CSAPP =2= 信息的表示和处理
思维导图
预计阅读时间:30min

阅读书籍 《深入理解计算机系统 第五版》
参考视频 【精校中英字幕】2015 CMU 15-213 CSAPP 深入理解计算机系统 课程视频
参考文章 《深入理解计算机系统(2.1)---信息的存储与值的计算》
《深入理解计算机系统(2.2)---布尔代数以及C语言上的位运算》
《深入理解计算机系统(2.3)---整数的表示方式精解》无符号与补码编码(重要)》
《深入理解计算机系统(2.4)---C语言的有符号与无符号、二进制整数的扩展与截断》
《深入理解计算机系统(2.5)---二进制整数的加、减法运算(重要)》
《深入理解计算机系统(2.6)---二进制整数的乘、除法运算(重要)【困难度高】》
《深入理解计算机系统(2.7)---二进制浮点数,IEEE标准(重要)》
《深入理解计算机系统(2.8)---浮点数的舍入,Java中的舍入例子以及浮点数运算(重要)》
原文链接 《旻天Clock:CSAPP =2= 信息的表示和处理》:https://zhuanlan.zhihu.com/p/220185200
先出几道题考考各位道友:
- 《问》在对精度有严格要求的程序中,为什么禁止使用浮点型,精度为什么会丢失?《、问》《答》《、答》
- 《问》如何不使用 if/else 来实现返回数字绝对值的方法(注意考虑整型和浮点型两种)《、问》》《答》《、答》
- 《问》为什么 (3.14 + 1e10) - 1e10 != 3.14 + (1e10 - 1e10)《、问》《答》《、答》
二、信息的表示和处理
通过上一章 CSAPP =1= 计算机系统漫游 的学习,相信各位道友已经对计算机系统的硬件和软件有了一些了解。
同时也知道应用程序在计算机中是以二进制的形式存储和传递的。
但光靠 0 和 1 这两个数字又是如何表示各种错综复杂的程序的呢?明明我们更习惯十进制,又为何要发明二进制呢?为啥不是三进制、五进制的?
再抄一段左潇龙大神的引言:
我们很难想象,0 和 1 这两个再简单不过的数字,给计算机科学带来了彻底的改变。对于无法与人脑相比的计算机来说,简单的 0 和 1 却是最适合它们的数字。
不过同样的二进制往往代表不同的含义,它们必须被赋予上下文,才能有具体的含义。比如,如果知道二进制是要表示布尔类型,那么我们就知道 1 是 true,0 是 false。
对于二进制所表示的
数字来说,主要有三种,即无符号、补码以及浮点数。不过计算机对于固定类型的二进制数字往往都有位数限制,比如 int 类型使用四个字节,因此对于无符号整数只能表示 0 ~ 4294967296(2^32,42亿+),再大的数字就没法表示了(溢出)。
而对于有符号整数,产生的溢出结果就更是会超出预期了。
而浮点数就是二进制世界中的科学计数法,但它也有自己的限制,比如开始的 (3.14 + 1e10) - 1e10 != 3.14 + (1e10 - 1e10)。
下面就请带着这些兴趣,来了解信息在计算机中的表示和处理吧。
2.1 信息的存储
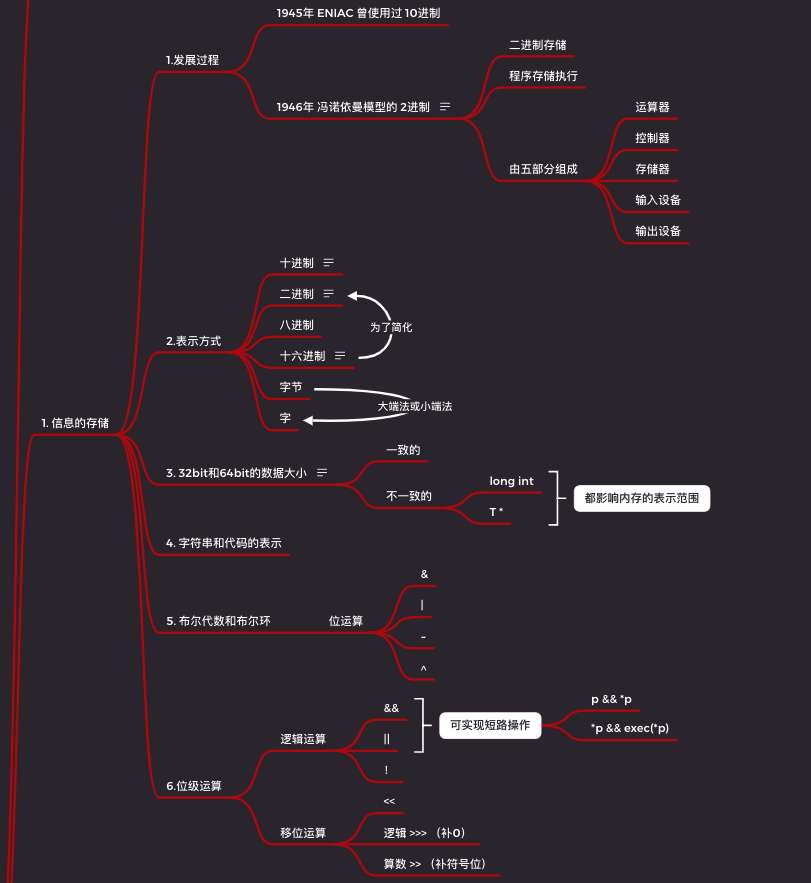
2.1.1 二进制的发展过程
在 1945年,世界上曾出现过一款 十进制 计算机。
但因为二值信号更容易在计算机中表示、存储和传输,如纸带的有孔和无孔,导线上的高电压和低电压。而且基于二值信号的电子电路非常的简单可靠,造价也更加经济。
所以在 1946 年,冯诺依曼模型诞生。冯诺依曼模型有以下三个特点:
- 计算机的数值编码采用二进制;
- 计算机应该按照程序顺序执行;
- 计算机由(运算器、控制器、存储器、输入设备、输出设备)五个部分组成。
2.1.2 数据在计算机的表示形式
二进制
在物理上是利用二极管的特性,使二极管的两端产生不同的高低电压。
而逻辑上就采用0和1来对应上面所说的高低电压,1表示高电压0表示低电压。
十六进制
二进制表示法太长还不直观,而四位一组正好可以用一种叫做十六进制的模式表示。
这样一个字节的表示范围就从 00000000 ~ 11111111 变成了 0x00 ~ 0xFF。
字节
大多数计算机使用 8 个位(bit)的块取名为字节(byte),用来作为内存分配和寻址的最小单位。
而上章中操作系统(OS)会将存储器抽象为一个巨大的字节数组,称为虚拟存储器。数组的下标称为地址(address)。而所有可能地址的集合就称之为虚拟地址空间。
编译器和运行时系统的一个任务就是将存储空间划分为更容易管理的单元,来存放不同的程序对象,如程序的代码、数据。
例如:C中的一个指针的值(不论类型)都是某个或某几个字节块中第一个字节的虚拟地址。而C编译器会把指针和类型关联,这样C编译器就可以根据指针值的类型,生成不同的机器级代码,来访问指针指向处向下相邻的几个字节了。
尽管C编译器维护着这个类型信息,但生成的机器级程序(汇编)并没有关于数据类型的信息。
字
每台计算机都有一个字长(word size),指明长整数和指针的数据位长。
因为虚拟地址就是以这样的字来编码的,所以字长决定的最重要系统参数就是可表示的虚拟地址最大值。
2.1.3 数据大小
由于计算机位数的不同,会造成在数据类型的存储上,采用的位数略有不同,下表是在32位和64位机器下,C语言当中的数字数据类型需要的位数。
C 声明 32 bit机器 64位机器
--------------------------------------------
char 1 1
short int 2 2
int 4 4
long int 4 8
T * 4 8
float 4 4
double 8 8
程序员应该尽量的使自己的程序可以兼容更多类型的机器,这被称作可移植性。而提高可移植性的一方面就是使程序对不同机器的数据类型大小不敏感。
2.1.4 寻址和字节顺序
对于跨越多个字节的程序对象(程序对象指令、数据或者控制信息等,是程序当中对象的统称)来说,我们需要制定两个规则,才能唯一确定一个程序对象的值。比如对于 int 类型的值 0x01234567 来说,如果我们要根据虚拟内存地址去获取这个整数值,那么需要确定:
- 这个 int 的 起始虚拟地址 是多少
- 这四个字节的排列顺序是
01 23 45 67(看着顺眼的大端法) 还是67 45 23 01(看着奇怪的小端法)
计算机通常会把需要多个字节存放的对象放在相邻的一段空间内,并把地址最小的字节地址来代表对象地址。如:
0x100 0x101 0x102 0x103
01 23 45 67
而大多数时候,机器的字节顺序是不可见也不用关心的,但有几种情况例外:
- 当小端法机器的数据要发送给大端法机器时(或情况对调),字里的字节就成了反序的了。所以为了避免这个问题,网络应用程序的代码编写必须遵守相应的网络标准,以确保发送方机器将它的内部表示转换成网络标准,接受方在将网络标准转为自己的内部表示。
- 检查机器级程序时,对表示整数数据的字节顺序有严格要求。
- 当编写规避正常的类型系统的程序时,如强制类型转换时。
强制类型转换
计算机在解释一个数据类型的值时主要有四个因素:
- 位排列规则(大端或者小端)
- 起始位置
- 数据类型的字节数
- 数据类型的解释方式
如,在大端法的机器上,起始位置为 0x100 的位置有个值为 0x61FFFFFF 的整数对象。
对于特定的系统来说,位排列规则和起始位置已经确定,而后两种因素可以通过强制类型转换来改变。
假如代码如下:
#include <stdio.h>
int main(){
unsigned int x = 0x61FFFFFF;
int *p = &x;
char *cp = (char *)p;
printf("%c\n",*cp); # print a, 因为 a 的 ASCII 编码为 61
}
2.1.5 表示字符串
C 中的字符串被编码为一个以 null (也就是零0)结尾的字符数组,而每个字符又是由某种标准编码表示,比较常见的编码有 ASCII、GBK、UTF-8 等。
各编码的来历和区别,可以看我的另一篇文章《计算机编码的发展史》
如果我们打印一个 ASCII 字符串如 “12345” 的字节编码,可以得到结果 “31 32 33 34 35 00”,并且在任何系统都是这些值和这个顺序。因而,文本数据比二进制数据具有更强的移植性。
2.1.6 表示代码
源代码
源代码对于机器而言就是文本数据,上面我们说了,文本数据具有很强的移植性。
二进制代码
不同机器类型使用不同的且不兼容的指令和编码方式。即便处理器支持相同的机器级指令,也不一定会完全是二进制兼容的。二进制代码很少能在不同的机器和操作系统组合之间移植。
即便是 JVM 这种的虚拟机(或叫解释器)也不能做到绝对的二进制重用。因为 JVM 只是将
.class这种特殊的二进制转化为真正底层处理器可执行的机器指令。
2.1.7 布尔代数和环
因为二进制值是计算机编码、存储和执行的核心,所以围绕数值 0 和 1 已经演化了非常丰富且有趣的数学知识体系。
布尔代数
这起源于 1850 年左右,乔治丶布尔的工作,他将二进制的 1 和 0 翻译为逻辑值 TRUE(真)和 FALSE(假),并设计出一种代数来研究命题逻辑的属性,因此这套理论被称为 “布尔代数”。
我们不需要去彻底的了解这个知识体系,但是里面定义了几种二进制的运算,却是我们在平时的编程过程当中也会遇到的。
下面是展示了四种最基本的二进制运算:
非 ~
-------------------
0 1
1 0
与 & 0 1
-------------------
0 0 0
1 0 1
或 | 0 1
-------------------
0 0 1
1 1 1
异或 ^ 0 1
-------------------
0 0 1
1 1 0
同时这种运算可以扩展到 N 位二进制上,形成集合的四种运算 补集、交集、并集、差集:
假如有两个集合如下:
a = [01101001] ==集合抽象==> {0, 3, 5, 6}
b = [01010101] ==集合抽象==> {0, 2, 4, 6}
则对于运算有:
操作 描述 二进制表示 集合表示
---------------------------------------------------------
~a 对a集合求补集 [10010110] {1, 2, 4, 7}
a&b 求a、b集合的交集 [01000001] {0, 6}
a|b 求a、b集合的并集 [01111101] {0, 2, 3, 4, 5, 6}
a^b 求a、b集合的差集 [00111100] {2, 3, 4, 5}
布尔环
布尔环的概念就更加的偏向数学了,这里我也只是了解了个大概。不过这里有一个概念一定要了解,不然之后的二进制运算就会迷糊了。
什么是模数运算?
一个代数就是被定义为一组元素、一些关键运算和一些重要元素的环,比如二进制的<{0,1}, ~, &, |, ^, 0, 1>。
而模数运算也构成了一个环,对于模数 n,代数环表示为 <Zn, +n, -n, *n, 0, 1>,其中各部分定义如下:
Zn = {0, 1, ---, n-1}
A +n B = (A + B) mod n
A *n B = (A * B) mod n
如果是整数运算,直观上可以感受到 A + B 在大于 n 的情况下显然不等于 (A + B) mod n,而模数运算就认为他们是相等的,这也就是二进制产生溢出时结果偏离直觉的情况了。
除了数学家,还有谁关心布尔环呢?
当播放脏的或损坏的 CD 时,为了对错位纠错会利用纠错算法,而这算法的核心理论就是布尔环了。
2.1.8 C 中的位级运算
在C语言中,也支持位运算,而它的计算方式就是布尔代数中的位运算。
非、与、或、异或
我们最常使用的是掩码方式。
比如我们知道一个整数 x = 0x76543210,如果我们想取得这个整数的最后两个字节的整数值 0x10 的话,就可以采用位运算。就像下面这样。
0x76543210
& 0x000000FF
Out 0x00000010
在比如我们想实现一个对整数参数的交换函数,C的源码如下:
void swap(int *x, int *y) # 初始 x = a, y = b
{ # 技巧 a ^ a = 0
*x = *x ^ *y; # 此时 x = a ^ b
*y = *x ^ *y; # 此时 y = x ^ b = a ^ b ^ b = a ^ 0 = a
*x = *x ^ *y; # 此时 x = x ^ a = a ^ b ^ a = 0 ^ b = b
}
逻辑运算
C语言中的逻辑运算有||、&&和!,这比较容易与刚才的|,&和~搞混。逻辑运算比较特别,在这种运算的结果中认为所有非 0 的数值都是 true,而为 0 的则为 false。
!0x41 (true) = 0x00 (false)
!!0x41 (true) = 0x01 (true)
0x105 (01101001) & 0x85 (01010101) = 0x65 (01000001)
0x105 (true) && 0x85 (true) = 0x01 (true)
同时逻辑运算有短路的特性,利用指针的短路特性可以写出更优雅的代码,如 p && *p,如果 p 没有值(0,null)就是 false,那 && 就不会计算后面的语句了,因为表达式一定是 false,这样就可以避免空指针的问题。
移位运算
移位运算分为两种,左移和右移。
对于一个n位的二进制数[Xn-1, Xn-2, ---, Xn]来说,如果将它进行左移运算,则 x << k = [X(n-1-k), X(n-2-k), ---, X0, 0, ---, 0],等于丢弃了左侧 k 个最高位,右侧补 0。
而对于右移运算与左移是类似的,只不过为了照顾有符号数,分为了逻辑右移和算数右移。
- 对于逻辑右移来说,
x >> k=[0, ---, 0, Xn-1, Xn-2, ---, Xk] - 而对于算术右移来说,
x >> k=[Xn-1, ---, Xn-1, Xn-1, Xn-2, ---, Xk]。
需要注意的是,
x >> k应该是x >> (k mod n)的简写,什么意思呢?比如:
对于八位的二进制00000001 << 7 == 10000000,这没有问题。
但00000001 << 8 == 00000001 << (8 mod 8) == 00000001
2.2 整数的表示
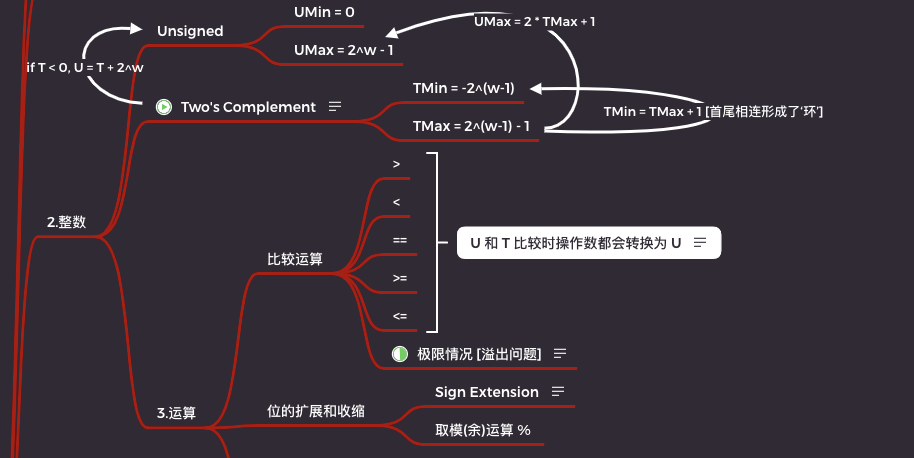
上面我们已经了解了数据在计算机中的表示,以及基于 0 和 1 产生的数学理论学科布尔代数和布尔环。
接下来我们就来深入的学习一下计算机是如何表示一个整数的。
2.2.1 整型数据类型
整数分为有范围的整数(有符号数)和有范围的非负整数(无符号数)两种。
还是以C语言为例,八种整数类型的表示范围如下图所示:
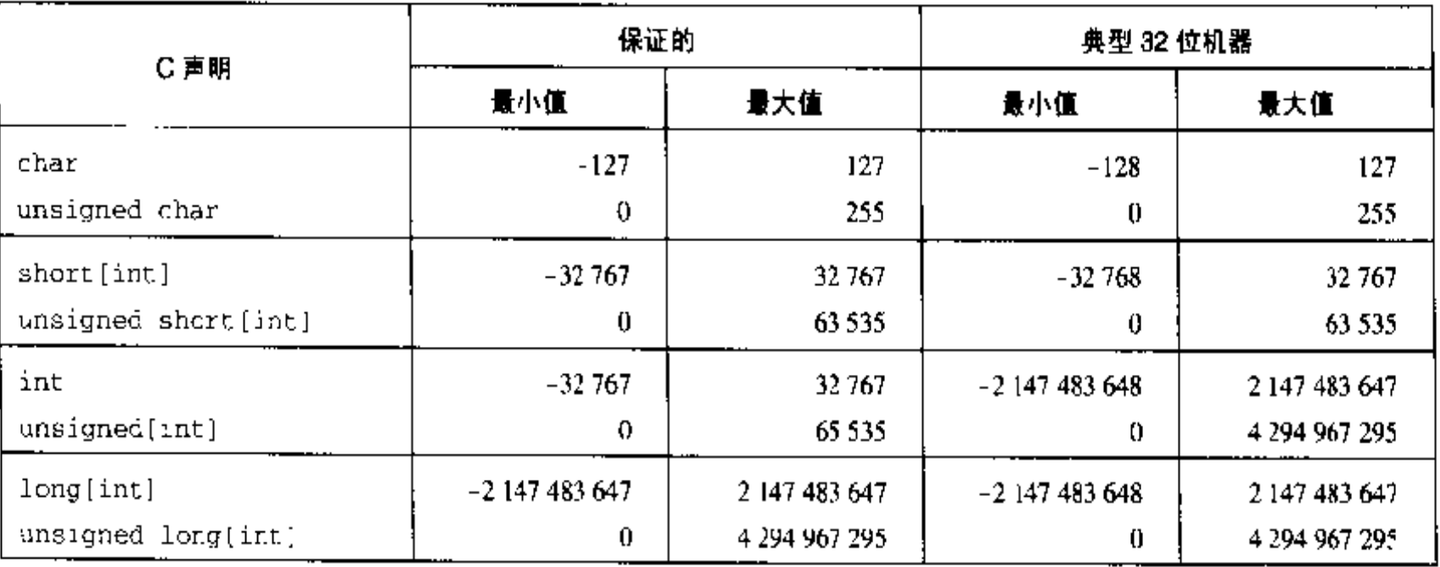
这里可以说一个小技巧,
2 ^ 10 = 1024这个大家肯定早已烂熟于心。所以可以估计2 ^ 10 = 10 ^ 3, 也就是二进制:十进制 = 10:3。
那么 int 是 4 字节 32 位长度,所以表示范围大约就是2 ^ (2+30) = 4 * (2^30) = 4 * (10^9)。
2.2.2 无符号和补码
无符号整数
从上面可以看到每一种整数类型都可以加 unsigned 关键字,来表示一个非负整数,也就是无符号数。
对于一个 w 位的二进制来说,它的无符号表示为以下形式:

看不懂公式不要紧,但是大家应该都知道二进制转十进制步骤是:
二进制 11101011
用集合表示为 {7, 6, 5, 3, 1, 0}
则十进制为 (2^7) + (2^6) + (2^5) + 0 + (2^3) + 0 + (2^1) + (2^0)
因此我们可以看出无符号整数的最大值就是全集,也就是全是 1 的时候,得到的最大值我们用 UMax 表示。对于 w 位的二进制,表示的十进制值为 (2^w)-1。
而最小值不用说了,就是二进制全 0 时表示的十进制 0。
原码整数
可以看出无符号整数是无法表示负数的,这在科学且严谨的计算机中是无法接受的。因此我们需要像个办法表示负数,那就是把最高位定义为符号位,0 表示整数、1 表示负数,其余位的意义不变。
但原码表示又产生了新的问题:
- 表示的 0 有两种情况,+0(0000) 和 -0(1000)
- +1(0001) 和 -1(1001) 相加等于 -2(1010)
反码整数
接着为了解决原码的问题,又引入了反码的概念。反码比原码稍微麻烦一点,但概念还是十分简单,就是先用0+无符号表示正数,然后1+按位取反表示相应的负数。
比如 5(0101) + -5(1010) = -0(1111)
不同通过上面例子我们也看到了,正负 0 的问题还是没有解决
补码整数
重头戏来了,补码是什么,在学校老师可能是这么描述:
补码正数= 反码正数= 如:+1 = 0001
补码负数= 反码负数+1= 如:-1 = 1110 + 1 = 1111
这么描述没毛病,而且简单粗暴,但实际上,他最先的定义是这样的:
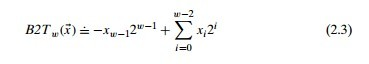
意思就是最高位的十进制含义取反,这听着好像没有老师总结的规律好,但是我们看例子:
二进制 11101011
用集合表示为 {-7, 6, 5, 3, 1, 0}
则十进制为 -(2^7) + (2^6) + (2^5) + 0 + (2^3) + 0 + (2^1) + (2^0)
也就是没有什么取反,没有加一,还是无符号数的那一套,只不过对最高位相减,可以更快的明白当初前辈们设计的初衷,更快的将补码转为十进制。
作为目前还在广泛使用的二进制整数表示方式,我就在多说一点吧。参考 补码是谁发明的,它的最初作用是什么?
补码出现就是为了解决三个重要问题:1. 表示负数;2. 不要双 0 问题产生的二义性;3. 可以用加法来代替减法。
先来回顾一下数学里面的加法。首先画一个数轴,在有限集合里它会是一段线段:

所以表示 1 + 2 = 3 是因为在 1 处的一个点移动两个单位到了 3 处。
减法也是相同的道理。
而表示 4 + 4 = 8 会因为线段不够长而无法表示,但会知道这个值为 7 + 1,如果延伸数轴即可表示。
而计算机所能表示的数轴是不能无限延伸的,结合我们之前学习的布尔环可知,它不像是一个线段,更应该是一个如下的环:
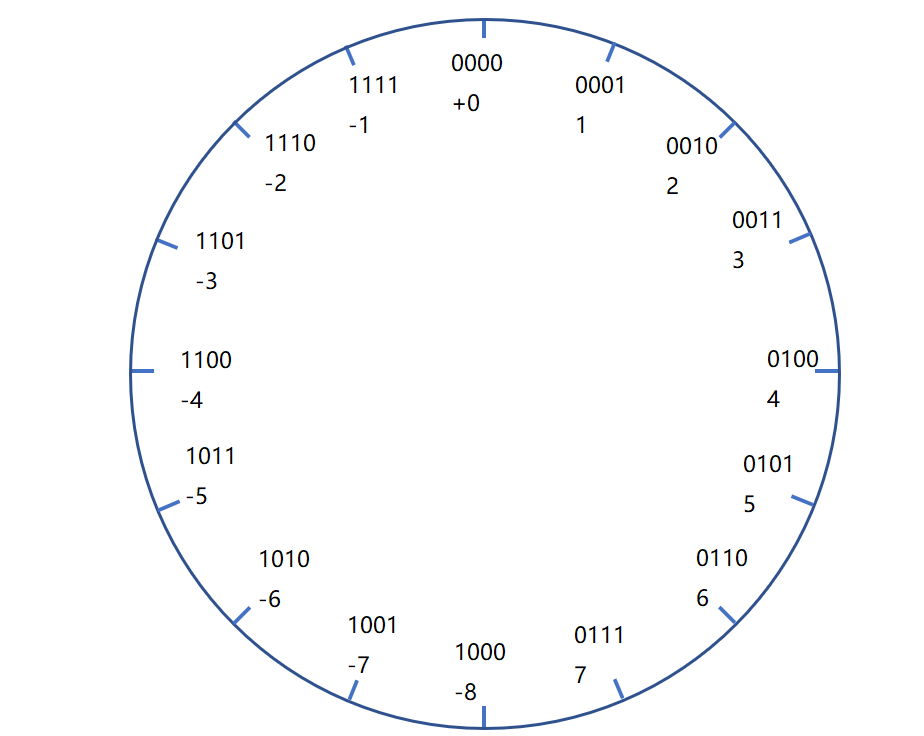
同样表示 1 + 2 = 3 ,假如在 1 处的一个点顺时针(加法)移动两个单位到了 3 处。
而表示 4 + 4 = -8 会因为环结构停在 -8 处,这也就是所谓的正溢出了。
同时也能看出对于补码最小值 TMin = -2^(w-1),而 TMax 比 Tmin 的绝对值少 1(因为给了0),所以 TMax = 2^(w-1) - 1
总结
所以总结一下发展过程,不要去记规则,而是去想象当初因为什么目的去这样设计:
无符号数 => 原码 => 反码 => 补码
简单有用 => 双 0 问题 => 双 0 问题 => 能加能减
没有负数 => 能加不能减
2.2.3 补码和无符号的转换
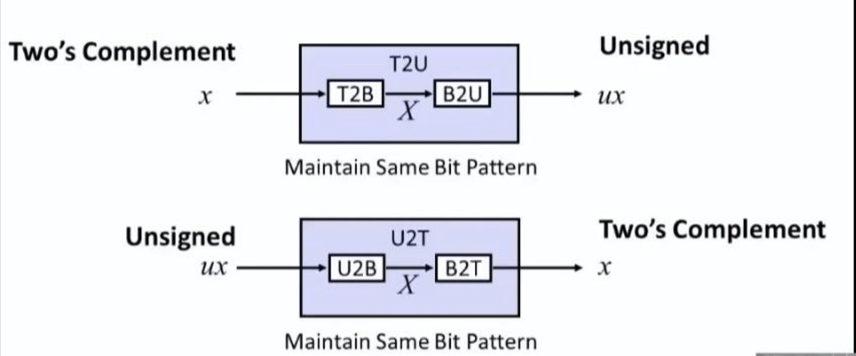
关于转换很简单,就是按照原始规则先转为二进制,再按照目标规则转为十进制即可。
简单总结一下规则:
- 补码的正数和无符号正数表示一样;
- 补码的负数等于无符号数
-2^w。T(1110) = U(8+4+2) - 2^4 = U(14) - 16 = T(-2) - UMax = Tmax * 2 + 1
关于总结三,我再详细说一下。比如
TMax = 0111,UMax = 1110 + 1,而0111 -> 1110是什么关系,不就是左移一位(乘2)了吗!
2.2.4 C中的有符号数和无符号数
尽管 C 标准没有指定使用哪种有符号数编码(原码、反码、补码),但几乎所有机器都使用二进制补码编码。而 C 中的大多数数字都是有符号的,如果想创建一个无符号常量,则必须在后缀加上字符 U 或者 u。
C 允许两者之间的转换,原则上二进制位表示保持不变,解释方式改变,相当于我们上面说的转换规则。
转换一般发生在强制类型转换时,分为显示和隐式的情况,如:
int tx, ty
unsigned ux, uy
# 显示类型转换
tx = (int) ux;
uy = (unsigned) ty;
# 隐式类型转换
tx = ux
uy = ty
注意,当一个表达式中同时出现有符号和无符号两种时,那么 C 会隐含的将有符号数强制转化为无符号数处理,也就是负数会变成非负的。
参数1 操作符 参数2 结果 原理
0 == 0U 1 (true) -
-1 < 0U 0 (false) T(-1) = UMax > 0U
UMax/2 > TMin-1 0 (false) TMin = UMax/2, TMin = UMax/2 - 1 < UMax/2
TMax > (int)UMax/2 0 (false) int(UMax/2) = 溢出TMin < TMax
所以,在以后我们需要跨类型比较的时候,可以将极限和特殊值带入表达式,这将更容易得到验证结果。如将 0、Tmin、Tmax、UMax 等带入表达式。
2.2.5 位数扩展
当我们将一个短整型的变量转换为整型变量时,就涉及到了位的扩展,此时由两个字节扩充为四个字节。
扩展的高位就是补充符号位。对于正数而言,高位补 0 明显不会对值造成改变。
而对于负数,高位补符号位 1,虽然不明显,但确实结果值也没变化。
下面我来分析一下原因:
假如原本的二进制为: 1100 = -8 + 4 = -4
先扩展一位到五位后为: 11100 = -16 + 8 + 4 = -4
看两次不同,其实 -16 + 8 = -8,和扩展前是一样的。
2.2.6 位数截断
正所谓“由奢入简易,由简入奢难”。位数扩展概念简单还不会影响表示结果,但位数截断却会对表示结果造成很大影响。
截断和扩展相反,它是将一个多位二进制序列截断至较少的位数,也就是与扩展是相反的过程。
回忆一下之前的布尔代数或者上面的补码环。所以对于位数的截断就是一个取模运算。
2.2.7 关于有符号和无符号的建议
可以看到在进行强制类型转换的时候,可能会出现与直觉不相符的情况,而这些不相符的情况很容易导致程序错误。
举例1:
int arr[] = [1,2,3,4,5]
unsigned i
for(i=4; i >= 0; i--){
# i 到 0 之后不会停止循环,而是会变成 UMax
print(arr[i])
}
举例2:
int arr[] = [1,2,3,4,5]
int i
for(i=1; sizeof(arr) - i >= 0; i++){
print(arr[i-1])
}
sizeof 会返回一个 unsigned,结果和例子1产生相同bug。
避免这种错误的一个有效办法就是不使用无符号数,实际上除了C以外,很少有语言支持无符号整数。
2.3 整数运算
刚入门的程序员有时会发现神奇的一幕,两个正数相加竟然得到了一个负数。
而且移项操作有时也不可靠了,如 x > y 但 x-y < 0。
而这些问题或者说特性就是计算机运算的有效性造成的,虽然现在的高级编程语言已经很少出现这种问题了,但理解计算机在二进制运算上的细微之处能够帮助我们写出更可靠的代码。
2.3.1 无符号加法
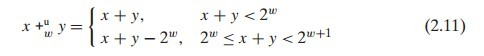
无符号的加法相对简单,只要理解了前面对 位数截断 的概念即可。而需要截断的表达式就是所谓的 溢出。
溢出在我们的数学认知上是违反常理的,但对计算机而言,它是没出错的。这点一定要记得,因为之后我们还会遇到正溢出、负溢出和乘法溢出的问题。
2.3.2 二进制补码加法
对于补码的加减法,我们在前面的补码环处已经介绍了,这里不做过多介绍。我重点说一下溢出的问题。
- 正溢出:两个正数相加,理想值为正数,结果却返回了负数。
- 负溢出:两个负数相加,理想值为负数,结果却返回了正数。
2.3.3 二进制补码的非
对于补码中除 TMin 以外的每个值 x,都有唯一的一个加法逆元 -x,使 x + (-x) = 0。((TMin) 没有对应的加法逆元,因为补码的正负集合不是对称的)。
那么二进制又是如何实现 ~ 运算得到逆元的呢?先记着结论吧,还是老师教的 取反加一。比如 -2(1110) 的逆元为 2(0010)。
如何得来的呢?我有个新的验证思路,就是利用截断和溢出原理。
假如 x=-2(1110),而为了产生溢出并溢出后结果为0,则需要出现一个 1111 + 1 = 10000 截断得 0000。
1111 是全集,减去 x 的集合,得到的就是补集(x取反)。
所以 x 的逆元就是我们常听的 取反加一。
因为很多 CPU 只有加法器是没有减法器的,而他们实现减法的方式就是将减法转为加逆元的方式,虽然多了一步操作,却省了一部分减法器的空间和造价。
2.3.4 无符号乘法
无符号乘法在概念上还算简单:

要知道两个 w 位的无符号数相乘,那么最大可能需要 2w 位来表示,再结合之前说的 截断 的原因和目的,就得出了这个结论。
2.3.5 二进制补码乘法
这里是我看的最懵的一部分了,这里我就大概的说说自己的思路。首先公式是:
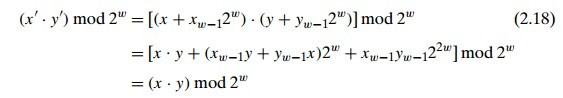
x' 表示无符号数 T2U(x),则有 x' = x + 符号位 * (2^w),再按上图推导,可得 无符号数的乘积取模等于补码的乘积取模。
上面的结论也意味着机器可以使用一种乘法指令来进行有符号无符号两种乘法指令集和硬件。
2.3.6 乘以 2 的幂
记得我们刚学乘法的时候,老师教我们 a * b 等于 b 个 a 相加。计算机虽然不会傻到真的一遍遍把 a 相加 b 次,但对于老式乘法器,也会消耗至少 12 个时钟周期完成一次乘法。
而新式乘法器已经大大改进只需要 3 个时钟周期即可完成一次乘法运算。
不过聪明的编译器可以通过移位和加减法来优化乘法,只需要 2 个甚至 1 个(乘以2次幂)时钟周期即可完成一次优化乘法。
证明过程如下:
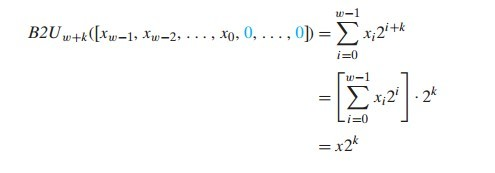
我们举个例子:对于 x * 17,我们可以计算 x * 16 + x = (x << 4) + x ,这样算下来的话,我们只需要一次移位和一次加法就可以搞定这个乘法运算。
而对于x * 14,则可以计算 x * 8 + x * 4 + x * 2 = (x << 3) + (x << 2) + (x << 1) 。
更快的方式我们可以这么计算,x * 16 - x * 2 = (x << 4) - (x << 1) 。
2.3.7 除以 2 的幂
在大多数机器上,整数的除法会比乘法更慢,需要30甚至更多的时钟周期。而且即便是现代计算机,除法也依旧很慢。
除以2的幂也可以使用右移运算来实现。无符号要逻辑右移 >>>,补码要算数右移 >>。
我们应该知道,两个整数如果无法整除,计算机会返回一个近似整数,而不是小数或浮点数,这就是除法的舍入问题。
舍入
对于二进制补码的除法,对结果总是向 0 舍入的。
对于无符号除法,除以2^k等价于右移k位,如:
a = 17 = 00010001
b = 8 = 00001000 = 2 ^ 3
a/b = 2 = 00000010 = 00010001 >> 3
因为对正数而言,向下舍入就等于截断或者取模运算。补码的正数部分和无符号数同理。
但对于补码的负数部分就有些麻烦了,如果我们还是单纯的右移代替除法,则:
a = -17 = 11101111
b = 8 = 00001000 = 2 ^ 3
a/b = -3 = 11111101 = 11101111 >> 3
目标 = -2 = 11111110
因为对于负数而言,截断等于向下取整,而不是向零舍入,为了补救这个问题,计算机的大佬们引入了一个新的概念偏置。也就是通过在移位之前“偏置”这个值,来修正不合适的舍入。
先来验证一下偏置的可行性,先定义两个符号 ┌向上取整┐ 和 └向下取整┘。则我们有 ┌x/y┐ = └(x+y-1)/y┘ 。
这一过程的证明不难理解,我们假设x = ky + r(我们考虑余数 r > 0 且 r < y,此时会有舍入发生),则有 └(x+y-1)/y┘ = └(ky+r+y-1)/y┘ = k + └(r+y-1)/y┘ = k + 1
再拿之前的例子验证一下:
a = -17 = 11101111
b = 8 = 00001000 = 2 ^ 3
偏置 = b-1 = 00000111 = 7
a+偏置 = -17+8 = 11110110 = -9
(a+偏置)/b = -2 = 11111110 = 11110110 >> 3
目标 = -2 = 11111110
2.4 浮点
之前我们已经学习了如何用二进制表示整数,整数可以解决计算机中很大一部分存储、表示、运算的问题了,但还没有办法表示更精确的小数,这对严谨的计算机科学是不能接受的。
对原码进行一点点的扩展即可表示小数,也就是二进制小数,但它有着很多的局限性却有着很小的表示范围。
而浮点数表示法可以更好的表示小数。但当时每个计算机制造商都有一套自己的浮点数标准,这给程序的可移植性造成了很大的困扰。有需求就有创新,最终在1985年左右,浮点数标准 IEEE-754 就应运而生了。
下面让我们来具体的学习一下 IEEE 浮点。
2.4.1 二进制小数
尽管现在计算机中几乎没有使用二进制小数编码来表示十进制小数的情况了,但并不妨碍我们了解一下小数编码的进化史,而且学习 IEEE 也需要知道二进制小数的转换规则。
二进制小数的表达式是这样的:
举例说明二进制转换十进制的过程:
二进制小数 0101.101
过程 (2^2) + (2^0) + (2^-1) + (2^-3)
结果 5 + 5/8
明明很简单的表示过程,为什么最后没有计算机厂商使用呢?因为:
- 表示精度有限,如 1/3、1/5 就只能表示近似值。
- 表示范围有限,之前我们知道 float 和 double 的表示位数只有 32 和 64 位,如果采用这种小数表示法,并把小数点放到位数中间,那么会使原来的表示范围减少指数倍。
2.4.2 IEEE 浮点表示
假如用8位来表示 3.5,并规定小数点在第四位和第五位中间,那么二进制表示位0011.1000。但想要表示 16.5 就不行了,因为整数位不够了。
如果明知小数表示 0.5 只需要一位,那向小数部分借两位给整数部分不就可以了,如010000.10,而浮点数(浮动的小数点)就是这么产生的。
不过计算机的前辈们,为了获得更好的二进制数轴和更大的表示范围、表示精度,不会直接按照上面简陋的浮动小数点来定义 IEEE 标准。
IEEE 标准就好比二进制界的科学计数法,比如还是 16.5 = 1.65 * (10^1),二进制就是 01.000010 >> 4。
按照科学计数法每一个浮点数可以表示为 V = (-1)s * M * (2^E)
- 符号位s:正为0 负为1,如上例的 0
- 底数位M:是一个二进制小数,如上例的 1.00001
- 指数位E:是二进制无符号整数减去偏置值所得的差,可以是负哦
上面是表示情况,IEEE 规定了三个区域来编码上面的三种表示数。
- 符号区域s:左侧第一个符号位直接编码了符号位s
- 底数区域frac:frac = (默认不表示的
0.或1.) + 底数值M + (补位0) - 指数区域exp:指数E加偏置值的和表示的无符号二进制数
最后再说一下浮点数表示的三种精度:
表示精度 符号位 底数区域位数 指数区域位数
单精度 1 23 8
双精度 1 52 11
扩展精度 1 15 64
偏置
《问》为什么 exp 不用补码表示正负,而是要采用无符号数加偏置值方式?《、问》
《答》使用无符号数,是为了保证 exp 可以在正负之间和最小到最大之间保持持续递增。而这种递增状态也会体现到表示的 浮点数上。
同时为了保证指数 0 可以在中位数处,所以偏置值是 2^(k-1)-1,最后的 -1 使的最终 的指数 E 的正数比负数多 1。
如 exp = 1010,则 -6 <= E <= 7,因为 0000 和 1111 是非规范数,另作他用。
《、答》
2.4.3 数值示例
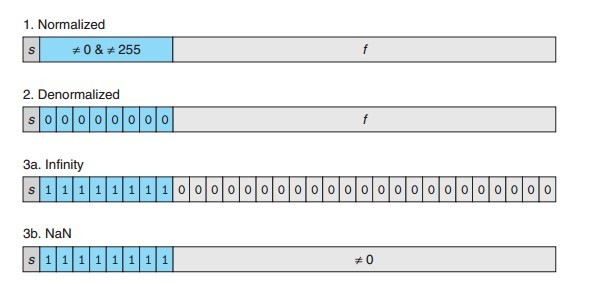
IEEE 表示数会产生四种情况,每种有不同的十进制转换公式,不过都很简单:
1. 规格化值
情况:当指数区域exp既不是全0也不是全1时
底数M:M = 1 + FRAC,FRAC 是 frac 区域表示的二进制小数
指数E:E = EXP - Bias,EXP 是 exp 区域表示的无符号整数,偏置值 Bias=2^(k-1)-1,k 为 exp 位数
举例:
Bias = 2^(4-1)-1 = 7
位表示 EXP EXP-Bias FRAC M Value
0 0001 000 1 -6 0/8 8/8 8/8 * (2^-6) = 8/512
0 0001 001 1 -6 1/8 9/8 9/8 * (2^-6) = 9/512
...
0 0111 000 7 0 0 8/8 1 * (2^0) = 1
...
0 1110 111 14 7 7/8 15/8 15/8 * (2^7) = 240
2. 非规格化值
情况:当指数区域exp全0时
底数M:M = 0 + FRAC,只有 FRAC,为了实现更小的精度,并且提供了对浮点 0 的支持
指数E:E = 1 - Bias,对于非规格化值,不需计算 EXP,直接用 1 - Bias,实现数字的平滑过渡到规格化值
举例:
Bias = 2^(4-1)-1 = 7
位表示 EXP EXP-Bias FRAC M Value
0 0000 000 0 -6 0/8 0/8 +0.0
0 0000 001 0 -6 1/8 1/8 1/8 * (2^-6) = 1/512
...
0 0000 111 0 -6 7/8 7/8 7/8 * (2^-6) = 7/512
对比 7/512 和 8/512 就可以发现为什么非规格化值的 M = 0 + FRAC,而E = 1 - Bias。因为这样
- 可以提供浮点0.0值
- 可以获得更小的表示精度
- 正好保证了最大的非规格化值和最小的规格化值接轨。
3. 特殊数值-无穷大
情况:当指数区域exp全1,并且底数区域全0时
底数M:全0
指数E:全1
举例:
0 1111 000 正无穷
1 1111 000 负无穷
4. 特殊数值-非数字
情况:当指数区域exp全1,并且底数区域也全1时
底数M:非0
指数E:全1
举例:
0 1111 001
1 1111 010
总结
当 IEEE 以上面四种情况表示时,会产生如下的数轴分布:

这样的数轴分布也就意味着,浮点数之间,可以按照无符号编码的风格比较,因为浮点数是按编码单调上升的。
最后在来个完整的例子:
定义一个值:float F = 15123.0
它的二进制:11101101101101
科学计数法:1.1101101101101 * 2^13
为了额外获得一位数字表示,我们永远使底数 M 的正数部分隐式的为 1
则 M = (1.)1101101101101
按照精度补全0,补全的 M 称为 frac = 1101101101101 0000000000
指数 E = 13
偏置值 Bias = 2^(8-1)-1 = 127
则 exp = 13 + 127 = 140
二进制为:10001100
加上符号位 s 是正为 0
所以最终结果是 s + exp + frac
0 10001100 1101101101101 0000000000
2.4.4 舍入
之前我们已经提到过,有很多小数是二进制浮点数无法准确表示的,因此就难免会遇到舍入的问题。这一点其实在我们平时的计算当中会经常出现,就比如之前我们提到过的0.3,它就是无法用浮点小数准确表示的。
我们一般想有一种系统的办法, 能够找到“最接近的”匹配值,它可以用期望的浮点形式表示出来,这就是“舍入”的任务。
不同于十进制简单的四舍五入,浮点数的舍入更丰富一点,有四种方式,分别是++向偶数舍入++、++向零舍入++、++向上舍入++以及++向下舍入++。
向上舍入:向上找到最接近且可表示的浮点数
向下舍入:向下找到最接近且可表示的浮点数
向零舍入:大于零时向下舍入,小于零时向上舍入,总之就是尽量去靠近零
向偶数舍入:平时向接近值舍入,但当要舍入的精度正好位于两个可能值中间时,会向偶数值舍入。
举例:
方式 1.40 1.60 1.50 -1.50 2.50
向上舍入 2.00 2.00 2.00 -1.00 3.00
向下舍入 1.00 1.00 1.00 -2.00 2.00
向零舍入 1.00 1.00 1.00 -1.00 2.00
向偶舍入 1.00 2.00 2.00* -2.00* 2.00*
主要关注最下面的一列向偶数舍入,对于1.40和1.60因为不是正好位于舍入精度的中间 *.50(二进制末尾为1的),因此向最接近的值舍入。而对于后三列,都是在向偶数舍入(使二进制末尾为0)。所以可以简单的记为 四舍六入五取偶。
偶数舍入是默认的舍入方式,在统计中使用可以最大程度的抵消误差。
2.4.5 浮点运算
在IEEE标准中,制定了关于浮点数的运算规则,就是我们将把两个浮点数运算后的精确结果的舍入值,作为我们最终的运算结果。正是因为有了这一个特殊点,就会造成浮点数当中,很多运算不满足我们平时熟知的一些运算特性。
比如加法的结合律,也就是a + b + c = a + (b + c) 的结果就不是定值,如最开始我们说的例子“为什么 (3.14 + 1e10) - 1e10 != 3.14 + (1e10 - 1e10)”。因为对于 1e10 来说,3.14 实在太小了,如果低精度的处理器缓存了 3.14 + 1e10 的结果,代表3.14的底数就会被舍入。
对于不连续甚至会出现巨大差异的情况使用浮点数会造成问题,如果把你的余额和马云的财富放到一起,你的余额就会被舍入。
2.4.6 C语言中的浮点
C 提供了两种不同的浮点数据类型:float 和 double。
强制转换
当 float 或 double 强制转换到 int 时,会对小数部分截断,仅保留整数部分;
当 int 强制转换到 float 时,int 原有 32 位表示整数,而 float 只有 23 位表示底数,所以可能发生舍入;
而 int 强制转换到 double 时,因为 double 有更大的范围,所以可以保留全部精度数值。
当 double 强制转换到 float 时,可能会溢出为正无穷或者负无穷,也可能像 int 一样被舍入。
扩展精度陷阱
前面我们已经知道 IA32 处理器的浮点寄存器为了获得更高的计算精度,所以使用了一种特殊的 80 位扩展精度格式,这比在存储器中的 float 和 double 提供了更大的表示范围和精度。
然而当把扩展寄存器中的浮点存入到存储器中时,不可避免的会发生舍入,这在某些时候,会产生非常奇特的结果。如下例子:
double recip(int denom)
{
return 1.0/(double) denom;
}
void do_nothing(){}
void test(int denom)
{
double d1, d2;
int t1, t2;
d1 = recip(denom);
d2 = recip(denom);
t1 = d1 == d2;
printf("test print t1: d1 %f %c= d2 %f\n", d1, t1?'=':'!', d2);
do_nothing();
t2 = d1 == d2;
printf("test print t2: d1 %f %c= d2 %f\n", d1, t2?'=':'!', d2);
}
上面的例子代码非常简单,也好像一眼就知道了输出,do_nothing() 就如同它的名字一样什么也没做,而 t1 和 t2 也是由相同的表达式生成的,我们预计它们是一样的。
然而,当带有优化选项 “-O2” 编译,并用参数 10 去运行这个程序时,得到了如下结果:
test print t1: d1 0.100000 != d2 0.100000
test print t2: d1 0.100000 == d2 0.100000
而出现不同的原因,就是因为后计算的 d2 当时还存放在浮点寄存器中,拥有更高的精度,也就和已经从寄存器存到存储器中的 d1 有了差异。
当调用任意函数包括 do_nothing 时,会报错寄存器,也就使 d2 也保存到了存储器中,所以造成了现在的输出结果。
以上问题只是多年前的 IA32 和 GCC 的一个Bug,各位道友只需知道这么一种情况,无须较真。如果真的出现类似情况,可以给 GCC 加上参数
-ffloat-store强制保存浮点寄存器到存储器。
总结
计算机将信息编码为bit(位),8位组织成一个 byte(字节)。计算机中有不同的数据类型,分别占用不同的字节。
有不同的编码方式用来表示字符串、代码、整数和小数。他们都依赖于布尔代数和布尔环的理论基础。
大多数机器对整数使用二进制补码编码,而对浮点数使用 IEEE 编码。在位级上理解这些编码,并且理解算数运算的数学特性,对于编写安全稳定可移植的程序是很重要的。
无符号和补码之间的强制类型转换只是改变了十进制的解释方式,而 IEEE 和整数之间的转换就会导致舍入和溢出问题。
对于数字的运算,要时刻小心结果溢出,不过溢出的结果也是有遵循特定规则的。对于数字的乘除法,CPU的需要的时钟周期明显大于加减法,所以编译器会利用移位操作对乘除法进行优化。
完
《本章完》,期待各位道友指出文章的不足之处。
转载请注明出处~~
CSAPP =2= 信息的表示和处理的更多相关文章
- CSAPP:信息的表和处理2
CSAPP:信息的表和处理2 关键点:浮点数.浮点数运算. 二进制小数IEEE浮点数表示浮点数转换(单精度)参考 二进制小数 形如表示的二进制数,其中每个位的取值范围位0和1.这种表示方式的定义如 ...
- CSAPP:信息的表和处理1
CSAPP:信息的表和处理1 关键点:寻址.内存.磁盘.虚拟地址.物理地址.整型数组. 信息存储中的几个概念整型数据类型无符号数有符号数几个概念有符号数与无符号数之间转换基于栈与基于寄存器的区别 信息 ...
- CSAPP 2-1 - 信息的存储
目录 0 基础概念及摘要 1 信息存储 1.1 十六进制表示法 1.2 字数据大小 1.3 寻址和字节顺序 0 基础概念及摘要 (1) 基础概念: 现代计算机存储和处理的信息以二进制信号表示 -- 0 ...
- java笔记整理
Java 笔记整理 包含内容 Unix Java 基础, 数据库(Oracle jdbc Hibernate pl/sql), web, JSP, Struts, Ajax Spring, E ...
- [CSAPP笔记][第二章信息的表示和处理]
信息的表示和处理 2.1 信息存储 机器级程序将存储器视为一个非常大的字节数组,称为虚拟存储器. 存储器的每个字节由一个唯一的数字表示,称为它的地址 所有可能地址的集合称为虚拟地址空间 2.1.1 十 ...
- 【CSAPP】二、信息的表示和处理
三种重要的数字表示:无符号 . 补码 . 浮点数. [一]信息存储 最小单位是字节, 在操作系统层面,只需要关注地址.系统将存储器空间划分为更可管理的单元,存放不同的程序对象(程序数据.指令.控制信息 ...
- 六星经典CSAPP笔记(2)信息的操作和表示
2.Representing and Manipulating Information 本章从二进制.字长.字节序,一直讲到布尔代数.位运算,最后无符号.有符号整数.浮点数的表示和运算.诚然有些地方的 ...
- 信息安全系统设计基础_exp2
北京电子科技学院(BESTI) 实 验 报 告 课程:信息安全系统设计基础 班级:1353 姓名:吴子怡.郑伟 学号:20135313.20135322 指导教师: 娄嘉鹏 实验 ...
- 读完了csapp(中文名:深入理解计算机系统)
上个星期最终把csapp看完了. 我买的是中文版的,由于除了貌似评价不错以外,由于涉及到些自己不了解的底层东西,怕是看英文会云里雾里.如今看来,大概不能算是个长处,可是的确可以加快我的看书速度,否则一 ...
随机推荐
- Flutter 容器Container类和布局Layout类
1.布局和容器 [布局]是把[容器]按照不同的方式排列起来. Scaffold包含的主要部门:appBar,body,bottomNavigator 其中body可以是一个布局组件,也可以是一个容器组 ...
- Deep learning-based personality recognition from text posts of online social networks 阅读笔记
文章目录 一.摘要 二.模型过程 1.文本预处理 1.1 文本切分 1.2 文本统一 2. 基于统计的特征提取 2.1 提取特殊的语言统计特征 2.2 提取基于字典的语言特征 3. 基于深度学习的文本 ...
- Java并发-Synchronized关键字
一.多线程下的i++操作的并发问题 package passtra; public class SynchronizedDemo implements Runnable{ private static ...
- JAVA HTML 以压缩包下载多文件
Html: 利用form表单来发送下载请求 <form id ="submitForm" method="post"> </form> ...
- 配置react / antd 按需加载 并且使用less(react v16)
1.开启项目 并且执行 yarn eject 下载好我们需要的插件(babel-plugin-import less less-loader antd react-loadable ...
- ThinkCMF&Thinkphp 首页静态化处理
基于TP5的页面静态化教程 1.首页在控制器添加以下代码生成静态页面文件 $info = $this->buildHtml("/staticIndex", 'static', ...
- 发布 npm遇到的问题
npm publish 遇到 403 怎么办? 这说明你没有切换到 npm 原始源,那么你只需要用 npm config delete registry 删除淘宝源,然后再 publish. publ ...
- C++ 7种排序方法代码合集
class Solution { public: /******************************************************************** 直接插入排 ...
- [PyTorch 学习笔记] 2.1 DataLoader 与 DataSet
thumbnail: https://image.zhangxiann.com/jeison-higuita-W19AQY42rUk-unsplash.jpg toc: true date: 2020 ...
- sql 游标(理论)
游标是处理结果集的一种机制 --声明游标 --ISO 语法 DECLARE cursor_name [ INSENSITIVE ] [ SCROLL ] CURSOR FOR select_state ...