JUnit5学习之七:参数化测试(Parameterized Tests)进阶
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
关于《JUnit5学习》系列
《JUnit5学习》系列旨在通过实战提升SpringBoot环境下的单元测试技能,一共八篇文章,链接如下:
- 基本操作
- Assumptions类
- Assertions类
- 按条件执行
- 标签(Tag)和自定义注解
- 参数化测试(Parameterized Tests)基础
- 参数化测试(Parameterized Tests)进阶
- 综合进阶(终篇)
本篇概览
- 本文是《JUnit5学习》系列的第七篇,前文咱们对JUnit5的参数化测试(Parameterized Tests)有了基本了解,可以使用各种数据源控制测试方法多次执行,今天要在此基础上更加深入,掌握参数化测试的一些高级功能,解决实际问题;
- 本文由以下章节组成:
- 自定义数据源
- 参数转换
- 多字段聚合
- 多字段转对象
- 测试执行名称自定义
源码下载
- 如果您不想编码,可以在GitHub下载所有源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
- 这个git项目中有多个文件夹,本章的应用在junitpractice文件夹下,如下图红框所示:
- junitpractice是父子结构的工程,本篇的代码在parameterized子工程中,如下图:
自定义数据源
- 前文使用了很多种数据源,如果您对它们的各种限制不满意,想要做更彻底的个性化定制,可以开发ArgumentsProvider接口的实现类,并使用@ArgumentsSource指定;
- 举个例子,先开发ArgumentsProvider的实现类MyArgumentsProvider.java:
package com.bolingcavalry.parameterized.service.impl;
import org.junit.jupiter.api.extension.ExtensionContext;
import org.junit.jupiter.params.provider.Arguments;
import org.junit.jupiter.params.provider.ArgumentsProvider;
import java.util.stream.Stream;
public class MyArgumentsProvider implements ArgumentsProvider {
@Override
public Stream<? extends Arguments> provideArguments(ExtensionContext context) throws Exception {
return Stream.of("apple4", "banana4").map(Arguments::of);
}
}
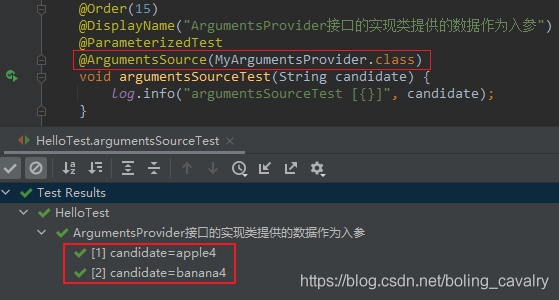
- 再给测试方法添加@ArgumentsSource,并指定MyArgumentsProvider:
@Order(15)
@DisplayName("ArgumentsProvider接口的实现类提供的数据作为入参")
@ParameterizedTest
@ArgumentsSource(MyArgumentsProvider.class)
void argumentsSourceTest(String candidate) {
log.info("argumentsSourceTest [{}]", candidate);
}
- 执行结果如下:
参数转换
- 参数化测试的数据源和测试方法入参的数据类型必须要保持一致吗?其实JUnit5并没有严格要求,而事实上JUnit5是可以做一些自动或手动的类型转换的;
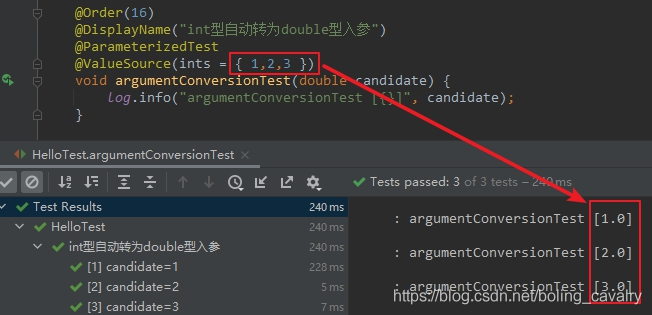
- 如下代码,数据源是int型数组,但测试方法的入参却是double:
@Order(16)
@DisplayName("int型自动转为double型入参")
@ParameterizedTest
@ValueSource(ints = { 1,2,3 })
void argumentConversionTest(double candidate) {
log.info("argumentConversionTest [{}]", candidate);
}
- 执行结果如下,可见int型被转为double型传给测试方法(Widening Conversion):
- 还可以指定转换器,以转换器的逻辑进行转换,下面这个例子就是将字符串转为LocalDate类型,关键是@JavaTimeConversionPattern:
@Order(17)
@DisplayName("string型,指定转换器,转为LocalDate型入参")
@ParameterizedTest
@ValueSource(strings = { "01.01.2017", "31.12.2017" })
void argumentConversionWithConverterTest(
@JavaTimeConversionPattern("dd.MM.yyyy") LocalDate candidate) {
log.info("argumentConversionWithConverterTest [{}]", candidate);
}
- 执行结果如下:

字段聚合(Argument Aggregation)
- 来思考一个问题:如果数据源的每条记录有多个字段,测试方法如何才能使用这些字段呢?
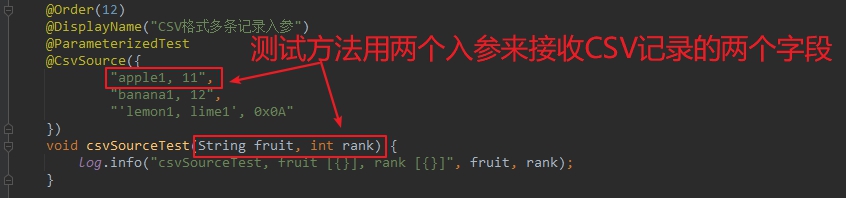
- 回顾刚才的@CsvSource示例,如下图,可见测试方法用两个入参对应CSV每条记录的两个字段,如下所示:
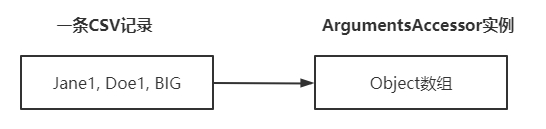
3. 上述方式应对少量字段还可以,但如果CSV每条记录有很多字段,那测试方法岂不是要定义大量入参?这显然不合适,此时可以考虑JUnit5提供的字段聚合功能(Argument Aggregation),也就是将CSV每条记录的所有字段都放入一个ArgumentsAccessor类型的对象中,测试方法只要声明ArgumentsAccessor类型作为入参,就能在方法内部取得CSV记录的所有字段,效果如下图,可见CSV字段实际上是保存在ArgumentsAccessor实例内部的一个Object数组中:
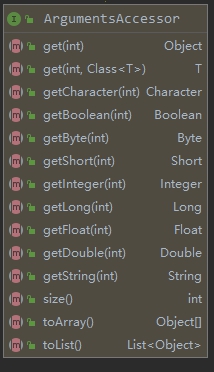
4. 如下图,为了方便从ArgumentsAccessor实例获取数据,ArgumentsAccessor提供了获取各种类型的方法,您可以按实际情况选用:
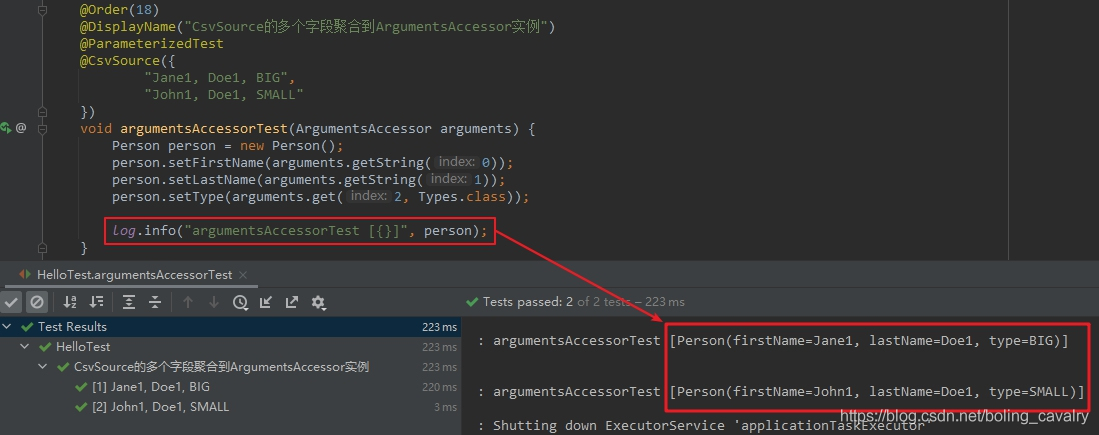
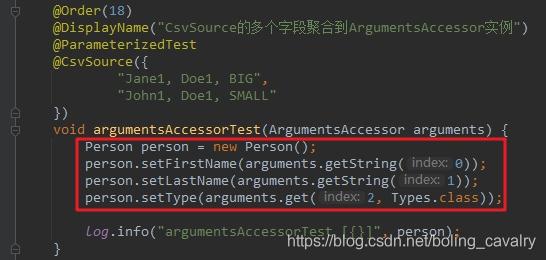
- 下面的示例代码中,CSV数据源的每条记录有三个字段,而测试方法只有一个入参,类型是ArgumentsAccessor,在测试方法内部,可以用ArgumentsAccessor的getString、get等方法获取CSV记录的不同字段,例如arguments.getString(0)就是获取第一个字段,得到的结果是字符串类型,而arguments.get(2, Types.class)的意思是获取第二个字段,并且转成了Type.class类型:
@Order(18)
@DisplayName("CsvSource的多个字段聚合到ArgumentsAccessor实例")
@ParameterizedTest
@CsvSource({
"Jane1, Doe1, BIG",
"John1, Doe1, SMALL"
})
void argumentsAccessorTest(ArgumentsAccessor arguments) {
Person person = new Person();
person.setFirstName(arguments.getString(0));
person.setLastName(arguments.getString(1));
person.setType(arguments.get(2, Types.class));
log.info("argumentsAccessorTest [{}]", person);
}
- 上述代码执行结果如下图,可见通过ArgumentsAccessor能够取得CSV数据的所有字段:
更优雅的聚合
- 前面的聚合解决了获取CSV数据多个字段的问题,但依然有瑕疵:从ArgumentsAccessor获取数据生成Person实例的代码写在了测试方法中,如下图红框所示,测试方法中应该只有单元测试的逻辑,而创建Person实例的代码放在这里显然并不合适:
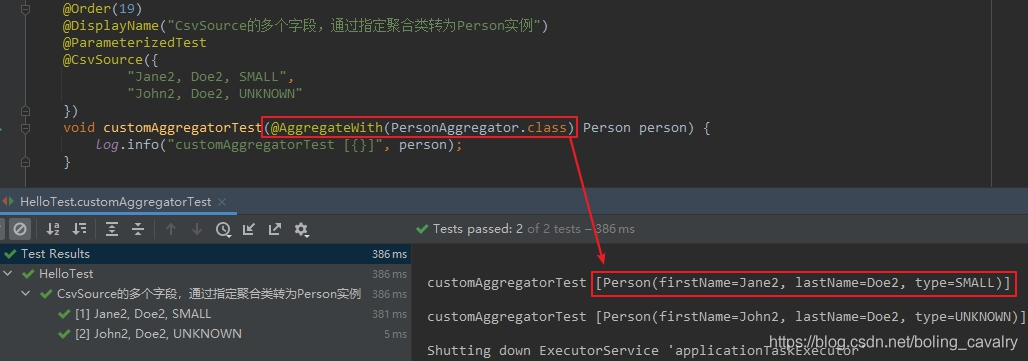
2. 针对上面的问题,JUnit5也给出了方案:通过注解的方式,指定一个从ArgumentsAccessor到Person的转换器,示例如下,可见测试方法的入参有个注解@AggregateWith,其值PersonAggregator.class就是从ArgumentsAccessor到Person的转换器,而入参已经从前面的ArgumentsAccessor变成了Person:
@Order(19)
@DisplayName("CsvSource的多个字段,通过指定聚合类转为Person实例")
@ParameterizedTest
@CsvSource({
"Jane2, Doe2, SMALL",
"John2, Doe2, UNKNOWN"
})
void customAggregatorTest(@AggregateWith(PersonAggregator.class) Person person) {
log.info("customAggregatorTest [{}]", person);
}
- PersonAggregator是转换器类,需要实现ArgumentsAggregator接口,具体的实现代码很简单,也就是从ArgumentsAccessor示例获取字段创建Person对象的操作:
package com.bolingcavalry.parameterized.service.impl;
import org.junit.jupiter.api.extension.ParameterContext;
import org.junit.jupiter.params.aggregator.ArgumentsAccessor;
import org.junit.jupiter.params.aggregator.ArgumentsAggregationException;
import org.junit.jupiter.params.aggregator.ArgumentsAggregator;
public class PersonAggregator implements ArgumentsAggregator {
@Override
public Object aggregateArguments(ArgumentsAccessor arguments, ParameterContext context) throws ArgumentsAggregationException {
Person person = new Person();
person.setFirstName(arguments.getString(0));
person.setLastName(arguments.getString(1));
person.setType(arguments.get(2, Types.class));
return person;
}
}
- 上述测试方法的执行结果如下:
进一步简化
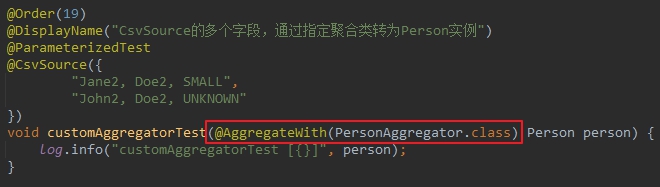
- 回顾一下刚才用注解指定转换器的代码,如下图红框所示,您是否回忆起JUnit5支持自定义注解这一茬,咱们来把红框部分的代码再简化一下:
2. 新建注解类CsvToPerson.java,代码如下,非常简单,就是把上图红框中的@AggregateWith(PersonAggregator.class)搬过来了:
package com.bolingcavalry.parameterized.service.impl;
import org.junit.jupiter.params.aggregator.AggregateWith;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.PARAMETER)
@AggregateWith(PersonAggregator.class)
public @interface CsvToPerson {
}
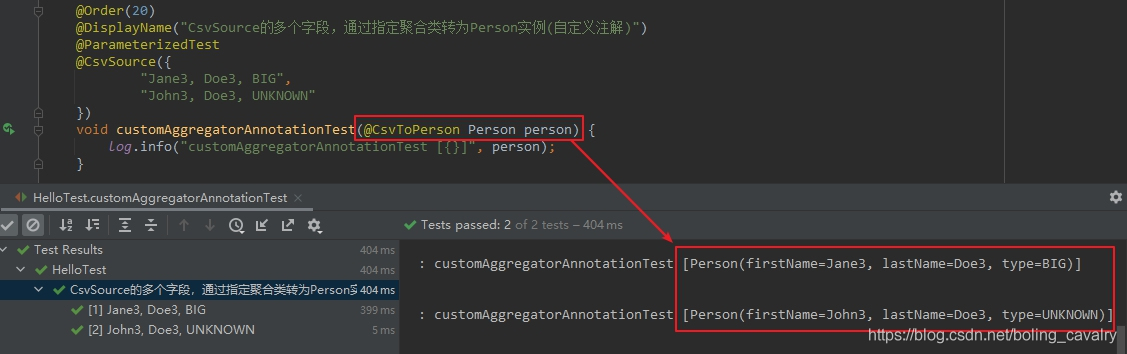
- 再来看看上图红框中的代码可以简化成什么样子,直接用@CsvToPerson就可以将ArgumentsAccessor转为Person对象了:
@Order(20)
@DisplayName("CsvSource的多个字段,通过指定聚合类转为Person实例(自定义注解)")
@ParameterizedTest
@CsvSource({
"Jane3, Doe3, BIG",
"John3, Doe3, UNKNOWN"
})
void customAggregatorAnnotationTest(@CsvToPerson Person person) {
log.info("customAggregatorAnnotationTest [{}]", person);
}
- 执行结果如下,可见和@AggregateWith(PersonAggregator.class)效果一致:
测试执行名称自定义
- 文章最后,咱们来看个轻松的知识点吧,如下图红框所示,每次执行测试方法,IDEA都会展示这次执行的序号和参数值:
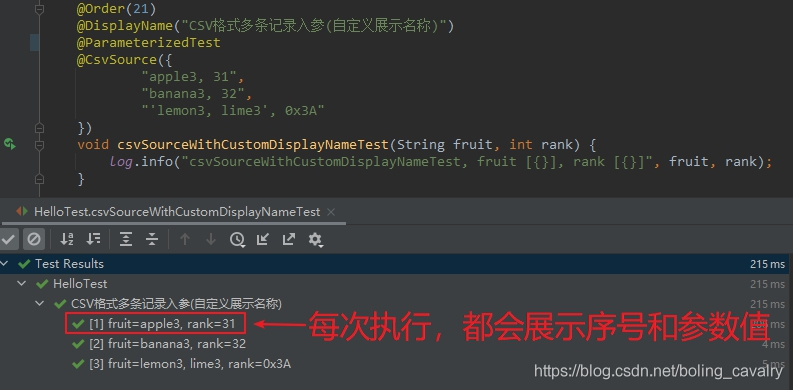
- 其实上述红框中的内容格式也可以定制,格式模板就是@ParameterizedTest的name属性,修改后的测试方法完整代码如下,可见这里改成了中文描述信息:
@Order(21)
@DisplayName("CSV格式多条记录入参(自定义展示名称)")
@ParameterizedTest(name = "序号 [{index}],fruit参数 [{0}],rank参数 [{1}]")
@CsvSource({
"apple3, 31",
"banana3, 32",
"'lemon3, lime3', 0x3A"
})
void csvSourceWithCustomDisplayNameTest(String fruit, int rank) {
log.info("csvSourceWithCustomDisplayNameTest, fruit [{}], rank [{}]", fruit, rank);
}
- 执行结果如下:
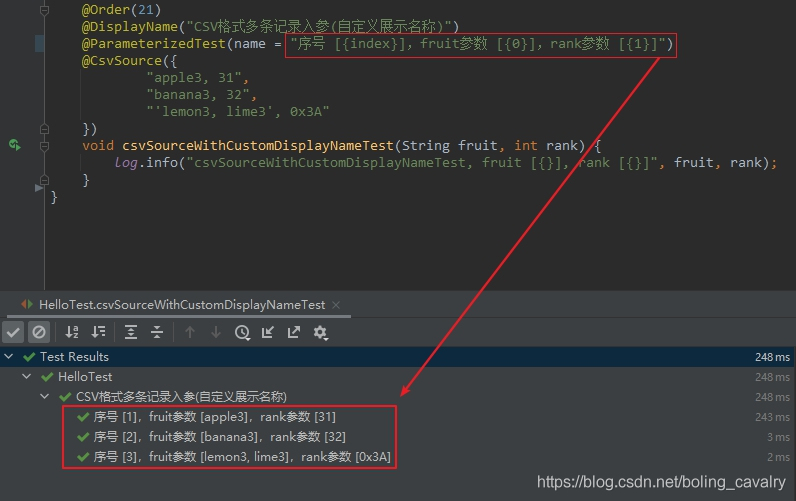
- 至此,JUnit5的参数化测试(Parameterized)相关的知识点已经学习和实战完成了,掌握了这么强大的参数输入技术,咱们的单元测试的代码覆盖率和场景范围又可以进一步提升了;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
JUnit5学习之七:参数化测试(Parameterized Tests)进阶的更多相关文章
- JUnit5学习之六:参数化测试(Parameterized Tests)基础
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Junit5中实现参数化测试
从Junit5开始,对参数化测试支持进行了大幅度的改进和提升.下面我们就一起来详细看看Junit5参数化测试的方法. 部署和依赖 和Junit4相比,Junit5框架更多在向测试平台演进.其核心组成也 ...
- JUnit5学习之八:综合进阶(终篇)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- JUnit5学习之一:基本操作
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- JUnit5学习之二:Assumptions类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- JUnit5学习之三:Assertions类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- JUnit5学习之四:按条件执行
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- JUnit5学习之五:标签(Tag)和自定义注解
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- JUnit5参数化测试的几种方式
参数化测试一直是津津乐道的话题,我们都知道JMeter有四种参数化方式:用户自定义变量.用户参数.CSV文件.函数助手,那么JUnit5有哪些参数化测试的方式呢? 依赖 JUnit5需要添加junit ...
随机推荐
- 力扣643.子数组最大平均数I-C语言实现
题目 给定 n 个整数,找出平均数最大且长度为 k 的连续子数组,并输出该最大平均数. 示例: 输入:[1,12,-5,-6,50,3], k = 4 输出:12.75 解释:最大平均数 (12-5- ...
- Grakn Forces 2020
比赛链接:https://codeforces.com/contest/1408 A. Circle Coloring 题意 给出三个长为 $n$ 的序列 $a,b,c$,对于每个 $i$,$a_i ...
- Educational Codeforces Round 20
Educational Codeforces Round 20 A. Maximal Binary Matrix 直接从上到下从左到右填,注意只剩一个要填的位置的情况 view code //#pr ...
- hdu 4315 Climbing the Hill && poj 1704 Georgia and Bob阶梯博弈--尼姆博弈
参考博客 先讲一下Georgia and Bob: 题意: 给你一排球的位置(全部在x轴上操作),你要把他们都移动到0位置,每次至少走一步且不能超过他前面(下标小)的那个球,谁不能操作谁就输了 题解: ...
- tju3243 Blocked Road
There are N seaside villages on X island, numbered from 1 to N. N roads are built to connect all of ...
- Pyqt5 安装
window 安装PyQt5 pip install pyqt5 pip install pyqt5-tools (安装常用的Qt工具) 添加环境变量 变量名: QT_QPA_PLATFORM_PL ...
- Detect the Virus ZOJ - 3430 AC自动机
One day, Nobita found that his computer is extremely slow. After several hours' work, he finally fou ...
- DDL 数据定义语言
目录 创建数据库(CREATE) 删除数据库(DROP) 修改数据库(ALTER) 创建数据表(CREATE) 数据表的数据属性 数据类型属性(Type) 其他属性(Null,Key,Default, ...
- VS常用命令
1.查看Windows文件首部信息 dumpbin/headers 项目名称. 例如:dumpbin/headers test.exe 2.查看CLR首部信息 dumpbin/clrheader 项目 ...
- woj1016 cherry blossom woj1017 Billiard ball 几何
title: woj1016 cherry blossom date: 2020-03-18 20:00:00 categories: acm tags: [acm,几何,woj] 几何题,判断给出的 ...