Python超全干货:【二叉树】基础知识大全
概念
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)
二叉树的链式存储:
将二叉树的节点定义为一个对象,节点之间通过类似链表的链接方式来连接。
树的定义与基本术语
树型结构是一类重要的非线性数据结构,其中以树和二叉树最为常用,是以分支关系定义的层次结构。树结构在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构;在计算机领域中也有广泛应用,如在编译程序中,可用树来表示源程序的语法结构;在数据库系统中,树型结构也是信息的重要组织形式之一;在机器学习中,决策树,随机森林,GBDT等是常见的树模型。
树(Tree)是n(n>=0)个结点的有限集。在任意一棵树中:(1)有且仅有一个特定的称为根(Root)的节点;(2)当n>1时,其余节点可分为m(m>0)个互不相交的有限集,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
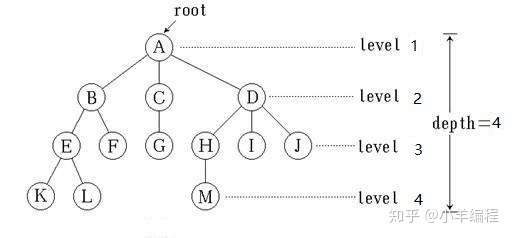
图1 树型结构
在图1,该树一共有13个节点,其中A是根,其余节点分成3个互不相交的子集:
T1={B,E,F,K,L},T2={C,G},T3={D,H,I,J,K};T1,T2,T3都是根A的子树,且本身也是一颗树。
例如T1,其根为B,其余节点分为两个互不相交的子集;T11={E,K,L},T12={F}。T11和T12都是B的子树。而在T11中E是根,{K}和{L}是E的两棵互不相交的子树,其本身又是只有一个根节点的树。
树的基本术语
树的结点包含一个数据元素及若干指向其子树的分支。
节点拥有的子树数量称为节点的度(Degree)。
在图1中,A的度为3,B的度为2,C的度为1,F的度为0。
度为0的结点称为叶子(Leaf)结点。
在图1中,K,L,F,G,M,I,J都是该树的叶子。度不为0的结点称为分支结点。
树的度是指树内个结点的度的最大值。
结点的子树的根称为该结点的孩子(Child),相应地,该结点称为孩子的双亲(Parent)
在图1,中,D是A的孩子,A是D的双亲。同一个双亲的孩子之间互称兄弟(Sibling)
H,I,J互为兄弟。结点的祖先是从根到该结点所经分支上的所有结点,M的祖先为A,D,H。
对应地,以某结点为根的子树中的任一结点都称为该结点的子孙。B的子孙为E,F,K,L。
树的层次(Level)是从根开始,根为第一层,根的孩子为第二层等。双亲在同一层的结点互为同兄弟。图1中,K,L,M互为堂兄弟。树中结点的最大层次称为树的深度(Depth)或高度,树的深度为4。
如果将树中结点的各子树看成从左到右是有次序的(即不能交换),则称该树为有序树,否则为无序树。
森林(Forest)是m(m>=0)棵互不相交的树的集合。对树中每个结点而言,其子树的集合即为森林。
在机器学习模型中,决策树为树型结构,而随机森林为森林,是由若干决策树组成的森林。
性质
性质1: 在二叉树的第i层上至多有2^(i-1)个结点(i>0)
性质2: 深度为k的二叉树至多有2^k - 1个结点(k>0)
性质3:对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
性质4:具有n个结点的完全二叉树的深度为 log2(n+1)
性质5:对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必须为i/2(i=1 时为根,除外)
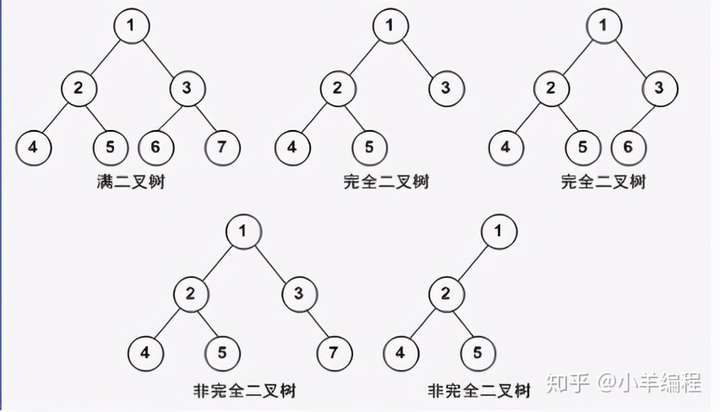
分类
1.完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布。
2.满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
二叉树Python实现
class Node(object):
"""节点类"""
def __init__(self, elem=-1, lchild=None, rchild=None):
self.elem = elem # 自身
self.lchild = lchild # 左孩子
self.rchild = rchild # 右孩子
class Tree(object):
"""树类"""
def __init__(self, root=None):
self.root = root def add(self, elem):
node = Node(elem)
if self.root == None:
self.root = node
else:
queue = []
queue.append(self.root) # 先将根节点添加到队列中
while queue: # 遍历树
cur = queue.pop(0) # 首先弹出了根节点
if cur.lchild == None: # 如果没有做孩子的话
cur.lchild = node # 添加node
return
elif cur.rchild == None: # 如果没有有孩子的话
cur.rchild = node
return
else: # 如果左右子树都不为空,加入队列继续判断
queue.append(cur.lchild)
queue.append(cur.rchild)
二叉树的遍历:
常见的遍历方法有:先序遍历,中序遍历,后序遍历,层序遍历。这些遍历方法一般使用递归算法实现。
前序遍历:EACBDGF
前序遍历的操作定义为:若二叉树为空,为空操作;否则(1)访问根节点;(2)先序遍历左子树;(3)先序遍历右子树。
递归实现:
def preorder(root):
if not root:
return
print(root.val)
preorder(root.left)
preorder(root.right)
迭代实现:
def preorder(root):
stack = [root]
while stack:
s = stack.pop()
if s:
print(s.val)
stack.append(s.right)
stack.append(s.left)
中序遍历:ABCDEGF
中序遍历的操作定义为:若二叉树为空,为空操作;否则(1)中序遍历左子树;(2)访问根结点;(3)中序遍历右子树。
递归实现:
def inorder(root):
if not root:
return
inorder(root.left)
print(root.val)
inorder(root.right)
迭代实现:
def inorder(root):
stack = []
while stack or root:
while root:
stack.append(root)
root = root.left
root = stack.pop()
print(root.val)
root = root.right
后序遍历:BDCAFGE
后序遍历的操作定义为:若二叉树为空,为空操作;否则(1)后序遍历左子树;(2)后序遍历右子树;(3)访问根结点。
递归实现:
def postorder(root):
if not root:
return
postorder(root.left)
postorder(root.right)
print(root.val)
迭代实现:
def postorder(root):
stack = []
while stack or root:
while root: # 下行循环,直到找到第一个叶子节点 stack.append(root)
if root.left: # 能左就左,不能左就右 root = root.left
else:
root = root.right
s = stack.pop()
print(s.val)
#如果当前节点是上一节点的左子节点,则遍历右子节点 if stack and s == stack[-1].left: root = stack[-1].right
else:
root = None
层次遍历:EAGCFBD
层序遍历的操作定义为:若二叉树为空,为空操作;否则从上到下、从左到右按层次进行访问。
递归实现:
def BFS(root):
queue = [root]
while queue:
n = len(queue)
for i in range(n):
q = queue.pop(0)
if q:
print(q.val)
queue.append(q.left if q.left else None)
queue.append(q.right if q.right else None)
代码实现:
# _*_ coding=utf-8 _*_ """
实现一个二叉树结果,并进行遍历
E
/ \
A G
\ \
C F
/ \
B D
"""
from collections import deque class BinaryTree(object):
def __init__(self, data):
self.data = data
self.child_l = None
self.child_r = None # 创建
a = BinaryTree("A")
b = BinaryTree("B")
c = BinaryTree("C")
d = BinaryTree("D")
e = BinaryTree("E")
f = BinaryTree("F")
g = BinaryTree("G") # 构造节点关系
e.child_l = a
e.child_r = g
a.child_r = c
c.child_l = b
c.child_r = d
g.child_r = f # 设置根
root = e def pre_order(tree):
"""
前序遍历:root -> child_l -> child_r
:param tree: the root of tree
:return:
"""
if tree:
print(tree.data, end=',')
# print("")
pre_order(tree.child_l)
pre_order(tree.child_r) def in_order(tree):
"""
中序遍历:child_l -> root -> child_r
:param tree:
:return:
"""
if tree:
in_order(tree.child_l)
print(tree.data, end=',')
in_order(tree.child_r) def post_order(tree):
"""
后序遍历:child_l -> child_r -> root
:param tree:
:return:
"""
if tree:
post_order(tree.child_l)
post_order(tree.child_r)
print(tree.data, end=',') def level_order(tree):
"""
层次遍历:E -> AG -> CF -> BD
使用队列实现
:param tree:
:return:
"""
queue = deque()
queue.append(tree) # 先把根添加到队列
while len(queue): # 队列不为空
node = queue.popleft()
print(node.data, end=',')
if node.child_l:
queue.append(node.child_l)
if node.child_r:
queue.append(node.child_r) pre_order(root)
print('')
in_order(root)
print('')
post_order(root)
print('')
level_order(root)
二叉树的最大深度
基本思路就是递归,当前树的最大深度等于(1+max(左子树最大深度,右子树最大深度))。代码如下:
def maxDepth(root):
if not root:
return 0
return 1+max(maxDepth(root.left),maxDepth(root.right))
二叉树的最小深度
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。可以通过递归求左右节点的最小深度的较小值,也可以层序遍历找到第一个叶子节点所在的层数。
递归方法:
class Solution:
def minDepth(self, root: TreeNode) -> int:
if not root:
return 0
if not root.left and not root.right:
return 1
if not root.right:
return 1+self.minDepth(root.left)
if not root.left:
return 1+self.minDepth(root.right)
return 1+min(self.minDepth(root.left),self.minDepth(root.right))
迭代方法:
class Solution:
def minDepth(self, root: TreeNode) -> int:
if not root: return 0
ans,count = [root],1
while ans:
n = len(ans)
for i in range(n):
r = ans.pop(0)
if r:
if not r.left and not r.right:
return count
ans.append(r.left if r.left else [])
ans.append(r.right if r.right else [])
count+=1
二叉树的所有路径
根节点到叶子节点的所有路径。
def traverse(node):
if not node.left and not node.right:
return [str(node.val)]
left, right = [], []
if node.left:
left = [str(node.val) + x for x in traverse(node.left)]
if node.right:
right = [str(node.val) + x for x in traverse(node.right)] return left + right
Python超全干货:【二叉树】基础知识大全的更多相关文章
- Python专题三字符串的基础知识
Python专题三字符串的基础知识 在Python中最重要的数据类型包括字符串.列表.元组和字典等.该篇主要讲述Python的字符串基础知识. 一.字符串基础 字符串指一有序的字符序列集合,用单引号. ...
- python爬虫之Beautiful Soup基础知识+实例
python爬虫之Beautiful Soup基础知识 Beautiful Soup是一个可以从HTML或XML文件中提取数据的python库.它能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档 ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- mysql基础知识大全
前言:本文主要为mysql基础知识的大总结,mysql的基础知识很多,这里作简单概括性的介绍,具体的细节还是需要自行搜索.当然本文还有很多遗漏的地方,后续会慢慢补充完善. 数据库和数据库软件 数据库是 ...
- 【值得收藏】C语言入门基础知识大全!从C语言程序结构到删库跑路!
01 C语言程序的结构认识 用一个简单的c程序例子,介绍c语言的基本构成.格式.以及良好的书写风格,使小伙伴对c语言有个初步认识. 例1:计算两个整数之和的c程序: #include main() { ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- Python 插件(add-in)基础知识
1) Python插件为何物 一个插件(add-in)就是一个客户化,比如嵌入到ArcGIS应用程序中的工具条上的一系列工具,这些工具作为ArcGIS标准程序的补充可以为客户完成特殊任务. ArcG ...
- Python 爬虫(1)基础知识和简单爬虫
Python上手很容易,免费开源,跨平台不受限制,面向对象,框架和库很丰富. Python :Monty Python's Flying Circus (Python的名字来源,和蟒蛇其实无关). 通 ...
- python学习(一) 基础知识
开始学习<Python基础教程> 1.2 交互式解释器 按照书上的例子敲了个最简单的print函数,居然报错: >>> print "fsdfs"Sy ...
随机推荐
- soloPi安装使用
SoloPi脚本转化器正式发布,支持转化为 Appium 与 Macaca 脚本:https://github.com/soloPi/SoloPi-Convertor,脚本转化器使用教程: https ...
- 11张图和源码带你解析Spring Bean的生命周期,建议收藏~!
在网上已经有跟多Bean的生命周期的博客,但是很多都是基于比较老的版本了,最近把整个流程画成了一个流程图.待会儿使用流程图,说明以及代码的形式来说明整个声明周期的流程.注意因为代码比较多,这里的流程图 ...
- 线程池基本使用和ThreadPoolExecutor核心原理讲解
原文地址:https://www.jianshu.com/p/ec5b8cccd87d java和spring都提供了线程池的框架 java提供的是Executors: spring提供的是Threa ...
- Redux学习day1
01.React介绍 Redux是一个用来管理管理数据状态和UI状态的JavaScript应用工具.随着JavaScript单页应用(SPA)开发日趋复杂,JavaScript需要管理比任何时候都要多 ...
- java联系人管理系统简单设计
本文实例为大家分享了java联系人管理系统毕业设计,供大家参考,具体内容如下 要求: 请使用XML保存数据,完成一个联系人管理系统. 用户必须经过认证登录后方可以使用系统. 注册 ...
- .Net5,C#9 新语法(逻辑和属性模式,记录)
代码: namespace ConsoleApp1{ class Program { static void Main(string[] args) { //创建list数组,=号右边可省略 List ...
- 限制页面只能由微信内置浏览器打开,在其他浏览器打开跳转到Oauth2页面
在需要限制的页面加上 appid必填,可以获取也可以自己随意 <script> var ua = navigator.userAgent.toLowerCase(); var isWei ...
- EFCore 5 新特性 `SaveChangesInterceptor`
EFCore 5 新特性 SaveChangesInterceptor Intro 之前 EF Core 5 还没正式发布的时候有发布过一篇关于 SaveChangesEvents 的文章,有需要看可 ...
- python菜鸟教程学习1:背景性学习
https://www.runoob.com/python3/python3-intro.html 优点 简单 -- Python 是一种代表简单主义思想的语言.阅读一个良好的 Python 程序就感 ...
- Mycat分库分表(一)
随着业务变得越来越复杂,用户越来越多,集中式的架构性能会出现巨大的问题,比如系统会越来越慢,而且时不时会宕机,所以必须要解决高性能和可用性的问题.这个时候数据库的优化就显得尤为重要,在说优化方案前,先 ...