数据结构中的树(二叉树、二叉搜索树、AVL树)
树的概念
树(英语:tree)是一种抽象数据类型(ADT)或是实作这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
每个节点有零个或多个子节点;
没有父节点的节点称为根节点;
每一个非根节点有且只有一个父节点;
除了根节点外,每个子节点可以分为多个不相交的子树;
节点的度:一个节点含有的子树的个数称为该节点的度;
树的度:一棵树中,最大的节点的度称为树的度;
叶节点或终端节点:度为零的节点;
父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次;
堂兄弟节点:父节点在同一层的节点互为堂兄弟;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
森林:由m(m>=0)棵互不相交的树的集合称为森林;
二叉树
每个节点最多含有两个子树的树称为二叉树
- 平衡二叉树(AVG树): 当且仅当任何节点的两棵子树的高度差不大于1的二叉树
- 完全二叉树: 对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树;
- 排序二叉树: (二叉查找数 Binary Search Tree), 也称二叉搜索树,有序二叉树,任意一个结点左边子节点的数据要比根结点的值小,右边子节点的数据要比根结点的值大。但是如果二叉树是单增的情况会退化成链表
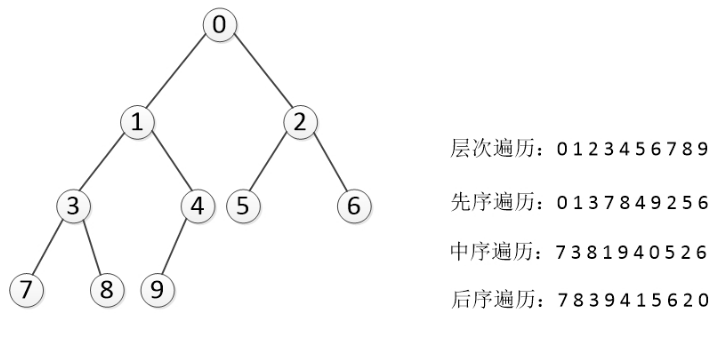
二叉树的遍历
- 深度优先遍历
- 先序遍历 preorder 在先序遍历中,我们先访问根节点,然后递归使用先序遍历访问左子树,再递归使用先序遍历访问右子树 根节点->左子树->右子树
- 中序遍历 inorder 在中序遍历中,我们递归使用中序遍历访问左子树,然后访问根节点,最后再递归使用中序遍历访问右子树 左子树->根节点->右子树
- 后序遍历 postorder 在后序遍历中,我们先递归使用后序遍历访问左子树和右子树,最后访问根节点 左子树->右子树->根节点
 )
)
- 广度优先遍历(层次遍历)
二叉树反推
如果已知中序和先序,或者中序和后序,可以确定二叉树的结构
eg:
先序:A B C D E F
中序: C B A E D F
先序找根,中序定两边
先序遍历序列为ABCDEF,第一个字母是A被打印出来,就说明A是根结点的数据。
再由中序遍历序列是CBAEDF,可以知道C和B是A的左子树的结点,
E、D、F是A的右子树的结点
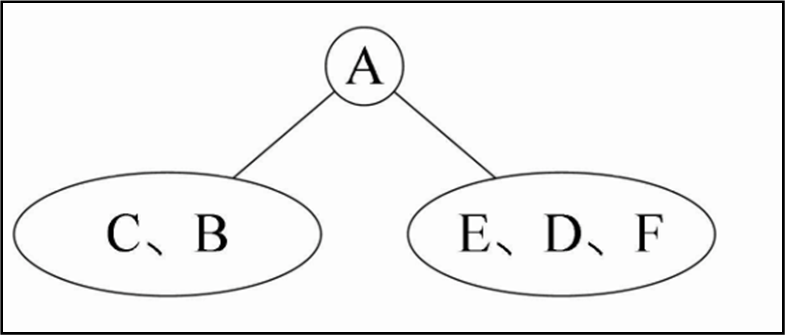
然后我们看先序中的C和B,它的顺序是ABCDEF,B是在C的前面打印,所以B应该是A的左孩子,而C就只能是B的孩子,此时是左还是右孩子还不确定。再看中序序列是CBAEDF,C是在B的前面打印,这就说明C是B的左孩子,否则就是右孩子了
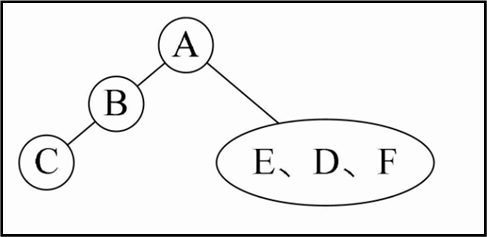
再看先序中的E、D、F,它的顺序是ABCDEF,那就意味着D是A结点的右孩子,E和F是D的子孙,注意,它们中有一个不一定是孩子,还有可能是孙子的。再来看中序序列是CBAEDF,由于E在D的左侧,而F在右侧,所以可以确定E是D的左孩子,F是D的右孩子
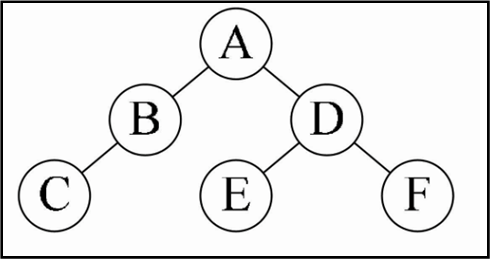
注:如果已经先序和后序无法判断二叉树结构
先序序列:ABC
后序序列:CBA
我们可以确定A一定是根结点,但接下来,我们无法知道,哪个结点是左子树,哪个是右子树
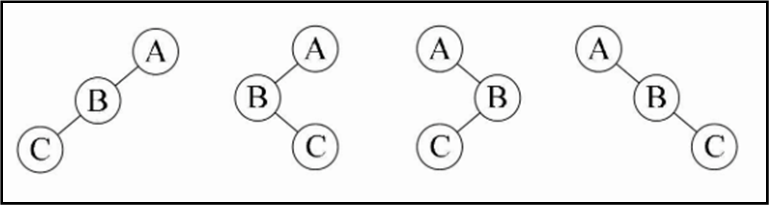
二叉查找树(二叉搜索树)
节点的左子树只包含小于当前节点的数。
节点的右子树只包含大于当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树
参考以下两篇文章(最好是自己画图容易理解):
二叉平衡树
Python实现平衡二叉树 删除和添加调整的是最小不平衡子树
平衡二叉树 (Height-Balanced Binary Search Tree) 是一种二叉排序树,
其中每一个结点的左子树和右子树的高度差不超过1(小于等于1)
二叉树的平衡因子 (Balance Factor) 等于该结点的左子树深度减去右子树深度的值称为平衡因子。平衡因子只可能是[-1,0,1]。距离插入结点最近的,且平衡因子的绝对值大于1的结点为根的子树,称为最小不平衡子树
平衡二叉树就是二叉树的构建过程中,每当插入一个结点,看是不是因为树的插入破坏了树的平衡性,若是,则找出最小不平衡树。在保持二叉树特性的前提下,调整最小不平衡子树中各个结点之间的链接关系,进行相应的旋转,使之成为新的平衡子树。简记为: 步步调整,步步平衡
参考以下两篇文章(最好是自己画图):
注:第一篇文章中针对左右失衡和右左失衡的处理图片和代码中有误,但是主要是看个人理解,作者可以只对根节点进行失衡处理,而我这边是按照第二篇文章说的,调整最小不平衡子树
对于其中添加元素的递归代码的理解:

霍夫曼树
(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树;
应用: 压缩文件
B树(B-Tree)
一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。B树是多路平衡查找树,2阶B树才是平衡二叉树
应用: 数据库存储
M阶的Btree的几个重要特性:
- 节点最多含有m棵字树(指针), m-1个关键字(存的数据,空间)(m > 2)
- 除根节点和叶子节点外,其他每个节点至少有ceil(m / 2)个子节点,(ceil为上取整)
- 若根节点不是叶子节点,则至少有两棵子树
M阶: 这个由磁盘的页大小决定,页内存是4KB, 好处是一次性取数据就可以取出这个节点即这个页数据,不会造成IO读取的浪费。

B+Tree
- 每个节点最多有m个子节点
- 除根节点外,每个节点至少有m/2个子节点,注意如果结果除不尽,就取上蒸,如 5/2=3
- 根节点要么是空,要么是独根,否则至少有2个子节点
- 有k个子节点的节点必有k个关键字
- 叶节点的高度一致
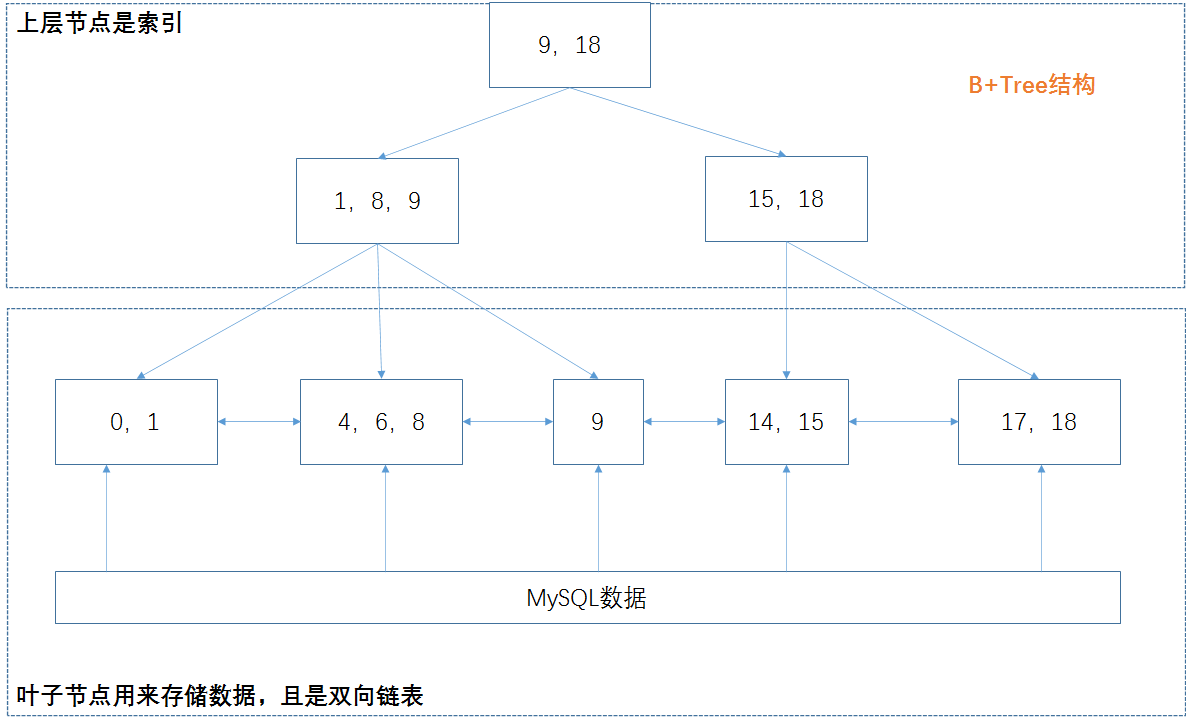

适合大数据的磁盘索引,经典的MySQL,所有的数据都存在叶子节点,其他上层节点都是索引,增加了系统的稳定性以及遍历查找效率。叶子节点之间是双向指针,这一点就有利于范围查找。
MyISAM存储引擎的数据结构(非聚集)
索引文件和数据文件是分离的,非聚集(非聚族)
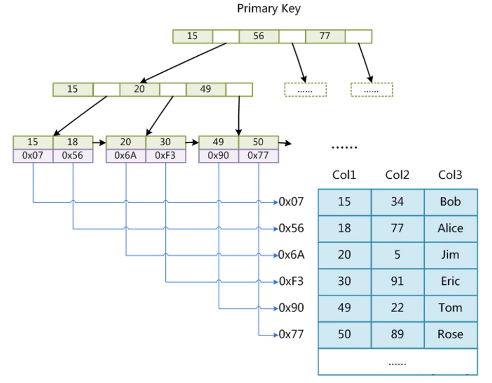
.MYD 存储数据的文件
.MYI 存储索引的文件
.FRM 表结构文件,管理索引和数据的框架
InnoDB索引的实现(聚集)
- 表数据本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶子节点包含了完整的数据记录,索引跟数据合并,MySQL默认节点大小为16KB,所以说高度为3的B+树就能够存储千万级别的数据。
- 为什么InnoDB表必须有主键,并且推荐使用整形的自增主键?
- 整形存储占用比较少,且比较容易,如果是uuid字符串还需要进行转换且占用空间大
- 使用自增是为了避免二叉树的频繁自平衡分裂,自增主键,只需要每次都忘后面增加即可,不会造成大范围的性能开销
- 为什么非主键索引结构叶子节点存储的是主键值?(一直性)
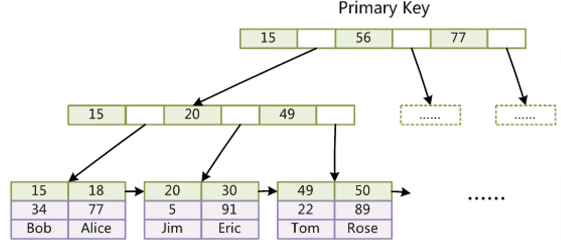
联合索引的底层存储结构
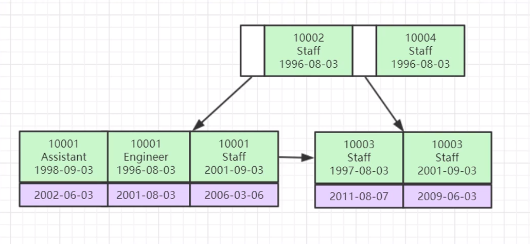
常见树的应用场景
- xml,html等,那么编写这些东西的解析器的时候,不可避免用到树
- 路由协议就是使用了树的算法
- mysql数据库索引
- 文件系统的目录结构
- 所以很多经典的AI算法其实都是树搜索,此外机器学习中的decision tree也是树结构
数据结构中的树(二叉树、二叉搜索树、AVL树)的更多相关文章
- 树-二叉搜索树-AVL树
树-二叉搜索树-AVL树 树 树的基本概念 节点的度:节点的儿子数 树的度:Max{节点的度} 节点的高度:节点到各叶节点的最大路径长度 树的高度:根节点的高度 节点的深度(层数):根节点到该节点的路 ...
- 树&二叉树&二叉搜索树
树&二叉树 树是由节点和边构成,储存元素的集合.节点分根节点.父节点和子节点的概念. 二叉树binary tree,则加了"二叉"(binary),意思是在树中作区分.每个 ...
- 高度平衡的二叉搜索树(AVL树)
AVL树的基本概念 AVL树是一种高度平衡的(height balanced)二叉搜索树:对每一个结点x,x的左子树与右子树的高度差(平衡因子)至多为1. 有人也许要问:为什么要有AVL树呢?它有什么 ...
- 树(二叉树 & 二叉搜索树 & 哈夫曼树 & 字典树)
树:n(n>=0)个节点的有限集.有且只有一个root,子树的个数没有限制但互不相交.结点拥有的子树个数就是该结点的度(Degree).度为0的是叶结点,除根结点和叶结点,其他的是内部结点.结点 ...
- 【数据结构与算法Python版学习笔记】树——平衡二叉搜索树(AVL树)
定义 能够在key插入时一直保持平衡的二叉查找树: AVL树 利用AVL树实现ADT Map, 基本上与BST的实现相同,不同之处仅在于二叉树的生成与维护过程 平衡因子 AVL树的实现中, 需要对每个 ...
- HDU 3179 二叉搜索树(树的建立)
二叉搜索树 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submi ...
- 看动画学算法之:平衡二叉搜索树AVL Tree
目录 简介 AVL的特性 AVL的构建 AVL的搜索 AVL的插入 AVL的删除 简介 平衡二叉搜索树是一种特殊的二叉搜索树.为什么会有平衡二叉搜索树呢? 考虑一下二叉搜索树的特殊情况,如果一个二叉搜 ...
- (4) 二叉平衡树, AVL树
1.为什么要有平衡二叉树? 上一节我们讲了一般的二叉查找树, 其期望深度为O(log2n), 其各操作的时间复杂度O(log2n)同时也是由此决定的.但是在某些情况下(如在插入的序列是有序的时候), ...
- 查找树ADT——二叉搜索树
在以下讨论中,虽然任意复杂的关键字都是允许的,但为了简单起见,假设它们都是整数,并且所有的关键字是互异的. 总概 使二叉树成为二叉查找树的性质是,对于树中的每个节点X,它的左子树中所有关键字值小于 ...
- 树·二叉查找树ADT(二叉搜索树/排序树)
1.定义 对于每个节点X,它的左子树中所有的项的值小于X的值,右子树所有项的值大于X的值. 如图:任意一个节点,都满足定义,其左子树的所有值小于它,右子树的所有值大于它. 2.平均深度 在大O模型中, ...
随机推荐
- 一道题理解setTimeout,Promise,async/await以及宏任务与微任务
今天看到这样一道面试题: //请写出输出内容 async function async1() { console.log('async1 start'); await async2(); consol ...
- 递归实现DropDownList层级
.NET下拉框DropDownList层级实现 这也算是第一篇博客吧,技术比较菜,写得不好,希望各位博友见谅哈,多多提提意见. 今天做电商网站新闻添加的时候,下拉框选择新闻类别觉得太长,又无法定位其准 ...
- 数据可视化之DAX篇(十九)值得你深入了解的函数:SUMMARIZE
https://zhuanlan.zhihu.com/p/66424209 SUMMARIZE函数非常强大,掌握以后表面上看也非常好用,所以我专门写篇文章介绍一下这个函数,至于是否一定要使用该函数,请 ...
- redis(十五):Redis 有序集合(sorted set)(python)
#coding:utf8 import redis r =redis.Redis(host="23.226.74.190",port=63279,password="66 ...
- Python之协程、异步IO、redis缓存、rabbitMQ队列
本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitMQ队列 Redis\Memcached缓存 Paramiko SS ...
- Spring Boot 2.3.0正式发布:优雅停机、配置文件位置通配符新特性一览
当大潮退去,才知道谁在裸泳..关注公众号[BAT的乌托邦]开启专栏式学习,拒绝浅尝辄止.本文 https://www.yourbatman.cn 已收录,里面一并有Spring技术栈.MyBatis. ...
- 你真的清楚DateTime in C#吗?
DateTime,就是一个世界的大融合. 日期和时间,在我们开发中非常重要.DateTime在C#中,专门用来表达和处理日期和时间. 本文算是多年使用DateTime的一个总结,包括DateTim ...
- jmeter 及测试(转载)
负载测试:在一定的工作负荷下,给系统造成的负荷及系统响应的时间. 压力测试:在一定的负荷条件下,长时间连续运行系统给系统性能造成的影响. 1.性能测试(Performance Test):通常收集 ...
- scss : div水平垂直居中
scss 是一个很好用的css预处理语言,有很多很好的特性. 比如 mixin. 我们可以像使用函数那样使用mixin. 比如写一个div水平垂直居中. 上代码. @mixin absolute_ce ...
- SQL语句 查询最新记录
要求:SQL语句按ID以最新时间查询最新的一条记录 方法1: select * from (select *, ROW_NUMBER() over(partition by id order by u ...