learning to Estimate 3D Hand Pose from Single RGB Images论文理解
持续更新......
概括:以往很多论文借助深度信息将2D上升到3D,这篇论文则是想要用网络训练代替深度数据(设备成本比较高),提高他的泛性,诠释了只要合成数据集足够大和网络足够强,我就可以不用深度信息。这篇论文的思路很清晰,主要分为三个部分:
1、HandSegNet
2、PoseNet
3、the PosePrior network
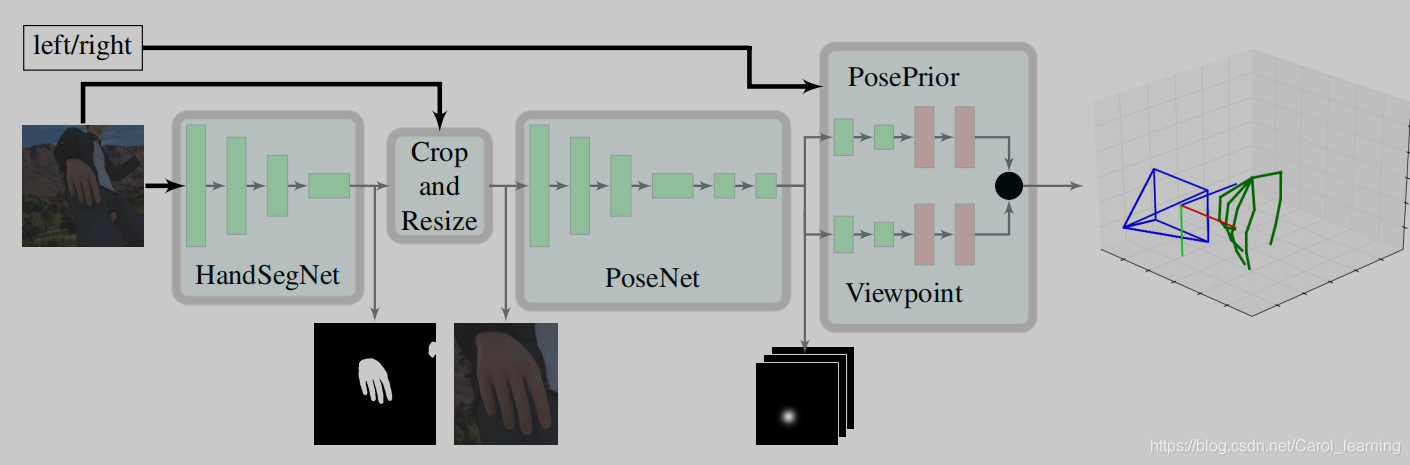
第1、2个网络主要是借助 Convolutional Pose Machines 这篇论文的网络进行设置, 通过卷积图层表达纹理信息和空间信息提取出手的位置(只是对第一个网络添加了二值化处理形成了handmask 的中间输出),由于手势比较小,因此对手的位置进行裁剪成为第二个网络的输入,以类似的方式提取关节的位置(score map)。
本论文的核心是第三个网络,该网络以score map 作为输入,进行网络的训练估计正则化框架WC内的三维坐标,并分别估计旋转矩阵R(Wrel),根据公式反求出wc (rel)。

为什么2D数据可以直接通过网络进行3D的估计?
关键在于方法用的是合成数据集(synthetic dataset (R-val) ),什么是合成数据集呢?Unity大家一定不陌生。通过类似Unity的引擎我们可以模拟各种场景、光线下的人物,根据自己的需要去制作大量的数据集,解决计算机视觉领域缺少数据集的短板。但是,这只是合成数据集的其中一个好处,最大的好处在于由于我们通过引擎模拟人物,那么这个人物的数据我们是有的,即我们可以知道人物三维手势各个关节的相对位置和绝对位置(ground truth),因此我们可以通过这些数据进行训练,从而达到不用深度数据就可以3D训练的效果。
为什么要用一个canonical frame呢?
论文中这样定义:
给定一个颜色图像I∈RN×M3显示一只手,我们想推断它的三维姿态。 我们用一组坐标wi=(xi,yi,zi)来定义手姿,它描述了J关键点在三维空间中的位置,即在我们的情况下,用J=21来∈[1,J]。


s将某对关键点之间的距离归一化为单位长度。

深度数据限制了我们可以脱离整个图像,如果不用深度数据,我们的目光就只需要针对一只手,以手建立对象来研究他的属性。论文中,作者将关节之间的距离归一化,并且手心关节这一个关键点作为标志(land mark),计算其他关节到手心关节点的距离,从而构成一个canonical frame。第三层网络则是不断将canonical frame测量值和ground truth 采用L2 损失对两个估计值WC内的三维坐标和旋转矩阵R(Wrel)进行训练。
为什么要用旋转矩阵将视角统一?
我的理解是如果将视角统一,那么手势的所有可能形式将大大地减少,这样子网络训练准确率将提高。
论文学习知识补充(之后迁移到其他地方)
ill-posed problems
定义:满足以下条件称为适定问题(well-posed problem):1. a solution exists 解必须存在2. the solution is unique 解必须唯一3. the solution's behavior changes continuously with the initial conditions. 解能根据初始条件连续变化,不会发生跳变,即解必须稳定
理解:病态问题简单来说就是结果不唯一,比如a*b=5,求解a和b的值就是病态问题。实际应用上很多问题都是病态问题,比如如果一个高温的东西,你不能直接去测量他,你只能间接去测量他,间接可以构成一个模型等式y=f(x,h...),那么我们得到测量值y,求解x,可见由于间接测量我们会受到其他无法测量的因素所影响,反向求x存在多个解,这就叫病态问题以对于病态问题,我们需要做各种先验假设来约束他,让他变成well-posed problem。
正则化与过拟合
摘录整理
基本定义:对于大量的训练数据,如果我们单纯最小化误差,那么模型的复杂度就会上升(联想一下maltab 的表达式很长很长),这样子会让模型泛化程度很小,所以我们定义规则函数,让他不要过拟合,保持模型较为简单(模型误差小)。
还有另一种理解:规则函数就是拿前人的经验让你少走弯路。
还有第三种理解:规则化符合奥卡姆剃刀原理,从从贝叶斯估计的角度来看,规则化项对应于模型的先验概率。民间还有个说法就是,规则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或惩罚项(penalty term)。
对于最小化的目标函数:
Obj(Θ)=L(Θ)+Ω(Θ)
常用的损失函数:损失函数链接
训练集上的损失定义为:L=∑ni=1l(yi,y^i)
1.0-1损失函数 (0-1 loss function): L(Y,f(X))={1,Y≠f(X)0,Y=f(X)
2.平方损失函数 (quadratic loss function) : L(Y,f(X))=(Y−f(x))2
3.绝对值损失函数 (absolute loss function) : L(Y,f(x))=|Y−f(X)|
4.对数损失函数 (logarithmic loss function) : L(Y,P(Y∣X))=−logP(Y∣X)
5.Logistic 损失:l(yi,yi)=yiln(1+eyi)+(1−yi)ln(1+eyi)
6.Hinge 损失:hinge(xi)=max(0,1−yi(w⊤xi+b)) ,SVM 损失函数,如果点正确分类且在间隔外,则损失为 0;如果点正确分类且在间隔内,则损失在 (0,1);如果点错误分类,则损失在 (1,+∞)
7.负对数损失 (negative log-likelihood, NLL):Li=−log(pyi),某一类的正确预测的失望程度 (>0),其值越小,说明正确预测的概率越大,表示预测输出与 y 的差距越小
8.交叉熵损失 (cross entropy):首先是 softmax 定义为 pk=efk/∑jefj,其中 fk=Wx+b 表示某一类的预测输出值,则某类的交叉熵损失为该类的输出指数值除所有类之和。基于交叉熵和 softmax 归一化的 loss
L=−1N∑i=1Nyi log ef(xi)∑ef(xi)
condition number
摘录
如果一个系统是ill-conditioned病态的,我们就会对它的结果产生怀疑。那到底要相信它多少呢?我们得找个标准来衡量,因为有些系统的病没那么重,它的结果还是可以相信的,不能一刀切。终于回来了,上面的condition number就是拿来衡量ill-condition系统的可信度的。condition number衡量的是输入发生微小变化的时候,输出会发生多大的变化。也就是系统对微小变化的敏感度。condition number值小的就是well-conditioned的,大的就是ill-conditioned的。
低秩
摘录整理
X是低秩矩阵。低秩矩阵每行或每列都可以用其他的行或列线性表出,可见它包含大量的冗余信息。利用这种冗余信息,可以对缺失数据进行恢复,也可以对数据进行特征提取。
L1是L0的凸近似。因为rank()是非凸的,在优化问题里面很难求解,那么就需要寻找它的凸近似来近似它了。对,你没猜错,rank(w)的凸近似就是核范数||W||*。
L0和L1的关系
L1可以使矩阵稀疏化,可以提取特征
L2可以防止过拟合,使得无关的参数更加小。
凸优化问题
为什么不能用MSE作为训练二元分类的损失函数呢?
因为用MSE作为二元分类的损失函数会有梯度消失的问题。
one hot编码

摘录
我们继续之前,你可以想一下为什么不直接提供标签编码给模型训练就够了?为什么需要one hot编码?
标签编码的问题是它假定类别值越高,该类别更好。“等等,什么!”
让我解释一下:根据标签编码的类别值,我们的迷你数据集中VW > Acura > Honda。比方说,假设模型内部计算平均值(神经网络中有大量加权平均运算),那么1 + 3 = 4,4 / 2 = 2. 这意味着:VW和Honda平均一下是Acura。毫无疑问,这是一个糟糕的方案。该模型的预测会有大量误差。
我们使用one hot编码器对类别进行“二进制化”操作,然后将其作为模型训练的特征,原因正在于此。
当然,如果我们在设计网络的时候考虑到这点,对标签编码的类别值进行特别处理,那就没问题。不过,在大多数情况下,使用one hot编码是一个更简单直接的方案。
OpenCV双目视觉之立体校正
立体校正就是,把实际中非共面行对准的两幅图像,校正成共面行对准。因为理想情况下计算距离需要两个摄像机需要在同一水平上,但是现实生活中我们有时候多视角的照片不是在同一个水平上拍的,所以需要立体校正将图片变成类似两个摄像机在同一水平上拍摄出来的效果。
双目立体视觉数据集 Stereo dataset
xx对,每一对可以通过立体校正后进行测距。
图像的先验特征
直观的理解就是你对图像的了解,比如手势估计中的手的大小其他已知的信息。
这些先验在很多图像task中可以作为loss中的正则化项,来迫使处理后的图像不会过于拟合。
梯度爆炸和梯度消失
@看【25】论文 与深度数据的区别
之后更新
@@怎样用STB去训练的?
之后去复现,目前认为是立体校正后将深度数据输入网络进行训练。
learning to Estimate 3D Hand Pose from Single RGB Images论文理解的更多相关文章
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- Learning Feature Pyramids for Human Pose Estimation(理解)
0 - 背景 人体姿态识别是计算机视觉的基础的具有挑战性的任务,其中对于身体部位的尺度变化性是存在的一个显著挑战.虽然金字塔方法广泛应用于解决此类问题,但该方法还是没有很好的被探索,我们设计了一个Py ...
- DensePose: Dense Human Pose Estimation In The Wild(理解)
0 - 背景 Facebook AI Research(FAIR)开源了一项将2D的RGB图像的所有人体像素实时映射到3D模型的技术(DensePose).支持户外和穿着宽松衣服的对象识别,支持多人同 ...
- Deep Learning 18:DBM的学习及练习_读论文“Deep Boltzmann Machines”的笔记
前言 论文“Deep Boltzmann Machines”是Geoffrey Hinton和他的大牛学生Ruslan Salakhutdinov在论文“Reducing the Dimensiona ...
- Towards Accurate Multi-person Pose Estimation in the Wild 论文阅读
论文概况 论文名:Towards Accurate Multi-person Pose Estimation in the Wild 作者(第一作者)及单位:George Papandreou, 谷歌 ...
- [论文理解]MetaAnchor: Learning to Detect Objects with Customized Anchors
MetaAnchor: Learning to Detect Objects with Customized Anchors Intro 本文我其实看了几遍也没看懂,看了meta以为是一个很高大上的东 ...
- [论文理解]SSD:Single Shot MultiBox Detector
SSD:Single Shot MultiBox Detector Intro SSD是一套one-stage算法实现目标检测的框架,速度很快,在当时速度超过了yolo,精度也可以达到two-stag ...
- [论文理解]Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition 简介 这是何大佬的一篇非常经典的神经网络的论文,也就是大名鼎鼎的ResNet残差网络,论文主要通过构建了一种新 ...
- [论文理解] Learning Efficient Convolutional Networks through Network Slimming
Learning Efficient Convolutional Networks through Network Slimming 简介 这是我看的第一篇模型压缩方面的论文,应该也算比较出名的一篇吧 ...
随机推荐
- Espruino似乎和Arduino一样
参考:https://baike.baidu.com/item/Espruino Espruino 编辑 锁定 讨论 Espruino 是一个微处理器的 JavaScript 解释器,我们用它来创 ...
- JavaScript求数组中元素的最大值
要求: 求数组[2,6,1,77,52,25,7]中的最大值. 实现思路: 声明一个保存最大元素的变量 max 默认最大值max定义为数组中的第一个元素arr[0] 遍历这个数组,把里面每个数组元素和 ...
- PyCharm 上安装 Package(以 pandas 为例)
一.使用 PyCharm 软件安装 pandas 包 1.打开 PyCharm 2.点击右上角 "Files" →"Settings..." 3.弹出" ...
- vue 异步提交php 两种方式传值
1.首先要在php的入口文件写上一条代码,允许异步提交 header("ACCESS-CONTROL-ALLOW-ORIGIN:*"); 2.在vue有两种方式将数据异步提交到ph ...
- mycat 单库分表实践
参考 https://blog.csdn.net/sq2006hjp/article/details/78732227 Mycat采用的水平拆分,不管是分库还是分表,都是水平拆分的.分库是指,把一个大 ...
- GIT 保存日志并建立自己的分支
以下是我个人在工作中对git的愚见全是大白话说明.也是我踩坑记录吧,防止下次再次踩坑. 再已有的dev(开发分支)新建自己的分支 (featuer)在更新到gitlab 仓库中的过程. 首先要有大致的 ...
- Dubbo部分知识点总结
Dubbo部分 Dubbo工作原理 dubbo工作原理第一层:service层,接口层,给服务提供者和消费者来实现的第二层:config层,配置层,主要是对dubbo进行各种配置的第三层:proxy层 ...
- 从面试角度学完 Kafka
Kafka 是一个优秀的分布式消息中间件,许多系统中都会使用到 Kafka 来做消息通信.对分布式消息系统的了解和使用几乎成为一个后台开发人员必备的技能.今天码哥字节就从常见的 Kafka 面试题入手 ...
- k8s集群添加新得node节点
服务端操作: 方法一: 获取master的join token kubeadm token create --print-join-command 重新加入节点 kubeadm join 192.16 ...
- day02 Pyhton学习
1.昨日内容回顾 1.python是一门解释型,弱类型的高级编程语言 优点: 1.优雅简单明确 2.短小快,代码短,代码量小,开发效率高 缺点: 1.运行效率低(相对) 2.python解释器 Cpy ...