Armv8-A Memory management
本文介绍Armv8-A的内存管理。内存管理指的是在系统中,内存访问是如何实现的。
使用内存管理机制,可以让每个应用之间的内存地址分离,即sandbox application,也可以让多个在物理内存上碎片化的地址形成虚拟地址空间一个连续的地址,同时可以让程序员编程更为方便。
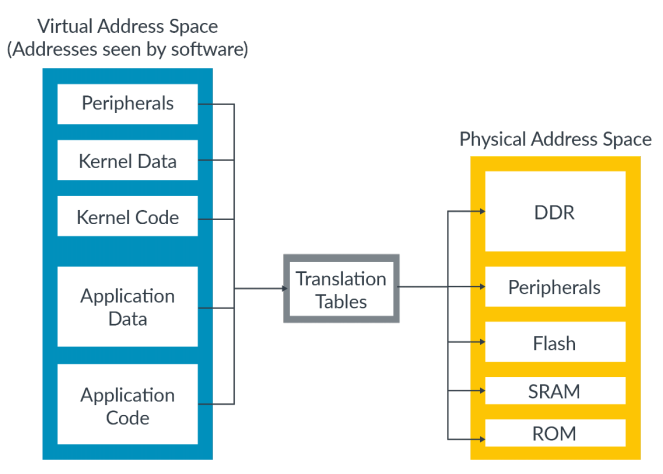
虚拟地址到物理地址的转换通过mapping的方式来进行,其关键为Translation tables,存储在memory中,并且被OS或者hypervisor来管理。
Memory Management Unit(MMU)
虚拟地址到物理地址的translation由MMU来执行,其包含两个部分:
- The table walk unit, which contains logic that reads the translation tables from memory.
- Translation Lookaside Buffers (TLBs), which cache recently used translations ,是被映射的地址,而不是地址对应的内容。
当一个虚拟地址来临的时候,MMU先是查找TLBs,看是否有cached translation,如果没有,那么table walk unit就memory中读取对应的table entry或者table entries(大块内存可能就需要多个entry)
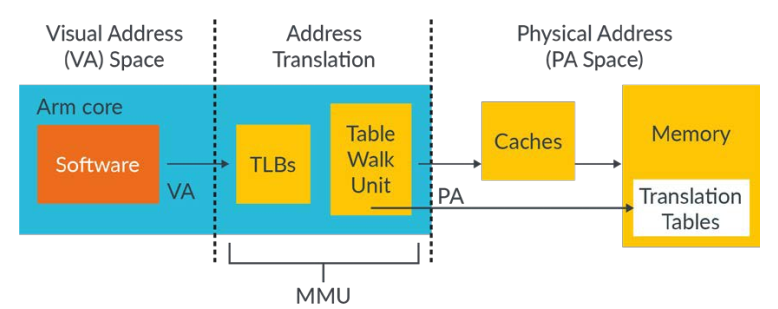
Table entry
translation tabls通过把整个虚拟地址空间划分为多个大小相同的block/page,然后每个page对应一个entry。
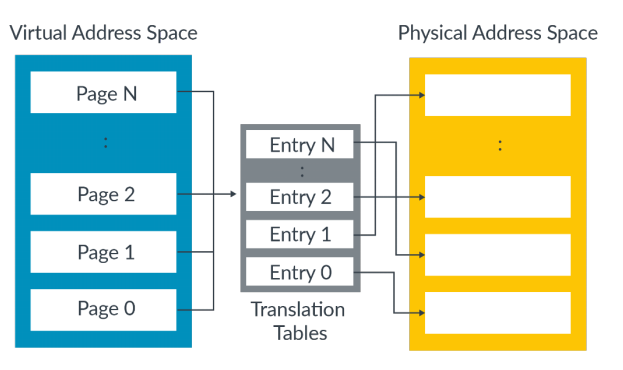
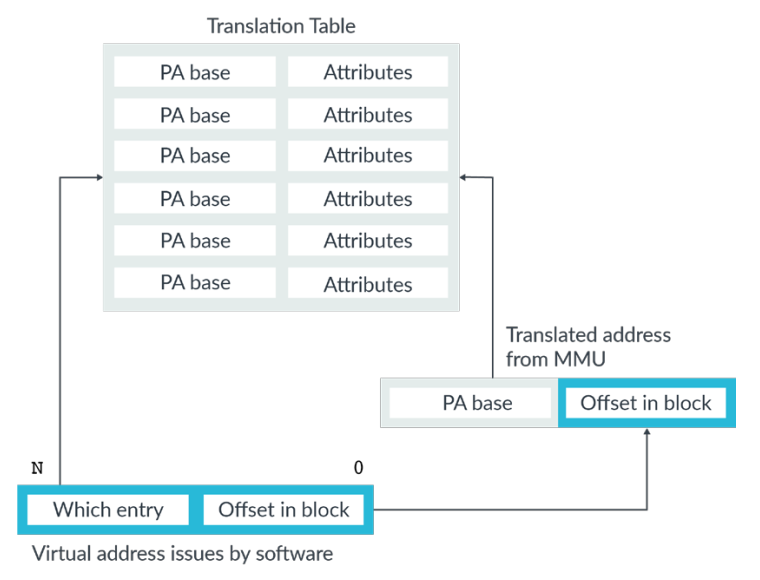
Table lookup
对于一个单一层级的查找来说,当对某个虚拟地址来查找table的时候,会把虚拟地址分城两部分,高位的用来定位对应的entry,而低位的则用来表示该地址在查找到的该block中的偏置大小。
Multilevel translation
在实践使用中,一般使用的是分级table。每一级的访问都像前面介绍的table lookup一样访问。
在armv8中,最多可以分为4级,每级分别被标记为0-3. 这种分级方案支持larger blocks和 smaller blocks:
- larger blocks:相比smaller blocks,它只要更少层级的读取翻译就可以得到对应的物理地址。同时,在TLB中的缓存效率也更高
- small block:可以提供对内存分配fine-grain的控制。但是在TLB中的缓存效率较低,因为需要更多层级的读取翻译才可以得到物理地址
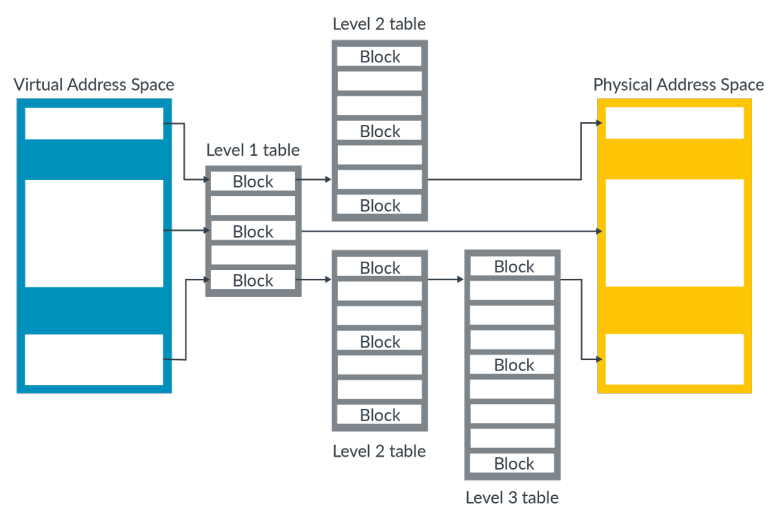
OS必须做好large block和small block之间的平衡,以达到效率和物理内存使用灵活上的平衡,从而达到最优的性能。Note:在这种情况下,处理器并不知道此次翻译对应的block大小,它需要通过table walk的方式来得到。
Address spaces in Armv8-A
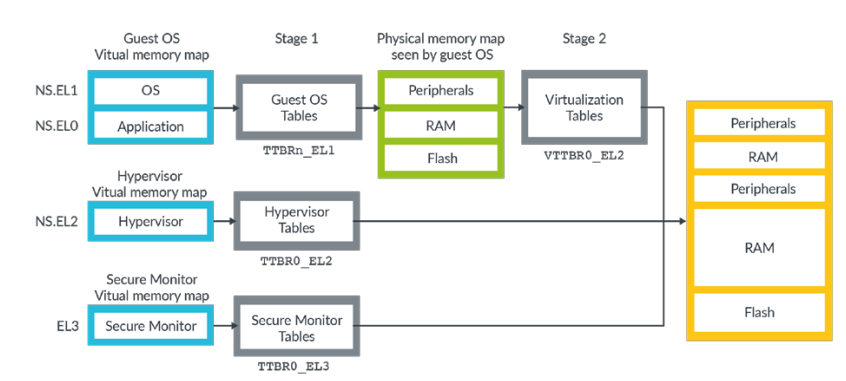
在arm中,同时存在几个独立的虚拟地址空间,比如OS的、Hypervisor的以及Secore Monitor的。每个虚拟地址空间都有他们自己的setting和tables。从这个图上我们可以看到,OS的虚拟地址其实是经过了两层translation的,先是由OS翻译成IPAs,然后再又hypervisor翻译成真正的物理地址,这两次翻译虽然在表的格式方面可能有所差异,但是大体是基本是一致的。如下图所示:
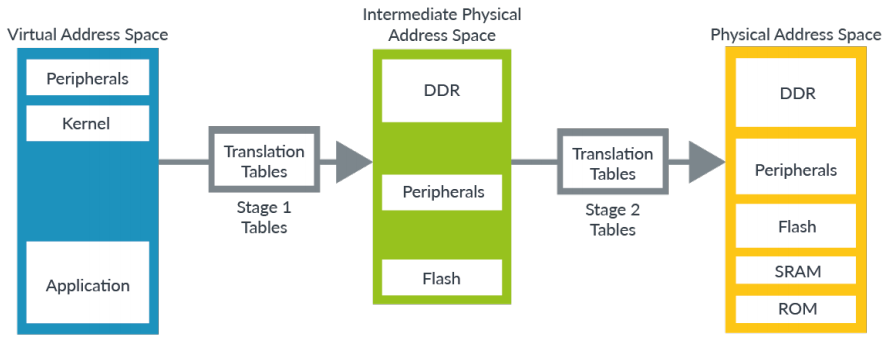
Address sizes
虽然Armv8-A是64位的架构,但是并不是意味着所有的地址都是64位的
Size of virtual addresses
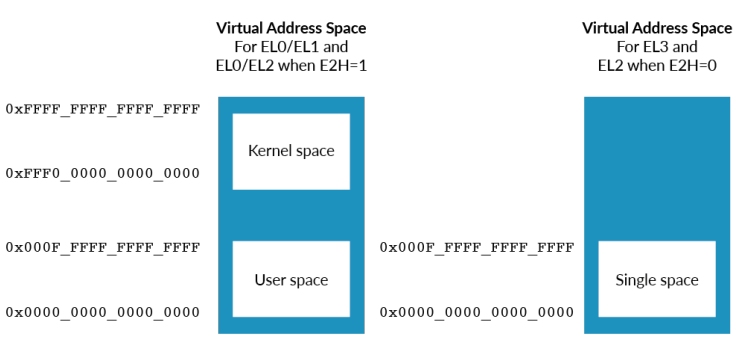
从这个图也可以看出,对于EL0/EL1,kernel space和user space的地址空间是分开的,kernel的位于高地址,user位于低地址。kernel space和user space都有各自的translation table。TCR_ELx registers中表示的TnSZ值用来控制虚拟地址空间:
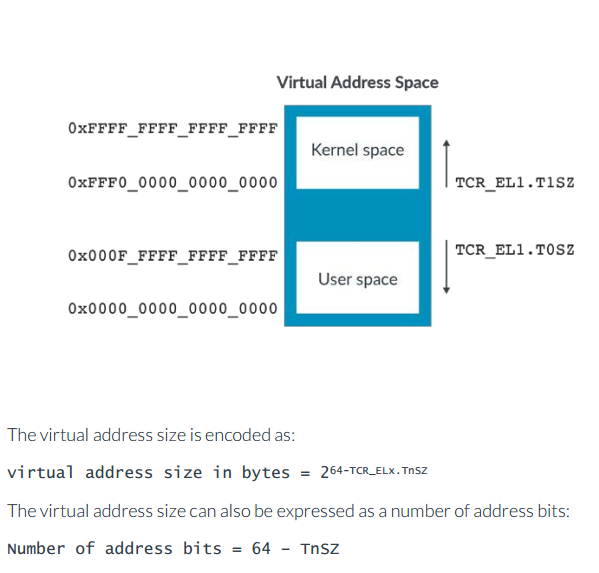
所有的armv8-a架构都支持48位的虚拟地址,52位的是可选支持。比如上图的中的0x0000_0000_0000_0000~0x000F_FFFF_FFFF_FFFF表示的就是一个52位的地址空间
Size of physical address
size of物理地址是有实现决定的,最大支持52bits。如果你在table entry中指定一个
Adress Space Identifiers - Tagging translations with the owning process
对于现代操作系统,多个同时运行的进程看起来都是有着相同的虚拟地址的。那么从MMU的角度来讲,它怎么区分一个相同的虚拟地址是来自哪个进程呢?同时,理想化的来讲,我们希望不同的进程所对应的TLB是互不冲突的,这就不会导致TLB的的刷新以及上下文切换。解决这个问题的手段就是使用Address Space Identifiers (ASIDs)
对于EL0/EL1,即OS,的虚拟地址,translations table entry的属性字段中的nG位用来标记global或者non-global。kernel对应的是global,也即意味着对于所有的进程都是共用的,而non-global的ranslation则与对应的进程相关。对于non-global的,则匹配TLB中的ASID和当前translations提供的ASID,会选择匹配了的来进行处理。
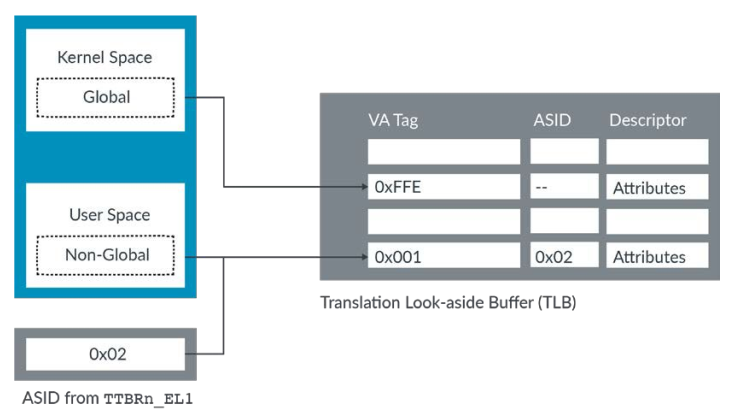
Virtual Machine Identifiers - Tagging translations with the owning VM
对于不同的VM,和ASID一样,使用Virtual Machine Identifier (VMID) 来进行tag。这里讲的VM就是EL0 EL1 EL2 EL3这些。
Common not Private
有这样一个问题,现在CPU都是多核的,同一个ASID和VMID在不同的process上有相同的含义吗?
对Armv8.0-A 版本,答案是否定的。没有要求对于多个processor之间要求ASID和VMID含义一致,即相同的ASID在不同的processor可能表示不同的进程。也即意味着,一个processor创建的TLB不能被另一个processor使用。
但是,在实际中,我们更倾向于他们是跨processor通用的,因此从Armv8.2-A 开始引入了Common not Private (CnP)bit in the Translation Table Base Register (TTBR) ,如果CnP位被set,那么就意味着可以通用。
Controlling address translation
Translation table format

为什么对于level3没有Next-level Table Address?因为前面也提到过,最多容许四级地址。也即3就是最后一级了,必须输出硬件地址了,即Output Block Address
为什么level0没有Output Block Address?因为level0表示的范围太大了,直接让其表示blocks没有意义。
为什么第一个和第三个的descriptor是一样的?因为这样容许recursive tables,让他们相互之间可以point back。This is useful because it makes it easy to calculate the virtual address of a particular page table entry so that it can be updated .
Translation granule
translation granule,即翻译粒度,指的是最小可described的block memory大小。Armv8-A 支持4KB, 16KB, and 64KB 。具体是由ID_AA64MMFR0_EL1 所指定。
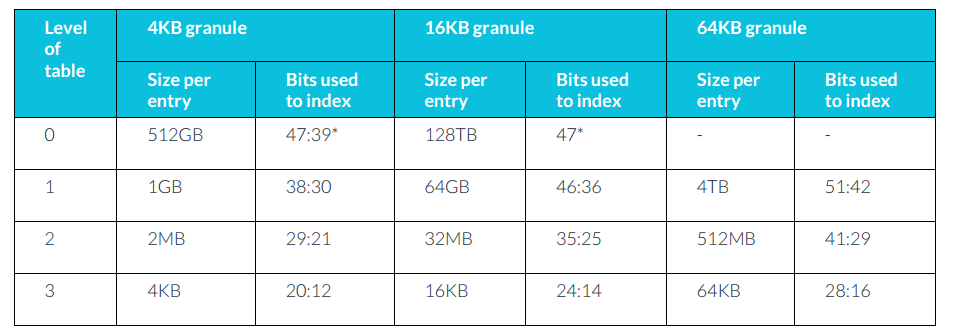
There are restrictions on using 52-bit addresses. When the selected granule is 4KB or 16KB, the maximum virtual address region size is 48 bits. Similarly, output physical addresses are limited to 48 bits. It is only when the 64KB granule is used that the full 52 bits can be used 。
The starting level of address translation
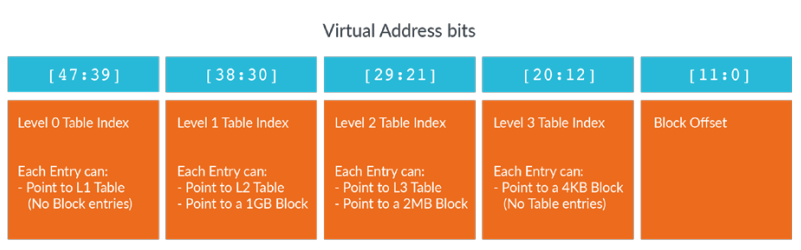
这张表说明的是,当选择4KB的 granule时,各个entry level所利用的地址bits。假如你设置TCR_ELx.T0SZ为32,那么虚拟地址空间就只有\(64-TOSZ=32\)位,那么对应上表,你就可以发现,已经不需要level0了,直接从level1开始就可以完全表示整个虚拟地址空间了。而如果虚拟地址空间只有30位,那么只需要从level2开始就可以完整表示整个地址空间了。也即,虚拟地址空间越小,那么所需的level也就越小。
Registers that control address translation
地址翻译是通过如下这些寄存器来配合控制的:
- SCTLR_ELx
- M - Enable Memory Management Unit (MMU).
- C - Enable for data and unified caches
- EE - Endianness of translation table walks.
- TTBR0_ELx and TTBR1_ELx
- BADDR - Physical address (PA) (or intermediate physical address, IPA, for EL0/EL1) of start of translation table.
- ASID - The Address Space Identifier for Non-Global translations.
- TCR_ELx
- PS/IPS - Size of PA or IPA space, the maximum output addresssize.
- TnSZ - Size of address space covered by table.
- TGn - Granule size.
- SH/IRGN/ORGN - Cacheability and shareability to be used by MMU table walks.
- TBIn - Disabling of table walks to a specific table.
- MAIR_ELx
- Attr - Controls the Type and cacheability in Stage 1 tables.
MMU disabled
如果MMU被禁用的话,那么所有地址都是flat-mapped,即输入等于输出。
Translation Lookaside Buffer maintenance
TLB缓存的最近使用的translations,以便可以得到translation结果而不用去读tables。注意:TLB换成的translations,即从虚拟地址到硬件地址的直接映射关系,而不是translation tables。个人认为有三个原因:一是这样效率最高,直接读结果;二是entry有多个level,换成entry的话,会需要更多的空间;三是entry可能会随着配置寄存器的更改而有不同的含义,这也会给缓存的重利用造成更多负担。
这些情况下,TLB不会对其进行缓存:
• A translation fault (unmapped address).
• An address size fault (address outside of range).
• An access flag fault.
当你首次mapping一个地址的时候,并不需要issue a TLB invalidate ,而当有下列行为的时候,必须issue a TLB invalidate :
- Unmap an address .Take an address that was previously valid or mapped and mark it as faulting.
- Change the mapping of an address. Change the output address or any of the attributes. For example, change an address from read-only to read-write permissions.
- Change the way the tables are interpreted. This is less common. But, for example, if the granule size was changed, then the interpretation of the tables also changes. Therefore, a TLB invalidate would be necessary.
对应的指令为TLBI <type><level>{IS|OS} {, <xt>} 。
Address translation instructions
Address Translation (AT) 可以用来查询特定地址的translation结果,翻译结果和地址属性,保存在Physical Address Register, PAR_EL1 。同时,AT指令可以查询指定regime的结果,比如EL2可以查询某个EL1地址的结果,但不能反过来。因为EL2比EL1拥有更高的特权。
Check your knowledge
What is the difference between a stage and a level in address translation?
stage表示的是从输入到输出的两个阶段。第一个阶段是从虚拟地址VA到中间物理地址IPA,阶段二是从IPA到物理地址PA。只有EL1/EL0的才有两个stage。
level表示的给定stage中不同级别的tables,从大范围往小范围级级缩小。
What is the maximum size of a physical address?
这是implementation决定的,最大为52bitWhich register field controls the size of the virtual address space?
TCR_ELx.TnSZ, or VTCR_EL2.T0SZ for Stage 2What is a translation granule, and what are the supported sizes?
表示的是最小的内存描叙分割单元,支持4,16,64KB三种What does the TLBI ALLE3 do?
刷新所有EL3的虚拟地址空间对应的TLB entriesHow are addresses mapped when the MMU is disabled?
采用flat mapped,即输出等于输入What is an ASID and when does a TLB entry include an ASID?
ASID表示的当前地址对应的哪个application。. Non-Global mappings (nG=1)对应的TLBs使用ASID进行标记。MMU和DMA?
As well as the Memory Management Unit (MMU) in the processor, it is increasingly common to have MMUs for non-processor masters, such as Direct Memory Access (DMA) engines. These are referred to as SMMUs (System MMUs) in Arm systems, and elsewhere as IOMMU.
参考
内容来自https://developer.arm.com/architectures/learn-the-architecture/memory-management
Armv8-A Memory management的更多相关文章
- Learn The Architecture Memory Management 译文
1.概述 本文档介绍了ARMv8-A架构内存管理的关键——内存地址转换,包括虚拟地址(VA)到物理地址(PA)的转换.页表(或称地址转换表)格式以及TLBs(Translation Lookaside ...
- Memory Management in Open Cascade
Open Cascade中的内存管理 Memory Management in Open Cascade eryar@163.com 一.C++中的内存管理 Memory Management in ...
- Java (JVM) Memory Model – Memory Management in Java
原文地址:http://www.journaldev.com/2856/java-jvm-memory-model-memory-management-in-java Understanding JV ...
- Objective-C Memory Management
Objective-C Memory Management Using Reference Counting 每一个从NSObject派生的对象都继承了对应的内存管理的行为.这些类的内部存在一个称为r ...
- Operating System Memory Management、Page Fault Exception、Cache Replacement Strategy Learning、LRU Algorithm
目录 . 引言 . 页表 . 结构化内存管理 . 物理内存的管理 . SLAB分配器 . 处理器高速缓存和TLB控制 . 内存管理的概念 . 内存覆盖与内存交换 . 内存连续分配管理方式 . 内存非连 ...
- Android内存管理(2)HUNTING YOUR LEAKS: MEMORY MANAGEMENT IN ANDROID PART 2
from: http://www.raizlabs.com/dev/2014/04/hunting-your-leaks-memory-management-in-android-part-2-of- ...
- Android内存管理(1)WRANGLING DALVIK: MEMORY MANAGEMENT IN ANDROID PART 1
from : http://www.raizlabs.com/dev/2014/03/wrangling-dalvik-memory-management-in-android-part-1-of-2 ...
- Understanding Memory Management(2)
Understanding Memory Management Memory management is the process of allocating new objects and remov ...
- Java Memory Management(1)
Java Memory Management, with its built-in garbage collection, is one of the language’s finest achiev ...
随机推荐
- kafka的认识、安装与配置
认识Kafka 花费越少的精力在数据移动上,就能越专注于核心业务 --- <Kafka:The Definitive Guide> 认识 Kafka 之前,先了解一下发布与订阅消息系统:消 ...
- 1-GPIO
GPIO的配置: GPIO库函数编程: void LED_init(void)//LED初始化 { GPIO_InitTypeDef GPIO_InitStructure;//定义一个结构体变量 RC ...
- (四)pandas的拼接操作
pandas的拼接操作 #重点 pandas的拼接分为两种: 级联:pd.concat, pd.append 合并:pd.merge, pd.join 0. 回顾numpy的级联 import num ...
- 史上最强vue总结~万字长文---面试开发全靠它了
vue框架篇 vue的优点 轻量级框架:只关注视图层,是一个构建数据的视图集合,大小只有几十kb: 简单易学:国人开发,中文文档,不存在语言障碍 ,易于理解和学习: 双向数据绑定:保留了angular ...
- JavaScript 基础 学习 (四)
JavaScript 基础 学习 (四) 解绑事件 dom级 事件解绑 元素.on事件类型 = null 因为赋值的关系,所以给事件赋值为 null 的时候 事件触发的时候,就没有事件处理 ...
- 你真的清楚DateTime in C#吗?
DateTime,就是一个世界的大融合. 日期和时间,在我们开发中非常重要.DateTime在C#中,专门用来表达和处理日期和时间. 本文算是多年使用DateTime的一个总结,包括DateTim ...
- 第一部分软件测试综述——软件测试背景【软件测试】(美)Ron Patton中文电子版
截取自:第一部分软件测试综述——软件测试背景[软件测试](美)Ron Patton中文电子版(有需要的可以关注我) 第一部分软件测试综述 对手的程序死掉叫崩溃.自己的程序死掉叫“身体不良反应(idio ...
- C++ 简单介绍线段树
题目描述 如题,已知一个数列,你需要进行下面两种操作: 将某区间每一个数加上k. 求出某区间每一个数的和. 输入格式 第一行包含两个整数n,m分别表示该数列数字的个数和操作的总个数. 第二行包含n个用 ...
- 一张图就可以完美解决Java面试频次最高、GG最高的题目!快点收藏
如果要问Java面试频次最高的题目,那么我想应该是HashMap相关了. 提到HahMap,必然会问到是否线程安全?然后牵扯出ConcurrentHashMap等,接着提及1.7和1.8实现上的区分, ...
- 如何从Python负零基础到精通数据分析
一.为什么学习数据分析 1.运营的尴尬:运营人需要一个硬技能每个初入行的新人都会察觉到,运营是一个似乎并没有自己的核心竞争力和安全感的工作.因为每天的工作好像都被各种琐事所围绕,而只有一个主题是永恒不 ...