初学者值得拥有Hadoop单机模式环境搭建
单机模式Hadoop环境搭建
Hadoop环境搭建流程图
具体过程
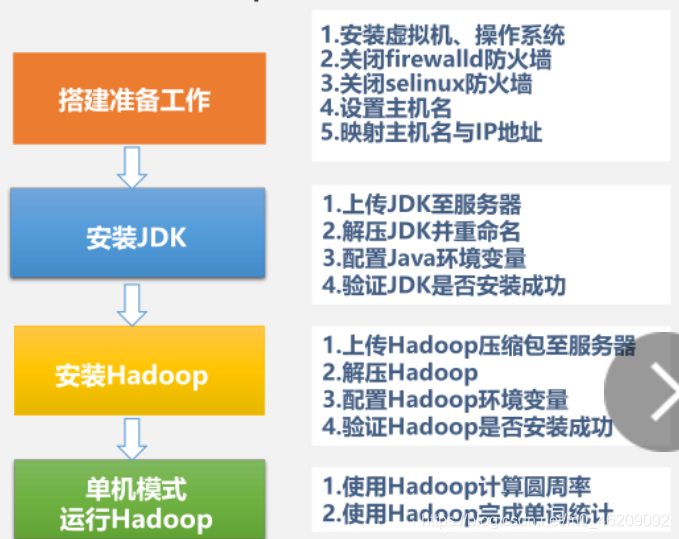
1.搭建准备工作
(1)关闭防火墙

systemctl stop firewalld //停止firewalld防火墙
systemctl disable firewalld //关闭防火墙开机自启
systemctl status firewalld //查看firewalld防火墙状态,看是否已关闭
(2)关闭selinux防火墙

vi /etc/sysconfig/selinux
SELINUX=disabled //将enforcing修改成disabled
(3)设置主机名

hostnamectl set-hostname ky002
hostname //显示主机名
(4)映射主机名与ip地址

ip add //查看ip地址
vi /etc/hosts //映射主机名与ip地址
//在最后一行加入ip地址及主机名
2.安装JDK
(1)下载jdk
在Oracle官网下载JDKlinux1.8以上的版本
(2)上传JDK至服务器
a.下载WinSCP软件
b.建立linux与windows之间文件互传
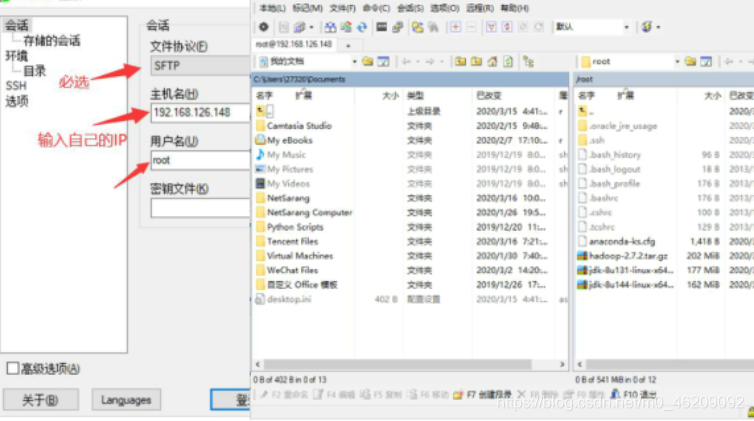
c.上传JDK至Linux
直接拖拽文件至Linux
(3)解压JDK并重命名
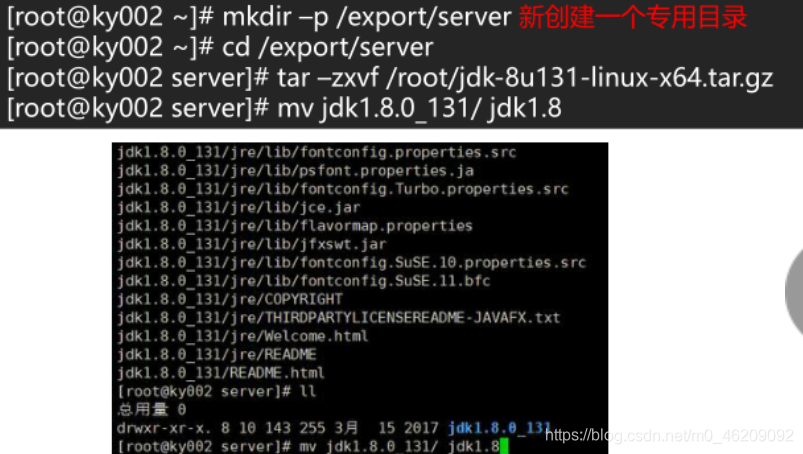
mkdir -p /export/server //创建一个专用目录
cd /export/server
tar -zxvf /root/jdk-8u131-liux-x64.tar.gz //解压jdk安装包 Tab键可以补全版本号
mv jdk1.8.0_131/ jdk1.8 //重命名jdk
(4)配置JAVA环境变量

pwd //显示java安装路径
vi /etc/profile //使用vi编辑器编辑配置文件 按i进入编辑
JAVA_HOME=/export/server/jdk1.8 //JAVA_HOME=jdk路径
export PATH=$PATH:$JAVA_HOME/bin //统一这么写
//按Esc退出编辑 shift+wq保存并退出
source /etc/profile //使设置的环境变量生效
(5)检查JDK是否安装成功
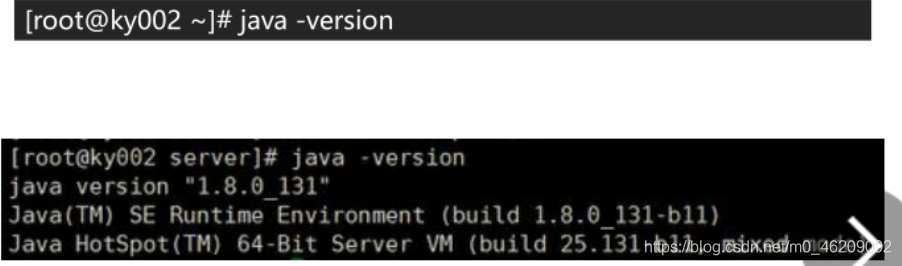
java -version //若成功则会出现jdk版本号信息
3.安装Hadoop
(1)上传Hadoop安装包至Linux
过程与上传jdk类似
a.进入官网下载安装包:[hadoop官网](http://hadoop.apache.org/)
b.使用WinSCP软件上传
(2)解压Hadoop安装包
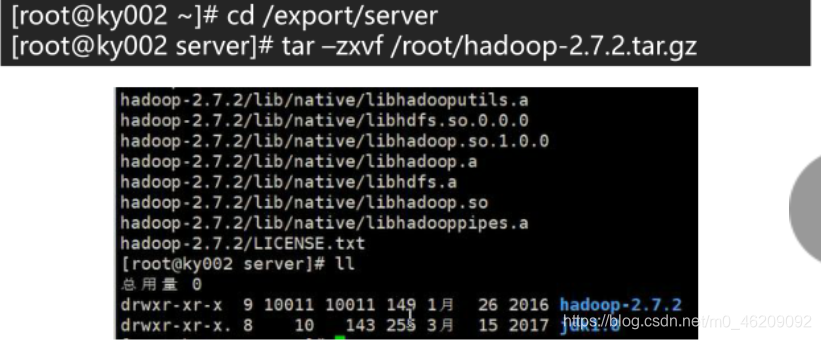
cd /export/server //进入专用目录
tar -zxvf /root/hadoop-2.7.2.tar.gz
(3)配置Hadoop环境变量

cd hadoop-2.7.2/
pwd //显示hadoop安装路径
vi /etc/profile //按i进入编辑
JAVA_HOME=/export/server/jdk1.8 //已有不用写
HADOOP_HOME=/export/server/hadoop-2.7.2 //HADOOP_HOME=hadoop安装路径
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME HADOOP_HOME PATH
//按Esc退出编辑 shift+wq保存并退出
source /etc/profile //使设置的环境变量生效
(4)检查Hadoop是否安装成功

hadoop version //若成功则会出现hadoop版本号信息
4.单机模式运行Hadoop
Hadoop自带了一些MapReduce示例程序,这些程序代码都在hadoop-example.jar包内,jar包的安装目录在Hadoop下
(1)计算圆周率

pi:程序名称
第一个参数:运行多少次map任务
第二个参数:每个map任务投掷多少次
二个参数之积即总投掷数(pi代码就是以投掷来计算值)
hadoop jar hadoop-mapreduce-examples-2.7.2.jar pi 5 5 //Tab键可以补全版本号
(2)完成单词统计

数据准备
cd /export/server/hadoop-2.7.2 //进入Hadoop安装目录
mkdir wcinput //创建wcinput
cd wcinput
vi word.txt //将单词数据存放到word.txt文件中

执行程序
cd /export/server/hadoop-2.7.2/
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
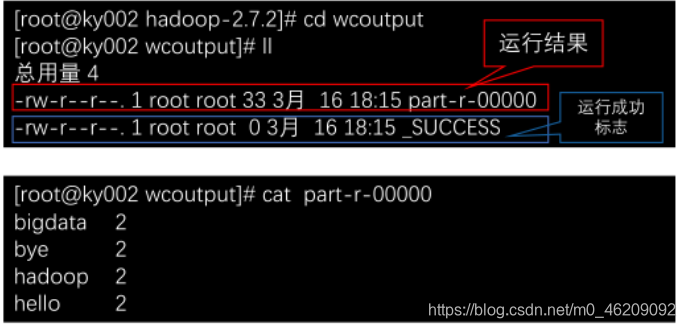
查看结果
初学者值得拥有Hadoop单机模式环境搭建的更多相关文章
- 初学Hadoop之单机模式环境搭建
本文仅作为学习笔记,供大家初学Hadoop时学习参考.初学Hadoop,欢迎有经验的朋友进行指导与交流! 1.安装CentOS7 准备 CentOS系统镜像CentOS-7.0-1406-x86_64 ...
- ubuntu14.04 Hadoop单机开发环境搭建MapReduce项目
Hadoop官网:http://hadoop.apache.org/ 目前最新的版本是Hadoop 3.0.0-alpha1前提:java 1.6 版本以上 首先从官网下载压缩包(hadoop-3.0 ...
- hadoop单击模式环境搭建
一 安装jdk 下载相应版本的jdk安装到相应目录,我的安装目录是/usr/lib/jdk1.8.0_40 下载完成后,在/etc/profile中设置一下环境变量,在文件最后追加如下内容 expor ...
- Hadoop单机模式安装
一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: ...
- 3-1.Hadoop单机模式安装
Hadoop单机模式安装 一.实验介绍 1.1 实验内容 hadoop三种安装模式介绍 hadoop单机模式安装 测试安装 1.2 实验知识点 下载解压/环境变量配置 Linux/shell 测试Wo ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- CentOS下Hadoop及ZooKeeper环境搭建
1. 测试环境 操作系统 CentOS 6.5. 总共5台机器,前两台作为namenode,称之为 nn01.nn02:后三台作为datanode,称为 dn01.dn02.dn03. 每台机器的内存 ...
- Spark—local模式环境搭建
Spark--local模式环境搭建 一.Spark运行模式介绍 1.本地模式(loca模式):spark单机运行,一般用户测试和开发使用 2.Standalone模式:构建一个主从结构(Master ...
- 《Programming Hive》读书笔记(一)Hadoop和hive环境搭建
<Programming Hive>读书笔记(一)Hadoop和Hive环境搭建 先把主要的技术和工具学好,才干更高效地思考和工作. Chapter 1.Int ...
随机推荐
- XJOI 夏令营501-511测试11 游戏
Alice和Bob两个人正在玩一个游戏,游戏有很多种任务,难度为p的任务(p是正整数),有1/(2^p)的概率完成并得到2^(p-1)分,如果完成不了,得0分.一开始每人都是0分,从Alice开始轮流 ...
- 二维码生成与windows系统IP查询功能
一个木函是一款强大的手机软件,里面囊括了很多小功能,每一个都基本可以堪称小程序.那么,这些小功能具体是怎么实现的呢?让我们来一起来探讨二维码生成.IP查询这两个功能吧! 一.二维码生成 首先,我们来看 ...
- 转载:WIFI无线协议802.11a/b/g/n/ac的演变以及区别
WIFI无线协议802.11a/b/g/n/ac的演变以及区别 版权声明:版权所有,转载须注明出处. https://blog.csdn.net/Brouce__Lee/article/details ...
- yum针对软件包操作的常用命令
yum针对软件包操作的常用命令: 1.使用YUM查找软件包 命令:yum search php 2.列出所有可安装的软件包 命令:yum list php 3.列出所有可更新的软件包 命令:yum l ...
- npm pm2
安装 npm install -g pm2 用法 $ npm install pm2 -g # 命令行安装 pm2 $ pm2 start app.js -i 4 # 后台运行pm2,启动4个app. ...
- linux基本操作之linux登陆
一 文本登陆方式: 输入用户名与密码:/etc/passwd文件对照(口令文件,保存基本的用户信息):/etc/shadow文件对照(影子文件,保存密码信息):启动相应的shell程序:用户得到 一个 ...
- python之 《pandas》
pandas稍微比numpy处理数据起来还是要慢一点,pandas呢是numpy的升级版,可以说各有所长,numpy的优势是用来处理矩阵,而pandas的优势是处理数表. 1. Series 线性数表 ...
- ceph各个版本之间参数变化分析
前言 本篇主要是分析ceph的版本之间参数的变化,参数变化意味着功能的变化,通过参数来分析增加,删除,修改了哪些功能,以及版本之间的变化,本篇主要通过导出参数,然后通过脚本去比对不同的版本的参数变化 ...
- 在线调整ceph的参数
能够动态的进行系统参数的调整是一个很重要并且有用的属性 ceph的集群提供两种方式的调整,使用tell的方式和daemon设置的方式 一.tell方式设置 调整配置使用命令: 调整mon的参数 #ce ...
- [C/C++] 结构体内存对齐:alignas alignof pack
简述: alignas(x):指定结构体内某个成员的对齐字节数,指定的对齐字节数不能小于它原本的字节数,且为2^n; #pragma pack(x):指定结构体的对齐方式,只能缩小结构体的对齐数,且为 ...