通过mapreduce把mysql的数据读取到hdfs
前面讲过了怎么通过mapreduce把mysql的一张表的数据放到另外一张表中,这次讲的是把mysql的数据读取到hdfs里面去
具体怎么搭建环境我这里就不多说了。参考
通过mapreduce把mysql的一张表的数据导到另外一张表中
也在eclipse里面创建一个mapreduce工程

具体的实现代码
package com.gong.mrmysql; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Iterator; import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.lib.IdentityReducer;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.mapred.lib.db.DBWritable; /**
* Function: 测试 mr 与 mysql 的数据交互,此测试用例将一个表中的数据复制到另一张表中
* 实际当中,可能只需要从 mysql 读,或者写到 mysql 中。
* date: 2013-7-29 上午2:34:04 <br/>
* @author june
*/
public class Mysql2Mr {
// DROP TABLE IF EXISTS `hadoop`.`studentinfo`;
// CREATE TABLE studentinfo (
// id INTEGER NOT NULL PRIMARY KEY,
// name VARCHAR(32) NOT NULL); public static class StudentinfoRecord implements Writable, DBWritable {
int id;
String name; //构造方法
public StudentinfoRecord() { } //Writable接口是对数据流进行操作的,所以输入是DataInput类对象
public void readFields(DataInput in) throws IOException {
this.id = in.readInt(); //输入流中的读取下一个整数,并返回
this.name = Text.readString(in);
} public String toString() {
return new String(this.id + " " + this.name);
} //DBWritable负责对数据库进行操作,所以输出格式是PreparedStatement
//PreparedStatement接口继承并扩展了Statement接口,用来执行动态的SQL语句,即包含参数的SQL语句
@Override
public void write(PreparedStatement stmt) throws SQLException {
stmt.setInt(, this.id);
stmt.setString(, this.name);
} //DBWritable负责对数据库进行操作,输入格式是ResultSet
// ResultSet接口类似于一张数据表,用来暂时存放从数据库查询操作所获得的结果集
@Override
public void readFields(ResultSet result) throws SQLException {
this.id = result.getInt();
this.name = result.getString();
} //Writable接口是对数据流进行操作的,所以输出是DataOutput类对象
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(this.id);
Text.writeString(out, this.name);
}
} // 记住此处是静态内部类,要不然你自己实现无参构造器,或者等着抛异常:
// Caused by: java.lang.NoSuchMethodException: DBInputMapper.<init>()
// http://stackoverflow.com/questions/7154125/custom-mapreduce-input-format-cant-find-constructor
// 网上脑残式的转帖,没见到一个写对的。。。
public static class DBInputMapper extends MapReduceBase implements
Mapper<LongWritable, StudentinfoRecord, LongWritable, Text> {
public void map(LongWritable key, StudentinfoRecord value,
OutputCollector<LongWritable, Text> collector, Reporter reporter) throws IOException {
collector.collect(new LongWritable(value.id), new Text(value.toString()));
}
} public static class MyReducer extends MapReduceBase implements
Reducer<LongWritable, Text, StudentinfoRecord, Text> {
@Override
public void reduce(LongWritable key, Iterator<Text> values,
OutputCollector<StudentinfoRecord, Text> output, Reporter reporter) throws IOException {
String[] splits = values.next().toString().split(" ");
StudentinfoRecord r = new StudentinfoRecord();
r.id = Integer.parseInt(splits[]);
r.name = splits[];
output.collect(r, new Text(r.name));
}
} public static void main(String[] args) throws IOException {
JobConf conf = new JobConf(Mysql2Mr.class);
DistributedCache.addFileToClassPath(new Path("hdfs://192.168.241.13:9000/mysqlconnector/mysql-connector-java-5.1.38-bin.jar"), conf); conf.setMapOutputKeyClass(LongWritable.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(LongWritable.class);
conf.setOutputValueClass(Text.class); // conf.setOutputFormat(DBOutputFormat.class);
conf.setInputFormat(DBInputFormat.class); // mysql to hdfs
conf.set("fs.defaultFS", "hdfs://192.168.241.13:9000");//在配置文件conf中指定所用的文件系统---HDFS
conf.setReducerClass(IdentityReducer.class);
Path outPath = new Path("hdfs://192.168.241.13:9000/student/out1");
FileSystem.get(conf).delete(outPath, true);
FileOutputFormat.setOutputPath(conf, outPath); DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.241.13:3306/mrtest",
"root", "");
String[] fields = { "id", "name" };
// 从 t 表读数据
DBInputFormat.setInput(conf, StudentinfoRecord.class, "t", null, "id", fields); // mapreduce 将数据输出到 t2 表
//DBOutputFormat.setOutput(conf, "t2", "id", "name"); // FileOutputFormat.setOutputPath(conf, new Path("hdfs://192.168.241.13:9000/student/out1")); conf.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);
conf.setMapperClass(DBInputMapper.class);
// conf.setReducerClass(MyReducer.class); JobClient.runJob(conf);
}
}
特别要主要的是在主函数里面添加这么一句话

如果不添加这句话的话就不能识别你的hdfs路径了,除了这个方法之外还,不想添加这句话的话还可以把集群的core-site.xml文件直接拷贝一份放到工程的src目录下
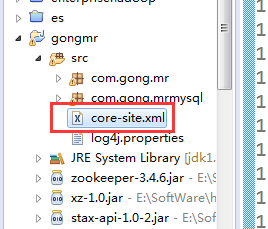
这样也是可以的
运行程序
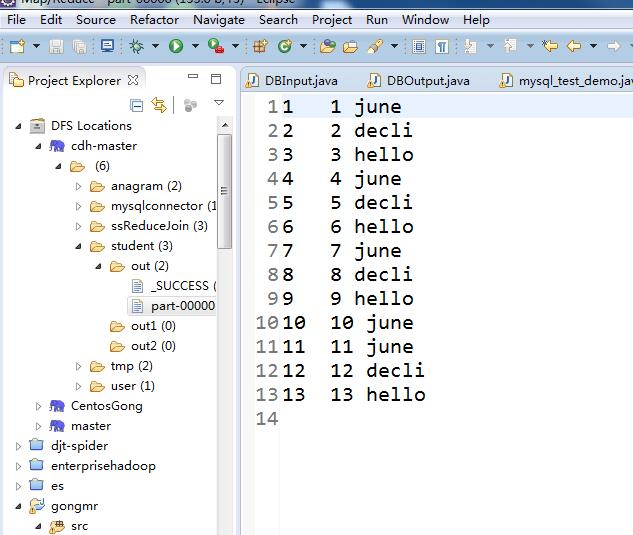
可以看到hdfs的文件上面已经有mysql数据库表的内容了
通过mapreduce把mysql的数据读取到hdfs的更多相关文章
- Mysql遍历大表(Mysql大量数据读取内存溢出的解决方法)
mysql jdbc默认把select的所有结果全部取回,放到内存中,如果是要遍历很大的表,则可能把内存撑爆. 一种办法是:用limit,offset,但这样你会发现取数据的越来越慢,原因是设置了of ...
- MySQL的数据读取过程
本文来自:http://blog.chinaunix.net/uid-20785090-id-4759476.html 对于build-in的innodb的架构,每次当发布IO请求时,究竟是mysql ...
- MYSQL 的数据读取方式
例子: create table T(X bit(8)); insert into T (X) values(b'11111111'); select X from T; 这个时候会发现这个X 是乱码 ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟
使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 Sqoop 大数据 Hive HBase ETL 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 基础环境 ...
- 五.hadoop 从mysql中读取数据写到hdfs
目录: 目录见文章1 本文是基于windows下来操作,linux下,mysql-connector-java-5.1.46.jar包的放置有讲究. mr程序 import java.io.DataI ...
- pandas读取MySql/SqlServer数据 (转)
在 Anacondas环境中,conda install pymssql ,一直报包冲突,所以采用先在 https://www.lfd.uci.edu/~gohlke/pythonlibs/#nump ...
- 通过mapreduce把mysql的一张表的数据导到另外一张表中
怎么安装hadoop集群我在这里就不多说了,我这里安装的是三节点的集群 先在主节点安装mysql 启动mysql 登录mysql 创建数据库,创建表格,先把数据加载到表格 t ,表格t2是空的 mys ...
- 如何实现MySQL表数据随机读取?从mysql表中读取随机数据
文章转自 http://blog.efbase.org/2006/10/16/244/如何实现MySQL表数据随机读取?从mysql表中读取随机数据?以前在群里讨论过这个问题,比较的有意思.mysql ...
随机推荐
- [转]B树(多向平衡查找树)详解
B-树是对2-3树数据结构的扩展.它支持对保存在磁盘或者网络上的符号表进行外部查找,这些文件可能比我们以前考虑的输入要大的多(以前的输入能够保存在内存中). (B树和B+树是实现数据库的数据结构,一般 ...
- 删除JavaScript对象中的元素
参考http://stackoverflow.com/questions/208105/how-to-remove-a-property-from-a-javascript-object 通过dojo ...
- spring-IOC容器(二)
一.bean配置里面使用外部属性文件: <bean>中添加context Schema定义,Spring 提供了一个<property-placeholder>元素,可以在be ...
- JMeter 插件 Json Path 解析 HTTP 响应 JSON 数据(转)
JMeter 是一个不错的负载和性能测试工具,我们也用来做 HTTP API 接口测试.我们的 API 返回结果为 JSON 数据格式.JSON 简介,JSON 教程. JSON 已经成为数据交换格式 ...
- Vivado HLS初识---阅读《vivado design suite tutorial-high-level synthesis》(2)
Vivado HLS初识---阅读<vivado design suite tutorial-high-level synthesis>(2) 1.实验目的 2.启动命令行 将命令行切换 ...
- 代码编辑器之sublime text
http://www.iplaysoft.com/sublimetext.html 1.特点: 中文乱码问题:另外,很多朋友反映表示打开中文会有乱码,其实是因为ST2本身只支持UTF-8编码,而我们常 ...
- Java ArrayList排序方法详解
由于其功能性和灵活性,ArrayList是 Java 集合框架中使用最为普遍的集合类之一.ArrayList 是一种 List 实现,它的内部用一个动态数组来存储元素,因此 ArrayList 能够在 ...
- windows下安装mingw-w64
mingw-w64应该可以算是mingw的改进版本吧,mingw系列编译器是非常好的并且主流的c/c++编译器 mingw-w64只负责程序的编译,只提供命令行操作没有编辑代码的图像界面,代码的编写需 ...
- HAAR小波
HAAR小波分解信号或图像的“平滑”部分和“变化”部分(也许所有小波都这样?). 比如信号[1 2 3 4 5 6 7 8] 分解后(不考虑系数): [1.5 3.5 5.5 7.5] ...
- ALGO-151_蓝桥杯_算法训练_6-2递归求二进制表示位数
记: 进制转换 AC代码: #include <stdio.h> #define K 2 int main(void) { ; scanf("%d",&n); ...