Ⅰ Introduction to Reinforcement Learning
Dictum:
To spark, often burst in hard stone. -- William Liebknecht
强化学习(Reinforcement Learning)是模仿人类的学习方式(比如,学习一种新的技能,从入门到掌握总是不断地去寻错,改正,直至完全掌握),强化学习的主要思想就是智能体在与环境的交互过程中不断调整,以达到理想结果。
强化学习的框架
Reinforcement learning is learning what to do--how to map situations to actions--so as to maximize a numerical reward signal.
强化学习的流程如下图所示,智能体首先洞悉环境的当前状态,再根据状态做出相应的动作,环境会根据动作给出反馈到智能体,此时环境也会做出相应改变,智能体通过得到的反馈和改变后的状态进行做出下一次的动作,如此迭代,最后达到最优效果。
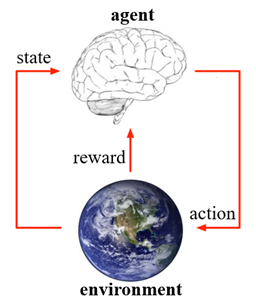
智能体(agent)是学习者和决策者,它能在某种程度上感知环境的状态,然后采取动作并影响环境的状态。
环境(environment)是强化学习问题中,除智能体以外与智能体交互的所有集合。
强化学习的特点
强化学习两个最重要的特征就是“试错搜索(trial-and-error search)”和“延迟奖励(delayed reward)"。智能体不会被告知选择什么动作是最好的,而是需要通过尝试去发现哪些动作获得最大的奖励,而所执行的动作不但影响即时奖励,还可能使状态发生改变从而影响未来的奖励。因此,这给强化学习带来了一个独特的挑战:更新策略的过程是在探索(exploration)和开发(exploitation)之间权衡完成的。为了获得更多的奖励,智能体需要不断优化已经尝试过的动作,同时为了选取最优的动作,智能体还需要不断去尝试新的动作。强化学习还有一个特点,就是它需要明确考虑目标导向型智能体与不确定性环境交互的整体问题。
强化学习的要素
上面框图展示了最简单的强化学习架构的三个基本要素,下面将具体讲述强化学习的几种要素的定义和作用:
- 状态(state),\(S_t\),表示环境在\(t\)时刻所处的状态\(s\)
- 动作(action),\(A_t\),表示智能体在\(t\)时刻采取的动作\(a\)
- 策略(policy),\(\pi(a|s)\),表示智能体在给定时间(状态)下采取的行为方式,是环境状态到动作的映射,一般是随机函数,它是智能体的核心
- 奖励信号(reward signal),定义了强化学问题的目标,即环境会在每一个时间步长给智能体发送被称为“奖励(reward)”的标量信号,\(R_t\),它表示对智能体当前所执行策略的短期判断,而价值函数则是对智能体当前所执行的长期判断
- 环境模型(model of the environment),它是对外部环境运作规则的推断,它被用于规划(即在真正经历之前,先考虑未来所有可能的情况做出预先的决策)。强化学习的方法被分为两种:基于模型(model-based)的方法和不基于模型(model-free)的方法--基于模型方法是通过模型和规划解决实际问题,而无模型方法则通过试错的方式学习
与其它学习方式的比较
区别于监督学习,监督学习是从外部监督者给出的带标签样本的训练集中学习,标签的实质就是先验知识,事先会告诉学习器什么是对什么是错,而强化学习只有奖励值,这与监督学习的输出不同,它是延迟给出的,这导致了智能体必须能够从自身的经验中学习。
区别于无监督学习,无监督学习是从无标签数据集中寻找隐藏的相似结构,无监督学习没有输出值,只有数据特征,而强化学习的目的是最大化奖励信号。
监督学习和无监督学习,它们的样本数据一般都是相互独立的,而强化学习每个时间步长得到的序列是迭代更新的,数据间的关联十分紧密。
References
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction (Second Edition). 2018.
Csaba Szepesvári. Algorithms for Reinforcement Learning. 2009.
Course: UCL Reinforcement Learning Course (by David Silver)
Ⅰ Introduction to Reinforcement Learning的更多相关文章
- 强化学习一:Introduction Of Reinforcement Learning
引言: 最近和实验室的老师做项目要用到强化学习的有关内容,就开始学习强化学习的相关内容了.也不想让自己学习的内容荒废掉,所以想在博客里面记载下来,方便后面复习,也方便和大家交流. 一.强化学习是什么? ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
- Introduction to Learning to Trade with Reinforcement Learning
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/ The academic ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- (转)Applications of Reinforcement Learning in Real World
Applications of Reinforcement Learning in Real World 2018-08-05 18:58:04 This blog is copied from: h ...
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- 强化学习 reinforcement learning: An Introduction 第一章, tic-and-toc 代码示例 (结构重建版,注释版)
强化学习入门最经典的数据估计就是那个大名鼎鼎的 reinforcement learning: An Introduction 了, 最近在看这本书,第一章中给出了一个例子用来说明什么是强化学习, ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- Reinforcement Learning: An Introduction读书笔记(3)--finite MDPs
> 目 录 < Agent–Environment Interface Goals and Rewards Returns and Episodes Policies and Val ...
随机推荐
- Docker实战(6): 导出docker镜像离线包
前言 离线环境安装Docker 镜像,我已知两种情况,以下操作我将采用在可访问外网的机器上通过镜像迁移的方式来给离线环境安装. 环境:服务器node1可访问外网.服务器node2无法访问外网 两台机器 ...
- Git+Gitlab+Ansible的roles实现一键部署Nginx静态网站(4)
前言 截止目前已经写了<Ansible基础认识及安装使用详解(一)–技术流ken>,<Ansible常用模块介绍及使用(二)–技术流ken><Ansible剧本介绍及使用 ...
- Redis详细使用及结合SpringBoot
今天咱来聊一下Redis五种数据类型的详细用法以及在代码中如何使用.废话不多说,开始! Redis五种数据类型: string:字符串对象 list:列表对象 hash:散列 set:集合 zset: ...
- Eclipse安装AmaterasUML插件问题
为了画UML图,我想在Eclipse(版本Version: Oxygen Release (4.7.0))安装AmaterasUML,第一步,安装GEF - http://download.eclip ...
- J.U.C之Executor框架入门指引
1.Executor接口 This interface provides a way of decoupling task submission from the mechanics of how e ...
- 滴滴开源AgileTC:敏捷测试用例管理平台
桔妹导读:AgileTC是一套敏捷的测试用例管理平台,支持测试用例管理.执行计划管理.进度计算.多人实时协同等能力,方便测试人员对用例进行管理和沉淀.产品以脑图方式编辑可快速上手,用例关联需求形成流 ...
- JVM学习(六)JVM常见知识问答
文章更新时间:2020/04/21 1.什么是Java虚拟机?为什么Java被称作是"平台无关的编程语言"? Java虚拟机是一个可以执行Java字节码的虚拟机进程. Java源文 ...
- pwnable.kr-shellshock-witeup
思路是:发现文件执行没什么好反馈显示结果的,于是看文件和权限,通过bash文件猜测可能存在破壳漏洞(CVE-2014-6271)漏洞,于是利用它并结合文件权限成功获得flag. 通过scp下载文件至本 ...
- DVWA从注入到GETSHELL
好好过你的生活,不要老是忙着告诉别人你在干嘛. 最近在复习学过的东西,自己就重新搭了个dvwa来学习新思路,写一些简单的脚本来练习写代码的能力. 众所周知SQL注入的危害是相当大的,对于每个老司机来说 ...
- SSRF漏洞(原理、漏洞利用、修复建议)
介绍SSRF漏洞 SSRF (Server-Side Request Forgery,服务器端请求伪造)是一种由攻击者构造请求,由服务端发起请求的安全漏洞.一般情况下,SSRF攻击的目标是外网无法访问 ...