日志分析平台ELK之日志收集器logstash常用插件配置
前文我们了解了logstash的工作流程以及基本的收集日志相关配置,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13761906.html;今天我们来了解下logstash的常用input插件和filter插件的相关配置;
先说filter插件吧,继续上一篇博客的环境,我们配置logstash收集httpd的访问日志;
示例:配置logstash收集日志的时间戳为日志生成时的时间戳
未配置date过滤器规则时,输出的文档信息是

提示:未配置date过滤器规则时,生成的文档中的时间戳信息是不一样的;@timestamp是指收集日志时的时间,timestamp是日志生成时的时间;
配置date过滤器规则,让生成日志的时间替换收集日志时的时间
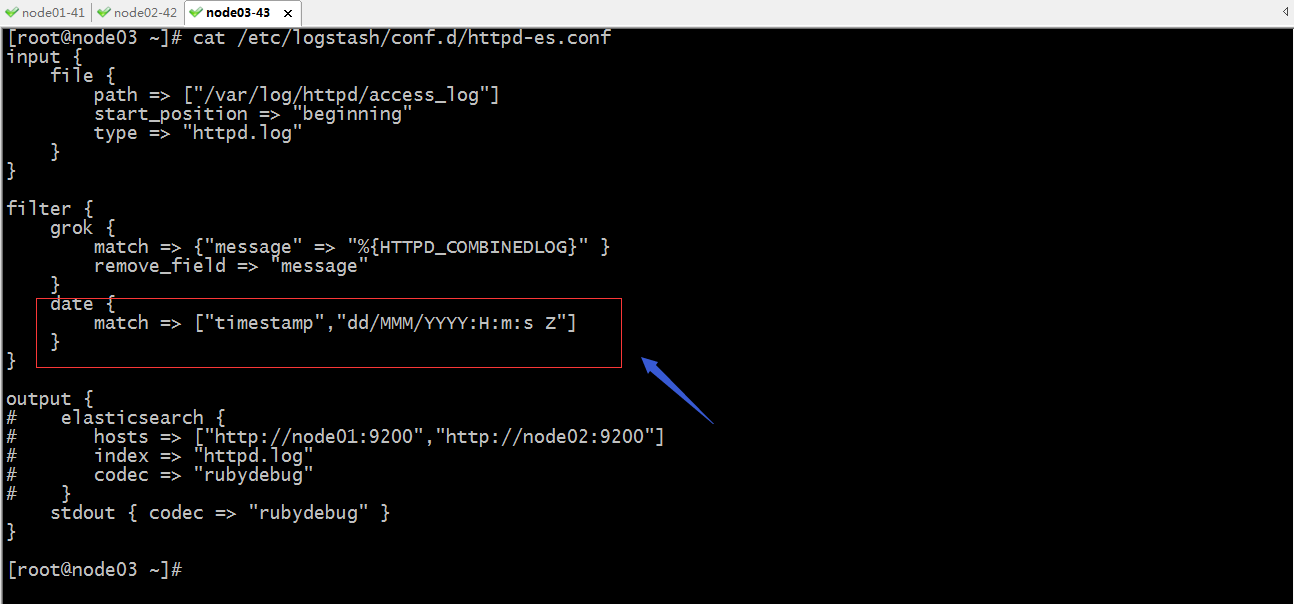
提示:以上红框中的配置表示把timestamp字段的时间替换@timestamp字段的时间,时间格式为标准的格林威治时间;
验证:启动logstash,看看输出的日志中的@timestamp字段的时间是否还是收集日志的时间呢?

提示:现在收集日志的时间就变成了日志生成时的时间了;只不过一个是格林威治标准时间,一个是东八区时间,两个时间相差8小时;这样配置以后,对于timestamp这个字段就显得多余,我们可以使用remove_field去删除timestamp字段即可;如下

示例:配置logstash收集httpd访问日志,基于clientip做地理位置分析
下载GeoLite2-City数据库到本地,这个数据库可以去maxmind官方去下载即可,我这里已经提前下载好了,直接传到服务器上即可;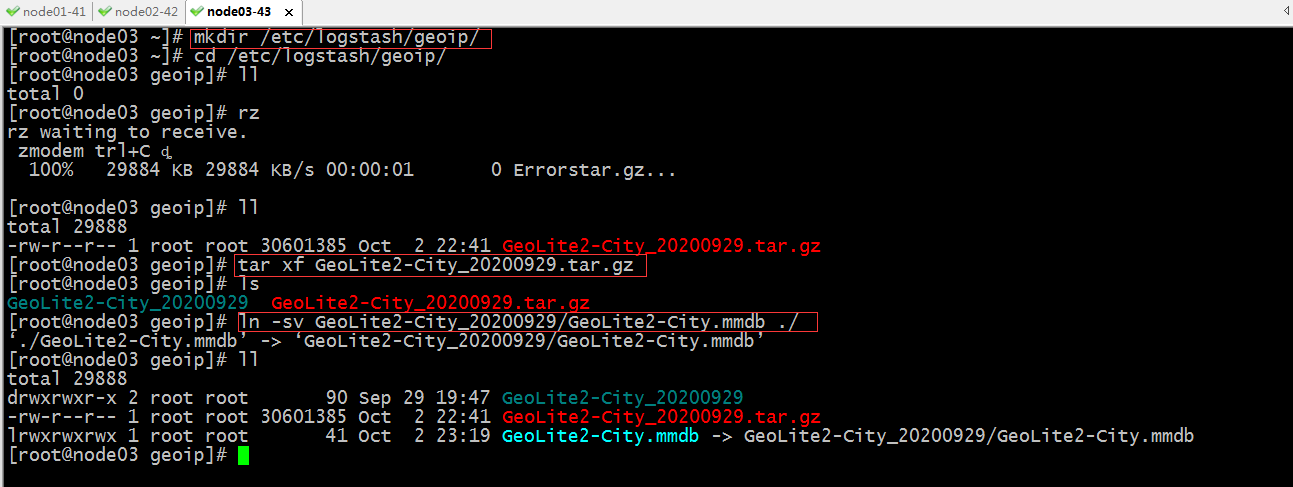
提示:以上主要把GeoLite2-City包上传到指定目录,然后解压,把GeoLite2-City.mmdb数据库文件在指定目录做了一个软连接;这样做的原因是日后方便更新数据库;
配置logstash过滤规则,让其能够基于httpd的访问日志中的clientip做地理位置分析
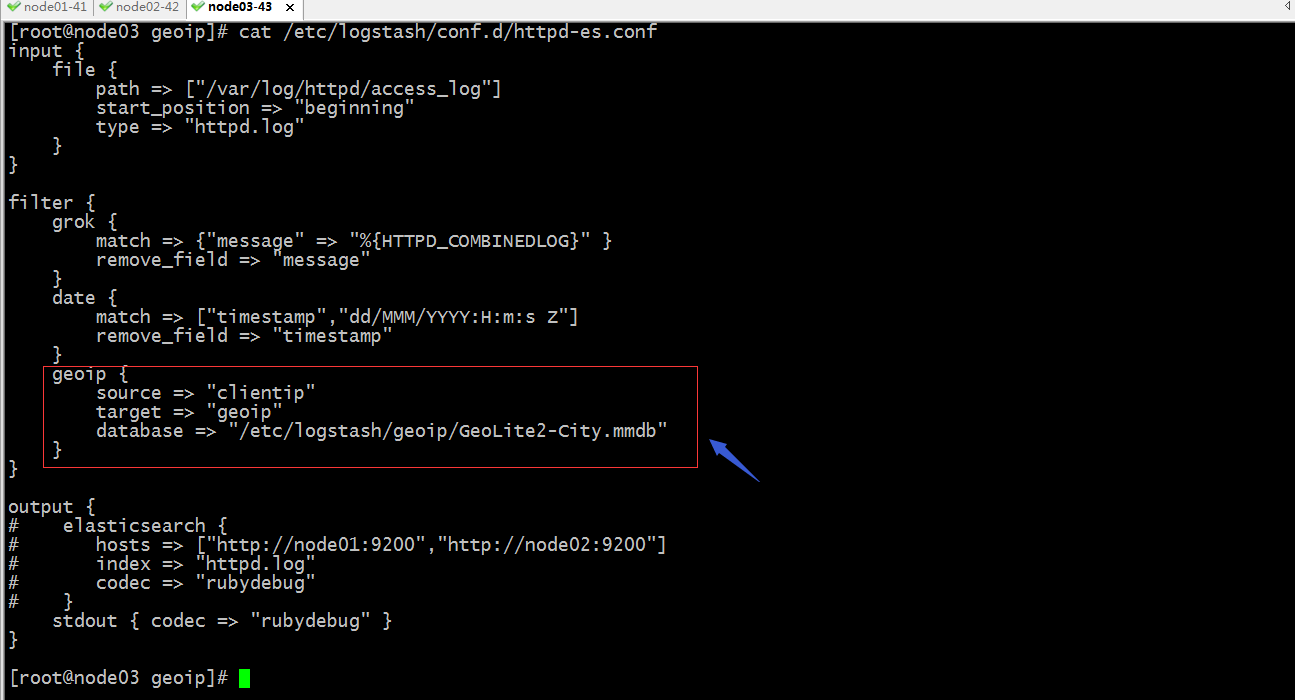
提示:以上配置表示使用geoip过滤器插件,其中source表示以那个字段的值作为ip地址分析,target表示分析后的结果保存在那个字段上,database表示用那个数据库文件;
验证:启动logstash,看看现在输出的文档是否有geoip字段?里面是否记录了clientip的ip地址信息呢?
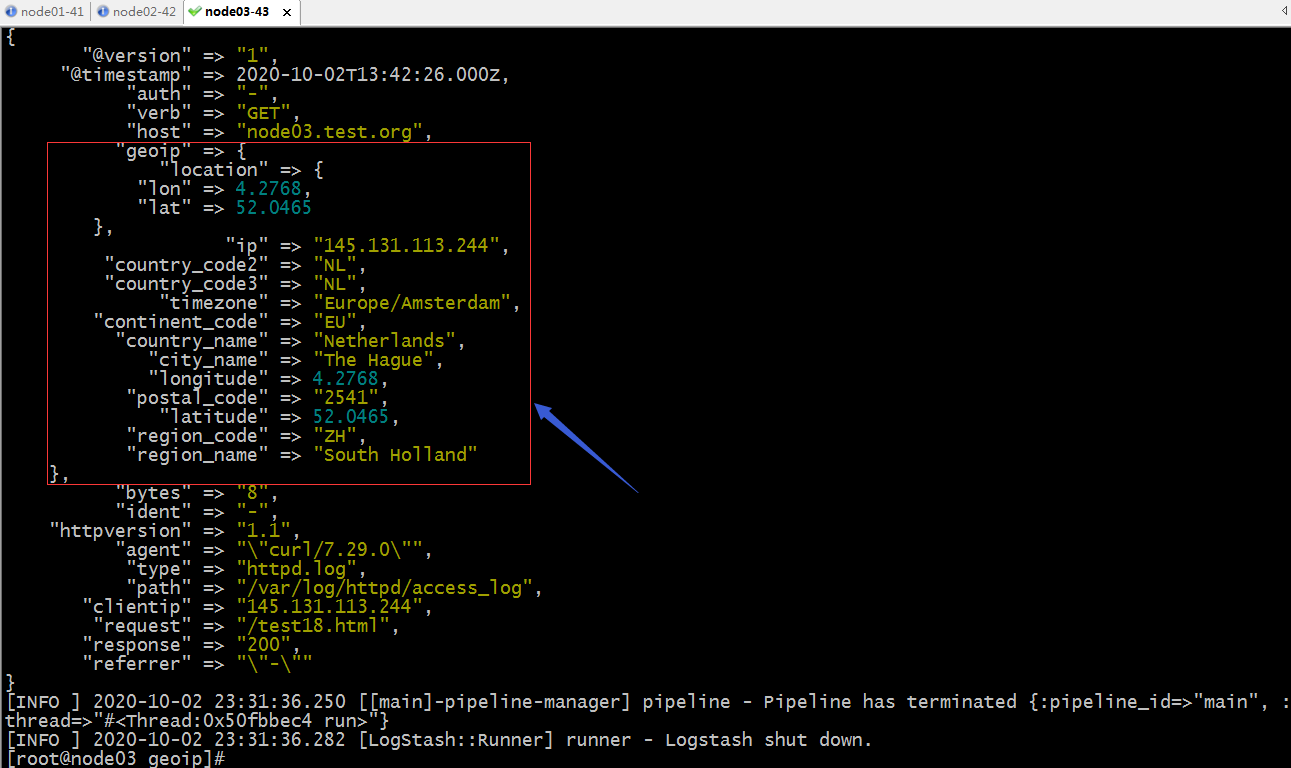
提示:可以看到配置了geoip过滤器插件以后,对应的文档中的geoip字段就把对应的clientip的位置信息分析后,加入到文档中了;这样经过logstash分析以后,我们就可以在kibana中配置区域地图来查看访问我们网站的客户端分布在世界地图的那些位置;
示例:修改字段名称
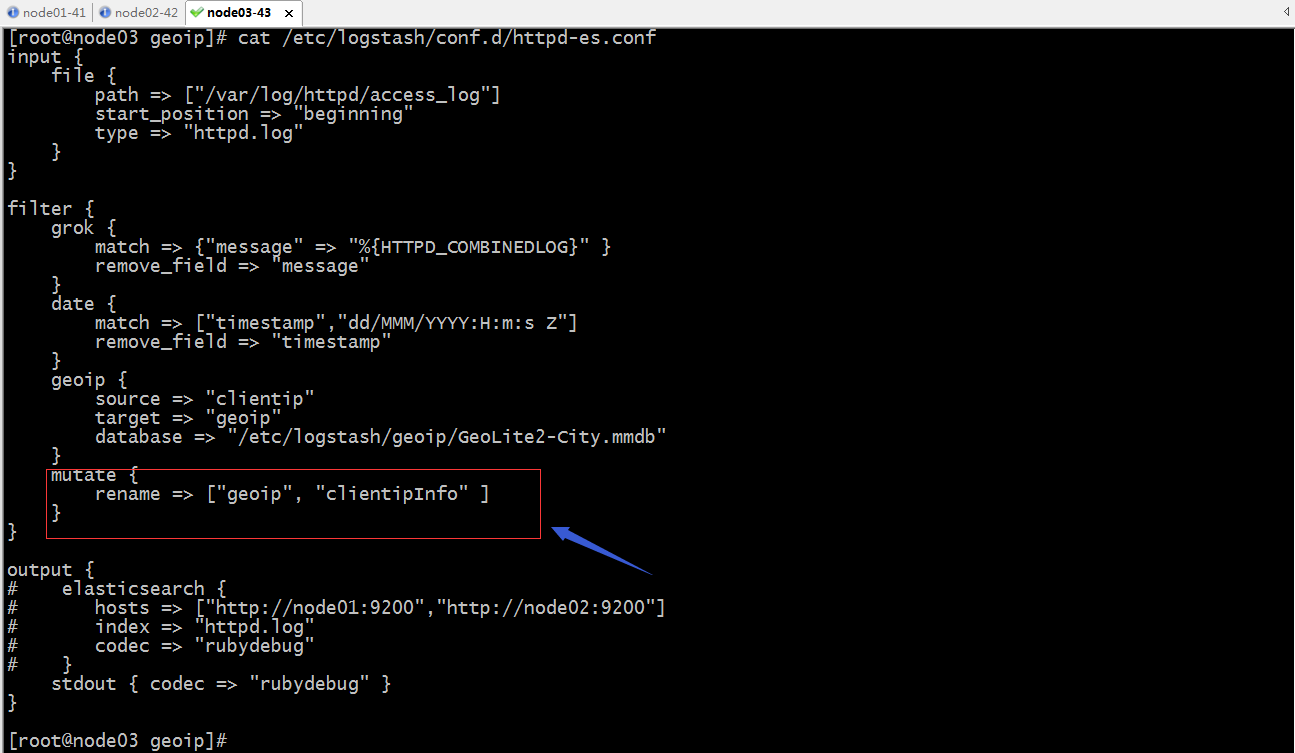
提示:mutate这个过滤器插件,主要对字段做操作,支持对字段进行增删查改;比如对字段重命名,如上配置;
验证:启动logstash,看看现在输出的文档中的geoip是否更改为clientipInfo了?
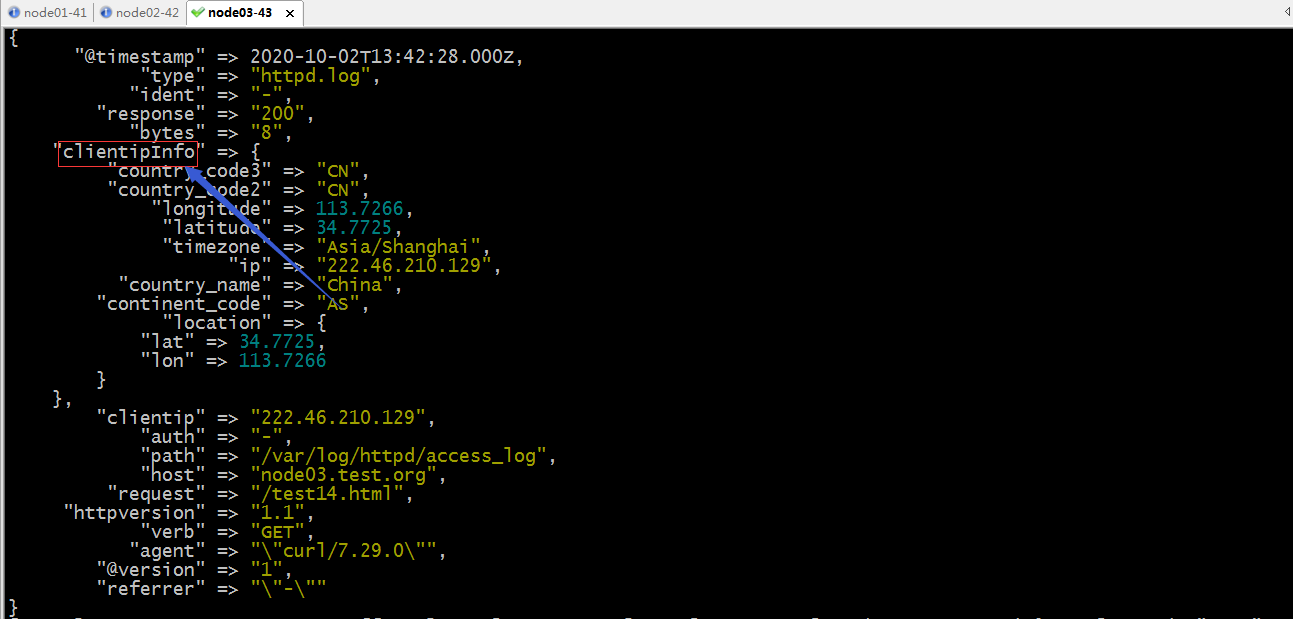
提示:可以看到原来的geoip字段名称已经修改成clientipInfo了;对于这个插件的用法还有其他操作和配置,可以去参考官方文档中的说明进行配置;
示例:将logstash收集的数据日志数据存入redis中
准备redis服务器,然后配置redis登录认证
[root@node04 ~]# yum install redis -y
Loaded plugins: fastestmirror
base | 3.6 kB 00:00:00
epel | 4.7 kB 00:00:00
extras | 2.9 kB 00:00:00
updates | 2.9 kB 00:00:00
(1/2): epel/x86_64/updateinfo | 1.0 MB 00:00:00
(2/2): epel/x86_64/primary_db | 6.9 MB 00:00:01
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
Resolving Dependencies
--> Running transaction check
---> Package redis.x86_64 0:3.2.12-2.el7 will be installed
--> Processing Dependency: libjemalloc.so.1()(64bit) for package: redis-3.2.12-2.el7.x86_64
--> Running transaction check
---> Package jemalloc.x86_64 0:3.6.0-1.el7 will be installed
--> Finished Dependency Resolution Dependencies Resolved =====================================================================================================================
Package Arch Version Repository Size
=====================================================================================================================
Installing:
redis x86_64 3.2.12-2.el7 epel 544 k
Installing for dependencies:
jemalloc x86_64 3.6.0-1.el7 epel 105 k Transaction Summary
=====================================================================================================================
Install 1 Package (+1 Dependent package) Total download size: 648 k
Installed size: 1.7 M
Downloading packages:
(1/2): jemalloc-3.6.0-1.el7.x86_64.rpm | 105 kB 00:00:00
(2/2): redis-3.2.12-2.el7.x86_64.rpm | 544 kB 00:00:00
---------------------------------------------------------------------------------------------------------------------
Total 1.3 MB/s | 648 kB 00:00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : jemalloc-3.6.0-1.el7.x86_64 1/2
Installing : redis-3.2.12-2.el7.x86_64 2/2
Verifying : redis-3.2.12-2.el7.x86_64 1/2
Verifying : jemalloc-3.6.0-1.el7.x86_64 2/2 Installed:
redis.x86_64 0:3.2.12-2.el7 Dependency Installed:
jemalloc.x86_64 0:3.6.0-1.el7 Complete!
[root@node04 ~]#
配置redis监听在本机所有地址的6379端口,并给redis设置认证口令

启动redis
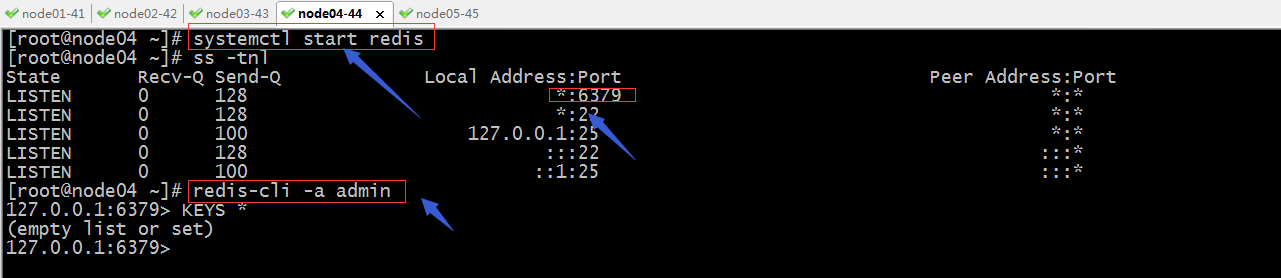
提示:可以看到redis使用我们设置的密码是可以正常登录到redis服务器,到此redis就准备好了;
配置logstash将收集的日志输出到redis的5号库中

提示:将logstash收集的日志输出到redis,需要用到输出插件redis,其中我们必须指定redis的主机地址,端口,密码,数据库,以及key和data_type;data_type是指定存放到redis是一那种数据结构存储,list表示存储为列表;我们知道列表有一个属性就是从列表取出数据以后,列表里对应的数据就会消失,这样一来当有多个logstash在redis中取数据时不会取到重复数据;
验证配置文件语法

启动logstash,然后去redis中验证,看看5号库中是否有我们定义key生成,对应key中是否有日志数据?
去redis上查看5号库的情况
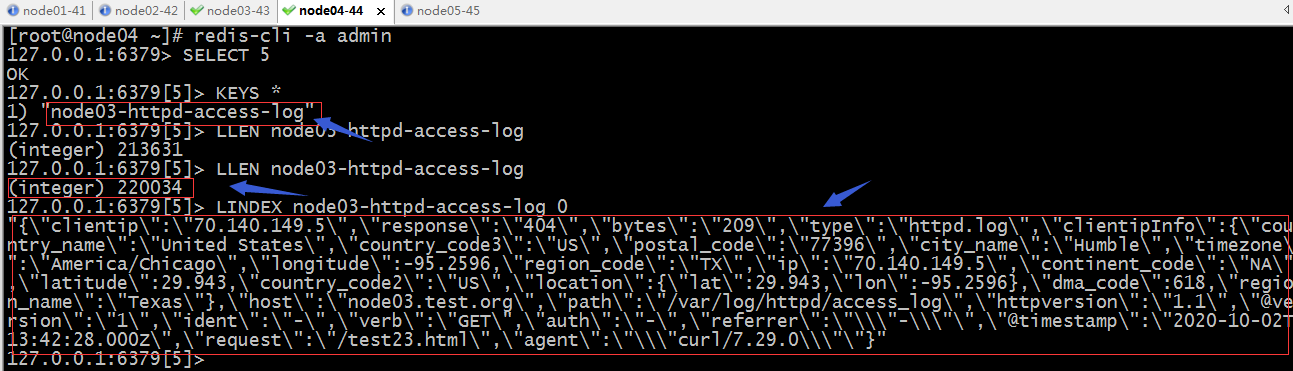
提示:在redis的5号库中可以看到logstash上配置的key的名称,对应key里有数据;
示例:配置logstash从redis中读数据
redis环境还是上面的环境,我们重新开一个服务器,把logstash安装上,logstash的安装请参考上一篇博客https://www.cnblogs.com/qiuhom-1874/p/13761906.html;
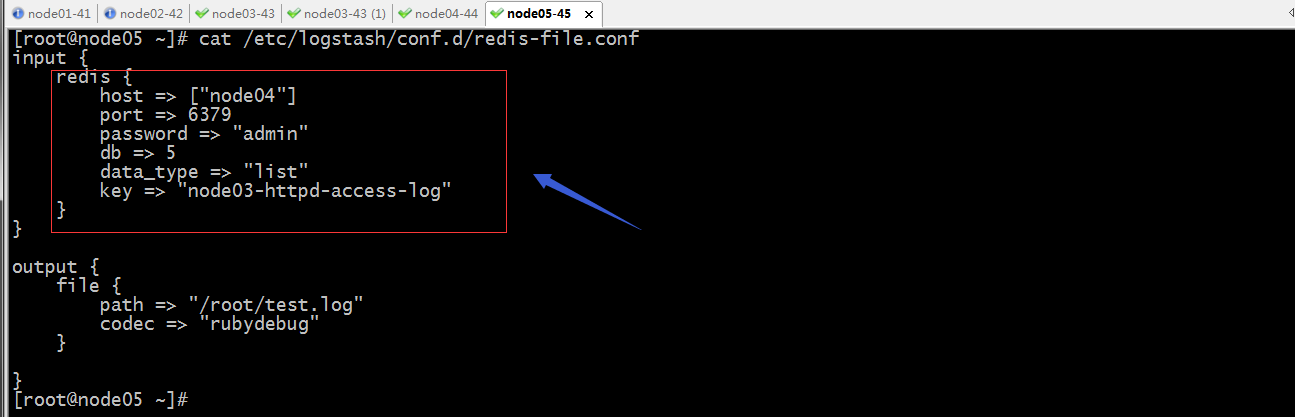
提示:以上配置我们需要在input里配置,用redis输入插件,并明确指定redis的主机,端口,密码,数据库,key,以及数据类型;上面在node05上配置logstash将从redis的5号库采集数据,然后将数据输出到/root/目录下的test.log中;
验证配置文件语法

启动logstash,然后去node05上看对应目录下的文件是否有数据产生?redis对应库里的数据是否有减少?

提示:可以看到启动logstash,它启动了一个线程去redis中读数据,然后有启动了一个线程把数据写到/root/test.log中;
验证:在node05上查看/root目录下是否有test.log生成?对应文件中是否有内容?
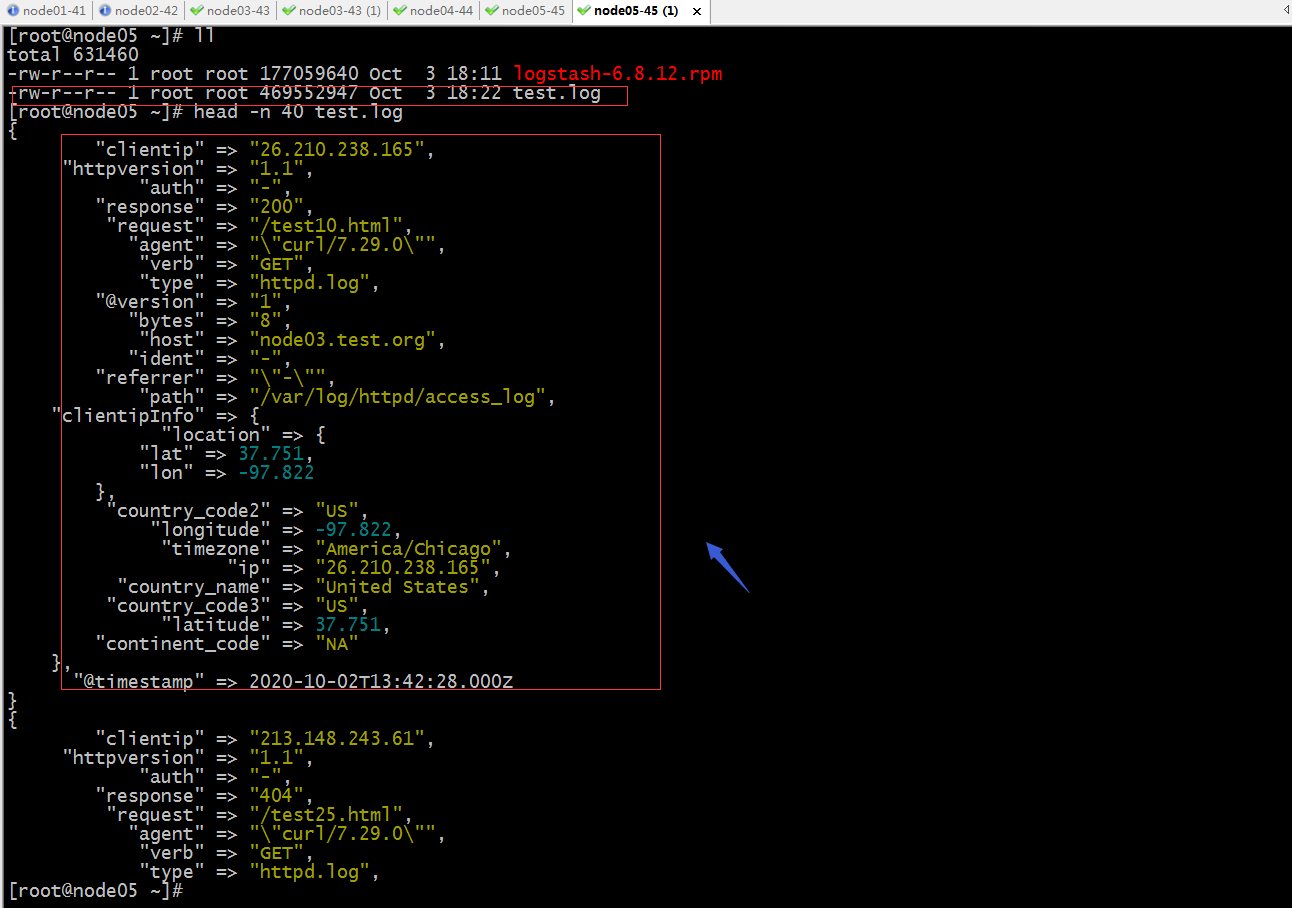
提示:可以看到node05的/root目录下有test.log生成,并且里面也有数据,数据也是从redis里拿的日志数据;
验证:到node04上的redis中查看对应库中的数据是否在减少?
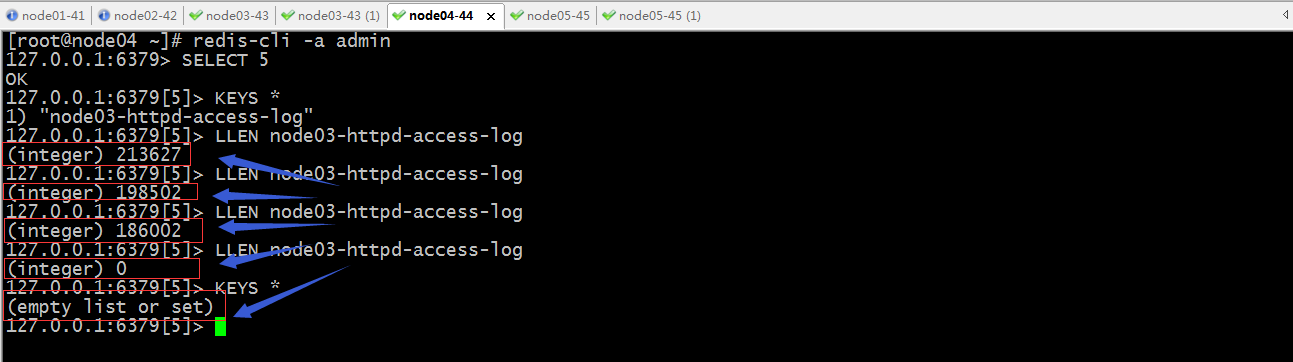
提示:在redis的5号库可以看到logstash在取数据,对应列表的数据在依次减少,最后当logstash把对应列表数据取完以后,对应的列表也就随之删除;
示例:配置logstash收集haproxy发送给rsyslog的日志
安装haproxy
[root@node03 ~]# yum install haproxy
Loaded plugins: fastestmirror
base | 3.6 kB 00:00:00
epel | 4.7 kB 00:00:00
extras | 2.9 kB 00:00:00
updates | 2.9 kB 00:00:00
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
Resolving Dependencies
--> Running transaction check
---> Package haproxy.x86_64 0:1.5.18-9.el7 will be installed
--> Finished Dependency Resolution Dependencies Resolved =====================================================================================================================
Package Arch Version Repository Size
=====================================================================================================================
Installing:
haproxy x86_64 1.5.18-9.el7 base 834 k Transaction Summary
=====================================================================================================================
Install 1 Package Total download size: 834 k
Installed size: 2.6 M
Is this ok [y/d/N]: y
Downloading packages:
haproxy-1.5.18-9.el7.x86_64.rpm | 834 kB 00:00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : haproxy-1.5.18-9.el7.x86_64 1/1
Verifying : haproxy-1.5.18-9.el7.x86_64 1/1 Installed:
haproxy.x86_64 0:1.5.18-9.el7 Complete!
[root@node03 ~]#
配置haproxy将日志发送给rsyslog
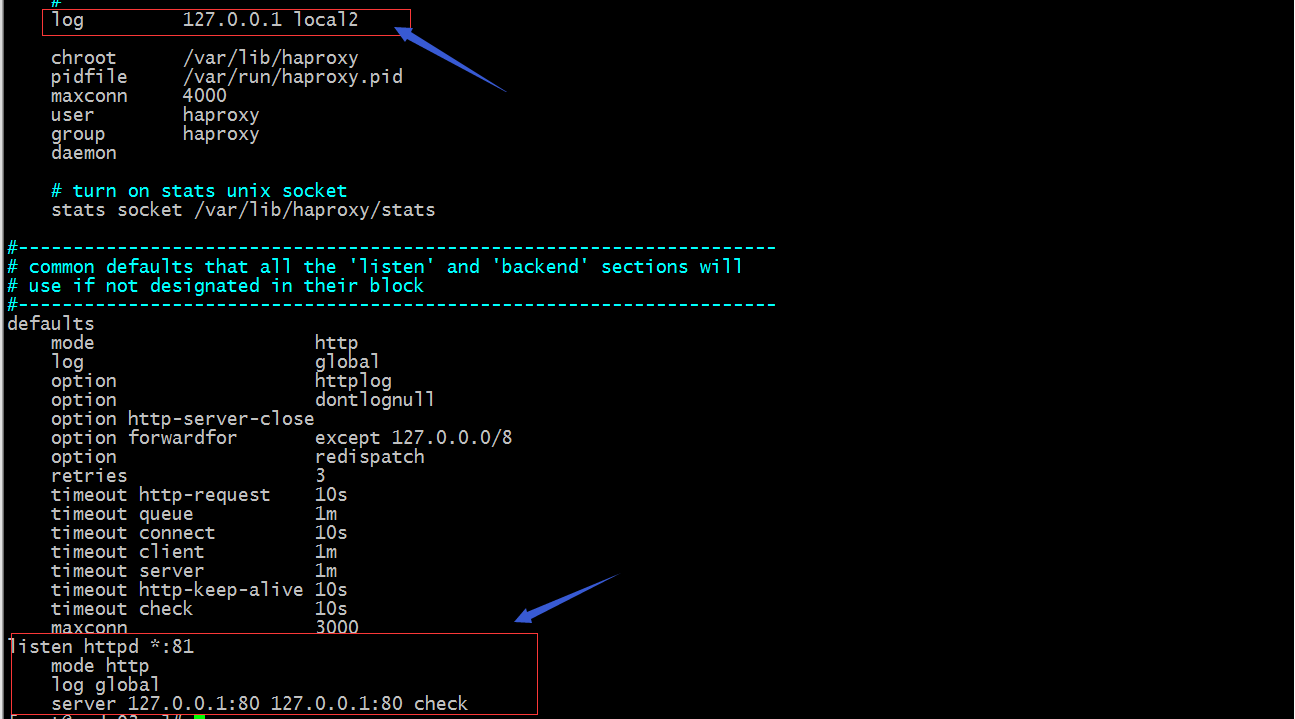
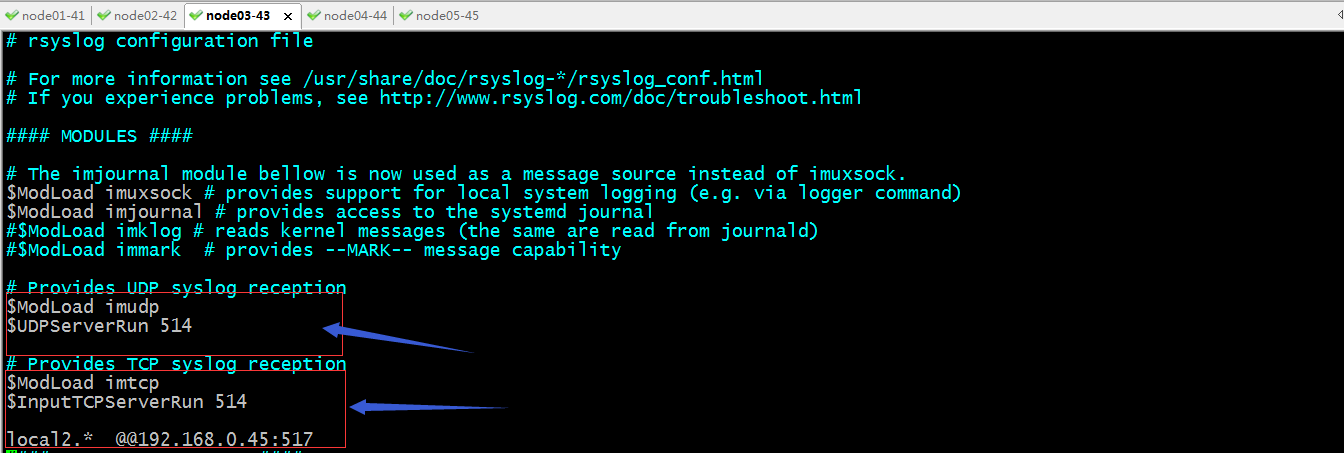
配置rsyslog把local2的日志发送给node05的517端口(这个端口是一个任意端口,只要在node05上不冲突就好)
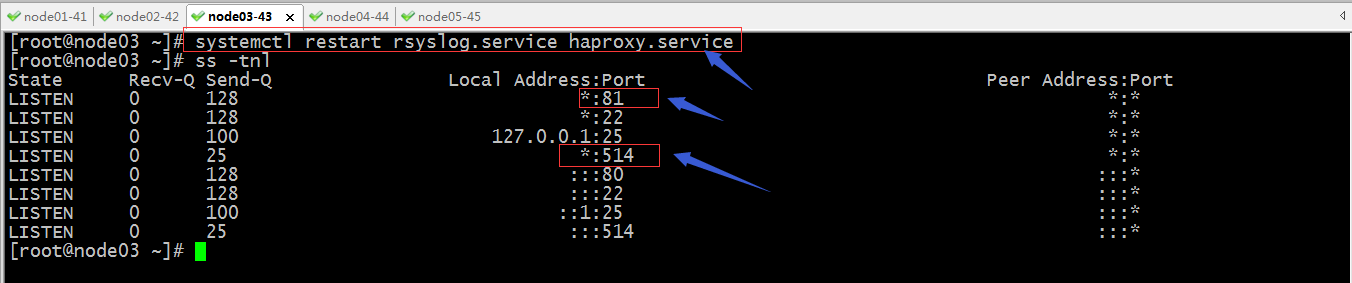
重启rsylog和haproxy
配置node05上的logstash,使用输入插件rsyslog监听517端口
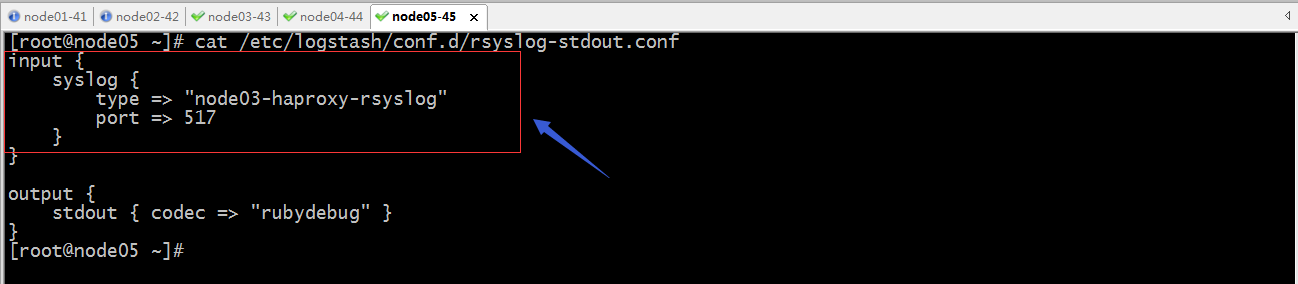
验证配置文件语法

启动logstash
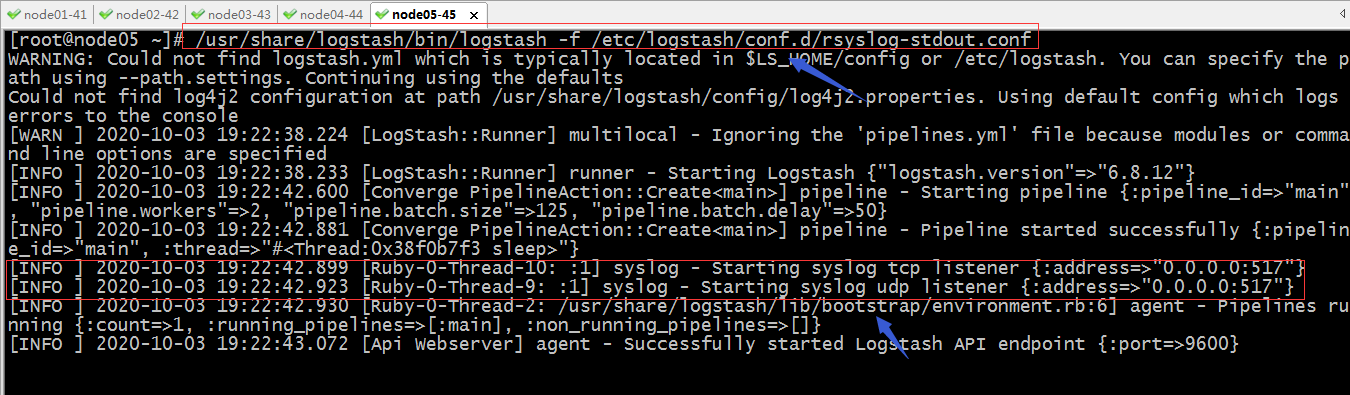
提示:可以看到logstash启动了两个线程监听了udp的517端口和tcp517端口
访问haproxy

看看对应的标准输出中是否会打印haproxy的日志呢?
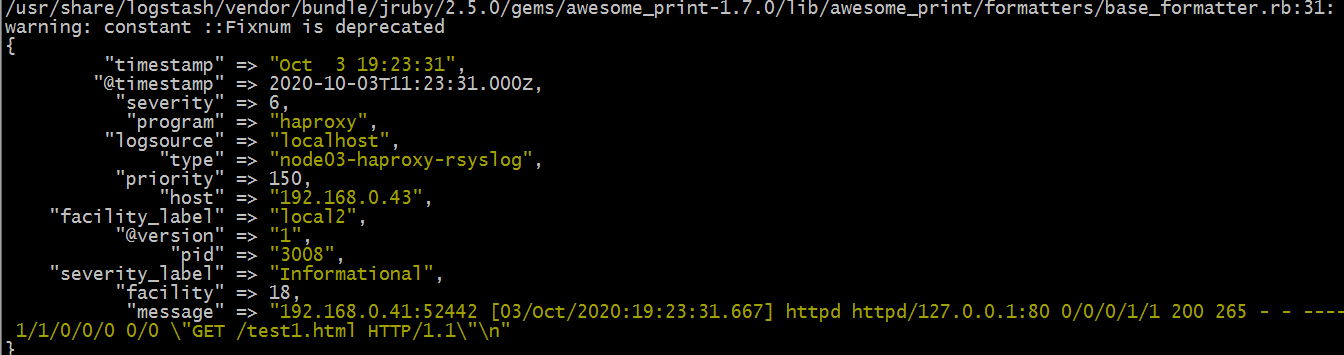
提示:可以看到在node05的标准输出上能够看到访问haproxy的日志打印;
示例:配置logstash收集tcp某个端口的数据

验证配置文件语法,没有问题就直接启动logstash

验证:在其他主机上利用nc向node05的52113发送数据,看看node05上是否会打印我们发送到信息内容?

提示:如果没有nc命令,直接使用yum install nc 即可;

提示:在node05上是能够看到从node01发送过来的消息;
好了,以上是logstash的常用插件的配置,当然还有很多很多,用到那个不会可以去官方文档查找相关插件文档说明进行配置即可;官方文档https://www.elastic.co/guide/en/logstash-versioned-plugins/current/index.html;
日志分析平台ELK之日志收集器logstash常用插件配置的更多相关文章
- 日志分析平台ELK之日志收集器logstash
前文我们聊解了什么是elk,elk中的elasticsearch集群相关组件和集群搭建以及es集群常用接口的说明和使用,回顾请查看考https://www.cnblogs.com/qiuhom-187 ...
- 日志分析平台ELK之日志收集器filebeat
前面我们了解了elk集群中的logstash的用法,使用logstash处理日志挺好的,但是有一个缺陷,就是太慢了:当然logstash慢的原因是它依赖jruby虚拟机,jruby虚拟机就是用java ...
- 集中式日志分析平台 - ELK Stack - 安全解决方案 X-Pack
大数据之心 关注 0.6 2017.02.22 15:36* 字数 2158 阅读 16457评论 7喜欢 9 简介 X-Pack 已经作为 Elastic 公司单独的产品线,前身是 Shield, ...
- 日志分析平台ELK之前端展示kibana
之前的博客一直在聊ELK集群中的存储.日志收集相关的组件的配置,但通常我们给用户使用不应该是一个黑黑的shell界面,通过接口去查询搜索:今天我们来了ELK中的前端可视化组件kibana:kibana ...
- 日志分析平台ELK之搜索引擎Elasticsearch集群
一.简介 什么是ELK?ELK是Elasticsearch.Logstash.Kibana这三个软件的首字母缩写:其中elasticsearch是用来做数据的存储和搜索的搜索引擎:logstash是数 ...
- 大数据时代日志分析平台ELK的搭建
A,首先说说ELK是啥, ELK是ElasticSearch . Logstash 和 Kiabana 三个开源工具组成.Logstash是数据源,ElasticSearch是分析数据的,Kiaba ...
- ELK日志分析平台
ELK日志分析平台 ELK(1): ELK-简介 ELK(2): ELK-安装环境和安装包 ELK(3): ELK-安装elasticsearch ELK(4): ELK-安装logstash ...
- 日志分析工具ELK(五)
八.Kibana实践 选择绝对时间和相对时间 搜索 还可以添加相关信息 自动刷新页面时间,也可以关闭 创建图像,可视化 编辑Markdown,创建一个值班联系表 值班联系表 保存 再创建一个饼图;查看 ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
随机推荐
- e3mall商城总结11之sso系统的分析、应用以及解决ajax跨域问题
说在前面的话 一.sso系统分析 什么是sso系统 SSO英文全称Single Sign On,单点登录.SSO是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统.它包括可以将这次 ...
- 复制一个Python全部环境到另一个环境
导出此环境下安装的包的版本信息清单 pip freeze > requirements.txt 联网,下载清单中的包到all-packet文件夹 [root@localhost ~]# p ...
- 高德地图POI爬取_Python
高德地图POI 官方文档:https://lbs.amap.com/api/webservice/guide/api/search#introduce 官网控制台:https://lbs.amap.c ...
- golang开发:CSP-WaitGroup Mutex
CSP 是 Communicating Sequential Process 的简称,中文可以叫做通信顺序进程,是一种并发编程模型,最初于Tony Hoare的1977年的论文中被描述,影响了许多编程 ...
- [LeetCode]347. 前 K 个高频元素(堆)
题目 给定一个非空的整数数组,返回其中出现频率前 k 高的元素. 示例 1: 输入: nums = [1,1,1,2,2,3], k = 2 输出: [1,2] 示例 2: 输入: nums = [1 ...
- 1. QCamera2基础组件——cam_semaphore
/* Copyright (c) 2012, The Linux Foundation. All rights reserved. * * Redistribution and use in sour ...
- 程序员你是如何降低NPE的?
程序员,如果系统突然报了一个空指针异常,你肯定像吞了一只苍蝇一样尴尬. 那么如何在日常开发过程中降低NPE? 问题 回答 现状 返回空值会出现大量的空指针异常 目的 改进方法的返回值,降低出现空指针异 ...
- react学习 | 踩坑指南
react样式模块化的"omit -loader"坑 众所周知 react样式的模块化(css modules) 是自己模块中写自己的css,与其他模块互补影响,解决了命名冲突和全 ...
- Mybatis 注解形式
1.查询 // 查询 @Select("select id, name, type, numbers, cancelled, completed, percentage from c ...
- k8s报错解决思路
问题1 1.报错信息如下 [root@ken1 ~]# kubectl get po The connection to the server 192.168.64.11:6443 was refus ...