ES数据库高可用配置
ES高可用集群部署
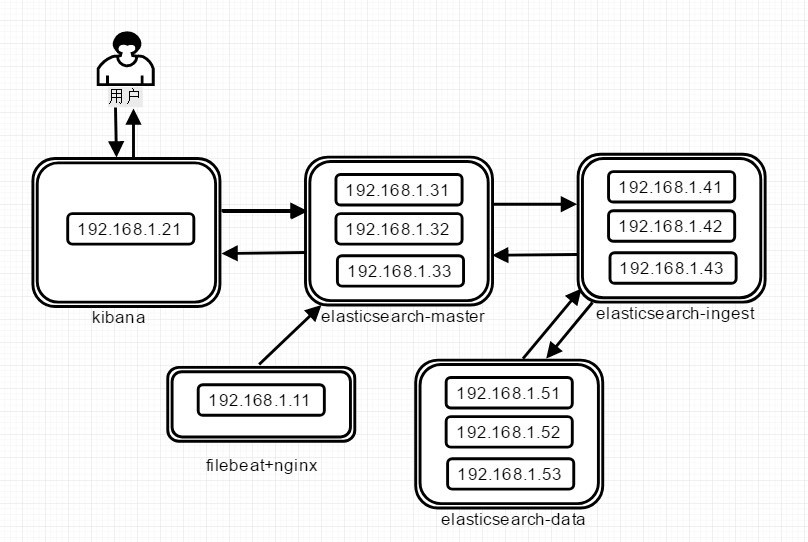
1、ES高可用架构图
2、创建ES用户组
1.Elasticsearch不能在 root 用户下启动,我们需要在三台机器上分创建一个普通用户# 创建elastic用户
useradd elastic
设置用户密码
passwd elastic
测试服务器密码设置的是
abc123!@#
切换到elastic用户
su elastic
- 分别在三台机器上的 /home/elastic/ 目录下分别创建data、logs文件夹。
cd /home/elastic/
mkdir data
mkdir logs在生产环境下我们要把Elasticsearch生成的索引文件数据存放到自定义的目录下
data:存储Elasticsearch索引文件数据
logs:存储日志文件
3.系统设置。
使用root用户分别在三台服务器上增加 /etc/sysctl.conf 配置
添加内容为
vm.max_map_count = 655300
接着输入如下命令让配置生效:
sysctl -p
解锁文件限制,增加 /etc/security/limits.conf 配置
* soft nofile 65535
* hard nofile 65535
* soft nofile 65535
* hard nofile 65535
? ? ? ?4、配置Elasticsearch
首先我们将下载好的elasticsearch-7.6.2-linux-x86_64.tar.gz压缩包通过elastic普通用户,上传到三台服务器集群的/home/elastic目录下,解压
tar -zxvf elasticsearch-7.9.0-linux-x86_64.tar.gz
如果是root用户,上传压缩包解压后,需要修改elastic 目录的拥有者
cd /home/
chown -R elastic elastic
解压完成后ll查看目录
su elastic一定要切换用户,切记!切记!
分别修改elasticsearch.yml配置文件
vi /home/elastic/elasticsearch-7.9.0/config/elasticsearch.yml
cluster.name: data-cluster
node.name: "data-es-05"
#node.data: false
# Indexing & Cache config
index.number_of_shards: 5
index.number_of_replicas: 1
index.cache.field.type: soft
index.cache.field.expire: 10m
index.cache.query.enable: true
indices.cache.query.size: 2%
indices.fielddata.cache.size: 35%
indices.fielddata.cache.expire: 10m
index.search.slowlog.level: INFO
#indices.recovery.max_size_per_sec: 1gb
index.merge.scheduler.max_thread_count: 2 # Only for spinning media.
# Refresh config
index.refresh_interval: 300s
# Translog config
index.translog.flush_threshold_ops: 100000
# Paths config
path.data: /data/esData
path.plugins: /usr/share/elasticsearch/plugins
# Network And HTTP
network.bind_host: 10.0.126.203
network.publish_host: 10.0.126.203
transport.tcp.port: 9300
transport.tcp.compress: true
http.port: 9200
# Discovery
discovery.zen.minimum_master_nodes: 1
discovery.zen.ping.timeout: 10s
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["10.0.32.3:9300", "10.0.4.37:9300", "10.0.40.159:9300", "10.0.107.116:9300" , "10.0.126.203:9300"]
配置文件位于%ES_HOME%/config/elasticsearch.yml文件中,用Editplus打开它,你便可以进行配置。
所有的配置都可以使用环境变量,例如:
node.rack: ${RACK_ENV_VAR} 表示环境变量中有一个RACK_ENV_VAR变量。
下面列举一下elasticsearch的可配置项:
1. 集群名称,默认为elasticsearch:
cluster.name: elasticsearch
2. 节点名称,es启动时会自动创建节点名称,但你也可进行配置:
node.name: "Franz Kafka"
3. 是否作为主节点,每个节点都可以被配置成为主节点,默认值为true:
node.master: true
4. 是否存储数据,即存储索引片段,默认值为true:
node.data: true
master和data同时配置会产生一些奇异的效果:
1) 当master为false,而data为true时,会对该节点产生严重负荷;
2) 当master为true,而data为false时,该节点作为一个协调者;
3) 当master为false,data也为false时,该节点就变成了一个负载均衡器。
你可以通过连接http://localhost:9200/_cluster/health或者http://localhost:9200/_cluster/nodes,或者使用插件http://github.com/lukas-vlcek/bigdesk或http://mobz.github.com/elasticsearch-head来查看集群状态。
5. 每个节点都可以定义一些与之关联的通用属性,用于后期集群进行碎片分配时的过滤:
node.rack: rack314
6. 默认情况下,多个节点可以在同一个安装路径启动,如果你想让你的es只启动一个节点,可以进行如下设置:
node.max_local_storage_nodes: 1
7. 设置一个索引的碎片数量,默认值为5:
index.number_of_shards: 5
8. 设置一个索引可被复制的数量,默认值为1:
index.number_of_replicas: 1
当你想要禁用公布式时,你可以进行如下设置:
index.number_of_shards: 1
index.number_of_replicas: 0
这两个属性的设置直接影响集群中索引和搜索操作的执行。假设你有足够的机器来持有碎片和复制品,那么可以按如下规则设置这两个值:
1) 拥有更多的碎片可以提升索引执行能力,并允许通过机器分发一个大型的索引;
2) 拥有更多的复制器能够提升搜索执行能力以及集群能力。
对于一个索引来说,number_of_shards只能设置一次,而number_of_replicas可以使用索引更新设置API在任何时候被增加或者减少。
ElasticSearch关注加载均衡、迁移、从节点聚集结果等等。可以尝试多种设计来完成这些功能。
可以连接http://localhost:9200/A/_status来检测索引的状态。
9. 配置文件所在的位置,即elasticsearch.yml和logging.yml所在的位置:
path.conf: /path/to/conf
10. 分配给当前节点的索引数据所在的位置:
path.data: /path/to/data
可以可选择的包含一个以上的位置,使得数据在文件级别跨越位置,这样在创建时就有更多的自由路径,如:
path.data: /path/to/data1,/path/to/data2
11. 临时文件位置:
path.work: /path/to/work
12. 日志文件所在位置:
path.logs: /path/to/logs
13. 插件安装位置:
path.plugins: /path/to/plugins
14. 插件托管位置,若列表中的某一个插件未安装,则节点无法启动:
plugin.mandatory: mapper-attachments,lang-groovy
15. JVM开始交换时,ElasticSearch表现并不好:你需要保障JVM不进行交换,可以将bootstrap.mlockall设置为true禁止交换:
bootstrap.mlockall: true
请确保ES_MIN_MEM和ES_MAX_MEM的值是一样的,并且能够为ElasticSearch分配足够的内在,并为系统操作保留足够的内存。
16. 默认情况下,ElasticSearch使用0.0.0.0地址,并为http传输开启9200-9300端口,为节点到节点的通信开启9300-9400端口,也可以自行设置IP地址:
network.bind_host: 192.168.0.1
17. publish_host设置其他节点连接此节点的地址,如果不设置的话,则自动获取,publish_host的地址必须为真实地址:
network.publish_host: 192.168.0.1
18. bind_host和publish_host可以一起设置:
network.host: 192.168.0.1
19. 可以定制该节点与其他节点交互的端口:
transport.tcp.port: 9300
20. 节点间交互时,可以设置是否压缩,转为为不压缩:
transport.tcp.compress: true
21. 可以为Http传输监听定制端口:
http.port: 9200
22. 设置内容的最大长度:
http.max_content_length: 100mb
23. 禁止HTTP
http.enabled: false
24. 网关允许在所有集群重启后持有集群状态,集群状态的变更都会被保存下来,当第一次启用集群时,可以从网关中读取到状态,默认网关类型(也是推荐的)是local:
gateway.type: local
25. 允许在N个节点启动后恢复过程:
gateway.recover_after_nodes: 1
26. 设置初始化恢复过程的超时时间:
gateway.recover_after_time: 5m
27. 设置该集群中可存在的节点上限:
gateway.expected_nodes: 2
28. 设置一个节点的并发数量,有两种情况,一种是在初始复苏过程中:
cluster.routing.allocation.node_initial_primaries_recoveries: 4
另一种是在添加、删除节点及调整时:
cluster.routing.allocation.node_concurrent_recoveries: 2
29. 设置复苏时的吞吐量,默认情况下是无限的:
indices.recovery.max_size_per_sec: 0
30. 设置从对等节点恢复片段时打开的流的数量上限:
indices.recovery.concurrent_streams: 5
31. 设置一个集群中主节点的数量,当多于三个节点时,该值可在2-4之间:
discovery.zen.minimum_master_nodes: 1
32. 设置ping其他节点时的超时时间,网络比较慢时可将该值设大:
discovery.zen.ping.timeout: 3s
http://elasticsearch.org/guide/reference/modules/discovery/zen.html上有更多关于discovery的设置。
33. 禁止当前节点发现多个集群节点,默认值为true:
discovery.zen.ping.multicast.enabled: false
34. 设置新节点被启动时能够发现的主节点列表(主要用于不同网段机器连接):
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
35.设置是否可以通过正则或者_all删除或者关闭索引
3、Elasticsearch配置优化
1、skywalking的elastixsearch配置优化
#bulkActions默认1000次请求批量写入一次改到4000次。
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:4000} # Execute the bulk every 1000 requests
#flushInterval每10秒刷新一次堆改为每30秒刷新。
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:30} # flush the bulk every 10 seconds whatever the number of requests
#concurrentRequests并发请求的数量由2改为4。
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:4} # the number of concurrent requests
#metadataQueryMaxSize查询的最大数量由5000改为8000。
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:8000}
2、elasticsearch内置参数优化
index.merge.scheduler.max_thread_count# 索引 merge 最大线程数
index.refresh_interval#index 刷新间隔
index.translog.durability# 这个可以异步写硬盘,增大写的速度
index.translog.sync_interval #translog 间隔时间
curl -H "Content-Type: application/json" -u -key elastic:elastic -X PUT 'http://172.16.45.7:9200/_all/_settings?preserve_existing=true' -d '{
"index.merge.scheduler.max_thread_count" : "1",
"index.refresh_interval" : "30s",
"index.translog.durability" : "async",
"index.translog.sync_interval" : "120s"
}'
3、验证ES高可用配置
http://localhost:9200/_all/_settings
ES数据库高可用配置的更多相关文章
- MariaDB+Keepalived双主高可用配置MySQL-HA
利用keepalived构建高可用MySQL-HA,保证两台MySQL数据的一致性,然后用keepalived实现虚拟VIP,通过keepalived自带的服务监控功能来实现MySQL故障时自动切换. ...
- MySQL MGR+ Consul之数据库高可用方案
背景说明: 基于目前存在很多MySQL数据库单点故障,传统的MHA,PXC等方案用VIP或者DNS切换的方式可以实现.基于数据库的数据强一致性考虑,采用MGR集群,采用consul服务注册发现 ...
- 美团点评MySQL数据库高可用架构从MMM到MHA+Zebra以及MHA+Proxy的演进
本文介绍最近几年美团点评MySQL数据库高可用架构的演进过程,以及我们在开源技术基础上做的一些创新.同时,也和业界其它方案进行综合对比,了解业界在高可用方面的进展,和未来我们的一些规划和展望. MMM ...
- 基于Consul的数据库高可用架构【转】
几个月没有更新博客了,已经长草了,特意来除草.本次主要分享如何利用consul来实现redis以及mysql的高可用.以前的公司mysql是单机单实例,高可用MHA加vip就能搞定,新公司mysql是 ...
- Centos7 Mysql 双机热备实现数据库高可用
mysql双主热备,也称主主互备,目的是mysql数据库高可用,只支持双机,原因是mysql的复制是一主多从,但一个从服务器只能有一个主服务器. 双机热备的条件是双机mysql版本必须一致. 服务器分 ...
- Rabbitmq安装、集群与高可用配置
历史: RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多 ...
- (转)Oracle与DB2在数据库高可用技术上的相同与差异探讨
原文:http://www.talkwithtrend.com/Article/178339 数据库建设过程中,高可用是每一个企业数据中心数据库建设过程中至关重要的一个关注点,直接关系到业务连续性和稳 ...
- Mysql双机热备实现数据库高可用
mysql双主热备,也称主主互备,目的是mysql数据库高可用,只支持双机,原因是mysql的复制是一主多从,但一个从服务器只能有一个主服务器. 双机热备的条件是双机mysql版本必须一致. 服务器分 ...
- MHA高可用配置及故障切换
MHA高可用配置及故障切换 目录 MHA高可用配置及故障切换 一.案例概述 二.案例前置知识点 1. MHA概述 2. MHA的组成 (1)MHA Manager(管理节点) (2)MHA Node( ...
随机推荐
- matlab多项式拟合以及指定函数拟合
clc;clear all;close all;%% 多项式拟合指令:% X = [1 2 3 4 5 6 7 8 9 ];% Y = [9 7 6 3 -1 2 5 7 20]; % P= poly ...
- Python利用xlutils统计excel表格数据
假设有像上这样一个表格,里面装满了各式各样的数据,现在要利用模板对它进行统计每个销售商的一些数据的总和.模板如下: 代码开始: 1 #!usr/bin/python3 2 # -*-coding=ut ...
- (十五)、shell脚本之简单控制流结构
一.基本的控制结构 1.控制流 常见的控制流就是if.then.else语句提供测试条件,测试条件可以基于各种条件.例如创建文件是否成功.是否有读写权限等,凡是执行的操作有失败的可能就可以用控制流,注 ...
- ConstraintLayout 学习笔记
如何阅读 xml 属性 与 Relativelayout 不同,ConstrainLayout 的属性需要同时说明需要怎么操作自己与目标控件,例如:layout_constraintLeft_toLe ...
- java时间的一些处理
获取当前时间 System.currentTimeMillis() //第一种 Date date = new Date(); System.out.println(date.getTime()); ...
- python之scrapy篇(三)
一.创建工程(cmd) scrapy startproject xxxx 二.编写item文件 # -*- coding: utf-8 -*- # Define here the models for ...
- 「Elasticsearch」ES重建索引怎么才能做到数据无缝迁移呢?
背景 众所周知,Elasticsearch是⼀个实时的分布式搜索引擎,为⽤户提供搜索服务.当我们决定存储某种数据,在创建索引的时候就需要将数据结构,即Mapping确定下来,于此同时索引的设定和很多固 ...
- JAVA NIO Selector Channel
These four events are represented by the four SelectionKey constants: SelectionKey.OP_CONNECT Select ...
- i5 11300H 怎么样 相当于什么水平
i5-11300H 为 4 核 8 线程,主频 3.1GHz,睿频 4.4GHz,三级缓存 8MBi5-11300H 怎么样看完你就知道了 https://list.jd.com/list.html?
- 一文详解 ARP 协议
我把自己以往的文章汇总成为了 Github ,欢迎各位大佬 star https://github.com/crisxuan/bestJavaer 公众号连载计算机网络文章如下 ARP,这个隐匿在计网 ...