关于 JMeter 5.4.1 的一点记录
APACHE JMeter
table { border: 0; border-collapse: collapse; background-color: rgba(255, 245, 218, 1) }
thead tr { border-bottom: 2px solid rgba(255, 198, 0, 1) }
th { font-weight: bold; text-align: left }
th, td { padding: 10px 0 }
Version: 5.4.1
采样器
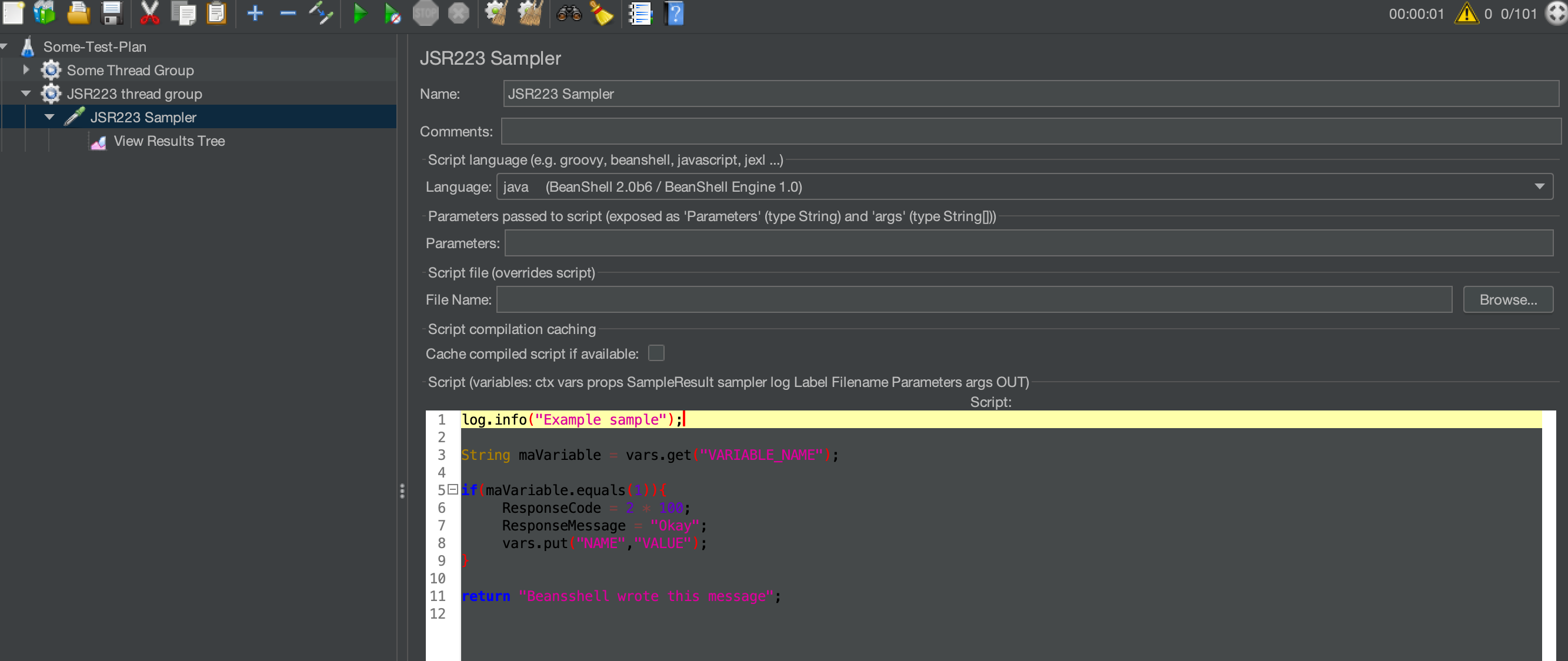
JSR223
JSR是Java Specification Requests的缩写,意思是Java规范提案.是指向JCP(Java Community Process)提出新增一个标准化技术规范的正式请求.任何人或组织都可以向JCP提交JSR,以向Java平台增添新的API和服务.JSR已成为Java界的一个重要标准.
JSR223定义了可集成在Java平台上运行的一系列脚本语言.比如Groovy,JavaScript等.
JSR223 采样器允许脚本用于样本执行或一些创建/更新变量必须的计算。
当采样器运行时,如果你不需要生成样本结果,调用以下方法:
SampleResult.setIgnore();
这个调用会产生以下影响:
- 样本结果不会传输到样本监听器,比如:查看结果树(View Results Tree)、统计描述(Summariser)等
- 样本结果也不会在断言(Assertions)和后置处理器(PostProcessors)中评估
- 样本结果将会用于评估样本最后的的状态(${JMeterThread.last_sample_ok}),并且线程组“采取采样器错误的措施”(自 JMeter 5.4 起)
JSR223 测试元素有一个特性(编译),它可以显著提升性能。要从这个特性中获取好处:
使用脚本文件代替内嵌它们。这将使 JMeter 编译并缓存它们,如果这个特性适用于脚本引擎(ScriptEngine)。
或使用脚本文本并检查
Cache compiled script if available(缓存编译过的脚本如果可用)属性。当使用这个特性时,确保你的脚本代码没有使用 JMeter 变量或者 JMeter 函数调用,因为缓存只会缓存第一次替换。使用脚本参数代替。要从缓存和编译中获得好处,使用的脚本语言引擎必须实现 JSR 223 编译接口(Groovy 是其中之一,beanshell 和 javascript 不是)当使用 Groovy 做为脚本语言并且不检查Cache compiled script if available(推荐使用缓存),你应该设置 JVM 属性 -Dgroovy.use.calssvalue=true 因为 Groovy 2.4.6 版本内存泄漏,查看:
缓存大小通过 JMeter 属性控制(jmeter.properties):
jsr223.compiled_scripts_cache_size=100
props.get("START.HMS");
props.put("PROP1","1234");
| 参数 | ||
|---|---|---|
| 属性 | 描述 | 必填 |
| Name(名称) | 采样器在树中的展示描述 | No |
| Scrpiting Language(脚本语言) | 使用的 JSR223 脚本语言名称 | Yes |
| 不止在下拉列表中显示的语言支持。如果合适的 jar 包安装在 JMeter lib 文件夹下,则有可能适用。注意有的语言比如 Velocity 可能对 JSR223 变量使用不同的语法,例如:
$log.debug("Hello " + $vars.get("a")); |
||
| Script File(脚本文件) | 用于 JSR223 脚本的文件名,如果使用相对地址,那么它将通过"user.dir"系统特性关联到文件夹 | No |
| Parameters(参数) | 传递到脚本文件或者脚本的参数集合 | No |
| Cache compiled script id available(缓存编译过的脚本如果可用) | 如果选中(建议选中)并且语言支持编译接口(Groovy 是其中之一,java、beanshell和 javascript 不是),JMeter 将会编译脚本并使用缓存,脚本的 MD5 哈希值做为存储主键 | No |
| Script(脚本) | 传到 JSR223 语言的脚本 | Yes(除非提供脚本文件) |
如果支持脚本文件,那么优先使用脚本文件,否则使用脚本。
调用脚本前,一些变量会装配。注意有 JSR223 变量 - 例如:它们可以直接用于脚本。
- log - 日志工具
- Label - 采样器标签
- FileName - 文件名,如果有的话
- Parameters - 从参数字段获取的文本
- args - 参数,如上所述拆分
- SampleResult - 指向当前样本结果
- sampler - (Sampler) - 指向当前采样器
- ctx - JMeterContext
- ctx - JMeterVariables - 例如:
vars.get("VAR1");
vars.put("VAR2","value");
vars.remove("VAR3");
vars.putObject("OBJ1",new Object());
- props - JMeter属性(类 java.util.Properties)
props.get("START.HMS");
props.put("PROP1","1234");
- OUT - System.out - 例如:OUT.println("message")
样本结果 响应数据设置来自脚本的返回结果。如果脚本返回 null ,它可以,通过使用方法 SampleResult.setResponseData(data) 直接设置响应,返回数据类型要么是 String 要么是 byte 数组。返回数据类型默认“text”,但是可以通过方法SampleResult.setDataType(SampleResult.BINARY)设置二进制。
样本结果变量给予脚本所有字段和方法的访问权。例如,脚本有权限访问方法setStopThread(boolean) 和 setStopTest(boolean)。
不同于 BeanShell 采样器, JSR223 采样器不设置 ResponseCode,ReponseMessage 并且样本状态借助于脚本变量。当前修改这些数据唯一的办法是通过样本结果方法:
- SampleResult.setSuccessful(true/false)
- SampleResult.setResponseCode("code")
- SampleResult.setResponseMessage("message")
Best Practices (最佳实践)
设置正确的线程数量
除了硬件性能,测试计划(Test Plan)设计也同样会影响 JMeter 运行有效线程数量。线程数量还将依赖你的服务速度(更快的服务器使 JMeter 工作更快,因为服务器响应更快)。与任何负载测试(Load Testing)工具一样,如果不恰当的设置线程数量,你将面临“协调遗漏(Coordinated Omission)”问题,它会给你错误或不精确的结果。如果你需要大规模负载测试,考虑在多个机器上使用分布式模式(或者不用)运行多个 CLI JMeter 实例。当使用分布式模式时,结果文件在控制器节点(Controller node)中组合,如果使用多个自主实例,样本结果可以组合起来以供后续分析。为了测试 JMeter 如何在给定的平台上执行,可以使用 JavaTest 采样器。它不需要任何网络访问,因此可以对最大可达吞吐量给出一些头绪。
JMeter 有延迟线程创建的选择,直到线程开始采样。例如:在任何线程组延迟和线程自身启动(ramp-up)时间。这将允许对于一个很大的总线程数量,具有不同时激活太多的能力。
如何设置正确的线程数量
- 最大线程数量依赖于
- 运行 JMeter 的机器的功率
- JVM 32位还是64位
- JVM 分配的最大堆大小 -Xmx
- 测试计划(大量的 beanshell 脚本、前置处理器等意味着消耗更多的 CPU)
- 操作系统配置
- GUI/NON-GUI 模式
所以没有一个理论能直接得到最大线程数量。
- 设置正确的线程数量
- 多次设置不同线程数量,观察吞吐量,找出合适的线程数量
Aggregate Report(聚合报告)
聚合报告在你的测试中为每个不同命名的请求在表格中创建一行。它为每个请求汇总返回信息并提供请求次数、最短时间(同一个样本,ms)、最长时间(同一个样本,ms)、平均时间(结果集中的平均时间,ms)、错误率(请求错误比例)、近似吞吐率(请求/秒)和每秒 KB 吞吐量。一旦完成测试,吞吐量是整个测试期间的真实吞吐量。
吞吐量是从采样器目标的角度计算的(例如:在 HTTP 样本情况下的远程服务器)。JMeter 把生成请求的时间算入总时间。如果其它采样器和计时器在同一个线程中,他们将会增加总时间,并因此减少吞吐量。所以两个完全相同不同名字的采样器相对两个有相同名字的采样器只有一半的吞吐量。要从聚合报告中获取最佳结果,选择正确的采样器名字很重要。
计算中位数和 90% Line(第90百分位)值需要额外的内存。JMeter 现在通过相同的消耗时间联合样本,到目前为止,它使用的内存更少。然而,对于超过几秒钟的样本,可能只有少数样本有相同的时间,这种情况下需要消耗更多的内存。注意,之后您可以使用此侦听器重新加载CSV或XML结果文件,这是避免对性能造成影响的推荐方法。
从 JMeter 2.12 开始,你可以配置 3 个你要计算的百分比值,可以通过设置属性完成:
- aggregate_rpt_pct1:默认 第 90 区间
- aggregate_rpt_pct2:默认 第 95 区间
- aggregate_rpt_pct3:默认 第 99 区间
- Label - 样本的标签。如果选中 "Include group name in label?",那么线程组的名称会做为前缀加到标签中。这样,可以根据需要分别整理来自不同线程组的相同标签。
Samples - 具有相同标签的的样本数量
- Average - 一个结果集中的平均时间
- Median - 中位数是结果集中的中间数。 50% 的样本花费不超过这个时间;剩余的至少花费了一样的时间。
- 90% Line - 百分之 90 的样本花费不超过这个时间。剩余的样本至少花费了一样的时间。(第 90 百分位)
- 95% Line - 百分之 95 的样本花费不超过这个时间。剩余的样本至少花费了一样的时间。(第 95 百分位)
- 99% Line - 百分之 99 的样本花费不超过这个时间。剩余的样本至少花费了一样的时间。(第 99 百分位)
- Min - 同一个标签里样本的最短时间
- Max - 同一个标签里样本的最长时间
- Error % - 错误请求百分比
- Throughput - 吞吐量用与测量每秒钟/分钟/小时的请求数。时间单位是选择的所以显示比例至少是 1.0。当吞吐量保存到 CSV 文件时,它通过 请求数/秒 表示,例如:30.0 请求数/分 保存为 0.5 请求数/秒。
- Recieved KB/sec - 吞吐量测量每秒接收到的 KB 数
- Sent KB/sec - 吞吐量测量每秒发送的 KB 数
时间以毫秒为单位。
| Label | # Samples | Average | Median | 90% Line | 95% Line | 99% Line | Min | Max | Error % | Throughput | Received KB/sec | Sent KB/sec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Http Request - 1 | 200 | 303 | 259 | 489 | 673 | 986 | 147 | 1069 | 0.000% | 0.09529 | 0.02 | 0.02 |
| Http Request - 2 | 100 | 229 | 222 | 288 | 319 | 358 | 143 | 381 | 0.000% | 81.63265 | 18.46 | 18.73 |
| Http Request - 3 | 100 | 225 | 194 | 324 | 440 | 506 | 146 | 677 | 0.000% | 85.91065 | 20.42 | 19.72 |
| TOTAL | 400 | 265 | 226 | 392 | 496 | 882 | 143 | 1069 | 0.000% | 0.17941 | 0.04 | 0.04 |
术语表
中位数 是一个把样本分为两等份的数字。一半样本小于中位数,另一半比中位数大。【有的样本可能等于中位数。】这是一个标准的统计学测量。中位数和第 50 百分位是相同的。
90% Line 第 90 百分位是低于 90% 样本的值。剩余的样本至少和这个值一样长。这个一个标准的统计学测量。
关于 JMeter 5.4.1 的一点记录的更多相关文章
- 关于Java8:StreamAPI的一点记录
关于 Stream ,Functional Interface 的一点记录 stream对于集合操作的便捷度提升: import java.util.ArrayList; import java.ut ...
- JMeter 关于JMeter 正则表达式提取器的一点研究
关于JMeter 正则表达式提取器的一点研究 by:授客 QQ:1033553122 1. 实验环境: JMeter 2.13 2. 添加正则表达式提取器 右键线程组->添加-> ...
- 对Integer类中的私有IntegerCache缓存类的一点记录
对Integer类中的私有IntegerCache缓存类的一点记录 // Integer类有内部缓存,存贮着-128 到 127. // 所以,每个使用这些数字的变量都指向同一个缓存数据 // 因此可 ...
- 从symbol link和hard link 到 unlink函数的一点记录
之前一直对Linux的文件类型中的 “l” 类型的了解不是很深入,最近经过“圣经”指点,略知一二,在此先记录一下,以便以后查阅,之后会对文件和目录.文件I/O这部分再扩充. 首先需明确,Unix在查阅 ...
- 关于删除MySQL Logs的一点记录
五一前,一个DBA同事反馈,在日常环境中删除一个大的slow log文件(假设文件大小10G以上吧),然后在MySQL中执行flush slow logs,会发现mysqld hang住. 今天尝试着 ...
- 关于类属性值校验的一点记录 【知识点Attribute】
好久没有进来了,之前励志坚持写博客,记录自己在做代码搬运工这段历程中点滴,可是仅仅只坚持了几天,就放弃了!果然是,世上无难事,只要肯放弃!哈哈……闲话不多说,开始进入正题,给自己留点笔记,避免将来老了 ...
- 【.Net】关于内存缓存的一点记录
引言 最近看了内存缓存的一些介绍和用法,在此做个简单记录. MemoryCache 类 MemoryCache 类是.Net 4.0推出的类库,主要是为了方便在Winform和Wpf中构建缓存框架的. ...
- 关于db2的一点记录
近期听搞db2的兄弟说:db2数据库软件的license 不区分平台(os). 先记下来.像db2这么高大上的软件,接触的机会是比較少的. 另外:db2 的license是须要打的,不打的话,超过一段 ...
- Nodejs Promise的一点记录
项目需要,看了点nodejs,其中比较难理解的就是Promise了,记录一下学习bluebird提供的Promise实现. Promise.promisifyAll(obj)方法 作用:把对象的方法属 ...
随机推荐
- java.awt.event.MouseEvent鼠标事件的定义和使用 以及 Java Swing-JTextArea的使用
最近发现一个CSDN大佬写的Java-Swing全部组件的介绍:Java Swing 图形界面开发(目录) JTextArea 文本区域.JTextArea 用来编辑多行的文本.JTextArea 除 ...
- java swing JDialog 和 java.util.concurrent的使用
参考链接: Java-Swing的JFrame的一些插件使用详解 java swing JDialog 使用 ScheduledExecutorService定时周期执行指定的任务 swing JDi ...
- uva10891 Game of Sum(博弈+区间dp+优化)
题目:点击打开链接 题意:两个人做游戏,共有n个数,每个人可以任选一端取任意多连续的数,问两个人都想拿最多的情况下,先手最多比后手多拿多少分数. 思路:这题一开始想到的是用dp[i][j]表示区间[i ...
- hdu 6806 Equal Sentences 找规律
题意: 给你一个有n个单词的单词串S,对这n个单词进行排列组合形成新的一个单词串T,如果在S中任意某个单词所在位置,和这个单词在T中所在位置之差的绝对值小于等于1,那么就说S和T串相等 让你求S一共有 ...
- 迪杰斯特拉+拆点 Deliver the Cake - HDU 6805
题意: t组输入,给你n个点m条边.你需要输出从s点到t点的最短距离,然后是m条边,每条边输入信息为: a,b,c 表示从a点到b点的一个无向边长度为c 每一个点会有一个属性L.R或M 如果a和b一个 ...
- 2019 Multi-University Training Contest 5——permutation 2
传送门 题意: t组输入,之后每组例子有三个数n.x.y代表在一个以x为开头y为结尾的长为n的数组里面,开头和结尾数据已经固定,让你从1--n中找其他数据填入数组中 (每个数据不能重复使用),使它满足 ...
- httpclient几种请求方式
一.httpclient 模拟get请求,并获取cookie信息 public class MyCookiesForGet { private String url; //用来读取.propertie ...
- Linunx系统引导过程及MBR/GRUB故障
Linunx系统引导过程 系统初始化进程 init进程 Systemd Systemd单元类型 允许级别所对应的systemd目标 修复MBR扇区故障 解决思路 操作 修复GRUB引导故障 解决思路 ...
- 1005E1 Median on Segments (Permutations Edition) 【思维+无序数组求中位数】
题目:戳这里 百度之星初赛原题:戳这里 题意:n个不同的数,求中位数为m的区间有多少个. 解题思路: 此题的中位数就是个数为奇数的数组中,小于m的数和大于m的数一样多,个数为偶数的数组中,小于m的数比 ...
- Commons Collections2分析
0x01.POC分析 //创建一个CtClass对象的容器 ClassPool classPool=ClassPool.getDefault(); //添加AbstractTranslet的搜索路径 ...