Docker安装Mycat并实现mysql读写分离,分库分表
Docker安装Mycat并实现mysql读写分离,分库分表
原文地址:
CSDN:SophiaLeo:Docker安装Mycat并实现mysql读写分离,分库分表
一、拉取mycat镜像
docker pull longhronshens/mycat-docker
关于mysql的主从,参照原博主博文或同栏目下转载的原博主博文。
Docker安装mysql5.7并且配置主从复制
- 环境
- mysql主:192.168.21.55:3307
- mysql从:192.168.21.55:3308
- mycat:192.168.21.55
二、准备挂载的配置文件
参照原博主博文:
Mycat安装并实现mysql读写分离,分库分表
2.1 创建文件夹并添加配置文件
mkdir -p /usr/local/mycat
cd /usr/local/mycat
2.1.1 server.xml
vim /usr/local/mycat/server.xml
此处,可以将以下内容复制到本地的编辑器中,修好好后,通过rz命令上传至服务器也可,感觉这样方便。
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sequnceHandlerType">0</property>
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">1</property>
<!--
单位为m
-->
<property name="memoryPageSize">1m</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property>
</system>
<user name="root">
<property name="password">root</property>
<property name="schemas">test</property>
</user>
</mycat:server>
2.1.2 server.xml
vim /usr/local/mycat/schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="test" checkSQLschema="false" sqlMaxLimit="100">
<table name="tb_user" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3,dn4" rule="userrule" />
<table name="tb_category" primaryKey="id" dataNode="dn1,dn2,dn3,dn4" rule="categoryrule" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataNode name="dn4" dataHost="localhost1" database="db4" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.21.55:3307" user="root"
password="root">
<readHost host="hostS2" url="192.168.21.55:3308" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
2.1.3 sequence_conf.properties
vim /usr/local/mycat/sequence_conf.properties
TB_USER.HISIDS=
TB_USER.MINID=1
TB_USER.MAXID=20000
TB_USER.CURID=1
2.1.4 rule.xml
vim /usr/local/mycat/rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="userrule">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="categoryrule">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">4</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">4</property>
</function>
</mycat:rule>
三、启动mycat
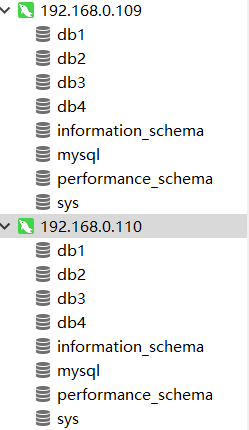
- 配置实际mysql数据库,在mysql主上建4个数据库db1,db2,db3,db4(不要操作从机)
- 放行端口号(未按照原博主方式进行放行)
firewall-cmd --zone=public --add-port=8066/tcp --permanent
firewall-cmd --zone=public --add-port=9066/tcp --permanent
firewall-cmd --reload
- 创建运行容器
docker run --name mycat -v /usr/local/mycat/schema.xml:/usr/local/mycat/conf/schema.xml -v /usr/local/mycat/rule.xml:/usr/local/mycat/conf/rule.xml -v /usr/local/mycat/server.xml:/usr/local/mycat/conf/server.xml -v /usr/local/mycat/sequence_conf.properties:/usr/local/mycat/conf/sequence_conf.properties --privileged=true -p 8066:8066 -p 9066:9066 -e MYSQL_ROOT_PASSWORD=root -d longhronshens/mycat-docker
- 连接(通过Navicat连接(原博文不推荐通过可视化工具连接,但为了查看效果方便,还是连接比较好))

- 进入mysql里连接
docker exec -it mysqlmaster /bin/bash
下面这个地方踩了个坑,直接127.0.0.1的方式去连接了,不行,因为我是虚拟机环境,所以应该使用虚拟机ip。
ip改为192.168.21.55即可。
mysql -h127.0.0.1 -uroot -proot -P8066
- 开始创建刚刚配置的逻辑库,逻辑表
show databases;
use test;
CREATE TABLE `tb_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户名',
`password` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '密码,加密存储',
`phone` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '注册手机号',
`email` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '注册邮箱',
`created` datetime(0) NOT NULL,
`updated` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `username`(`username`) USING BTREE,
UNIQUE INDEX `phone`(`phone`) USING BTREE,
UNIQUE INDEX `email`(`email`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 54 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '用户表' ROW_FORMAT = Compact;

- 可以看到mycat,mysql主从都创建了该表
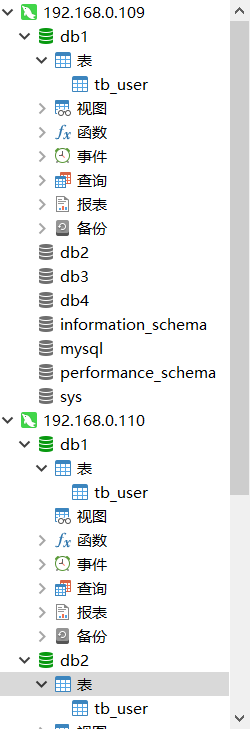
- 再建一张表
CREATE TABLE `tb_category` (
`id` varchar(5) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`name` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '名字',
`sort_order` int(4) NOT NULL DEFAULT 1 COMMENT '排列序号,表示同级类目的展现次序,如数值相等则按名称次序排列。取值范围:大于零的整数',
`created` datetime(0) NULL DEFAULT NULL,
`updated` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `updated`(`updated`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
- 再插入数据
INSERT INTO `tb_user`(id,username,password,phone,email,created,updated) VALUES (7, 'zhangsan', 'e10adc3949ba59abbe56e057f20f883e', '13488888888', 'aa@a', '2015-04-06 17:03:55', '2015-04-06 17:03:55');
如果报ERROR 1064 (HY000): insert must provide ColumnList
插入数据时一定要把所有字段带上。
插入时,并未出现错误,直接一次KO。。。
- 可以看到mysql主从里已经添加了数据


PS:安装原文博主教程一步一步走下来,搭建成功,再次感谢原博主的辛勤劳动。。。。。
Docker安装Mycat并实现mysql读写分离,分库分表的更多相关文章
- Mycat安装并实现mysql读写分离,分库分表
Mycat安装并实现mysql读写分离,分库分表 一.安装Mycat 1.1 创建文件夹 1.2 下载 二.mycat具体配置 2.1 server.xml 2.2 schema.xml 2.3 se ...
- Mycat 读写分离+分库分表
上次进过GTID复制的学习记录,已经搭建好了主从复制的服务器,现在利用现有的主从复制环境,加上正在研究的Mycat,实现了主流分布式数据库的测试 Mycat就不用多介绍了,可以实现很多分布式数据库的功 ...
- SpringCloud微服务实战——搭建企业级开发框架(二十七):集成多数据源+Seata分布式事务+读写分离+分库分表
读写分离:为了确保数据库产品的稳定性,很多数据库拥有双机热备功能.也就是,第一台数据库服务器,是对外提供增删改业务的生产服务器:第二台数据库服务器,主要进行读的操作. 目前有多种方式实现读写分离,一种 ...
- 读写分离&分库分表学习笔记
读写分离 何为读写分离? 见名思意,根据读写分离的名字,我们就可以知道:读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上. 这样的话,就能够小幅提升写性能,大幅提升读性能. 我简单画了一 ...
- Django 数据库读写分离 分库分表
多个数据库 配置: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BA ...
- MySQL主从复制&读写分离&分库分表
MySQL主从复制 MySQL的主从复制只能保证主机对外提供服务,从机是不提供服务的,只是在后台为主机进行备份数据 首先我们说说主从复制的原理,这个是必须要理解的玩意儿: 理解: MySQL之间的数据 ...
- MyCat:对MySQL数据库进行分库分表
本篇前提: mycat配置正确,且能正常启动. 1.schema.xml <table>标签: dataNode -- 分片节点指定(取值:dataNode中的name属性值) rule ...
- Mysql中的分库分表
mysql中的分库分表分库:减少并发问题分表:降低了分布式事务分表 1.垂直分表 把其中的不常用的基础信息提取出来,放到一个表中通过id进行关联.降低表的大小来控制性能,但是这种方式没有解决高数据量带 ...
- MySQL纯透明的分库分表技术还没有
MySQL纯透明的分库分表技术还没有 种树人./oneproxy --proxy-address=:3307 --admin-username=admin --admin-password=D033 ...
随机推荐
- python之scrapy篇(一)
一.首先创建工程(cmd中进行) scrapy startproject xxx 二.编写Item文件 添加要字段 # -*- coding: utf-8 -*- # Define here the ...
- TurtleBot3 Waffle (tx2版华夫)(6)
重要提示:请在配网通信成功后进行操作,配网后再次开机需要重新验证通信: 重要提示:[Remote PC]代表PC端.[TurtelBot]代表树莓派端: 操作步骤如下: 1)[Remote PC] 启 ...
- 彻底搞懂JavaScript的闭包、防抖跟节流
最近出去面试了一下,收获颇多!!! 以前的我,追求实际,比较追求实用价值,然而最近面试,传说中的面试造火箭,工作拧螺丝,竟然被我遇到了.虽然很多知识点在实际工作中并不经常用到,但人家就是靠这个来筛选人 ...
- MongoDB备份(mongoexport)与恢复(mongoimport)
1.备份恢复工具介绍: mongoexport/mongoimport mongodump/mongorestore(本文未涉及) 2.备份工具区别在哪里? 2.1 mongoexport/mongo ...
- nginx 重写去掉index.php
if (!-e $request_filename) { rewrite ^/(.*)$ /index.php?s=$1 last; }
- Java菜鸟在IP问题踩坑了
之前有做过获取客户端公网IP的项目 一般都是 正常的request.getRemoteAddr 或者request.getRemoteHost 可获取到客户端的公网IP, 或者项目部署在有nginx代 ...
- 【剑指 Offer】08.二叉树的下一个节点
题目描述 给定一颗二叉树和其中的一个节点,找出中序遍历序列的下一个节点.树中的节点除了有两个分别指向左右节点的指针,还有一个指向父节点的指针. Java public class Solution08 ...
- 基于JavaFX实现的音乐播放器
前言 这个是本科四年的毕业设计,我个人自命题的一个音乐播放器的设计与实现,其实也存在一些功能还没完全开发完成,但粗略的答辩也就过去了,还让我拿了个优秀,好开心.界面UI是参考网易云UWP版本的,即使这 ...
- linux系统Vsftpd搭建FTP
安装vsftp 使用yum命令安装vsftp #yum install vsftpd -y 添加ftp帐号和目录 先检查下nologin的位置,通常在/usr/sbin/nologin下 (*no ...
- 【Linux】1、命令行及命令参数
命令行及命令参数 文章目录 命令行及命令参数 1.命令行提示符 2.命令和命令参数 简单的命令 date ls 命令参数 短参数(一个字母) 长参数(多个字母) 参数的值 其它参数 3.小结 4.参考 ...