还不懂mysql的undo log和mvcc?算我输!
最近一直没啥时间写点东西,坚持分享真的好难,也不知道该分享点啥,正好有人要问我这些东西,所以腾出点时间,写一下这个主题。同样本篇可以给读者承诺,听不懂或者没收获算我输,哈哈!
众所周知,mysql中读取方式按照是否需要传统意义的锁,分为锁定读和非锁定读两种。锁定读不用多说,那就一堆算法了,行锁,间隙锁,next-key锁,无非就是为了保证,一个事务中锁定读取一条或者多条数据时,不能读到别的事务没有提交的更改(不能脏读),不能同一个事务两次读到的数据内容不一致(应该要可重复读),不能同一个事务,两次读到的数据条数都不一致(不能幻读)。只要拿到一个锁定读查询,往避免上面三种错误情况,就能很轻松的区分,针对最常见的RR隔离级别,什么情况下至少使用什么类型的锁(行锁,gap锁,next-key锁)才能避免脏读,不可重复读,幻读。又会联系到几个事务级别,从锁粒度从小到大,RU(读未提交),RC(读已提交),RR(可重复读),S(序列化)
RU(读未提交):英文全称就留给读者自己装B了哈哈),很显然,这个级别是最无节操的级别,就相当于我在房间,做秘密的事情,我都还没有觉得别人可以进来,门自己觉得我做完了,然后就给我开了,然后你就进来了,你好歹让我收拾一下把,再通知一下,我做完了,再进来把。当然也不会像有些人理解的门压根没上锁,总要的事情做到一半,你就可以进来,也不会这么没有节操的。在mysql中也就是就算是最低级别RU,也不会让你读到一半数据,所以还是有锁的,只不过这个锁并不是我们自己主观去决定打开的,他会认为每一条数据执行完就可以开锁了。虽然你还没手动提交事务,很显然这种级别,还是会让你看到一些不该看到的东西。脏读估计就是从这里来的把。
RC(读已提交):很显然,只有等我事情做完,并且通知你可以进来了,你才能进来。这样你总不能看到脏东西了吧,但是有一种情况,门开着你进门上厕所,这时候有一卷新卫生纸,然后我进去用了一点,然后门打开你又进去发现纸少了一半,你是不是会怀疑这尼玛怎么两次看到的纸不一样啊,这在生活中很常见,我甚至觉得这个理所当然的没毛病。但是在数据库领域它就是觉得有毛病,比如一段代码,假设你要买一卷纸100块(好吧,我承认有点小贵),先查询你的卡里的钱发现有100,结果这是时候你妹子用微信付款花了50(明显妹子微信绑定你的卡),然后拿纸,扣钱,结果50 - 100 = -50扣款失败。这是什么神仙逻辑,就不能在我交易的过程中不要让妹子可以用钱吗,我想假设查账,扣款要是一个完整的逻辑,biu的一下不需要时间就可以搞定,就不会有这种尴尬了,因为要是每个操作的时间都足够快,要么妹子在我交易之前一刻用50,要么就在我之后一刻50,而不会在我中间一刻用50。我想正是因为我们的系统不可能做到那么快,才需要认为定义这个东西,才会遇到这种不可重复读的情况吧
RR(可重复读):为了解决上面不可重复读的问题,谁让我们条件不够快呢?很显然,我开始要用钱的时候,直接把我的卡的钱锁住,不让别人用,等我交易完才让别人用。
S(序列化):很显然,锁好门,排好队,我的事情确定都做完才放其他人进来
以上回顾了一下锁定读和四种隔离级别,下面进入正题,来说说mvcc和undo log吧。mvcc作为多版本并发控制,使用undo log实现,同样也可以实现上述四种隔离级别,只不过实现手段不是通过传统意义上的锁罢了。当然针对RU(读未提交)隔离级别,所有更改的语句别的事务都可以直接看到,那根本没有保留多个版本的必要,用到的就是最新的唯一版本,同样S(序列化)级别,排队一个个去读写,也根本没有保留多个版本数据的必要,因为都是用最新的数据就行了。
到了这里,要进入正题,其实我想说下为啥,在网上那么一大堆,并且一大堆mysql的好书,我为啥还死皮赖脸的分享undo log和mvcc。还嫌知识不够多不够乱吗?那是因为我之前学习这些,经历过很多误导,可以这么说网上那么一大堆,我还没有看到有一篇博客或者网络课堂,把这两个东西说的准确和清楚的,书上那么一大堆,我想一般人要是不仔细揣摩一阵子,可能永远都会活在自己的世界里,并以之为真理,下面我列举一下网上的那些错误或者说不准确的地方。后续再回过头来看
1)为了实现mvcc,每行数据会多两列DATA_TRX_ID和DATA_ROLL_PTR(有些人也不要抬杠,不对可能还有一列DB_ROW_ID,当没有默认主键时会自动加上这列,请不要说于本篇无关的内容),这时候他们的解释DATA_TRX_ID表示当前数据的事务版本,没啥毛病,DATA_ROLL_PTR表示事务删除版本号,纳尼!ptr一般不是用来表示指针的吗,你跟我说时删除版本号,我书读的少,你不要忽悠我。我不否认用这样的理解方式真的可以让自己感觉理解了,但是面试要问到你这么答真的没毛病吗,除非面试官也这么理解的(菩萨保佑)。
2)mvcc里面使用一个可读视图ReadView来辅助判断那些事务版本号,里面主要有几个元素构成,当前活跃事务ID集合mIds,mIds的最小事务ID,mIds的最大事务ID,网络上的资料99%都是这样描述的,只能说可能那些作者没有理解清楚或者是人云亦云。正确如何后面再解释
3)书上说insert 的undo log区别于delete和update操作的undo log,insert 操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该undo log可以在事务提交后直接删除。而delete和update的undo log需要等待purge线程在合适的条件删除。为啥insert的undo log就可以直接删除,为啥会有区别,各位读者看到这句话是直接死记硬背就满足了吗,你能从这句话看懂是为啥吗,然而可惜的是,至今没看到有哪本书解释过,可能是我书读的少吧。
4)都说redo是物理日志(绝大部分是,不纠结),undo是逻辑日志,并且你新增,undo log会记录删除,你更新他会记录相反的更新,这里有两个点,怎么理解物理日志和逻辑日志,怎么理解是记录相反操作,新增和删除相反可以理解,那更新x = x - 10相反难道是x = x + 10,你减去10,相反我就给你加上10,我相信肯定好大一部分人都这么理解,这么理解就坑大了。
5)mvcc能解决幻读吗?如果能解决为啥就mysql吹嘘RR级别解决了幻读,难道别的数据库没有mvcc,如果不能那怎么敢吹嘘呢?这真的是一个人才问题,后面再谈吧!
我们都知道mysql数据库是以主键ID作为索引使用B+Tree的结构组织整个表的数据,存放在xx.IBD文件中,数据存放在叶子节点块中,每一块都有后一块叶子节点的指针,当然我们这里忘了强调,本篇以InnDB引擎来说明的,不然又要有人纠结了。当然这些基本的索引知识,包括上述描述的各种锁算法,可以自己看书或者别人家博客,或者得空我再分享一篇。
回到正题,MVCC是个什么鬼?
1)官方一点的解释:并发访问(读或写)数据库时,对正在事务内处理的数据做 多版本的管理。以达到用来避免写操作的堵塞,从而引发读操作的并发问题。
2)无节操解释,拿厕所的纸巾举例子,为了让不同的人多次进来看到的纸巾都是一样的,那么每次有人用纸巾,先做个标记版本A,(A能看到的),然后放在一个柜子里,然后复制一个一模一样的纸巾放在纸巾盒里,标记成当前版本(自己看到的)。然后假定做一个看的规则,每个人进来只能根据规则看到之前看到的那卷纸巾,保证每个人多次进来看到的纸巾是一致的,好吧,纸巾真多,够麻烦!后面在详细解释
MVCC是做什么的?
1)用于事务的回滚
2)MVCC
undo log我们关注的类型有哪些?
1)insert undo log
2)update undo log
InnoDB中的MVCC实现原理
数据表增加两个隐藏列DATA_TRX_ID和DATA_ROLL_PTR,用于实现mvcc
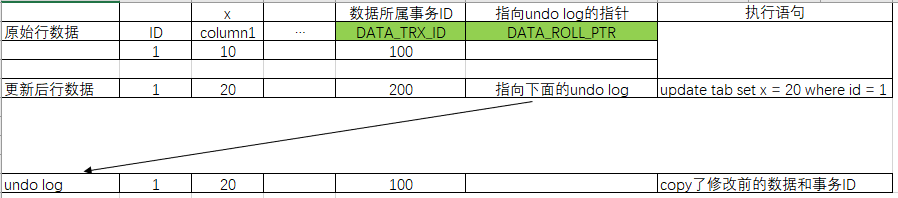
事务 A 对值 x 进行更新之后,该行即产生一个新版本和旧版本。假设之前插入该行的事务 ID 为 100,事务 A 的 ID 为 200。操作过程如下
1)对 ID = 1 的记录加排他锁,毕竟要修改了,总不能加共享锁把
2)把该行原本的值拷贝到 undo log 中
3)修改改行值并且更新 DATA_TRX_ID,将 DATA_ROLL_PTR 指向刚刚拷贝到 undo log 链中的旧版本记录,记住undo log是个链表,如果多个事务多次修改会继续生成undo log并通过DATA_ROLL_PTR建立指向关系
上文中的undo log是一个链表结构,也就是如果多个事务都修改了这行数据,会根据事务ID的先后,以链表形式存放,至于旧版本存放在链表的先后顺序,这个其实无关紧要,只要方便获取就好,我倾向于每次修改后把旧版放在链表的头部,这样可以保证从指针递归下来,先找到较新的数据,再找到更旧的数据,一个个版本去判断是否是自己可以看到的版本。
那么现在的核心问题就是当前事务读取数据的时候如何判断应该读取哪个版本?mysql中引入了一个可读试图ReadView的概念。主要包含如下属性
1)mIds 代表生成ReadView时,当前活跃所有的事务ID,活跃的意思就是事务开启了还没提交,这里可以提一点,事务开启事务ID会自增,实际上事务ID就是一个全局自增的数字
2)min_trx_id 表示当前活跃的mIds中最小的事务ID
3)max_trx_id 表示生成ReadView时,最大的事务ID,这里一定不要理解成mIds中最大的ID,这是一个相当错误的理解,后面再解释
4)creator_trx_id 该ReadView在那个事务里创建的,
ReadView有了上面4个属性后,那么应该以什么样的规则,判断当前事务到底可以读取哪个版本的数据呢?
1)如果被访问版本的 data_trx_id 小于 m_ids 中的最小值,说明生成该版本的事务在 ReadView 生成前就已经提交了,那么该版本可以被当前事务访问。
2)如果被访问版本的 data_trx_id大于当前事务的最大值,说明生成该版本数据的事务在生成 ReadView 后才生成,那么该版本不可以被当前事务访问。为什么这里的最大值不是mIds的最大值,因为事务ID虽然是全局递增的,但是并不代表事务ID大的一定要在事务ID小的后面提交,也就是事务开启有先后,但是事务结束的先后和开启的先后并不是完全一致的,毕竟事务有长有短。如果此时数据的事务版本是200,而mIds中没有200,那么mIds最大值就可能小于200,那么以规则2判断就可能让本该可以访问到的数据因为这个规则,而访问不到了,归根结底就是因为没有正确找到生成ReadView时的最大事务ID,所以不能肯定的说生成该版本数据的事务在生成 ReadView 后才生成
3)如果被访问版本的 data_trx_id属性值在 最大值和最小值之间(包含),那就需要判断一下 trx_id 的值是不是在 m_ids 列表中。如果在,说明创建 ReadView 时生成该版本所属事务还是活跃的,因此该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
通俗点来说,也就是ReadView中通过最大事务ID,mIds最小事务ID,mIds活跃事务列表,将当前要读的数据的事务ID分成了3种情况,要么小于mIds的最小事务ID,很明显又在当前活跃的最小事务之前生成,又不在活跃事务中,一定是已提交的事务,这个版本肯定可以访问;要么大于生成ReadView的当前的最大事务ID,很明显在所有活跃事务之后,并且也不可能存在于活跃事务列表中,那么就说明,该版本在当前活跃事务之后才出现,总不能读取到未来的版本吧;要么处于最大最小值之间,这时候就有两种情况,因为并不是说最大最小值之间就一定是活跃的,毕竟先开启的事务并不一定会先结束,事务有大小长短,这时候就很简单,在mIds中就是还没提交的活跃版本,不可被读取,不在就是已经提交的版本,可以被读取。当一个事务要读取一行数据,首先用上面规则判断数据的最新版本也就是那行记录,如果发现可以访问就直接读取了,如果发现不能访问,就通过DATA_ROLL_PTR指针找到undo log,递归往下去找每个版本,知道读取到自己可以读取的版本为止,如果读取不到那就返回空呗。
还有个问题就是MVCC在RC和RR隔离级别下有啥区别?

很明显,如果是RC级别,那么事务A两次读取到的分别是10和20,如果是RR级别两次读取到的都是10,如果同样由ReadView判断需要怎么样才能区分两个隔离级别取的版本不一样呢?先说RC级别,两个版本不一致,说明可能事务A两次使用的ReadView里的内容肯定是有不一样,结合B事务中间有提交,而提交事务很明显会影响到mIds当前活跃事务列表,因为事务提交之后就不是活跃事务了不可能再出现在mIds列表中了,这一点很好理解。再来看RR隔离级别事务A,如果要两次读取的x值一致,除非两次用来判定的ReadView没有啥变化,这不由得让我们想起了缓存的用法,是不是可以在A事务开启的时候生成一个ReadView,然后在整个A事务期间都用这一份ReadView就行了呢,就像用缓存一样。而RC级别每次查询都生成一个最新的ReadView,是不是就可以产生区别了,这算是一个比较常规并且巧妙的设计了。
目前为止,应该基本了解了mvcc和undo log是咋回事,那么接下来就该回到刚开始提到的,网上各种博客,在线课堂,甚至书上,所讲到的错误,不准确和模糊的地方了,为了凑字数(开个玩笑,为了方便一个个说清楚),再次copy一下上面的问题。
1)为了实现mvcc,每行数据会多两列DATA_TRX_ID和DATA_ROLL_PTR(有些人也不要抬杠,不对可能还有一列DB_ROW_ID,当没有默认主键时会自动加上这列,请不要说于本篇无关的内容),这时候他们的解释DATA_TRX_ID表示当前数据的事务版本,没啥毛病,DATA_ROLL_PTR表示事务删除版本号。
2)mvcc里面使用一个可读视图ReadView来辅助判断那些事务版本号,里面主要有几个元素构成,当前活跃事务ID集合mIds,mIds的最小事务ID,mIds的最大事务ID,网络上的资料99%都是这样描述的,只能说可能那些作者没有理解清楚或者是人云亦云。正确如何后面再解释
3)书上说insert 的undo log区别于delete和update操作的undo log,insert 操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该undo log可以在事务提交后直接删除。而delete和update的undo log需要等待purge线程在合适的条件删除。为啥insert的undo log就可以直接删除,为啥会有区别,各位读者看到这句话是直接死记硬背就满足了吗,你能从这句话看懂是为啥吗,然而可惜的是,至今没看到有哪本书解释过,可能是我书读的少吧。
4)都说redo是物理日志(绝大部分是,不纠结),undo是逻辑日志,并且你新增,undo log会记录删除,你更新他会记录相反的更新,这里有两个点,怎么理解物理日志和逻辑日志,怎么理解是记录相反操作,新增和删除相反可以理解,那更新x = x - 10相反难道是x = x + 10,你减去10,相反我就给你加上10,我相信肯定好大一部分人都这么理解,这么理解就坑大了。
5)mvcc能解决幻读吗?如果能解决为啥就mysql能吹嘘RR级别解决了幻读。
对于问题1)我想不用说了,这个很明确了,不管看哪本书都不会这么讲,PTR一般都表示指针了,要说删除版本号,怎么不叫ROLL_ID呢,从基本的单词解释都不可能是删除版本号吧,不纠结了。
对于问题2)ReadView中假设那么最大事务ID是mIds里的最大事务ID,那当我要读取的数据版本号大于这个活跃的最大事务ID,就一定认为我这个数据的版本是在生成ReadView之后了吗,先开启的事务一定会先提交吗,当前最大的活跃事务ID,一定是当时最大的事务ID吗?这不刚生成ReadView的时候好几个大事务ID提交了,不行吗?
对于问题3)insert undo log和update undo log为啥要分开,为啥提交之后insert undo log可以直接删除了,update undo log还要命苦的等着purge呢?首先insert的特殊性,如果某个事务ID=100新增了一条记录,那么在这个事务版本之前这个记录是不存在的,也就是这条数据要么就是事务100提交,然后就存在这条数据了,事务100没有提交,这条数据就是null,那么请问还需要mvcc多版本控制吗,这条数据本身不就是一个版本吗,要么就是不存在,读取不到,要么就是存在,可以读取,数据是否存在,在RC和RR级别不就看事务有没有提交吗,至于RU和S前面早就说了不需要用到MVCC了。不用纠结数据在哪里读取出来的,是缓存还是磁盘,也不用纠结事务提交后数据是否真的落磁盘了,总之提交后数据可以被读取到,没提交数据就读取不到,我想这就是书上所说的事务隔离性的要求吧。所以根本不需要用到多版本的冗余,当然事务提交就可以直接删除insert的undo log了。至于update的undo log可能同时存在事务A,B,C在修改数据,到底是事务A,B或者C提交后就删除undo log呢,显然不知道吧,所以要等到purge线程事后再决定啥时候删除了。
对于问题4)redo确实绝大部分是物理日志,物理日志的意思就是有个日志文件存放,记录了每个物理地址目前的值到底是多少,至于undo log,存在于一个特殊的段中,存在于表空间中,很明显就是和主键id组织的数据存在一个文件中,毕竟每行数据都有个指向undo log的指针了,合并单独放在一个文件中呢。如果一个新增操作,undo log记录的是一个删除类型,甚至都不需要copy任何数据,当读到这个版本,发现了删除标记,就可以直接返回null了,如果是个更新操作,那么copy一下更新前的值,没有更新的当然不用copy,也并不需要记录某个物理地址上是某个特定的值,当你读到这个undo log,那么就把读到的数据根据需要更新成undo log里对应的数据就行了。如果是一个删除操作,则将这行记录copy到undo log中,然后将原始数据标记成已经删除。这种日志难道不能看成是一种逻辑日志吗,与当前操作相反的一种逻辑日志,不需要记录对应物理地址上是些什么内容的逻辑日志。
对于问题5)乍一看很唬人,很容易把你唬懵了。先搞清楚幻读怎么产生的,假如事务A中先后读取了age>10的数据(age加了索引),第一次读取了一条age=12的,由于紧随其后事务B又插入了一条13,导致事务A接着第二次查询发现获取了两条数据,说好的一条,怎么现在是两条,是不是我喝醉酒眼花了产生了幻觉。而在mysql的锁定读场进很明显通过间隙锁/next-key锁解决了幻读,当我读取age>10的时候,就把我周围右边的间隙的范围都给锁住,其它事务休想再插入age>10的数据,然后就解决了幻读,从源头上就让你不能插入。再来说mvcc,在RR隔离级别,当事务A开启的时候会生成一个事务的快照ReadView,里面记录了当前生成的最大事务ID,假定事务A第一次查询就一条记录,这时候事务B的事务ID最多存在两种可能,要么此时正在运行还没提交(废话你要提交了,我怎么可能就读到一条),那就一定在mIds列表里,要么此时该事务还没生成,那么事务B插入的时候,该数据的事务版本必然是大于当前ReadView中的事务最大值的,不管是从那种情况来看根据ReadView的判别规则该数据都不可能读到。我就不明白为啥网上一大把人义正严词的说单凭mvcc解决不了幻读,信息时代网上一大把资料有的说可以解决,有的说不能解决,但是又不给理由,渐渐的就让人们分成两个派别了,苦恼啊!其实我觉得mvcc天然就可以解决幻读,并且基本所有现代关系型数据库都有mvcc的实现,我有理由相信那些数据库的快照读都解决了幻读(个人猜测,毕竟没有深入研究过其它数据库)。我想人们都说mysql的RR可以解决幻读其它数据库不行,那只是针对锁定读,因为mysql 的RR级别有间隙锁,其它数据库没有这种算法,所以这么说把。不相信的人可以多看几遍上面的推理过程也可以开两个连接,准备如下两个语句,上述所得两种情况分别对应事务A和B先后执行begin,自己去测试下,没有什么比自己亲自测试让人相信了。
- -- 事务A
begin;- select * from test where age > 10;
- -- 先执行上面两句,再去别的连接执行插入
- select * from test where age > 10;
- rollback;
- -- 事务B
begin;- insert into test(age) values(13);
- COMMIT;

我也看了网上一些测试,其实很多人在事务A中间加入一个更新语句让以前查不到的数据,第二次可以查到,我想说这种自己事务的操作,自己难道都不能看到吗?这是幻读吗,要是自己事务里面的修改,自己都看不到,我估计你要怀疑数据库出毛病了吧,刚修改居然看不到。我说你怎么不在事务A加一条插入age=13的语句再查询呢,绝对可以查到,自己插入修改的自己都看不到,那不是幻读了那是错误了。不信可以把事务A两个语句都加上for update,然后中间修改或者插入一条居于,现象都是一样的,因为一般都是可重入的,不会锁自己锁自己的。
至此,基本理论知识都告一段落了,如果你们以为这样就完了,那只能说你们想多了,哈哈,作为一个专业的码农,当然是要亮出代码,下面我会将自己的理解用java代码的方式写一套简单的关于MVCC,ReadView和UNDO LOG的逻辑,代码是最简单的流水帐的模式,目的只是为了程序猿们能进一步理解本篇说的所有内容,如有雷同绝对是抄袭我的,哈哈!
- package com.mvcc;
- import java.util.ArrayList;
- import java.util.Collections;
- import java.util.List;
- import java.util.Map;
- import java.util.concurrent.ConcurrentHashMap;
- import java.util.concurrent.atomic.AtomicInteger;
- /**
- * 事务类,只是为了方便看懂原理和避免偏离主题,所以这里省略了本应该需要用到的锁
- * @author rongdi
- * @date 2020-07-25 20:17
- */
- public class Transaction {
- /**
- * 全局事务id
- */
- private static AtomicInteger globalTrxId = new AtomicInteger();
- /**
- * 当前活跃的事务
- */
- private static Map<Integer,Transaction> currRunningTrxMap = new ConcurrentHashMap<>();
- /**
- * 当前事务id
- */
- private Integer currTrxId = 0;
- /**
- * 事务隔离级别,ru,rc,rr和s
- */
- private String trxMode = "rr";
- /**
- * 只有rc和rr级别非锁定读才需要用到mvcc,这个readView是为了方便判断到底哪个版本的数据可以被
- * 当前事务获取到的视图工具
- */
- private ReadView readView;
- /**
- * 开启事务
- */
- public void begin() {
- /**
- * 根据全局事务计数器拿到当前事务ID
- */
- currTrxId = globalTrxId.incrementAndGet();
- /**
- * 将当前事务放入当前活跃事务映射中
- */
- currRunningTrxMap.put(currTrxId,this);
- /**
- * 构造或者更新当前事务使用的mvcc辅助判断视图ReadView
- */
- updateReadView();
- }
- /**
- * 构造或者更新当前事务使用的mvcc辅助判断视图ReadView
- */
- public void updateReadView() {
- /**
- * 构造辅助视图工具ReadView
- */
- readView = new ReadView(currTrxId);
- /**
- * 设置当前事务最大值
- */
- readView.setMaxTrxId(globalTrxId.get());
- List<Integer> mIds = new ArrayList<>(currRunningTrxMap.keySet());
- Collections.sort(mIds);
- /**
- * 设置当前活跃事务id
- */
- readView.setmIds(new ArrayList<>(currRunningTrxMap.keySet()));
- /**
- * 设置mIds中最小事务ID
- */
- readView.setMinTrxId(mIds.isEmpty()? 0 : mIds.get(0));
- /**
- * 设置当前事务ID
- */
- readView.setCurrTrxId(currTrxId);
- }
- /**
- * 提交事务
- */
- public void commit() {
- currRunningTrxMap.remove(currTrxId);
- }
- public static AtomicInteger getGlobalTrxId() {
- return globalTrxId;
- }
- public static void setGlobalTrxId(AtomicInteger globalTrxId) {
- Transaction.globalTrxId = globalTrxId;
- }
- public static Map<Integer, Transaction> getCurrRunningTrxMap() {
- return currRunningTrxMap;
- }
- public static void setCurrRunningTrxMap(Map<Integer, Transaction> currRunningTrxMap) {
- Transaction.currRunningTrxMap = currRunningTrxMap;
- }
- public Integer getCurrTrxId() {
- return currTrxId;
- }
- public void setCurrTrxId(Integer currTrxId) {
- this.currTrxId = currTrxId;
- }
- public String getTrxMode() {
- return trxMode;
- }
- public void setTrxMode(String trxMode) {
- this.trxMode = trxMode;
- }
- public ReadView getReadView() {
- return readView;
- }
- }
- package com.mvcc;
- import java.util.ArrayList;
- import java.util.List;
- /**
- * 模拟mysql中的ReadView
- * @author rongdi
- * @date 2020-07-25 20:31
- */
- public class ReadView {
- /**
- * 记录当前活跃的事务ID
- */
- private List<Integer> mIds = new ArrayList<>();
- /**
- * 记录当前活跃的最小事务ID
- */
- private Integer minTrxId;
- /**
- * 记录当前最大事务ID,注意并不是活跃的最大ID,包括已提交的,因为有可能最大的事务ID已经提交了
- */
- private Integer maxTrxId;
- /**
- * 记录当前生成readView时的事务ID
- */
- private Integer currTrxId;
- public ReadView(Integer currTrxId) {
- this.currTrxId = currTrxId;
- }
- public Data read(Data data) {
- /**
- * 先判断当前最新数据是否可以访问
- */
- if(canRead(data.getDataTrxId())) {
- return data;
- }
- /**
- * 获取到该数据的undo log引用
- */
- UndoLog undoLog = data.getNextUndoLog();
- do {
- /**
- * 如果undoLog存在并且可读,则合并返回
- */
- if(undoLog != null && canRead(undoLog.getTrxId())) {
- return merge(data,undoLog);
- }
- /**
- * 还没找到可读版本,继续获取下一个更旧版本
- */
- undoLog = undoLog.getNext();
- } while(undoLog != null && undoLog.getNext() != null);
- /**
- * 整个undo log链都找不到可读的,没办法了我也帮不鸟你
- */
- return null;
- }
- /**
- * 合并最新数据和目标版本的undo log数据,返回最终可访问数据
- */
- private Data merge(Data data,UndoLog undoLog) {
- if(undoLog == null) {
- return data;
- }
- /**
- * update 更新 直接把undo保存的数据替换过来返回
- * add 新增 直接把undo保存的数据替换过来返回
- * del 删除 数据当时是不存在的,直接返回null就好了
- */
- if("update".equalsIgnoreCase(undoLog.getOperType())) {
- data.setValue(undoLog.getValue());
- return data;
- } else if("add".equalsIgnoreCase(undoLog.getOperType())) {
- data.setId(undoLog.getRecordId());
- data.setValue(undoLog.getValue());
- return data;
- } else if("del".equalsIgnoreCase(undoLog.getOperType())) {
- return null;
- } else {
- //其余情况,不管了,直接返回算了
- return data;
- }
- }
- private boolean canRead(Integer dataTrxId) {
- /**
- * 1.如果当前数据的所属事务正好是当前事务或者数据的事务小于mIds的最小事务ID,
- * 则说明产生该数据的事务在生成ReadView之前已经提交了,该数据可以访问
- */
- if(dataTrxId == null || dataTrxId.equals(currTrxId) || dataTrxId < minTrxId) {
- return true;
- }
- /**
- * 2.如果当前数据所属事务大于当前最大事务ID(并不是mIds的最大事务,好多人都觉得是),则
- * 说明产生该数据是在生成ReadView之后,则当前事务不可访问
- */
- if(dataTrxId > maxTrxId) {
- return false;
- }
- /**
- * 3.如果当前数据所属事务介于mIds最小事务和当前最大事务ID之间,则需要进一步判断
- */
- if(dataTrxId >= minTrxId && dataTrxId <= maxTrxId) {
- /**
- * 如果当前数据所属事务包含在mIds当前活跃事务列表中,则说明该事务还没提交,
- * 不可访问,反之表示数据所属事务已经提交了,可以访问
- */
- if(mIds.contains(dataTrxId)) {
- return false;
- } else {
- return true;
- }
- }
- return false;
- }
- public List<Integer> getmIds() {
- return mIds;
- }
- public void setmIds(List<Integer> mIds) {
- this.mIds = mIds;
- }
- public Integer getMinTrxId() {
- return minTrxId;
- }
- public void setMinTrxId(Integer minTrxId) {
- this.minTrxId = minTrxId;
- }
- public Integer getMaxTrxId() {
- return maxTrxId;
- }
- public void setMaxTrxId(Integer maxTrxId) {
- this.maxTrxId = maxTrxId;
- }
- public Integer getCurrTrxId() {
- return currTrxId;
- }
- public void setCurrTrxId(Integer currTrxId) {
- this.currTrxId = currTrxId;
- }
- }
- package com.mvcc;
- import java.util.Map;
- import java.util.concurrent.ConcurrentHashMap;
- /**
- * 模仿数据库的数据存储地方
- * @author rongdi
- * @date 2020-07-25 19:24
- */
- public class Data {
- /**
- * 模拟一个存放数据的表
- */
- private static Map<Integer,Data> dataMap = new ConcurrentHashMap<>();
- /**
- * 记录的ID
- */
- private Integer id;
- /**
- * 记录的数据
- */
- private String value;
- /**
- * 记录当前记录的事务ID
- */
- private Integer dataTrxId;
- /**
- * 指向上个版本的undo log的引用
- */
- private UndoLog nextUndoLog;
- /**
- * 标记数据是否删除,实际数据库会根据情况由purge线程完成真实数据的清楚
- */
- private boolean isDelete;
- public Data(Integer dataTrxId) {
- this.dataTrxId = dataTrxId;
- }
- /**
- * 模拟数据库更新操作,这里就不要自增id,直接指定id了
- * @param id
- * @param value
- * @return
- */
- public Integer update(Integer id,String value) {
- /**
- * 获取原值,这里就不判断是否存在,于本例核心偏离的逻辑了
- */
- Data oldData = dataMap.get(id);
- /**
- * 更新当前数据
- */
- this.id = id;
- this.value = value;
- /**
- * 不要忘了,为了数据的一致性,要准备好随时失败回滚的undo log,这里既然是修改数据,那代表以前
- * 这条数据是就记录一下以前的旧值,将旧值构造成一个undo log记录
- */
- UndoLog undoLog = new UndoLog(id,oldData.getValue(),oldData.getDataTrxId(),"update");
- /**
- * 将旧值的undo log挂到当前新的undo log之后,形成一个按从新到旧顺序的一个undo log链表
- */
- undoLog.setNext(oldData.getNextUndoLog());
- /**
- * 将当前数据的undo log引用指向新生成的undo log
- */
- this.nextUndoLog = undoLog;
- /**
- * 更新数据表当前id的数据
- */
- dataMap.put(id,this);
- return id;
- }
- /**
- * 按照上面更新操作的理解,删除相当于是把原纪录修改成标记成已删除状态的记录了
- * @param id
- */
- public void delete(Integer id) {
- /**
- * 获取原值,这里就不判断是否存在,于本例核心偏离的逻辑了
- */
- Data oldData = dataMap.get(id);
- this.id = id;
- /**
- * 将当前数据标记成已删除
- */
- this.setDelete(true);
- /**
- * 同样,为了数据的一致性,要准备好随时失败回滚的undo log,这里既然是删除数据,那代表以前
- * 这条数据存在,就记录一下以前的旧值,并将旧值构造成一个逻辑上新增的undo log记录
- */
- UndoLog undoLog = new UndoLog(id,oldData.getValue(),oldData.getDataTrxId(),"add");
- /**
- * 将旧值的undo log挂到当前新的undo log之后,形成一个按从新到旧顺序的一个undo log链表
- */
- undoLog.setNext(oldData.getNextUndoLog());
- /**
- * 将当前数据的undo log引用指向新生成的undo log
- */
- this.nextUndoLog = undoLog;
- /**
- * 更新数据表当前id的数据
- */
- dataMap.put(id,this);
- }
- /**
- * 按照上面更新操作的理解,新增相当于是把原纪录原来不存在的记录修改成了新的记录
- * @param id
- */
- public void insert(Integer id,String value) {
- /**
- * 更新当前数据
- */
- this.id = id;
- this.value = value;
- /**
- * 同样,为了数据的一致性,要准备好随时失败回滚的undo log,这里既然是新增数据,那代表以前
- * 这条数据不存在,就记录一下以前为空值,并将空值构造成一个逻辑上删除的undo log记录
- */
- UndoLog undoLog = new UndoLog(id,null,null,"delete");
- /**
- * 将当前数据的undo log引用指向新生成的undo log
- */
- this.nextUndoLog = undoLog;
- /**
- * 更新数据表当前id的数据
- */
- dataMap.put(id,this);
- }
- /**
- * 模拟使用mvcc非锁定读,这里的mode表示事务隔离级别,只有rc和rr级别才需要用到mvcc,同样为了方便,
- * 使用英文表示隔离级别,rc表示读已提交,rr表示可重复读
- */
- public Data select(Integer id) {
- /**
- * 拿到当前事务,然后判断事务隔离级别,如果是rc,则执行一个语句就要更新一下ReadView,这里写的
- * 这么直接就是为了好理解
- */
- Transaction currTrx = Transaction.getCurrRunningTrxMap().get(this.getDataTrxId());
- String trxMode = currTrx.getTrxMode();
- if("rc".equalsIgnoreCase(trxMode)) {
- currTrx.updateReadView();
- }
- /**
- * 拿到当前事务辅助视图ReadView
- */
- ReadView readView = currTrx.getReadView();
- /**
- * 模拟根据id取出一行数据
- */
- Data data = Data.getDataMap().get(id);
- /**
- * 使用readView判断并读取当前事务可以读取到的最终数据
- */
- return readView.read(data);
- }
- public static Map<Integer, Data> getDataMap() {
- return dataMap;
- }
- public static void setDataMap(Map<Integer, Data> dataMap) {
- Data.dataMap = dataMap;
- }
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getValue() {
- return value;
- }
- public void setValue(String value) {
- this.value = value;
- }
- public Integer getDataTrxId() {
- return dataTrxId;
- }
- public void setDataTrxId(Integer dataTrxId) {
- this.dataTrxId = dataTrxId;
- }
- public UndoLog getNextUndoLog() {
- return nextUndoLog;
- }
- public void setNextUndoLog(UndoLog nextUndoLog) {
- this.nextUndoLog = nextUndoLog;
- }
- public boolean isDelete() {
- return isDelete;
- }
- public void setDelete(boolean delete) {
- isDelete = delete;
- }
- @Override
- public String toString() {
- return "Data{" +
- "id=" + id +
- ", value='" + value + '\'' +
- '}';
- }
- }
- package com.mvcc;
- /**
- * 模仿undo log链
- * @author rondi
- * @date 2020-07-25 19:52
- */
- public class UndoLog {
- /**
- * 指向上一个undo log
- */
- private UndoLog pre;
- /**
- * 指向下一个undo log
- */
- private UndoLog next;
- /**
- * 记录数据的ID
- */
- private Integer recordId;
- /**
- * 记录的数据
- */
- private String value;
- /**
- * 记录当前数据所属的事务ID
- */
- private Integer trxId;
- /**
- * 操作类型,感觉用整型好一点,但是如果用整型,又要搞个枚举,麻烦,所以直接用字符串了,能表达意思就好
- * update 更新
- * add 新增
- * del 删除
- */
- private String operType;
- public UndoLog(Integer recordId, String value, Integer trxId, String operType) {
- this.recordId = recordId;
- this.value = value;
- this.trxId = trxId;
- this.operType = operType;
- }
- public UndoLog getPre() {
- return pre;
- }
- public void setPre(UndoLog pre) {
- this.pre = pre;
- }
- public UndoLog getNext() {
- return next;
- }
- public void setNext(UndoLog next) {
- this.next = next;
- }
- public Integer getRecordId() {
- return recordId;
- }
- public void setRecordId(Integer recordId) {
- this.recordId = recordId;
- }
- public String getValue() {
- return value;
- }
- public void setValue(String value) {
- this.value = value;
- }
- public Integer getTrxId() {
- return trxId;
- }
- public void setTrxId(Integer trxId) {
- this.trxId = trxId;
- }
- public String getOperType() {
- return operType;
- }
- public void setOperType(String operType) {
- this.operType = operType;
- }
- }
一共就四个类,敢兴趣的读者可以写个测试类,然后开几个线程,每个事务使用一个线程模拟,并加上睡眠延时去跑一下代码。再次强调,本代码只是为了让读者理解一下上面说的理论知识,并不是mysql的真实实现,可以理解成作者本人认为的一种可行的简单实现。回顾全文,发现真心不知道如何排版,艺术能力有限,自我感觉只是把问题说清楚了,希望各位见谅!好了,下次再见吧!
还不懂mysql的undo log和mvcc?算我输!的更多相关文章
- mysql的undo log和redo log
在数据库系统中,既有存放数据的文件,也有存放日志的文件.日志在内存中也是有缓存Log buffer,也有磁盘文件log file,本文主要描述存放日志的文件. MySQL中的日志文件,有这么两 ...
- 看完这篇还不懂 MySQL 主从复制,可以回家躺平了~
大家好,我是小羽. 我们在平时工作中,使用最多的数据库就是 MySQL 了,随着业务的增加,如果单单靠一台服务器的话,负载过重,就容易造成宕机. 这样我们保存在 MySQL 数据库的数据就会丢失,那么 ...
- 还不懂MySQL索引?这1次彻底搞懂B+树和B-树
前言 看了很多关于索引的博客,讲的大同小异.但是始终没有让我明白关于索引的一些概念,如B-Tree索引,Hash索引,唯一索引….或许有很多人和我一样,没搞清楚概念就开始研究B-Tree,B+Tree ...
- 详细分析MySQL事务日志(redo log和undo log)
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- 详细分析MySQL事务日志(redo log和undo log) 表明了为何mysql不会丢数据
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- MySQL 详细解读undo log :insert undo,update undo
转自aobao.org/monthly/2015/04/01/ 本文是对整个Undo生命周期过程的阐述,代码分析基于当前最新的MySQL5.7版本.本文也可以作为了解整个Undo模块的代码导读.由于涉 ...
- 详细分析MySQL事务日志(undo log)
2.undo log 2.1 基本概念 undo log有两个作用:提供回滚和多个行版本控制(MVCC). 在数据修改的时候,不仅记录了redo,还记录了相对应的undo,如果因为某些原因导致事务失败 ...
- 【Mysql】三大日志 redo log、bin log、undo log
@ 目录 redo log(物理日志\重做日志) binlog(逻辑日志/归档日志) update语句执行流程 Uodolog(回滚日志/重做日志) undo log+redo log保证持久性 re ...
- 3000帧动画图解MySQL为什么需要binlog、redo log和undo log
全文建立在MySQL的存储引擎为InnoDB的基础上 先看一条SQL如何入库的: 这是一条很简单的更新SQL,从MySQL服务端接收到SQL到落盘,先后经过了MySQL Server层和InnoDB存 ...
随机推荐
- ssh -i 密钥文件无法登陆问题
一.用ssh 带密钥文件登录时候,发生以下报错 [root@99cloud1 ~]# ssh -i hz-keypair-demo.pem centos@172.16.17.104The authen ...
- 深入理解JavaScript系列(2):揭秘命名函数表达式(转)
前言 网上还没用发现有人对命名函数表达式进去重复深入的讨论,正因为如此,网上出现了各种各样的误解,本文将从原理和实践两个方面来探讨JavaScript关于命名函数表达式的优缺点. 简 单的说,命名函数 ...
- Oracle 11g各种服务作用以及哪些需要开启
Windwos server 2012 R2上成功安装Oracle 11g后共有7个服务,如果全局数据库名为orcl,则Oracle服务分别为 Oracle ORCL VSSWriter Servic ...
- pycharm中导入包失败的解决办法
将鼠标移动到requests处,出现如下提示 按住alt+enter键,点击install package requests即可安装requests包 安装成功后
- Spring Boot + Vue + Shiro 实现前后端分离、权限控制
本文总结自实习中对项目的重构.原先项目采用Springboot+freemarker模版,开发过程中觉得前端逻辑写的实在恶心,后端Controller层还必须返回Freemarker模版的ModelA ...
- css获取除第一个之外的子元素
在前端页面开发中,需要使用css来选择除了第一个之外的子元素,例如希望每个span之间能间隔一定的距离,单不能给每个span设置margin-left,这样会导致第一个span的前面有间距,影响排版. ...
- 转载---最简单的JavaScript模板引擎
转载自:http://www.cnblogs.com/dolphinX/p/3489269.html,http://blog.jobbole.com/56689/
- Redis哨兵集群创建脚本--v1
基础环境 操作系统版本 CentOS Linux release 7.6.1810 (Core) Docker 版本 19.03.11, build 42e35e61f3 Redis 版本 3 ...
- 结合实际需求,在webapi内利用WebSocket建立单向的消息推送平台,让A页面和服务端建立WebSocket连接,让其他页面可以及时给A页面推送消息
1.需求示意图 2.需求描述 原本是为了给做unity3d客户端开发的同事提供不定时的消息推送,比如商城购买道具后服务端将道具信息推送给客户端. 本篇文章简化理解,用“相关部门开展活动,向全市人民征集 ...
- Windows配置Delve的测试环境
引言 自己最近在玩Go,在开发一些项目的时候需要调试,由于之前都是在GoLand上写的,但是这个IDE启动太慢并且不轻便.并且自己之前很多项目都是在Vscode中编写的,所以特意想在Vscode中配置 ...