MapReduce之自定义分区器Partitioner
@
问题引出
要求将统计结果按照条件输出到不同文件中(分区)。
比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
默认Partitioner分区
public class HashPartitioner<K,V> extends Partitioner<K,V>{
public int getPartition(K key,V value, int numReduceTasks){
return (key.hashCode() & Integer.MAX VALUE) & numReduceTasks;
}
}
- 默认分区是根据key的hashCode对ReduceTasks个数取模得到的。
- 用户没法控制哪个key存储到哪个分区。
自定义Partitioner步骤
- 自定义类继承
Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<Text,FlowBea>{
@Override
public int getPartition(Text key,FlowBean value,int numPartitions){
//控制分区代码逻辑
……
return partition;
}
}
- 在Job驱动类中,设置自定义
Partitioner
job.setPartitionerClass(CustomPartitioner.class)
- 自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的
ReduceTask
job.setNumReduceTask(5);//假设需要分5个区
Partition分区案例实操
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
输入数据:
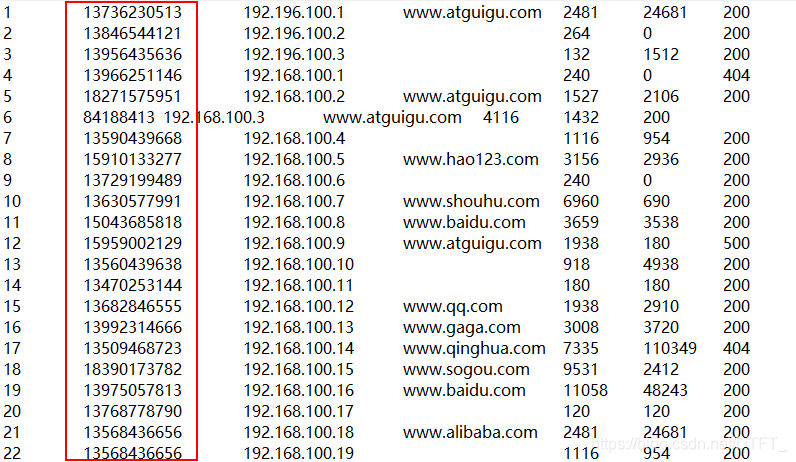
期望输出数据:
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。所以总共分为5个文件,也就是五个区。
相比于之前的自定义flowbean,这次自定义分区,只需要多编写一个分区器,以及在job驱动类中设置分区器,mapper和reducer类不改变
MyPartitioner.java
/*
* KEY, VALUE: Mapper输出的Key-value类型
*/
public class MyPartitioner extends Partitioner<Text, FlowBean>{
// 计算分区 numPartitions为总的分区数,reduceTask的数量
// 分区号必须为int型的值,且必须符合 0<= partitionNum < numPartitions
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
String suffix = key.toString().substring(0, 3);//前开后闭,取手机号前三位数
int partitionNum=0;//分区编号
switch (suffix) {
case "136":
partitionNum=numPartitions-1;//由于分区编号不能大于分区总数,所以用这种方法比较好
break;
case "137":
partitionNum=numPartitions-2;
break;
case "138":
partitionNum=numPartitions-3;
break;
case "139":
partitionNum=numPartitions-4;
break;
default:
break;
}
return partitionNum;
}
}
FlowBeanDriver.java
public class FlowBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/flowbean");
Path outputPath=new Path("e:/mroutput/partitionflowbean");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(FlowBeanMapper.class);
job.setReducerClass(FlowBeanReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置ReduceTask的数量为5
job.setNumReduceTasks(5);
// 设置使用自定义的分区器
job.setPartitionerClass(MyPartitioner.class);
// ③运行Job
job.waitForCompletion(true);
}
}
FlowBeanMapper.java
/*
* 1. 统计手机号(String)的上行(long,int),下行(long,int),总流量(long,int)
*
* 手机号为key,Bean{上行(long,int),下行(long,int),总流量(long,int)}为value
*
*
*
*
*/
public class FlowBeanMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
private Text out_key=new Text();
private FlowBean out_value=new FlowBean();
// (0,1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200)
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
//封装手机号
out_key.set(words[1]);
// 封装上行
out_value.setUpFlow(Long.parseLong(words[words.length-3]));
// 封装下行
out_value.setDownFlow(Long.parseLong(words[words.length-2]));
context.write(out_key, out_value);
}
}
FlowBeanReducer.java
public class FlowBeanReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
private FlowBean out_value=new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
long sumUpFlow=0;
long sumDownFlow=0;
for (FlowBean flowBean : values) {
sumUpFlow+=flowBean.getUpFlow();
sumDownFlow+=flowBean.getDownFlow();
}
out_value.setUpFlow(sumUpFlow);
out_value.setDownFlow(sumDownFlow);
out_value.setSumFlow(sumDownFlow+sumUpFlow);
context.write(key, out_value);
}
}
FlowBean.java
public class FlowBean implements Writable{
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
// 序列化 在写出属性时,如果为引用数据类型,属性不能为null
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//反序列化 序列化和反序列化的顺序要一致
@Override
public void readFields(DataInput in) throws IOException {
upFlow=in.readLong();
downFlow=in.readLong();
sumFlow=in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
}
输出结果:
总共五个文件
一号区:

二号区:

三号区:

四号区:
其他号码为第五号区:

分区总结
- 如果
ReduceTask的数量 > getPartition的结果数,则会多产生几个空的输出文件part-r-000xx - 如果
Reduceask的数量 < getPartition的结果数,则有一部分分区数据无处安放,会Exception - 如果
ReduceTask的数量 = 1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件partr-00000
以刚才的案例分析:
例如:假设自定义分区数为5,则
- job.setlNlurmReduce Task(1);会正常运行,只不过会产生一个输出文件
- job.setlNlunReduce Task(2),会报错
- job.setNumReduceTasks(6);大于5,程序会正常运行,会产生空文件
MapReduce之自定义分区器Partitioner的更多相关文章
- spark自定义分区器实现
在spark中,框架默认使用的事hashPartitioner分区器进行对rdd分区,但是实际生产中,往往使用spark自带的分区器会产生数据倾斜等原因,这个时候就需要我们自定义分区,按照我们指定的字 ...
- kafka 自定义分区器
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.Partitioner; import org.a ...
- 关于MapReduce中自定义分区类(四)
MapTask类 在MapTask类中找到run函数 if(useNewApi){ runNewMapper(job, splitMetaInfo, umbilical, reporter ...
- Parallel中分区器Partitioner的简单使用
Partitioner.Create(1,10,4).GetDynamicPartitions() 为长度为10的序列创建分区,每个分区至多4个元素,分区方法及结果:Partitioner.Creat ...
- Spark源码分析之分区器的作用
最近因为手抖,在Spark中给自己挖了一个数据倾斜的坑.为了解决这个问题,顺便研究了下Spark分区器的原理,趁着周末加班总结一下~ 先说说数据倾斜 数据倾斜是指Spark中的RDD在计算的时候,每个 ...
- 玩转Kafka的生产者——分区器与多线程
上篇文章学习kafka的基本安装和基础概念,本文主要是学习kafka的常用API.其中包括生产者和消费者, 多线程生产者,多线程消费者,自定义分区等,当然还包括一些避坑指南. 首发于个人网站:链接地址 ...
- kafka producer partitions分区器(七)
消息在经过拦截器.序列化后,就需要确定它发往哪个分区,如果在ProducerRecord中指定了partition字段,那么就不再需要partitioner分区器进行分区了,如果没有指定,那么会根据k ...
- RDD(六)——分区器
RDD的分区器 Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数.RDD中每条数据经过Shuffle过 ...
- Spark分区器浅析
分区器作用:决定该数据在哪个分区 概览: 仅仅只有pairRDD才可能持有分区器,普通RDD的分区器为None 在分区器为None时RDD分区一般继承至父RDD分区 初始RDD分区数: 由集合创建,R ...
随机推荐
- springcloud2.0 添加配置中心遇到的坑
新手入门,在springcloud 配置config的时候遇到了几个比较烦的坑 先说1.5x版本的一些配置吧 首先是端点暴露的方式 management: security: enabled: fal ...
- Spring 面试详解
SpringSpring就像是整个项目中装配bean的大工厂,在配置文件中可以指定使用特定的参数去调用实体类的构造方法来实例化对象.Spring的核心思想是IoC(控制反转),即不再需要程序员去显式地 ...
- Docker(三)Docker常用命令
Docker常用命令 帮助命令 # 显示 Docker 版本信息 docker version # 显示系统信息,包括镜像和容器的数量 docker info # 查看帮助文档 帮助文档地址:http ...
- Unity常见的三种数据本地持久化方案
做游戏的时候常常会有数据配置或者存读档的需求,本文整理了常用的几种解决方案,分别是Unity自带的PlayerPrefs类,XML文件和Json文件. 一. PlayerPrefs 这是Unity自带 ...
- 查看Oracle当前用户下的(表视图,同义词...)
查看Oracle当前用户下的信息(用户,表视图,索引,表空间,同义词,存储过程函数,约束条件) 0.表空间 SQL>select username,default_tablespace from ...
- pdfjs优化,实现按需加载,节省流量和内存
1 问题 当使用pdfjs来实现预览功能的时候,遇到了2个问题: 一是带宽占用过大,会下载整个pdf文件,这对部署在公网的应用来说,成本压力很大,因为云服务带宽是很贵的. 二是内存占用过大,一个80M ...
- vx小程序(1)
一.程序配置 app.json 1. pages字段——用于描述当前小程序的页面路径. 2.window字段——定义小程序所有页面的顶部背景颜色,文字颜色等. 注意:可以在pages/logs目录下的 ...
- 曹工说面试:当应用依赖jar包的A版本,中间件jar包依赖B版本,两个版本不兼容,这还怎么玩?
背景 大一点的公司,可能有一些组,专门做中间件的:假设,某中间件小组,给你提供了一个jar包,你需要集成到你的应用里.假设,它依赖了一个日期类,版本是v1:我们应用也依赖了同名的一个日期类,版本是v2 ...
- H5软键盘弹起收回(IOS与Android)
IOS下中,软键盘处于窗口最顶层,与原有的窗口不冲突,所以底部导航条不会被顶起,但是在android下,软键盘与窗口处于同一层,所以当软键盘弹起时,当前窗口缩小,那么窗口内容自然要被挤: 解决办法: ...
- 最简单的博弈论——HDU - 5963 朋友 (博弈)
OK,好的先看一下题意: B君在围观一群男生和一群女生玩游戏,具体来说游戏是这样的: 给出一棵n个节点的树,这棵树的每条边有一个权值,这个权值只可能是0或1. 在一局游戏开始时,会确定一个节点作为根. ...