Redis 设计与实现 8:五大数据类型之哈希
哈希对象的编码有两种:ziplist、hashtable。
编码一:ziplist
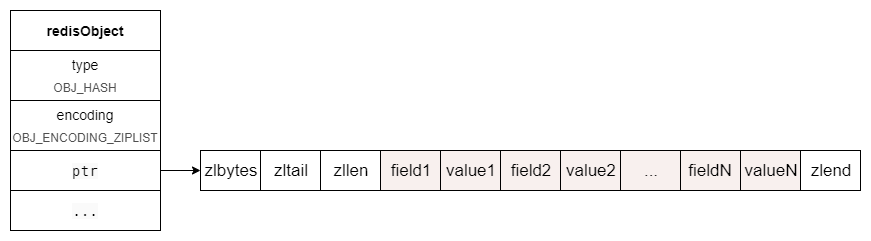
ziplist 已经是我们的老朋友了,它一出现,那肯定就是为了节省内存啦。那么哈希对象是怎么用 ziplist 存储的呢?
每次插入键值对的时候,在 ziplist 列表末尾,挨着插入 field 和 value 。如下图:
常见操作
增删改查都涉及到一块很类似的代码,那就是查找。
redis 这几个函数的查找部分,几乎都是直接复制粘贴。。。可能有改动就有点难维护了。
获取
先从 ziplist 中拿到 field 的指针,然后向后一个节点就是 value
找
field的时候,ziplistFind最后一个参数传入的是1,表示查一个节点后,跳过一个节点不查。
因为hash在ziplist中的存就是fieldvalue挨着存的,我们查的是field,所以要跳过value。
int hashTypeGetFromZiplist(robj *o, sds field, unsigned char **vstr,
unsigned int *vlen, long long *vll) {
unsigned char *zl, *fptr = NULL, *vptr = NULL;
int ret;
serverAssert(o->encoding == OBJ_ENCODING_ZIPLIST);
zl = o->ptr;
// 获取 ziplist 头指针
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
// 再调用 `ziplist.c/ziplistFind` 查找跟 field 相等的节点
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
// 获取 field 的下个指针,就是 value 啦
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
}
}
if (vptr != NULL) {
// 通过上面获取到的指针,在 ziplist 中获取对应的值
ret = ziplistGet(vptr, vstr, vlen, vll);
serverAssert(ret);
return 0;
}
return -1;
}
删除
删除其实就是先查找,后删除
int hashTypeDelete(robj *o, sds field) {
// 0 表示找不到,1 表示删除成功
int deleted = 0;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr;
zl = o->ptr;
// 调用 ziplist.c/ziplistIndex 的函数,获取 ziplist 的头指针
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
// 通过 ziplist.c/ziplistFind 函数去找 field 对应的节点指针
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
// 删除 field
zl = ziplistDelete(zl,&fptr);
// 删除 value
zl = ziplistDelete(zl,&fptr);
o->ptr = zl;
deleted = 1;
}
}
}
// ...
return deleted;
}
插入 / 更新
一切尽在注释中
int hashTypeSet(robj *o, sds field, sds value, int flags) {
// 0 表示是插入操作,1 表示是更新操作
int update = 0;
// 如果是 ziplist 编码
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
// 调用 ziplist.c/ziplistIndex 的函数,获取 ziplist 的头指针
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
// 找 field 对应的指针
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
// 如果能找到,说明 field 已存在,是更新操作。
if (fptr != NULL) {
// 获取 field 下一个节点,也就是值(再次强调,ziplist 中 field 和 value 是挨着放的)
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
// 删除原来的值
zl = ziplistDelete(zl, &vptr);
// 插入新值
zl = ziplistInsert(zl, vptr, (unsigned char*)value, sdslen(value));
}
}
// 如果找不到 field 对应的节点,update == 0,那这就是一个插入操作
if (!update) {
// 在末尾插入 field 和 value
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field), ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value), ZIPLIST_TAIL);
}
o->ptr = zl;
// 判断长度是否达到阈值,如果达到将进行编码转换
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
}
// ...
}
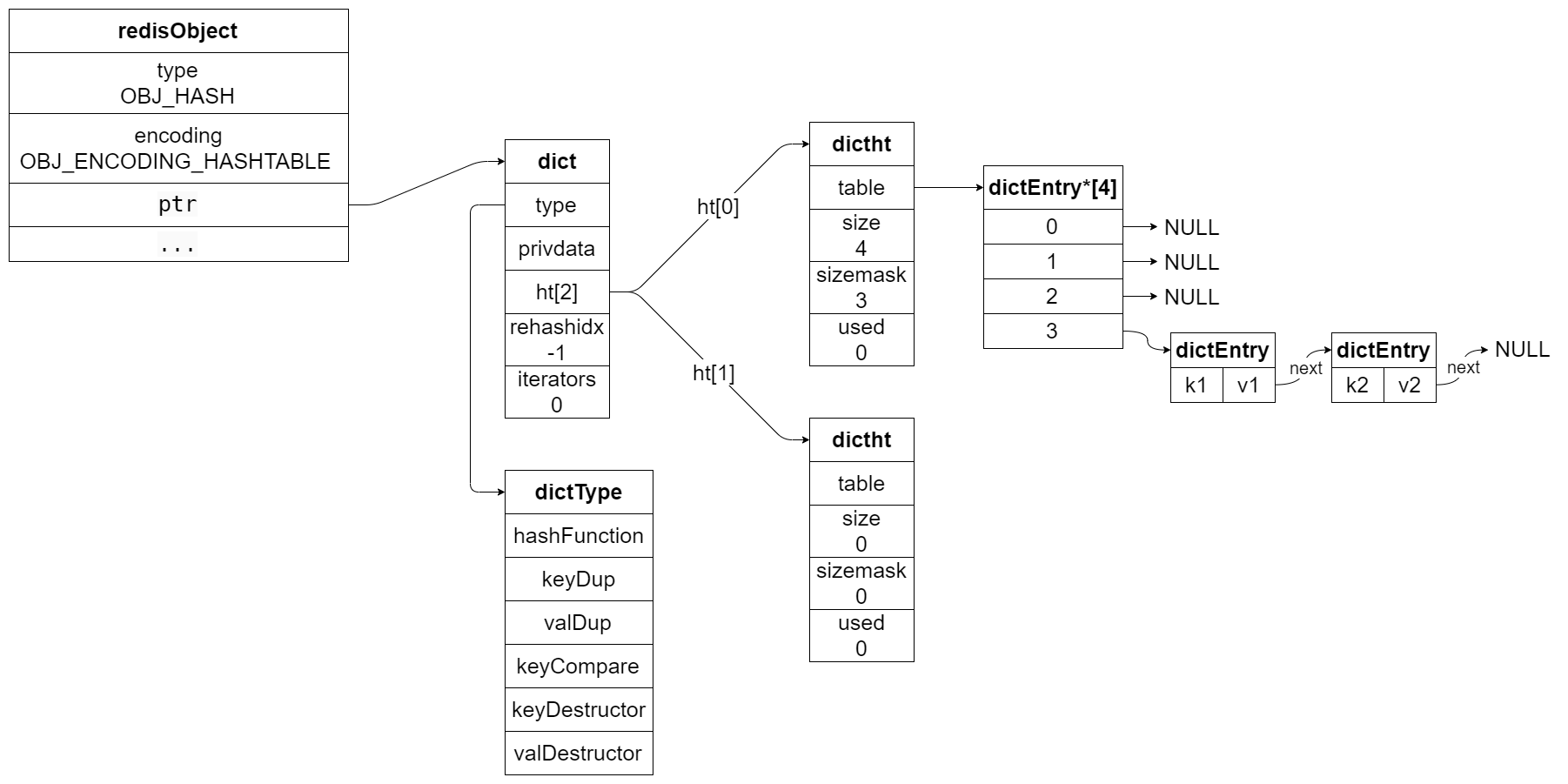
编码二:hashtable
hashtable 编码用的是字典 dict 作为底层实现,关于 dict,具体的前文 Redis 设计与实现 4:字典 dict 已经写了,包括了 dict 基本操作的源码解读。
其结构就相当复杂啦,再来复习一下,如下图:
常见操作
获取
hashtable 编码本身的思路跟 dict 的基本 api 很契合,所以代码比较整洁。获取值就是直接调用 dict.c/dictFind 而已。
前文 Redis 设计与实现 4:字典 dict 已经对 dict 的查找源码分析过,感兴趣的读者可以看看。
sds hashTypeGetFromHashTable(robj *o, sds field) {
dictEntry *de;
serverAssert(o->encoding == OBJ_ENCODING_HT);
// 直接调用 dict.c/dictFind 找到 dictEntry 键值对
de = dictFind(o->ptr, field);
if (de == NULL) return NULL;
return dictGetVal(de);
}
删除
直接调用 dict.c/dictDelete 函数进行删除。
前文 Redis 设计与实现 4:字典 dict 已经对 dict 的删除源码分析过,感兴趣的读者可以看看。
int hashTypeDelete(robj *o, sds field) {
// 0 表示找不到,1 表示删除成功
int deleted = 0;
// ...
if (o->encoding == OBJ_ENCODING_HT) {
if (dictDelete((dict*)o->ptr, field) == C_OK) {
deleted = 1;
/* Always check if the dictionary needs a resize after a delete. */
if (htNeedsResize(o->ptr)) dictResize(o->ptr);
}
}
// ...
return deleted;
}
插入 / 更新
hashtable 的 插入 / 更新 逻辑跟 ziplist 类似。也是先查看是否存在,如果已存在,则删除原来的值,再重新设置新值; 如果不存在,则添加一整个键值对。
这里比较有趣的是,对 field 和 value 定义了所有权 flags,如果拥有所有权,则函数可以直接用来设置field 或者 value,否则只能重新拷贝一份(sds.c/sdsdup)。
// 所有权定义
#define HASH_SET_TAKE_FIELD (1<<0)
#define HASH_SET_TAKE_VALUE (1<<1)
#define HASH_SET_COPY 0
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
if (o->encoding == OBJ_ENCODING_HT) {
// 先找 field
dictEntry *de = dictFind(o->ptr,field);
if (de) {
// 如果找到了,那就删掉旧了,然后设置新的
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
// 如果拥有 value 的所有权,那么可以把 value 直接设置进去
dictGetVal(de) = value;
value = NULL;
} else {
// 如果不拥有 value 的所有权,例如复制的时候。那么要拷贝一个新的 value 出来
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
// 如果找不到值,那么要新设置值
sds f,v;
// 如果拥有 field 的所有权,那么直接用于 field,否则需要重新拷贝一份
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
// 同样,只有拥有 value 的所有权,才能直接用,否则要拷贝一份
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
// 再调用 dict.c 的 dictAdd 添加
dictAdd(o->ptr,f,v);
}
}
// ...
}
编码转换
当哈希对象可以同时满足以下两个条件时,哈希对象使用 ziplist 编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于
64字节 (可通过配置hash-max-ziplist-value修改) - 哈希对象保存的键值对数量小于
512个 (可通过配置hash-max-ziplist-entries修改)
不能同时满足这两个条件的哈希对象需要使用 hashtable 编码。
在 hsetnxCommand 和 hsetCommand 函数中,都会调用到编码的转换。代码如下
void hsetnxCommand(client *c) {
// ...
hashTypeTryConversion(o,c->argv,2,3);
// ...
hashTypeSet(o,c->argv[2]->ptr,c->argv[3]->ptr,HASH_SET_COPY);
// ...
}
void hsetCommand(client *c) {
// ...
hashTypeTryConversion(o,c->argv,2,c->argc-1);
// ...
hashTypeSet(o,c->argv[2]->ptr,c->argv[3]->ptr,HASH_SET_COPY);
// ...
}
// 检查长度超过 hash_max_ziplist_value 就转编码
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
for (i = start; i <= end; i++) {
// #define sdsEncodedObject(objptr) (objptr->encoding == OBJ_ENCODING_RAW || objptr->encoding == OBJ_ENCODING_EMBSTR)
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT);
break;
}
}
}
int hashTypeSet(robj *o, sds field, sds value, int flags) {
// ...
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
// ...
// 判断长度是否达到阈值,如果达到将进行编码转换
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
}
// ...
}
Redis 设计与实现 8:五大数据类型之哈希的更多相关文章
- redis学习(七)——五大数据类型总结:字符串、散列、列表、集合和有序集合
目录 字符串类型(String) 散列类型(Hash) 列表类型(List) 集合类型(Set) 有序集合类型(SortedSet) 其它命令 一.字符串类型(String) 1.介绍: 字符串类型是 ...
- Redis 设计与实现 6:五大数据类型之字符串
前文 Redis 设计与实现 2:Redis 对象 说到,五大数据类型都会封装成 RedisObject. typedef struct redisObject { unsigned type:4; ...
- Redis详解(五)------ redis的五大数据类型实现原理
前面两篇博客,第一篇介绍了五大数据类型的基本用法,第二篇介绍了Redis底层的六种数据结构.在Redis中,并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这些对 ...
- Redis 详解 (五) redis的五大数据类型实现原理
目录 1.对象的类型与编码 ①.type属性 ②.encoding 属性和 *prt 指针 2.字符串对象 3.列表对象 4.哈希对象 5.集合对象 6.有序集合对象 7.五大数据类型的应用场景 8. ...
- redis的五大数据类型实现原理
1.对象的类型与编码 Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Redis中的每个对象都是由 redi ...
- Redis 设计与实现 6:五大数据类型之列表
列表对象有 3 种编码:ziplist.linkedlist.quicklist. ziplist 和 linkedlist 是 3.2 版本之前的编码. quicklist 是 3.2 版本新增的编 ...
- Redis 设计与实现 9:五大数据类型之集合
集合对象的编码有两种:intset 和 hashtable 编码一:intset intset 的结构 整数集合 intset 是集合底层的实现之一,从名字就可以看出,这是专门为整数提供的集合类型. ...
- Redis 设计与实现 10:五大数据类型之有序集合
有序集合 sorted set (下面我们叫zset 吧) 有两种编码方式:压缩列表 ziplist 和跳表 skiplist. 编码一:ziplist zset 在 ziplist 中,成员(mem ...
- Redis数据库 01概述| 五大数据类型
1.NoSQL数据库简介 解决应用服务器的CPU和内存压力:解决数据库服务的IO压力: ----->>> ① session存在缓存数据库(完全在内存里),速度快且数据结构简单: 打 ...
随机推荐
- Python中排序函数sorted和排序方法sort的异同点对比分析
Python中对序列进行排序有两种方法,一种是使用python内置的全局sorted函数,另一种是使用序列内置的sort方法. 一. 两者相同点 在支持sort方法的序列中都可以对序列进行排序: 二者 ...
- PyQt(Python+Qt)学习随笔:QAbstractItemView的SelectionBehavior属性
老猿Python博文目录 老猿Python博客地址 一.概述 SelectionBehavior属性用于控制选择行为操作的数据单位,是指选择时选中数据是按行.按列还是按项来选择.SelectionBe ...
- [BJDCTF2020]ZJCTF,不过如此 php伪协议, preg_replace() 函数/e模式
转自https://www.cnblogs.com/gaonuoqi/p/12499623.html 题目给了源码 <?php error_reporting(0); $text = $_GET ...
- Redis数据库简介
最近的项目需要用到Redis数据库和MySQL,恶补学习. Redis的使用手册可以看: https://redis.io/ https://www.runoob.com/redis/redis-tu ...
- 题解-洛谷P5410 【模板】扩展 KMP(Z 函数)
题面 洛谷P5410 [模板]扩展 KMP(Z 函数) 给定两个字符串 \(a,b\),要求出两个数组:\(b\) 的 \(z\) 函数数组 \(z\).\(b\) 与 \(a\) 的每一个后缀的 L ...
- 【AtCoder AGC023F】01 on Tree(贪心)
Description 给定一颗 \(n\) 个结点的树,每个点有一个点权 \(v\).点权只可能为 \(0\) 或 \(1\). 现有一个空数列,每次可以向数列尾部添加一个点 \(i\) 的点权 \ ...
- Android全面解析之Context机制
前言 很高兴遇见你~ 欢迎阅读我的文章. 在文章Android全面解析之由浅及深Handler消息机制中讨论到,Handler可以: 避免我们自己去手动写 死循环和输入阻塞 来不断获取用户的输入以及避 ...
- Java并发编程的艺术(六)——中断、安全停止线程
什么是中断 Java的一种机制,用于一个线程去暂停另一个线程的运行.就是一个正在运行的线程被其他线程给打断,停止运行挂起了. 我觉得,在Java中,这种中断机制只是一种方便程序员编写进程间的通信罢了. ...
- Maven笔记之核心概念及常用命令
Maven的核心概念 Maven是一款服务于java平台的自动化构建工具. 自动化构建工具还有:make->ant->maven->gradle 1.约定的目录 2.P ...
- Ajax相关基础知识总结
URL:统一资源定位符 网络的七层协议:网卡 驱动 网络层(ip) 传输层(tcp udp) 会话层( ) 应用层(http.) restful表征状态转移(一种表征架构) CURD 增删改查 ...