SPA 路由三部曲之核心原理
为了配合单页面 Web 应用快速发展的节奏,近几年,各类前端组件化技术栈层出不穷。通过不断的版本迭代 React、Vue 脱颖而出,成为当下最受欢迎的两大技术栈。

仅 7 个月的时间,两个技术栈的下载量就突破了百万,React 甚至突破了千万。不管是现下流行的 React、Vue,还是红极一时的 Angular、Ember,只要是单页面 Web 应用,都离不开前端路由的配合。如果把单页面 Web 应用比作一间房,每个页面对应房子中的各个房间,那么路由就是房间的门,不管房间装饰的有多漂亮,没有门,也无法展示在用户眼前,路由在单页面 Web 应用的地位也就不言而喻了。
为了能更详细的介绍前端路由,小编将从三个层面,由浅入深,一步一步的带领大家探索前端路由的实现原理。首先通过《SPA 路由三部曲之核心原理》了解前端路由的核心知识,紧接着《SPA 路由三部曲之 MyVueRouter 实践》将带领大家实现属于自己的 vue-router,最后《SPA 路由三部曲之 VueRouter 源码解析》将挑战自我,深度解析 vue-router 源码。《SPA 路由三部曲之核心原理》将从端路由的前世今生、核心原理解析、vue-router 与 react-router 应用对比三部分对前端路由进行初步了解。

前端路由前世今生
前端路由发展到今天,经历了后端路由、前后端路由过渡、前端路由的过程,如果你对前端路由的理解还是懵懵懂懂,那有必要了解一下它的发展过程。
后端路由
路由这个概念最先是在后端出现的, Web 开发还在「刀耕火种」年代时,一直是后端路由占据主导地位,页面渲染完全依赖服务器。
在最开始的时候,HTML、CSS、JavaScript 的文件以及数据载体 json(xml) 等文件都是放到后端服务器目录下的,并且这些文件彼此是没有联系的,想要改变网站的布局,可能会改上百个 HTML,繁琐且毫无技术含量。后来聪明的工程师就将相同的 HTML 整理成模板,进行复用,成功减少了前端的工作量。前端工程师开始用模板语言代替手写 HTML,后端服务器目录的文件也变成了不同的模板文件。
这个时期,不管 Web 后端是什么语言的框架,都会有一个专门开辟出来的路由模块或者路由区域,用来匹配用户给出的 URL 地址,以及一些表单提交、页面请求地址。用户进行页面切换时,浏览器发送不同的 URL 请求,服务器接收到浏览器的请求时,通过解析不同的 URL 地址进行后端路由匹配,将模板拼接好后将之返回给前端完整的 HTML,浏览器拿到这个 HTML 文件后直接解析展示了,也就是所谓的服务端渲染。

服务端渲染页面,后端有完整的 HTML 页面,爬虫更容易获取信息,有利于 SEO 优化。对于客户端的资源占用更少,尤其是移动端,可以更省电。
过渡
以后端路由为基础,开发的 Web 应用,都会存在一个弊端。每跳转到不同的 URL,都是重新访问服务端,服务器拼接形成完整的 HTML,返回到浏览器,浏览器进行页面渲染。甚至浏览器的前进、后退键都会重新访问服务器,没有合理地利用缓存。
随着前端页面复杂性越来越高,功能越来越完善,后端服务器目录下的代码文件会越来越多,耦合性也越来越严重。不仅加大服务器的压力,也不利于良好的用户体验,代码维护。受限于以 JavaScript 为代表的前端技术尚未崛起,这个痛点成了程序员的最大难题。
直到 1998 年,微软的 Outloook Web App 团队提出 Ajax 的基本概念(XMLHttpRequest 的前身),相信大家对这个技术已经非常熟悉了,浏览器实现异步加载的一种技术方案,并在 IE5 通过 ActiveX 来实现了这项技术。有了 Ajax 后,页面操作就不用每次都刷新页面,体验带来了极大的提升。
2005 年 Google Map 的发布让 Ajax 这项技术发扬光大,向人们展示了它真正的魅力,让其不仅仅局限于简单的数据和页面交互,也为后来异步交互体验方式的繁荣发展奠定了基础。2008 年,Google V8 引擎发布,JavaScript 随之崛起,前端工程师开始借鉴后端模板思想,单页面应用就此诞生。2009 年,Google 发布 Angularjs 将 MVVM 及单页面应用发扬光大,由衷的佩服 Google 的强大。
单页应用不仅在页面交互是无刷新的,连页面跳转都是无刷新的,为了配合实现单页面应用跳转,前端路由孕育而生。
前端路由
前端路由相较于后端路由的一个特点就是页面在不完全刷新的情况下进行视图的切换。页面 URL 变了,但是并没有重新加载,让用户体验更接近原生 app。
前端路由的兴起,使得页面渲染由服务器渲染变成了前端渲染。为什么这么说呢!请求一个 URL 地址时,服务器不需要拼接模板,只需返回一个 HTML 即可,一般浏览器拿到的 HTML 是这样的:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Demo</title>
<link href="app.css" rel="stylesheet"/>
</head>
<body>
<div id="app"></div>
<script type="text/javascript" src="app.js"></script>
</body>
</html>
这里空荡荡的只有一个 <div id="app"></div>,以及一系列的 js 文件,所以说这个 HTML 是不完整的。我们看到的页面是通过这一系列的 js 渲染出来的,也就是前端渲染。前端渲染通过客户端的算力来解决页面的构建,很大程度上缓解了服务端的压力。

单页面开发是趋势,但也不能避重就轻,忽略前端渲染的缺点。由于服务器没有保留完整的 HTML,通过 js 进行动态 DOM 拼接,需要耗费额外的时间,不如服务端渲染速度快,也不利于 SEO 优化。所以说,实际开发中,不能盲目选择渲染方式,一定要基于业务场景。对于没有复杂交互,SEO 要求严格的网站,服务器渲染也是正确的选择。
核心原理解析
路由描述了 URL 与 UI 之间的映射关系,这种映射是单向的,即 URL 变化引起 UI 更新(无需刷新页面)。前端路由最主要的展示方式有 2 种:
- 带有 hash 的前端路由:地址栏 URL 中有 #,即 hash 值,不好看,但兼容性高。
- 不带 hash 的前端路由:地址栏 URL 中没有 #,好看,但部分浏览器不支持,还需要后端服务器支持。
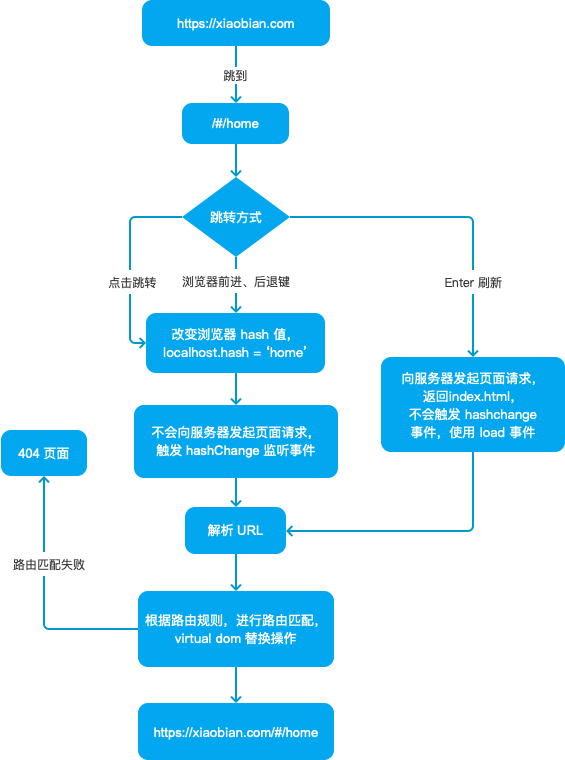
在 vue-router 和 react-router 中,这两种展示形式,被定义成两种模式,即 Hash 模式与 History 模式。前端路由实现原理很简单,本质上就是检测 URL 的变化,截获 URL 地址,通过解析、匹配路由规则实现 UI 更新。现在就跟着小编一起来揭开它神秘的面纱吧!
Hash
一个完整的 URL 包括:协议、域名、端口、虚拟目录、文件名、参数、锚。

hash 值指的是 URL 地址中的锚部分,也就是 # 后面的部分。hash 也称作锚点,是用来做页面定位的,与 hash 值对应的 DOM id 显示在可视区内。在 HTML5 的 history 新特性出现前,基本都是使用监听 hash 值来实现前端路由的。hash 值更新有以下几个特点:
- hash 值是网页的标志位,HTTP 请求不包含锚部分,对后端无影响
- 因为 HTTP 请求不包含锚部分,所以 hash 值改变时,不触发网页重载
- 改变 hash 值会改变浏览器的历史记录
- 改变 hash 值会触发 window.onhashchange() 事件
而改变 hash 值的方式有 3 种:
- a 标签使锚点值变化,例: <a href='#/home'></a>
- 通过设置 window.location.hash 的值
- 浏览器前进键(history.forword())、后退键(history.back())
综上所述,这 3 种改变 hash 值的方式,并不会导致浏览器向服务器发送请求,浏览器不发出请求,也就不会刷新页面。hash 值改变,触发全局 window 对象上的 hashchange 事件。所以 hash 模式路由就是利用 hashchange 事件监听 URL 的变化,从而进行 DOM 操作来模拟页面跳转。
History
在讲解 History 之前,大家先思考一个问题,点击浏览器左上角的回退按钮为什么能回到之前的浏览记录,点击前进按钮就能回到回退之前的浏览记录?这是因为浏览器有一个类似栈的历史记录,遵循先进后出的规则。URL 的每次改变,包括 hash 值的变化都会在浏览器中形成一条历史记录。window 对象通过 history 对象提供对览器历史记录的访问能力。
- history.length
出于安全考虑,History 对象不允许未授权代码访问历史记录中其它页面的 URLs,但可以通过 history.length 访问历史记录对象的长度。 - history.back()
回退到上一个历史记录,同浏览器后退键 - history.forward()
前进到下一个历史记录,同浏览器前进键 - history.go(n)
跳转到相应的访问记录;若 n > 0,则前进,若 n < 0,则后退,若 n = 0,则刷新当前页面
为了配合单页面的发展,HTML5 对 History API 新增的两个方法:pushState()、replaceState(),均具有操纵浏览器历史记录的能力。
history.pushState(state, title, URL)
pushState 共接收 3 个参数:
- state:用于存储该 URL 对应的状态对象,可以通过 history.state 获取
- title:标题,目前浏览器并不支持
- URL:定义新的历史 URL 记录,需要注意,新的 URL 必须与当前 URL 同源,不能跨域
pushState 函数会向浏览器的历史记录中添加一条,history.length 的值会 +1,当前浏览器的 URL 变成了新的 URL。需要注意的是:仅仅将浏览器的 URL 变成了新的 URL,页面不会加载、刷新。简单看个例子:

通过 history.pushState({ tag: "cart" }, "", "cart.html"),将 /home.html 变成 /cart.html 时,只有 URL 发生了改变,cart.html 页面并没有加载,甚至浏览器都不会去检测该路径是不是存在。这也就是证明了,pushState 在不刷新页面的情况下修改浏览器 URL 链接,单页面路由的实现也就是利用了这一个特性。
细心地童鞋应该发现了,通过 pushState 设置新的 URL 的方法与通过 window.location='#cart' 设置 hash 值改变 URL 的方法有相似之处:URL 都发生了改变,在当前文档内都创建并激活了新的历史记录条目,但页面均没有重新渲染,浏览器没有发起请求。那前者的优势又是什么呢?
- 新的 URL 可以是任意同源的 URL,而 window.location,只能通过改变 hash 值才能保证留在当前 document 中,浏览器不发起请求
- 新的 URL 可以是当前 URL,不改变,就可以创建一条新的历史记录项,而 window.location 必须设置不同的 hash 值,才能创建。假如当前URL为
/home.html#foo,使用 window.location 设置 hash 时,hash
值必须不能是#foo,才能创建新的历史记录 - 可以通过 state 参数在新的历史记录项中添加任何数据,而通过 window.location 改变 hash 的方式,只能将相关的数据转成一个很短的字符串,以 query 的形式放到 hash 值后面
- 虽然 title 参数现在还不能被所有的浏览器支持,前端发展这么快,谁能说的准之后发生的事情呢!
history.replaceState(state, title, URL)
replaceState 的使用与 pushState 非常相似,都是改变当前的 URL,页面不刷新。区别在于 replaceState 是修改了当前的历史记录项而不是新建一个,history.length 的值保持不变。

从上面的动画,我们就可以知道,通过 history.replaceState({ tag: "cart" }, "", "cart.html") 改变 URL 之前,history 的历史记录为 /classify.html、/home.html,URL 改变之后,点击浏览器后退键,直接回到了 /classify.html,跳过了 /home.html。也就证明了 replaceState 将历史记录中的 /home.html 修改为 /cart.html,而不是新建 /cart.html。
window.onpopstate()
通过 a 标签或者 window.location 进行页面跳转时,都会触发 window.onload 事件,页面完成渲染。点击浏览器的后退键或前进键,根据浏览器的不同机制,也会重新加载(Chrome 浏览器),或保留之前的页面(Safari 浏览器)。而对于通过 history.pushState() 或 history.replaceState() 改变的历史记录,点击浏览器的后退键或前进键页面是没有反应的,那该如何控制页面渲染呢?为了配合 history.pushState() 或 history.replaceState(),HTML5 还新增了一个事件,用于监听 URL 历史记录改变:window.onpopstate()。
官方对于 window.onpopstate() 事件的描述是这样的:
每当处于激活状态的历史记录条目发生变化时,popstate 事件就会在对应 window 对象上触发。 如果当前处于激活状态的历史记录条目是由 history.pushState() 方法创建,或者由 history.replaceState() 方法修改过的, 则 popstate 事件对象的 state 属性包含了这个历史记录条目的 state 对象的一个拷贝。调用 history.pushState() 或者 history.replaceState() 不会触发 popstate 事件。popstate 事件只会在浏览器某些行为下触发, 比如点击后退、前进按钮(或者在JavaScript 中调用 history.back()、history.forward()、history.go()方法),此外,a 标签的锚点也会触发该事件。
第一次读到这段话的时候似懂非懂,思考了很久,也做了很多的例子,发现其中的坑很多,这些坑主要是因为每个浏览器机制不同。官方文档对 window.onpopstate() 的描述很少,也有很多不明确的地方,根据自己的测试,来拆解一下官网描述,如果有不对的,还希望大家指出。
1.每当处于激活状态的历史记录条目发生变化时,popstate 事件就会在对应 window 对象上触发。
对这句话的理解是,在浏览器中输入一个 URL ,使其处于激活状态,不管通过哪种方式,只要 URL 改变,popstate 就会触发。但实际情况却是:只有通过 pushState 或 replaceState 改变的 URL,在点击浏览器后退键的时候才会触发,如果是通过 a 标签或 window.location 实现 URL 改变(不是改变锚点)页面跳转,在点击浏览器回退键的时候,并不会触发。对这种情况,我有两个猜测:
- popstate 事件是异步函数。由于通过 a 标签或 window.location 实现 URL 改变时,当前页面卸载,新的页面加载。由于 popstate 事件是异步的,在页面卸载之前并没来得及加载。
- 只有触发新增的 pushState 与 replaceState 改变的历史记录条目,才会触发 popstate 事件,毕竟 popstate 事件的出现是为了配合 pushState 与 replaceState。
查阅了很多资料,这两个猜测没有得到证实,但有一点可以肯定,想要监听到 popstate 事件,必须是使用 pushState 与 replaceState 改变的历史记录。
2.调用 history.pushState() 或者 history.replaceState() 不会触发 popstate 事件,popstate 事件只会浏览器的某些行为下触发。
由于各个浏览器的机制不同,测试结果也是不同的。我们先在 Chrome 浏览器下做个测试:
home.html
<div>
<h3>home html</h3>
<div id="btn" class="btn">跳转至 cart.html</div>
<a href="classify.html"> a 标签跳转至 classify.html</a>
</div>
<script>
document.getElementById('btn').addEventListener('click', function(){
history.replaceState({ tag: "cart" }, "", "cart.html")
}, false);
window.addEventListener('popstate', ()=>{
console.log('popstate home 跳转')
})
</script>
我们进行这样的操作:当前 URL 为 /home.html,通过 history.pushState({ tag: "cart" }, "", "cart.html") 将当前 URL 变成了 /cart.html。这个过程中,home.html 中的 popstate 事件确实没有触发。此时点击浏览器后退键,URL 变回了/home.html,home.html 中的 popstate 事件触发了。
那如果我们跳出 /home.html 的 document 呢?通过 history.pushState({ tag: "cart" }, "", "cart.html") 将当前 URL 变成了 /cart.html 后,点击 a 标签将 URL 变为 /classify.html。
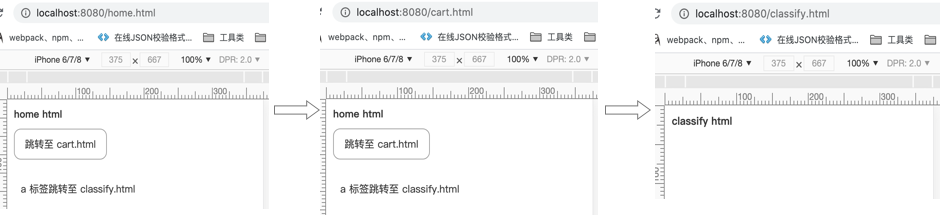
执行到这里,我们需要明确一点:a 标签改变 URL,浏览器会重新发起请求,页面发生了跳转,window 对象也发生了改变。popstate 官方文档第一句指出: popstate 事件是在对应 window 对象上触发。此时,我们点击浏览器后退键,URL 变成 /cart.html,执行 /cart.html 中的 load 事件,页面加载。再次点击浏览器后退键,URL 变为 /home.html,/cart.html 中的 popstate 事件触发,页面未渲染。

popstate 事件虽然触发了,但是是 cart.html 页面中定义的 popstate 事件,并不是 home.html 的事件。并且同样的浏览器回退键操作,在 Safari 浏览器的展示是这样的:

在浏览器回退时,Safari 浏览器与 Chrome 浏览器对于页面的加载出现了差异。classify.html 回退到 cart.html ,URL 变成了 /cart.html,但触发了 home.html 中的 popstate 事件,继续回退,URL 变成了 /home.html, 依然触发了 home.html 中 popstate 事件。
Chrome 浏览器与 Safari 浏览器差异的产生与浏览器对 popstate 事件处理有关系。至于浏览器内部是怎样处理的,小编也没有研究清楚。虽然 Chrome 浏览器与 Safari 浏览器对于 popstate 事件的处理方式不一样,但是 URL 的回退路径是一致的,完全符合历史记录后进先出的规则。
在实际开发中,这种情况也是存在的:URL 由 /home.html 到 /cart.html 的改变,就类似单页面开发中的跳转。若此时在 cart.html 中,需要使用 pushState 跳出单页面,进入登录页,用户在登录页点击浏览器回退,或移动端手势返回。上述情况就会出现,Chrome 浏览器与 Safari 浏览器渲染页面不一致。
popstate 官网描述是“popstate 事件会在对应 window 对象上触发”,注意是对应 window 对象,这个概念就比较模糊了,指的是触发 pushState 的 window 对象,还是 pushState 新定义的 window 对象。根据我们上述的测试,都有可能触发 popstate 事件。所以童鞋们,在遇到上面情况时,一定不要忘记在相关的两个页面中都要做 popstate 监听处理。
3.a 标签的锚点也可以触发 popstate 事件的方法
与 pushState 和 replaceState 不同,a 标签锚点的变化会立即触发 popstate 事件。这里我们扩展一下思路,a 标签做的事情就是改变了 hash 值,那通过 window.location 改变 hash 值是不是也是能立即触发 popstate。答案是肯定的,也会立即触发 popstate。
通过 hash 小节的了解,hash 值的改变会触发 hashchange 事件,所以,hash 值的改变会同时触发 popstate 事件与 hashchange 事件,但如果改变的 hash 值与当前 hash 值一样的话,hashchange 事件不触发,popstate 事件触发。之前我们说过,window.location 设置的 hash 值必须与当前 hash 值不一样才能新建一条历史记录,而 pushState 却可以。
结合上述,在浏览器支持 pushState 的情况下,hash 模式路由也可以使用 pushState 、replaceState 和 popstate 实现。pushstate 改变 hash 值,进行跳转,popstate 监听 hash 值的变化。小小的剧透,vue-router 中不管是 hash 模式,还是 history 模式,只要浏览器支持 history 的新特性,使用的都是 history 的新特性进行跳转。

前端路由应用
其实 history 和 hash 都是浏览器自有的特性,单页面路由只是利用了这些特性。在不跳出当前 document 的情况下,除了 history 自身的兼容性之外,各个浏览器都不会存在差异,而单页面开发就是在一个 document 中完成所有的交互,这两者的完美结合,将前端开发提升到了一个新的高度。
vue-router 和 react-router 是现在最流行的路由状态管理工具。两者实现原理虽然是一致的,但由于所依赖的技术栈不同,使用方式也略有不同。在 react 技术栈开发时,大部分的童鞋还是喜欢使用 react-router-dom ,它基于 react-router,加入了在浏览器运行环境下的一些功能。
注入方式
1. vue-router
vue-router 可以在 vue 项目中全局使用,vue.use() 功不可没。通过 vue.use(),向 VueRouter 对象注入了 Vue 实例,也就是根组件。根组件将 VueRouter 实例一层一层的向下传递,让每个渲染的子组件拥有路由功能。
import VueRouter from 'vue-router'
const routes = [
{ path: '/',name: 'home',component: Home,meta:{title:'首页'} }
]
const router = new myRouter({
mode:'history',
routes
})
Vue.use(VueRouter)
2. react-router-dom
react-router 的注入方式是在组件树顶层放一个 Router 组件,然后在组件树中散落着很多 Route 组件,顶层的 Router 组件负责分析监听 URL 的变化,在其下面的 Route 组件渲染对应的组件。在完整的单页面项目中,使用 Router 组件将根组件包裹,就能完成保证正常的路由跳转。
import { BrowserRouter as Router, Route } from 'react-router-dom';
class App extends Component {
render() {
return (
<Router>
<Route path='/' exact component={ Home }></Route>
</Router>
)
}
}
基础组件
1. vue-router 提供的组件主要有 <outer-link/> 和 <router-view/>
- <router-link/> 可以操作 DOM 直接进行跳转,定义点击后导航到哪个路径下;对应的组件内容渲染到 <router-view/> 中。
2. react-router-dom 常用到的是 <BrowserRouter/>、<HashRouter/>、<Route/>、<Link/>、<Switch/>
<BrowserRouter/>、<HashRouter/> 组件看名字就知道,用于区分路由模式,并且保证 React 项目具有页面跳转能力。
<Link /> 组件与 vue-router 中的 <router-link/> 组件类似,定义点击后的目标导航路径,对应的组件内容通过 <Route /> 进行渲染。
<Switch/> 用来将 react-router 由包容性路由转换为排他性路由,每次只要匹配成功就不会继续向下匹配。vue-router 属于排他性路由。
路由模式
1. vue-router 主要分为 hash 和 history 两种模式。在 new VueRouter() 时,通过配置路由选项 mode 实现。
Hash 模式:地址栏 URL 中有 #。vue-router 优先判断浏览器是否支持 pushState,若支持,则通过 pushState 改变 hash 值,进行目标路由匹配,渲染组件,popstate 监听浏览器操作,完成导航功能,若不支持,使用 location.hash 设置 hash 值,hashchange 监听 URL 变化完成路由导航。
History 模式:地址栏 URL 中没有 #。与 Hash 模式实现导航的思路是一样的。不同的是,vue-router 提供了 fallback 配置,当浏览器不支持 history.pushState 控制路由是否应该回退到 hash 模式。默认值为 true。
网上资料对 Hash 路由模式的原理分析大都是通过 location.hash 结合 hashchange 实现,与上述描述的 hash 路由模式的实现方式不同,这也是小编最近阅读 vue-router 源码发现的,鼓励小伙伴们读一下,肯定会收获满满!
2. react-router-dom 常用的 2 种模式是 browserHistory、hashHistory,直接用 <BrowserRouter> 或 <HashHistory> 将根组件(通常是 <App> )包裹起来就能实现。
react-router 的实现依赖 history.js,history.js 是 JavaScript 库。<BrowserRouter> 、 <HashHistory> 分别基于 history.js 的 BrowserHistory 类、HashHistory 类实现。
BrowserHistory 类通过 pushState、replaceState 和 popstate 实现,但并没有类似 vue-router 的兼容处理。HashHistory 类则是直接通过 location.hash、location.replace 和 hashchange 实现,没有优先使用 history 新特性的处理。
嵌套路由与子路由
1. vue-router 嵌套路由
在 new VueRouter() 配置路由表时,通过定义 Children 实现嵌套路由,无论第几层的路由组件,都会被渲染到父组件 <router-view/> 标识的地方。
router.js
const router = new Router({
mode:'history',
routes: [{
path: '/nest',
name: 'nest',
component: Nest,
children:[{
path:'first',
name:'first',
component:NestFirst
}]
}]
})
nest.vue
<div class="nest">
一级路由 <router-view></router-view>
</div>
first.vue
<div class="nest">
二级路由 <router-view></router-view>
</div>
在 /nest 下设置了二级路由 /first,二级对应的组件渲染在一级路由匹配的组件 <router-view/> 标识的地方。在配置子路由时,path 只需要是当前路径即可。

2. react-router 子路由
react-router 根组件会被渲染到 <Router/> 指定的位置,子路由则会作为子组件,由父组件指定该对象的渲染位置。如果想要实现上述 vue-router 嵌套的效果,需要这样设置:
route.js
const Route = () => (
<HashRouter>
<Switch>
<Route path="/nest" component={Nest}/>
</Switch>
</HashRouter>
);
nest.js
export default class Nest extends Component {
render() {
return (
<div className="nest">
一级路由
<Switch>
<Route path="/nest/first" component={NestFirst}/>
</Switch>
</div>
)
}
}
first.js
export default class NestFirst extends Component {
render() {
return (
<div className="nest">
二级路由
<Switch>
<Route exact path="/nest/first/second" component={NestSecond}/>
</Switch>
</div>
)
}
}
其中,/nest 为一级路由,/fitst 二级路由匹配的组件,作为一级路由的子组件。react-router 定义子路由 path 时,需要写完整的路径,即父路由的路径要完整。
路由守卫
1. vue-router 导航守卫分为全局守卫、路由独享守卫、组件内的守卫三种。主要用来通过跳转或取消的方式守卫导航。
a. 全局守卫
- beforeEach — 全局前置钩子(每个路由调用前都会触发,根据 from 和 to 来判断是哪个路由触发)
- beforeResolve — 全局解析钩子(和 router.beforeEach 类似,区别是在导航被确认之前,同时在所有组件内守卫和异步路由组件被解析之后,解析守卫就被调用)
- afterEach — 全局后置钩子
b. 路由独享守卫
- 路由配置上可以直接定义 beforeEnter 守卫。
c. 组件内守卫
- beforeRouteEnter — 在渲染该组件的对应路由被 confirm 前调用,不能获取组件实例
this,因为当守卫执行前,组件实例还没被创建。 - beforeRouteUpdate — 当前路由改变,但是该组件被复用时调用
- beforeRouteLeave — 导航离开该组件的对应路由时调用
2. react-router 4.0 版本之前,提供了 onEnter 和 onLeave 钩子,实现类似 vue-router 导航守卫的功能,但 4.0 版本后取消了该方法。
路由信息
1. vue-router 中 $router、$route 对象
vue-router 在注册时,为每个 vue 实例注入了 $router、$route 对象。$router 为 router 实例信息,利用 push 和 replace 方法实现路由跳转,$route 提供当前激活的路由信息。
import router from './router'
export default new Vue({
el: '#app',
router,
render: h => h(App),
})
2. react-router 中 history、location 对象
在每个由 <Route/> 包裹的组件中提供了 history、location 对象。利用 this.props.history 的 push、replace 方法实现路由导航,this.props.location 获取当前激活的路由信息。
const BasicRoute = () => (
<div>
<HeaderNav></HeaderNav>
<HashRouter>
<Switch>
<Route exact path="/" component={Home}/>
</Switch>
</HashRouter>
</div>
);
如果想要获得 history、location 一定是 <Route /> 包裹的组件。所以在 <HeaderNav/> 中是无法获取这两个对象的,而 <Home/> 组件是可以的。
vue-router 是全局配置方式,react-router 是全局组件方式,但两者呈现给开发者的功能实际上是大同小异的。当然,vue-router 与 react-router 在使用上的差异不仅仅是小编说的这些。说到底,不管用什么样的方式实现,前端路由的实现原理都是不会变的。
总结
前端路由的初步体验马上就要结束了,在决定深入研究前端路由之前,小编自信满满,感觉应该不会花费很大的精力与时间,可事实是,涉及到的知识盲区越来越多,信心在逐渐瓦解。好在结局不错,收获了很多,也希望《SPA 路由三部曲之核心原理》这篇文章能让大家有所收获,哪怕只是一个知识点。
小编已经在争分夺秒的准备《SPA 路由三部曲之 MyVueRouter 实践》、《SPA 路由三部曲之 VueRouter 源码解析》过程中了,小编相信是不会让你失望的,请充满期待吧!
PS:文章中有些是个人观点,如果不对,欢迎交流、指正!
SPA 路由三部曲之核心原理的更多相关文章
- ASP.NET Core的路由[2]:路由系统的核心对象——Router
ASP.NET Core应用中的路由机制实现在RouterMiddleware中间件中,它的目的在于通过路由解析为请求找到一个匹配的处理器,同时将请求携带的数据以路由参数的形式解析出来供后续请求处理流 ...
- 路由系统的核心对象——Router
路由系统的核心对象--Router ASP.NET Core应用中的路由机制实现在RouterMiddleware中间件中,它的目的在于通过路由解析为请求找到一个匹配的处理器,同时将请求携带的数据以路 ...
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
- 深入解析Koa之核心原理
这篇文章主要介绍了玩转Koa之核心原理分析,本文从封装创建应用程序函数.扩展res和req.中间件实现原理.异常处理的等这几个方面来介绍,写的十分的全面细致,具有一定的参考价值,对此有需要的朋友可以参 ...
- 30个类手写Spring核心原理之动态数据源切换(8)
本文节选自<Spring 5核心原理> 阅读本文之前,请先阅读以下内容: 30个类手写Spring核心原理之自定义ORM(上)(6) 30个类手写Spring核心原理之自定义ORM(下)( ...
- 「进阶篇」Vue Router 核心原理解析
前言 此篇为进阶篇,希望读者有 Vue.js,Vue Router 的使用经验,并对 Vue.js 核心原理有简单了解: 不会大篇幅手撕源码,会贴最核心的源码,对应的官方仓库源码地址会放到超上,可以配 ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- docker核心原理
容器概念. docker是一种容器,应用沙箱机制实现虚拟化.能在一台宿主机里面独立多个虚拟环境,互不影响.在这个容器里面可以运行着我饿们的业务,输入输出.可以和宿主机交互. 使用方法. 拉取镜像 do ...
- HDFS 核心原理
HDFS 核心原理 2016-01-11 杜亦舒 HDFS(Hadoop Distribute File System)是一个分布式文件系统文件系统是操作系统提供的磁盘空间管理服务,只需要我们指定把文 ...
随机推荐
- 多测师讲解selenium _a标签定位()_高级讲师肖sir
shift+ctrl+c 快捷键 调出元素
- Java9系列第三篇-同一个Jar支持多JDK版本运行
我计划在后续的一段时间内,写一系列关于java 9的文章,虽然java 9 不像Java 8或者Java 11那样的核心java版本,但是还是有很多的特性值得关注.期待您能关注我,我将把java 9 ...
- 【C语言程序设计】小游戏之俄罗斯方块(一)!适合初学者上手、练手!
俄罗斯方块的核心玩法非常简单,所以制作起来并不是很复杂,我准备先用2篇文字的篇幅详细讲解一下俄罗斯方块的制作方法. 今天咱们算是第一篇,主要讲解俄罗斯方块中如何定义方块,以及如何实现方块的移动.旋转. ...
- 【水】怎么在 HZOI 上水到更高的分
前言 这些东西在联赛并用不了 预编译优化 40行优化 #define _CRT_SECURE_NO_WARNINGS #pragma GCC optimize(2) #pragma GCC optim ...
- 【贪心算法】HDU 5747 Aaronson
题目大意 vjudge链接 给你一个n,m,求解满足等式x0+2x1+4x2+...+2mxm=n的x0~xm的最小和(xi为非负整数) 数据范围 0≤n,m≤109 思路 n和m都在int范围内,所 ...
- kafka-消费者测试
1. 在窗口1创建一个producer,topic为test,broker-list为zookeeper集群ip+端口 /usr/local/kafka/bin/kafka-console-pro ...
- swoole协程通道channel
swoole 协程通道 为了协程直接互相通讯传递数据 和go的通道很相似 Co\run(function(){ $chan = new Swoole\Coroutine\Channel(1); Swo ...
- Qlik Sense学习笔记之插件开发
date: 2019-05-06 13:18:45 updated: 2019-08-09 15:18:45 Qlik Sense学习笔记之插件开发 1.开发前的基础工作 1.1 新建插件 dev-h ...
- Java基础之字面值
概要:什么是字面值 字面值是指在程序中无需变量保存,可直接表示为一个具体的数字或字符串的值.比如在a = b * 2这个语句中,2就是一个字面值,它本身就是一个具体的值. 在Java源代码中,字面值用 ...
- Navicat连接Mysql8.0.17出现1251错误 / 或者Navicat Premium出现2059错误
Navicat连接Mysql8.0.17出现1251错误 重装了电脑之后,好多软件出了问题,经过一系列的插件安装,mysql终于安装好了 但是Navicat又抽筋了~~~额(⊙o⊙)... 在网上查的 ...