等参数,可以按照实际参数来调整;quartz.sql是运行quartz框架需要的数据库表脚本,方在这里是为了方便;start.bat和start.vbs都是启动脚本,双击就可以启动admin端,start.bat会在控制台输出日志内容,start.vbs是在后台执行,不会弹出控制台,启动后会在该文件夹产生一个“catalina.base_IS_UNDEFINED”的文件夹,里面存放的是输出日志;双击stop.bat就可以停止admin端程序。我们双击start.bat来启动admin端程序:
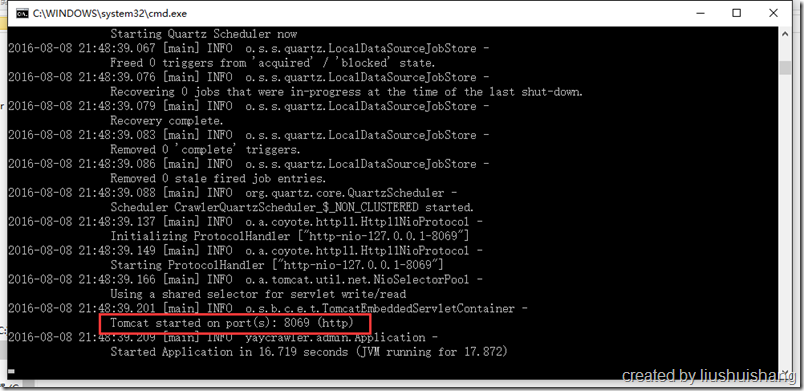
可以看到admin端已经成功启动,浏览器http://localhost:8069/admin/即可访问管理界面:
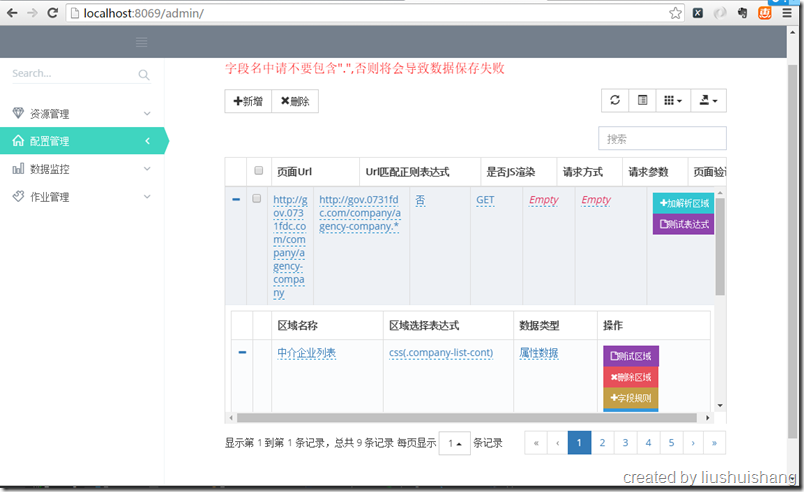
Master与Worker的启动与上面Admin端一致,只是没有web界面,这里不再赘述。
二、源码的运行与调试
首先从https://github.com/liushuishang/YayCrawler.git拉取源码,然后用Intellij Idea打开(Eclipse也可以),可以看到如下的目录解构:
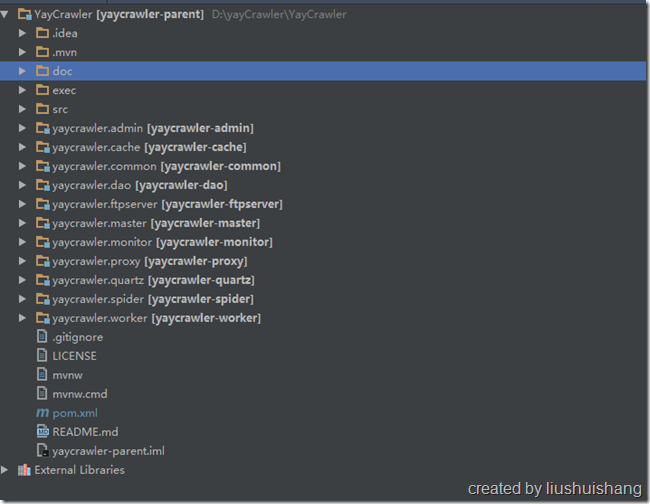
yaycrawler-admin:Web管理控制台,用户可以这里配置解析规则、测试规则、查看任务队列情况和发布任务等。
yaycralwer-master:管理任务队列和任务调度,与admin和worker互相通信。
yaycralwer-worker:爬虫任务的工作端,定时向master发送心跳,接收并执行任务,负责数据的持久化。
yaycralwer-spider:与WebMagic结合,负责下载页面、解析页面、定义爬虫任务的处理流程和接口。
yaycrawler-common:公用的实体模型和工具包。
yaycralwer-monitor:提供反监控的工具包,比如验证码刷新、自动登陆等
yaycralwer-proxy:工具包,用于从网上搜索可用的ip代理
yaycrawler-cache:为框架提供数据缓存功能的组件。
yaycrawler-quartz:通用的定时任务调度组件,可以通过配置定时调度不同的任务。可以用来做定时爬虫任务。
yaycrawler-dao:提供与mysql数据库交互的功能。
yaycrawler-ftpserver:ftpserver客户端工具包。
我们分别为admin、master和worker配置三个TomcatServer,各占用的http端口如下图所示。
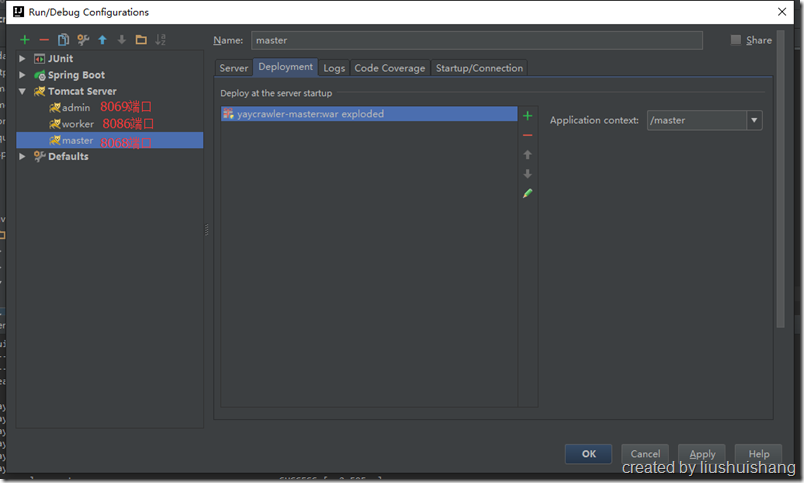
然后分别修改各自工程下的src/main/resources/application.properties文件,如(请注意红色的部分配置)
Admin端:
signature.token=2c91d29854a2f3fc0154a30959f40003
#Master的服务地址
master.server.address=http://127.0.0.1:8068/master/
# EMBEDDED SERVER CONFIGURATION (ServerProperties)
server.port=8069
# bind to a specific NIC
server.address=127.0.0.1
# the context path, defaults to '/'
server.context-path=/admin
# the servlet path, defaults to '/'
server.servlet-path=/
# base dir (usually not needed, defaults to tmp)
server.tomcat.basedir=/tmp
# in seconds
server.tomcat.background-processor-delay=30
# number of threads in protocol handler
server.tomcat.max-threads = 0
# character encoding to use for URL decoding
server.tomcat.uri-encoding = UTF-8
#(这里是限制的文件大小)
multipart.max-file-size=50Mb
#(这里是限制请求的文件大小)
multipart.max-request-size=50Mb
# SPRING MVC (HttpMapperProperties)
# pretty print JSON
http.mappers.json-pretty-print=false
# sort keys
http.mappers.json-sort-keys=false
# set fixed locale, e.g. en_UK
spring.mvc.locale=zh_CN
# set fixed date format, e.g. dd/MM/yyyy
spring.mvc.date-format=yyyy-MM-dd
# PREFIX_ERROR_CODE / POSTFIX_ERROR_CODE
spring.resources.cache-period=60000
# cache timeouts in headers sent to browser
spring.mvc.message-codes-resolver-format=PREFIX_ERROR_CODE # THYMELEAF (ThymeleafAutoConfiguration)
spring.thymeleaf.cache=false
spring.thymeleaf.check-template-location=true
spring.thymeleaf.content-type=text/html
spring.thymeleaf.enabled=true
spring.thymeleaf.encoding=UTF-8
#spring.thymeleaf.excluded-view-names= # Comma-separated list of view names that should be excluded from resolution.
spring.thymeleaf.mode=HTML5
spring.thymeleaf.prefix=classpath:/templates/
spring.thymeleaf.suffix=.html
#spring.thymeleaf.template-resolver-order= # Order of the template resolver in the chain.
#spring.thymeleaf.view-names= # Comma-separated list of view names that can be resolved. #配置Mysql数据库
spring.datasource.url = jdbc:mysql://localhost:3306/yaycrawler?autoReconnect=true
&characterEncoding=utf8&useSSL
=false
spring.datasource.username = root
spring.datasource.password = root
spring.datasource.driverClassName = com.mysql.jdbc.Driver
# Specify the DBMS
spring.jpa.database = MYSQL
# Show or not log for each sql query
spring.jpa.show-sql = true
# Hibernate ddl auto (create, create-drop, update)
spring.jpa.hibernate.ddl-auto = update //首次运行请修改为create来创建数据表,完成后更改为update
# Naming strategy
#spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.DefaultNamingStrategy
spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.ImprovedNamingStrategy
# stripped before adding them to the entity manager)
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect #配置MongoDB数据库
# MONGODB (MongoProperties)
#spring.data.mongodb.authentication-database= # Authentication database name.
spring.data.mongodb.database=crawler
#spring.data.mongodb.field-naming-strategy= # Fully qualified name of the FieldNamingStrategy to use.
#spring.data.mongodb.grid-fs-database= # GridFS database name.
spring.data.mongodb.host=localhost
spring.data.mongodb.port=27017
# Enable Mongo repositories.
spring.data.mongodb.repositories.enabled=true
#spring.data.mongodb.uri=mongodb://localhost/test # Mongo database URI. When set, host and port are ignored.
#spring.data.mongodb.username=
#spring.data.mongodb.password=
master端:
signature.token=2c91d29854a2f3fc0154a30959f40003
#一次分配给worker的任务大小
worker.task.batchSize=500
#worker的刷新时间
worker.refreshInteval=20000
#处理中队列超时时间
task.queue.timeout=5400000
#批量加入队列时的批量包含的任务数
task.queue.batchSize=1000
# EMBEDDED SERVER CONFIGURATION (ServerProperties)
server.port=8068
# bind to a specific NIC
server.address=127.0.0.1
#server.address=127.0.0.1
# the context path, defaults to '/'
server.context-path=/master
# the servlet path, defaults to '/'
server.servlet-path=/
# base dir (usually not needed, defaults to tmp)
server.tomcat.basedir=/tmp
# in seconds
server.tomcat.background-processor-delay=30
# number of threads in protocol handler
server.tomcat.max-threads = 0
# character encoding to use for URL decoding
server.tomcat.uri-encoding = UTF-8 spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.database=1
#spring.redis.password=
Worker端:
signature.token=2c91d29854a2f3fc0154a30959f40003
master.server.address=http://127.0.0.1:8068/master/
context.path=http://127.0.0.1:8086/worker/
worker.heartbeat.inteval=60000
worker.spider.threadCount=10 # ftpserver服务器地址
ftp.server.url=172.17.82.46
# ftpserver 端口
ftp.server.port=2121
# ftpserver 用户名
ftp.server.username=admin
# ftpserver 密码
ftp.server.password=admin # EMBEDDED SERVER CONFIGURATION (ServerProperties)
server.port=8086
# bind to a specific NIC
server.address=127.0.0.1
# the context path, defaults to '/'
server.context-path=/worker
# the servlet path, defaults to '/'
server.servlet-path=/
# base dir (usually not needed, defaults to tmp)
server.tomcat.basedir=/tmp
# in seconds
server.tomcat.background-processor-delay=30
# number of threads in protocol handler
server.tomcat.max-threads = 0
# character encoding to use for URL decoding
server.tomcat.uri-encoding = UTF-8 #Spring JPA
spring.datasource.url = jdbc:mysql://localhost:3306/yaycrawler?autoReconnect=true
&characterEncoding=utf8&useSSL=false
spring.datasource.username = root
spring.datasource.password = root
spring.datasource.driverClassName = com.mysql.jdbc.Driver
# Specify the DBMS
spring.jpa.database = MYSQL
# Show or not log for each sql query
spring.jpa.show-sql = false
# Hibernate ddl auto (create, create-drop, update)
spring.jpa.hibernate.ddl-auto = none
# Naming strategy
#spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.DefaultNamingStrategy
spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.ImprovedNamingStrategy
# stripped before adding them to the entity manager)
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect # MONGODB (MongoProperties)
#spring.data.mongodb.authentication-database= # Authentication database name.
spring.data.mongodb.database=crawler
#spring.data.mongodb.field-naming-strategy= # Fully qualified name of the FieldNamingStrategy to use.
#spring.data.mongodb.grid-fs-database= # GridFS database name.
spring.data.mongodb.host=localhost
spring.data.mongodb.port=27017
# Enable Mongo repositories.
spring.data.mongodb.repositories.enabled=true
#spring.data.mongodb.uri=mongodb://localhost/test # Mongo database URI. When set, host and port are ignored.
#spring.data.mongodb.username=
#spring.data.mongodb.password=
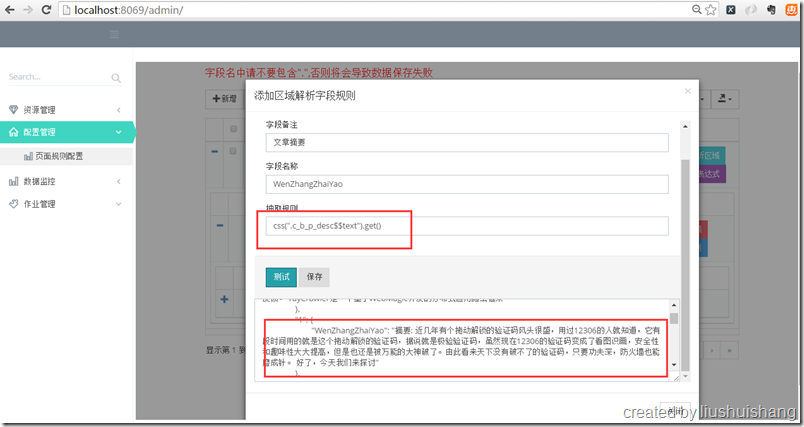
启动Master、Admin和Worker,在浏览器中输入http://localhost:8069/admin/,即可访问管理界面。
三、案例演示
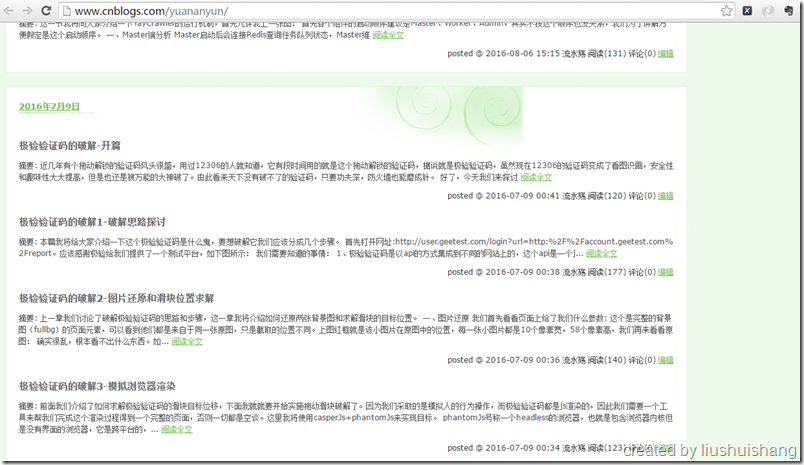
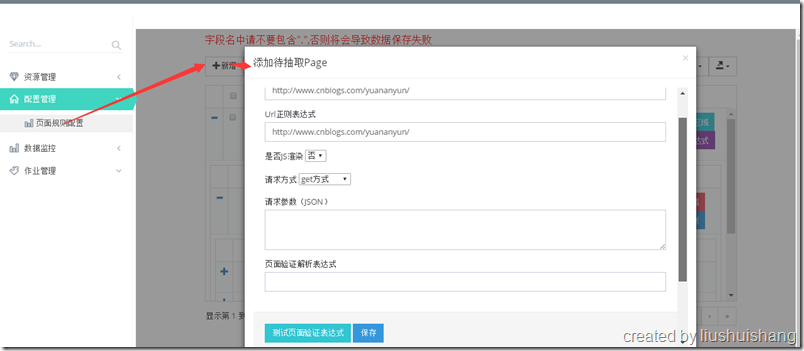
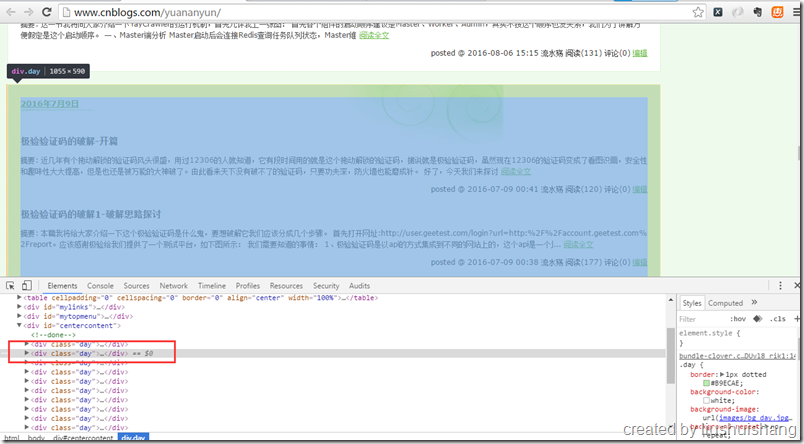
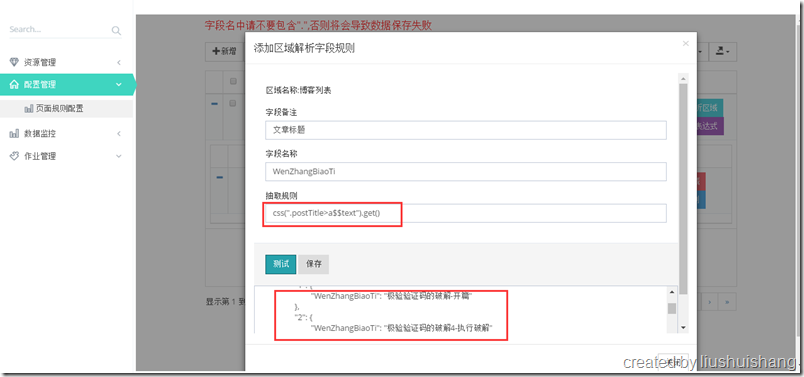
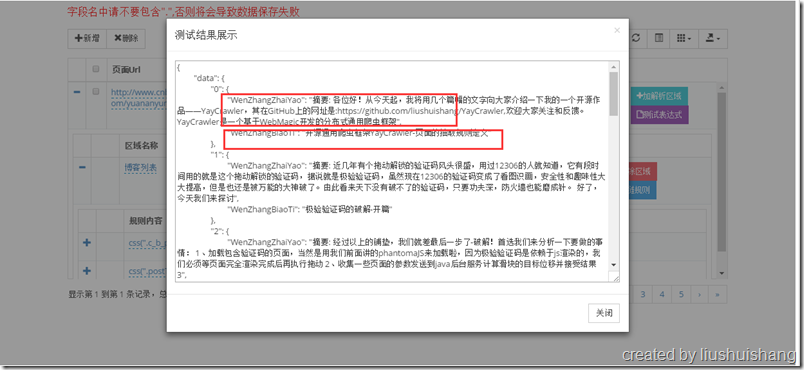
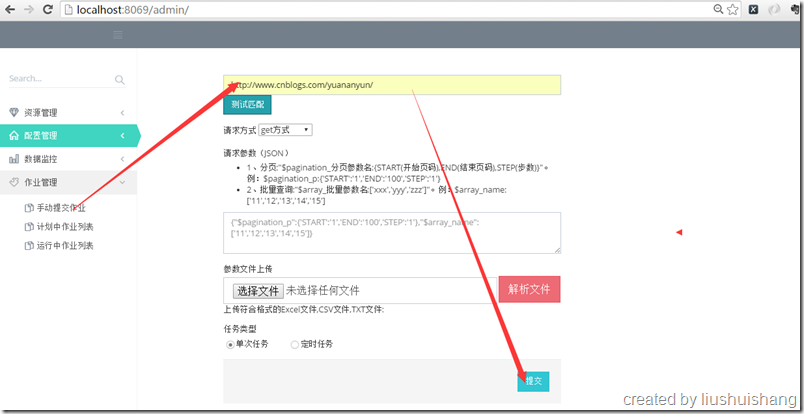
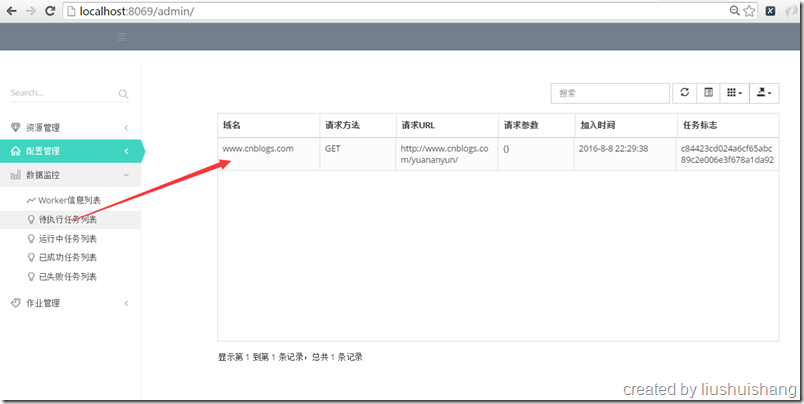
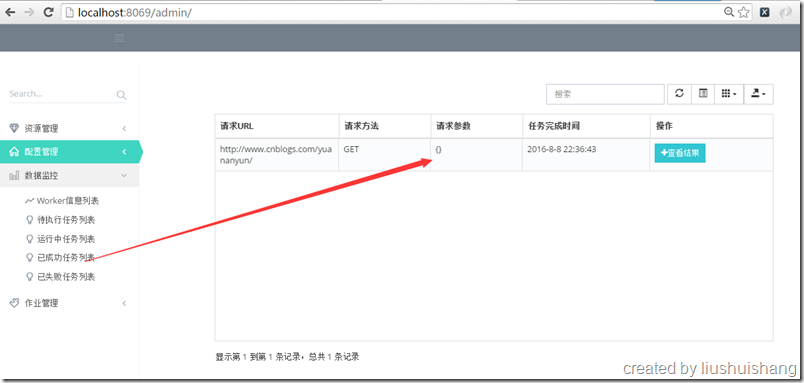
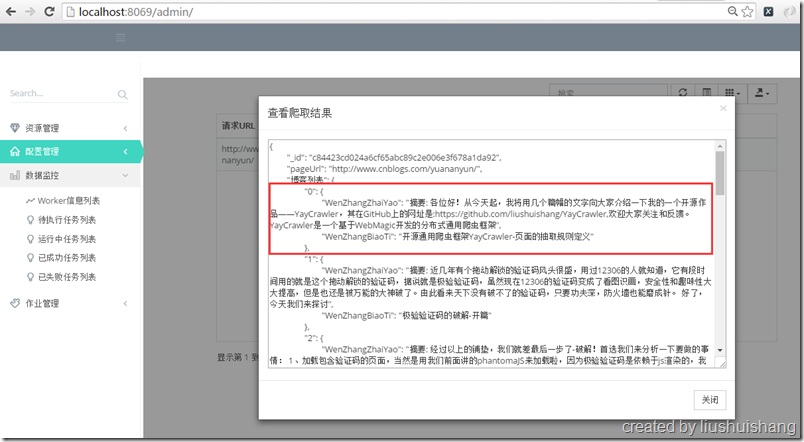
前面已经介绍如何启动项目,现在我们以抓取博客园的博客为例讲解如何使用框架。假设我要通过框架抓取http://www.cnblogs.com/yuananyun/页面的所有博客的标题和摘要,让我们来开始创建奇迹吧,哈哈。



开源通用爬虫框架YayCrawler-运行与调试的更多相关文章
- 开源通用爬虫框架YayCrawler-开篇
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品--YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCraw ...
- 开源通用爬虫框架YayCrawler-框架的运行机制
这一节我将向大家介绍一下YayCrawler的运行机制,首先允许我上一张图: 首先各个组件的启动顺序建议是Master.Worker.Admin,其实不按这个顺序也没关系,我们为了讲解方便假定是这个启 ...
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
本节我将向大家介绍一下YayCrawler的核心-页面的抽取规则定义,这也是YayCrawler能够做到通用的主要原因之一.如果我要爬去不同的网站的数据,尽管他们的网站采用的开发技术不同.页面的结构不 ...
- 爬虫框架YayCrawler
爬虫框架YayCrawler 各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liush ...
- 一个简单的开源PHP爬虫框架『Phpfetcher』
这篇文章首发在吹水小镇:http://blog.reetsee.com/archives/366 要在手机或者电脑看到更好的图片或代码欢迎到博文原地址.也欢迎到博文原地址批评指正. 转载请注明: 吹水 ...
- 基于 Java 的开源网络爬虫框架 WebCollector
原文:https://www.oschina.net/p/webcollector
- Scrapy爬虫框架第一讲(Linux环境)
1.What is Scrapy? 答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰.模块之间的耦合程度低,具有较强的扩张性,能满足各种需求.(前 ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师的要求,大多是招JA ...
- 二十四、【开源】EFW框架Winform前端开发之项目结构说明和调试方法
回<[开源]EFW框架系列文章索引> EFW框架源代码下载V1.2:http://pan.baidu.com/s/1hcnuA EFW框架实例源代码下载:http://pan ...
随机推荐
- 函数式编程编程即高阶函数+monad
高阶函数负责数据的单次映射: monad负责数据处理流的串联,并使得串联函数具有相同的形式. 同时moand负责基础类型和高阶类型间的转换.
- MetaMask/Website
https://github.com/MetaMask/Website 将这个包下载下来之后运行npm install出现下面的问题 gyp: No Xcode or CLT version dete ...
- ethereumjs/ethereumjs-util
ethereumjs/ethereumjs-util Most of the string manipulation methods are provided by ethjs-util 更多的字符串 ...
- DD-WRT
定时任务: 每日凌晨1點關, 星期1-, 上午7點半開, 8點半關, 晚上9點開 星期6/日, 上午開10點開 administration -> management -> enable ...
- WPF样式(Style)入门
原文:WPF样式(Style)入门 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/qq_34802416/article/details/78231 ...
- 洛咕 P3700 [CQOI2017]小Q的表格
洛咕 P3700 [CQOI2017]小Q的表格 神仙题orz 首先推一下给的两个式子中的第二个 \(b\cdot F(a,a+b)=(a+b)\cdot F(a,b)\) 先简单的想,\(F(a,a ...
- 分布式事务的CAP理论 与BASE理论
CAP理论 一个经典的分布式系统理论.CAP理论告诉我们:一个分布式系统不可能同时满足一致性(C:Consistency).可用性(A:Availability)和分区容错性(P:Partition ...
- resource fork, Finder information, or similar detritus not allowed
1.关闭当前项目和Xcode 2.打开终端或者iterm cd ~/Library/Developer/Xcode/DerivedData/ 3. xattr -rc . 4.重新打开项目 5.如果不 ...
- SpringBoot日记——Redis整合
上一篇文章,简单记录了一下缓存的使用方法,这篇文章将把我们熟悉的redis整合进来. 那么如何去整合呢?首先需要下载和安装,为了使用方便,也可以做环境变量的配置. 下载和安装的方法,之前有介绍,在do ...
- Js_字体滚动换颜色
<html><head><meta http-equiv="Content-Type" content="text/html; charse ...