【论文研读】Sabir, Ekraam, et al. "Recurrent convolutional strategies for face manipulation detection in videos." Interfaces (GUI) 3.1 (2019).
#摘要
错误信息通过合成逼真的图像和视频进行传播这一严重问题,需要鲁棒的篡改检测方法来应对。尽管在检测静止图像上的面部篡改方面已付出了巨大的努力,但人们对于通过利用视频流中存在的时序信息,对视频中被篡改面部的识别方面的研究较少。循环卷积模型是一类深度学习模型,已证明能够有效地利用跨域图像流中的时序信息。因此,我们通过广泛的实验,提出了将这些模型中的变化与特定领域的面部预处理技术相结合的最佳策略(根据后文应该是面部对齐和CNN (DenseNet) + bidirectional RNN),从而在公开的基于视频的面部篡改benchmark上达到了目前最先进的性能。具体来说,我们尝试检测Deepfake,Face2Face和FaceSwap生成的视频流中的篡改人脸。对最近提出的 FaceForensics++数据集进行评估,将以前的最先进技术的精确度提高 4.55%。
1. Introduction
错误信息可以以不同的方式表现:直接篡改信息(如copy-move和splicing)或在误导的环境中呈现未篡改的内容(如image repurposing)。
通过深度学习生成的人脸的伪像是如此微妙,以至于评估脸部真假的唯一线索是(i) 头发的微妙不一致 - 头发太直,断线或干脆不自然,(ii) 不自然不对称的脸,(iii) 奇怪的牙齿,更重要的是,大多数时候,(iv) 其他更明显的不一致不在脸上而在背景上。
假视频数量的激增可能归因于两个原因:1. 将某人的身份或表情换成别人的,现在更容易了;2. 一段视频比一张图片更可信。
鉴于上述观察结果,并考虑到人脸篡改生成工具不会在合成过程中增强时间连贯性,而是逐帧执行操作,因此我们提出利用时间上的伪像来指示视频流中的异常人脸。
本文使用循环卷积模型以利用时间差异来改进当前方法。为了消除与视频中面部刚性运动相关的其他混淆因素,本文还使用了面部对齐方法。
2. Related Work
Video processing with deep models.
这方面有三种主要方法:
• 第一种研究从两个流网络 [37] 发展,其中 RGB 视频帧及其光流版本在网络中的两个独立分支中处理,然后是融合机制。
• 第二个是由循环卷积层支持的单个流网络:使用提取高级语义特征的单独卷积神经网络 (CNN) 收集每个帧中内容的感知知识,同时在这些特征上训练一个循环模型,以执行对时间维度的决策。
• 第三种发展使用 3D 卷积 [40, 19] 作为网络中的local building block,以学习丰富的时空特征。
本文认为基于双流架构的方法在动作识别方面是有效的,但与捕获生成器在视频中可能产生的细微闪烁的伪像不相关;并且另一方面,3D卷积虽然可能更适合于此目的,但它们会大大增加可学习的滤波器的数量。因此本文使用第二种方法。
Face manipulation benchmarks.
FaceForensics以及FaceForensics++。
Face Manipulation Detection.
XceptionNet [8]、MesoNet [4]、GoogLeNet等等。
3. Method
篡改检测的整体方法是分成两步:从视频帧裁剪和对齐人脸,然后对预处理面部区域进行篡改检测。
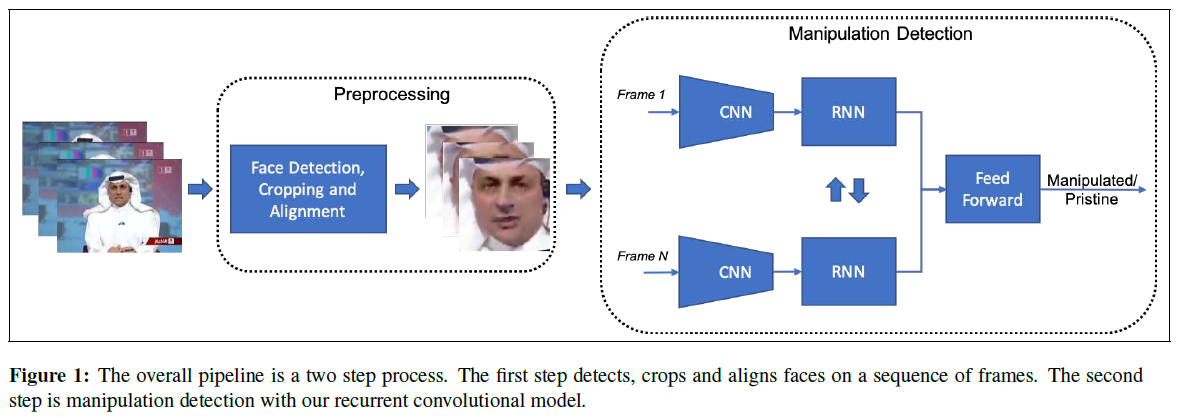
3.1. Face preprocessing
两种用于对齐人脸的技术:(i)使用面部landmark进行显式对齐,其中参考坐标系和面部裁剪的紧度由先验知识决定,并且所有面部都与该参考坐标系对齐,以便补偿面部的任何刚性运动,(ii)使用基于可学习的仿射变换的空间转换网络(STN:Spatial Transformer Network )进行隐式对齐。
Landmark-based alignment.
使用简单的相似度转换(四个自由度)对齐人脸图像,以补偿各向同性比例,平面内旋转和2D平移。转换后,分辨率为224×224。
Spatial Transformer Network.
其包括三个部分:定位网络,网格生成器和采样器。定位网络预测仿射变换参数,并且网格生成器和采样器将输入特征图使用仿射参数包装以生成输出特征图。
3.2. Videobased Face Manipulation Detection
使用循环卷积网络利用视频帧之间的时序伪像进行篡改检测。
Backbone encoding network.
本文使用ResNet [14]和DenseNet [15]作为模型的CNN组件有如下两个原因:
(i)FaceForensics ++ [34]是一个包含1,000个视频的低分辨率数据集,为避免过拟合,作者不得不使用经过预训练的具有固定特征提取层的XceptionNet [8]。
为了实现端到端的可训练性,本文选择了ResNet [14]。
(ii)篡改伪像表现为不需要高级面部语义特征的低级特征(例如不连续的下巴,眼睛模糊等)。
DenseNet也是一种合适的CNN架构,因为它提取了不同层次结构的特征。并使用cross-entropy loss。
RNN training strategies.实验将循环模型放置在backbone网络的不同部分:它将backbone网络连接在一起,充当特征学习器,将特征传递给RNN,随着时间的推移汇总。本文实验了两种策略:第一个是在backbone网络的最终特征之上仅使用单个循环网络。第二个是尝试在backbone网络层次结构的不同级别上学习多个循环网络。从CNN中提取多个特征级别的特征以进行篡改检测,这些特征在单个循环网络中处理,期望这个新的多循环卷积模型能够利用微观,中观和宏观特征进行篡改检测。
4. Experiments
通过实验发现(1)DenseNet优于ResNet,(2)面部对齐可提高性能,(3)图像序列要比单帧输入更好。
5. Conclusion
We found a landmark based face alignment with bidirectional-recurrent-denset to perform the best for face manipulation detection in videos.
【论文研读】Sabir, Ekraam, et al. "Recurrent convolutional strategies for face manipulation detection in videos." Interfaces (GUI) 3.1 (2019).的更多相关文章
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- AD预测论文研读系列2
EARLY PREDICTION OF ALZHEIMER'S DISEASE DEMENTIA BASED ON BASELINE HIPPOCAMPAL MRI AND 1-YEAR FOLLOW ...
- AD预测论文研读系列1
A Deep Learning Model to Predict a Diagnosis of Alzheimer Disease by Using 18F-FDG PET of the Brain ...
- GoogLeNetv4 论文研读笔记
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning 原文链接 摘要 向传统体系结构中引入 ...
- GoogLeNetv3 论文研读笔记
Rethinking the Inception Architecture for Computer Vision 原文链接 摘要 卷积网络是目前最新的计算机视觉解决方案的核心,对于大多数任务而言,虽 ...
- GoogLeNetv2 论文研读笔记
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 原文链接 摘要 ...
- GoogLeNetv1 论文研读笔记
Going deeper with convolutions 原文链接 摘要 研究提出了一个名为"Inception"的深度卷积神经网结构,其目标是将分类.识别ILSVRC14数据 ...
- Paper Reading - Long-term Recurrent Convolutional Networks for Visual Recognition and Description ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4389 Main Points: A novel Recurrent Convolutional Arch ...
- [论文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation 概括 这是一篇2016年的目标检测 ...
随机推荐
- JDK动态代理案例与原理分析
一.JDK动态代理实现案例 Person接口 package com.zhoucong.proxy.jdk; public interface Person { // 寻找真爱 void findlo ...
- go语言中运算符
Go语言学习笔记(运算符)-day01 go语言中与其他语言一样,存在多种运算符,下表列出了go语言中的运算符类型 算数运算符 关系运算符 逻辑运算符 位运算符 赋值运算符 算数运算符 运算符 描述 ...
- Flutter 基础组件:进度指示器
前言 Material 组件库中提供了两种进度指示器:LinearProgressIndicator和CircularProgressIndicator,它们都可以同时用于精确的进度指示和模糊的进度指 ...
- Linux学习笔记 | 配置nginx
目录 一.Nginx概述 二.why Nginx? 三.Linux安装Nginx APT源安装 官网源码安装 四.nginx相关文件的配置 html文件:/var/www/html/index.htm ...
- Head First 设计模式 —— 15. 与设计模式相处
模式 是在某情境(context)下,针对某问题的某种解决方案. P579 情景:应用某个模式的情况 问题:你想在某情境下达到的目标,但也可以是某情境下的约束 解决方案:一个通用的设计,用来解决约束. ...
- 代码审计 - BugkuCTF
extract变量覆盖: 相关函数: extract()函数:从数组中将变量导入到当前的符号表.把数组键名作为变量名,数组的键值作为变量值.但是当变量中有同名的元素时会默认覆盖掉之前的变量值. tri ...
- libnum报错问题解决
之前在使用python libnum库时报错 附上报错内容 Traceback (most recent call last) : File" D:/python file/ctf/RSA共 ...
- oracle rac搭建单实例DG步骤(阅读全篇后再做)
环境介绍 主库: 主机名 rac01 rac02 实体IP 10.206.132.232 10.206.132.233 私有IP 192.168.56.12 192.168.56.13 虚拟IP 10 ...
- CALL TRANSACTION 使用说明
以调用事务VA03为例: 在程序中添加如下代码就可以实现 SET PARAMETER ID 'AUN' FIELD var. CALL TRANSACTION 'VA03' AND SKIP FIR ...
- 痞子衡嵌入式:MCUBootFlasher v3.0发布,为真实的产线操作场景而生
-- 痞子衡维护的NXP-MCUBootFlasher工具(以前叫RT-Flash)距离上一个版本(v2.0.0)发布过去一年半以上了,这一次痞子衡为大家带来了全新版本v3.0.0,从这个版本开始,N ...