AQS之ReentrantReadWriteLock精讲分析上篇
1.用法
1.1 定义一个安全的list集合
public class LockDemo {
ArrayList<Integer> arrayList = new ArrayList<>();//定义一个集合
// 定义读锁
ReentrantReadWriteLock.ReadLock readLock = new ReentrantReadWriteLock(true).readLock();
// 定义写锁
ReentrantReadWriteLock.WriteLock writeLock = new ReentrantReadWriteLock(true).writeLock();
public void addEle(Integer ele) {
writeLock.lock(); // 获取写锁
arrayList.add(ele);
writeLock.unlock(); // 释放写锁
}
public Integer getEle(Integer index) {
try{
readLock.lock(); // 获取读锁
Integer res = arrayList.get(index);
return res;
} finally{
readLock.unlock();// 释放读锁
}
}
}
1.2 Sync类中的源码
Sync类中属性介绍
abstract static class Sync extends AbstractQueuedSynchronizer {
// 高16位为读锁,低16位为写锁
static final int SHARED_SHIFT = 16;
// 读锁单位
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
// 读锁最大数量
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
// 写锁最大数量
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 本地线程计数器
private transient ThreadLocalHoldCounter readHolds;
// 缓存的计数器
private transient HoldCounter cachedHoldCounter;
// 第一个读线程
private transient Thread firstReader = null;
// 第一个读线程的计数
private transient int firstReaderHoldCount;
}
Sync类中计数相关类
// 计数器
static final class HoldCounter {
int count = 0; // 计数
// 获取当前线程的TID属性的值
final long tid = getThreadId(Thread.currentThread());
}
HoldCounter主要有两个属性,count和tid,其中count表示某个读线程重入的次数,tid表示该线程的tid字段的值,该字段可以用来唯一标识一个线程
// 本地线程计数器
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
// 重写初始化方法,在没有进行set的情况下,获取的都是该HoldCounter值
public HoldCounter initialValue() {
return new HoldCounter();
}
}
ThreadLocalHoldCounter重写了ThreadLocal的initialValue方法,ThreadLocal类可以将线程与对象相关联。在没有进行set的情况下,get到的均是initialValue方法里面生成的那个HolderCounter对象
Sync类中构造函数
// 构造函数
Sync() {
// 本地线程计数器
readHolds = new ThreadLocalHoldCounter();
// 设置AQS的状态
setState(getState());
}
2.获取读锁源码分析
2.1 读锁加锁分析
先看读锁操作 readLock.lock(), 获取读取锁定
- 如果写锁未被另一个线程持有,则获取读锁并立即返回。
- 如果写锁由另一个线程持有,将当前线程将被阻塞,并处于休眠状态,直到获取读锁为止。
public void lock() {
sync.acquireShared(1);
}
以共享模式获取,此方法不支持中断。 通过首先至少调用一次tryAcquireShared ,并在成功后返回。 否则,线程将排队,并可能反复阻塞和解除阻塞,并调用tryAcquireShared直到成功。
- 返回负数表示获取失败
- 返回0表示成功,但是后继争用线程不会成功
- 返回正数表示获取成功,并且后继争用线程也可能成功
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
2.2 tryAcquireShared 获取锁分析
protected final int tryAcquireShared(int unused) {
// 获取当前线程
Thread current = Thread.currentThread();
// 获取状态
int c = getState();
/**
计算独占的持有次数
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
*/
// exclusiveCount(c) 第一次返回的是0
// 如果写锁线程数不等于0,并且独占锁不是当前线程则返回失败
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
/**
计算共享的持有次数 直接将state右移16位,就可以得到读锁的线程数量
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
*/
// sharedCount(c) 第一次返回的是0
// 读锁的数量
int r = sharedCount(c);
//readerShouldBlock() 当前读线程是否堵塞
if (!readerShouldBlock() &&
// 持有线程小于最大数65535
r < MAX_COUNT &&
// 设置读取锁状态
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
// firstReader是第一个获得读取锁定的线程,
// 第一个读锁firstReader是不会加入到readHolds中
firstReader = current;
// firstReaderHoldCount是firstReader的保留计数也就是
// 读线程占用的资源数为1
firstReaderHoldCount = 1;
// 如果第一个读线程是当前线程那么就将计数+1
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
// 读锁数量不为0并且不为当前线程
// 每个线程读取保持计数的计数器。 维护为ThreadLocal
// 缓存在cachedHoldCounter中
HoldCounter rh = cachedHoldCounter;
// 计数器为空或者计数器的tid不为当前正在运行的线程的tid
if (rh == null || rh.tid != getThreadId(current))
// 获取当前线程对应的计数器
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0) // 计数为0
// 加入到readHolds中
readHolds.set(rh);
rh.count++; // +1
}
// 获取锁成功
return 1;
}
return fullTryAcquireShared(current);
}
readerShouldBlock()
final boolean readerShouldBlock() {
return hasQueuedPredecessors();
}
在独占锁中也调用了该方法,头和尾部不为空不相等整明是有节点的,如果返回true,那么就是有当前线程前面的线程在排队,返回false,那么就是当前线程是在队列的头部的下一个节点或者队列是空的
public final boolean hasQueuedPredecessors() {
Node t = tail;
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
2.3 fullTryAcquireShared
获取读锁的完整版本,可处理tryAcquireShared中未处理的CAS丢失和可重入读操作
final int fullTryAcquireShared(Thread current) {
HoldCounter rh = null;
for (;;) {
// 获取状态
int c = getState();
// 如果写线程数量不为0
if (exclusiveCount(c) != 0) {
// 如果不是当前线程
if (getExclusiveOwnerThread() != current)
return -1;
// 写线程数量为0并且读线程被阻塞
} else if (readerShouldBlock()) {
// 确保我们没有重新获取读锁
if (firstReader == current) {
// 当前线程为第一个读线程
} else {
// 当前线程不为第一个读线程
if (rh == null) { // 计数器为空
rh = cachedHoldCounter;
// 计数器为空或者计数器的tid不为当前正在运行的线程的tid
if (rh == null || rh.tid != getThreadId(current)) { // 获取当前线程对应的计数器
rh = readHolds.get();
if (rh.count == 0) // 计数为0
// 从readHolds中移除
readHolds.remove();
}
}
if (rh.count == 0)
// 获取锁失败了
return -1;
}
}
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// 比较并且设置成功
if (compareAndSetState(c, c + SHARED_UNIT)) {
// 读线程数量为0
if (sharedCount(c) == 0) {
// firstReader是第一个获得读取锁定的线程,
// 第一个读锁firstReader是不会加入到readHolds中
firstReader = current;
firstReaderHoldCount = 1;
// 如果第一个读线程是当前线程那么就将计数+1
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
// 读锁数量不为0并且不为当前线程
// 每个线程读取保持计数的计数器。 维护为ThreadLocal
// 缓存在cachedHoldCounter中
if (rh == null)
rh = cachedHoldCounter;
// 计数器为空或者计数器的tid不为当前正在运行的线程的tid
if (rh == null || rh.tid != getThreadId(current))
// 获取当前线程对应的计数器
rh = readHolds.get();
else if (rh.count == 0)
// 加入到readHolds中
readHolds.set(rh);
rh.count++;
cachedHoldCounter = rh; // cache for release
}
// 获取锁成功
return 1;
}
}
}
2.4tryAcquireShared失败
如果tryAcquireShared(arg)返回的值为正数或者为0,那么意味着获取锁失败,执行doAcquireShared(arg)方法
private void doAcquireShared(int arg) {
// 将节点放入阻塞队列中返回当前节点,addWaiter前一篇文章已经讲过了
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
// 如果前置节点的waitStatus为唤醒那么就可以安心睡眠了,并且挂起当
// 前线程
if (shouldParkAfterFailedAcquire(p, node) &&
// 挂起当前线程
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
2.5setHeadAndPropagate
设置队列的头部,并检查后继者是否可能在共享模式下等待,如果正在传播,则传播是否设置为传播> 0或PROPAGATE状态
这个函数做的事情有两件:
- 在获取共享锁成功后,设置head节点
- 根据调用tryAcquireShared返回的状态以及节点本身的等待状态来判断是否要需要唤醒后继线程
在该方法内部我们不仅调用了setHead(node),还在一定条件下调用了doReleaseShared()来唤醒后继的节点。这是因为在共享锁模式下,锁可以被多个线程所共同持有,既然当前线程已经拿到共享锁了,那么就可以直接通知后继节点来拿锁,而不必等待锁被释放的时候再通知。
propagate是tryAcquireShared的返回值,这是决定是否传播唤醒的依据之一
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
// h.waitStatus为SIGNAL或者PROPAGATE时也根据node的下一个节点共享来决定
// 是否传播唤醒
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
2.6 doReleaseShared()
共享模式下的释放动作-信号后继并确保传播
以下的循环做的事情就是,在队列存在后继线程的情况下,唤醒后继线程;或者由于多线程同时释放共享锁由于处在中间过程,读到head节点等待状态为0的情况下,虽然不能unparkSuccessor,但为了保证唤醒能够正确稳固传递下去,设置节点状态为PROPAGATE。
这样的话获取锁的线程在执行setHeadAndPropagate时可以读到PROPAGATE,从而由获取锁的线程去释放后继等待线程。
在共享锁模式下,头节点就是持有共享锁的节点,在它释放共享锁后,它也应该唤醒它的后继节点,但是值得注意的是,我们在之前的setHeadAndPropagate方法中可能已经调用过该方法了,也就是说它可能会被同一个头节点调用两次,也有可能在我们从releaseShared方法中调用它时,当前的头节点已经易主了
private void doReleaseShared() {
for (;;) {
Node h = head;
// 如果队列中存在后继线程
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
// 如果h节点的状态为0,需要设置为PROPAGATE用以保证唤醒的传播
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
// 检查h是否仍然是head,如果不是的话需要再进行循环
if (h == head) // loop if head changed
break;
}
}
在看该方法时,我们需要明确以下几个问题:
- 该方法有几处调用?
- 该方法有两处调用,一处在doAcquireShared方法的末尾,当线程成功获取到共享锁后,在一定条件下调用该方法;
- 一处在releaseShared方法中,当线程释放共享锁的时候调用
- 调用该方法的线程是谁?
在共享锁中,持有共享锁的线程可以有多个,这些线程都可以调用releaseShared方法释放锁;因为这些线程想要获得共享锁,则它们必然曾经成为过头节点,或者就是现在的头节点。所以如果是在releaseShared方法中调用的doReleaseShared,那么此时调用方法的线程可能已经不是头节点所代表的线程了,此时头节点可能已经被更换了好几次了。
- 调用该方法的目的是什么?
无论是在doAcquireShared中调用,还是在releaseShared方法中调用,该方法的目的都是在当前共享锁是可获取的状态时,唤醒head节点的下一个节点。(看上去和独占锁唤醒下一个节点似乎一样),但是它们的一个重要的差别是在共享锁中,当头节点发生变化时,是会回到循环中再立即唤醒head节点的下一个节点的。
- 退出该方法的条件是什么
该方法是一个自旋操作,退出该方法的唯一办法是走最后的break语句
if (h == head) // loop if head changed
break;
只有在当前head没有变的时候,才会退出,否则继续循环。为什么呢?
为了说明问题,这里我们假设目前sync queue队列中依次排列有
dummy node -> A -> B -> C -> D
现在假设A已经拿到了共享锁,则它将成为新的dummy node,
dummy node (A) -> B -> C -> D
此时,A线程会调用doReleaseShared,我们写做doReleaseShared[A],在该方法中将唤醒后继的节点B,它很快获得了共享锁,成为了新的头节点:
dummy node (B) -> C -> D
此时,B线程也会调用doReleaseShared,我们写做doReleaseShared[B],在该方法中将唤醒后继的节点C,但是别忘了,在doReleaseShared[B]调用的时候,doReleaseShared[A]还没运行结束呢,当它运行到if(h == head)时,发现头节点现在已经变了,所以它将继续回到for循环中,与此同时,doReleaseShared[B]也没闲着,它在执行过程中也进入到了for循环中
我们这里形成了一个doReleaseShared的调用循环,大量的线程在同时执行doReleaseShared,这极大地加速了唤醒后继节点的速度,提升了效率,同时该方法内部的CAS操作又保证了多个线程同时唤醒一个节点时,只有一个线程能操作成功。
那如果这里doReleaseShared[A]执行结束时,节点B还没有成为新的头节点时,doReleaseShared[A]方法不就退出了吗?是的,但即使这样也没有关系因为它已经成功唤醒了线程B,即使doReleaseShared[A]退出了,当B线程成为新的头节点时doReleaseShared[B]就开始执行了,它也会负责唤醒后继节点的,这样即使变成这种每个节点只唤醒自己后继节点的模式,从功能上讲,最终也可以实现唤醒所有等待共享锁的节点的目的,只是效率上没有之前的快。
由此我们知道,这里的调用循环事实上是一个优化操作,因为在我们执行到该方法的末尾的时候,unparkSuccessor基本上已经被调用过了,而由于现在是共享锁模式,所以被唤醒的后继节点极有可能已经获取到了共享锁,成为了新的head节点,当它成为新的head节点后,它可能还是要在setHeadAndPropagate方法中调用doReleaseShared唤醒它的后继节点。
明确了上面几个问题后,我们再来详细分析这个方法
private void doReleaseShared() {
for (;;) {
Node h = head;
// 如果队列中存在后继线程也就是队列至少有两个节点
if (h != null && h != tail) {
int ws = h.waitStatus;
// 如果当前ws值为Node.SIGNAL,则说明后继节点需要唤醒,这里采用CAS操作先将
// Node.SIGNAL状态改为0,这是因为可能有大量的doReleaseShared方法在
// 同时执行,我们只需要其中一个执行unparkSuccessor(h)操作就行了,这里通过CAS
// 操作保证了unparkSuccessor(h)只被执行一次。
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
// 如果h节点的状态为0,需要设置为PROPAGATE用以保证唤醒的传播
// ws啥时候为0
// 一种是上面的compareAndSetWaitStatus(h, Node.SIGNAL, 0)会导致ws为0,
// 但是很明显,如果是因为这个原因,则它是不会进入到else if语句块的。所以这里
// 的 ws为0是指当前队列的最后一个节点成为了头节点。为什么是最后一个节点呢,因为
// 每次新的节点加进来,在挂起前一定会将自己的前驱节点的waitStatus修
// 改成 Node.SIGNAL的
else if (ws == 0 &&
// compareAndSetWaitStatus(h, 0, Node.PROPAGATE)这个操作什么时候会失败?
// 这个操作失败,说明就在执行这个操作的瞬间,ws此时已经不为0了,说明有新的节点
// 入队了,ws的值被改为了Node.SIGNAL,此时我们将调用continue,在下次循环中
// 直接将这个刚刚新入队但准备挂起的线程唤醒
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
// 检查h是否仍然是head,如果不是的话需要再进行循环
if (h == head) // loop if head changed
break;
}
}
private void unparkSuccessor(Node node) {
// 获取当前节点的node.waitStatus 此时为 SIGNAL所以将当前节点的waitStatus
// 设置成 0
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
// 获取后继节点
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
// 往前寻找遍历找到第一个节点waitStatus 为SIGNAL的节点,为了唤醒其节点
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 如果不为空直接唤醒后继节点
if (s != null)
LockSupport.unpark(s.thread);
}
这里优化了一个点:
- 首先队列里至少有两个节点
- 其次要执行到else if语句,说明我们跳过了前面的if条件,说明头节点是刚刚成为头节点的,它的waitStatus值还为0,尾节点是在这之后刚刚加进来的,它需要执行shouldParkAfterFailedAcquire,将它的前驱节点(即头节点)的waitStatus值修改为Node.SIGNAL,但是目前这个修改操作还没有来的及执行。这种情况使我们得以进入else if的前半部分else if (ws == 0 &&
- 再次,要满足!compareAndSetWaitStatus(h, 0, Node.PROPAGATE)这一条件,说明此时头节点的 waitStatus 已经不再是 0 了,这说明之前那个没有来得及执行的在shouldParkAfterFailedAcquire将前驱节点的的waitStatus值修改为Node.SIGNAL的操作现在执行完了。
注意:else if 的 && 连接了两个不一致的状态,分别对应了shouldParkAfterFailedAcquire的compareAndSetWaitStatus(pred, ws, Node.SIGNAL)执行成功前和执行成功后,因为doReleaseShared和shouldParkAfterFailedAcquire是可以并发执行的,所以这一条件是有可能满足的,可能只是一瞬间发生的。
3.获取读锁流程图

流程解析:
读锁获取锁的过程比写锁稍微复杂些
- 首先判断写锁是否为0并且当前线程不占有独占锁,直接返回;
- 否则,判断读线程是否需要被阻塞并且读锁数量是否小于最大值并且比较设置状态成功,若当前没有读锁,则设置第一个读线程firstReader和firstReaderHoldCount;
- 若当前线程线程为第一个读线程,则增加firstReaderHoldCount;
- 否则,将设置当前线程对应的HoldCounter对象的值。
4.释放读锁源码分析
4.1释放锁的时候调用ReadLock的unlock方法
public void unlock() {
sync.releaseShared(1);
}
4.2sync.releaseShared(1)调用的是AQS中的 releaseShared方法
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
4.3tryReleaseShared方法的具体实现是在具体的子类中
protected final boolean tryReleaseShared(int unused) {
// 获取当前线程
Thread current = Thread.currentThread();
// 当前线程是否是第一个读线程
if (firstReader == current) {
// 如果读线程占用的资源为1那么将firstReader设置成null
if (firstReaderHoldCount == 1)
firstReader = null;
// 如果不是那么就减一
else
firstReaderHoldCount--;
} else {
// 如果当前线程不是第一个读线程
// 获取缓存计数器
HoldCounter rh = cachedHoldCounter;
// 计数器为空或者计数器的tid不为当前正在运行的线程的tid
if (rh == null || rh.tid != getThreadId(current))
// 获取当前线程对应的计数器
rh = readHolds.get();
// 获取计数器中count的值
int count = rh.count;
if (count <= 1) {
// 移除
readHolds.remove();
if (count <= 0)
throw unmatchedUnlockException();
}
// 如果不小于等于1 减少资源占用
--rh.count;
}
for (;;) { // 自旋
// 获取状态
int c = getState();
// 计算状态
int nextc = c - SHARED_UNIT;
// 设置状态
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
如果tryReleaseShared(arg)方法返回true那么执行doReleaseShared()方法,前文已经讲过该方法了。
5.释放读锁流程图
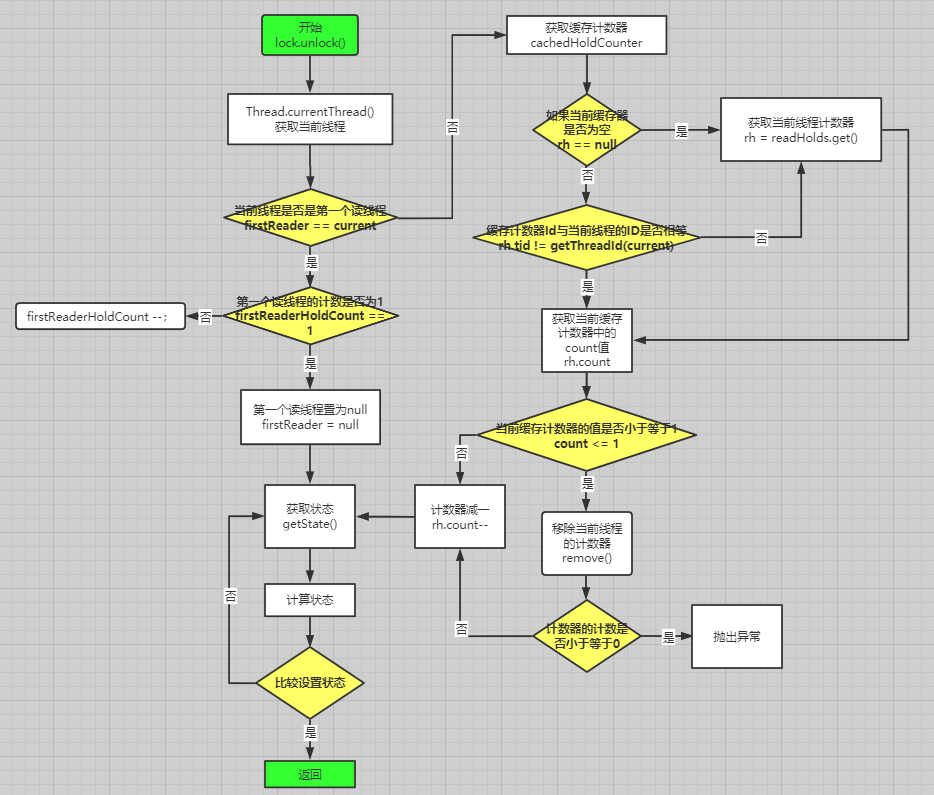
流程解析:
- 首先判断当前线程是否为第一个读线程firstReader,若是,则判断第一个读线程占有的资源数firstReaderHoldCount是否为1,若是,则设置第一个读线程firstReader为空,否则,将第一个读线程占有的资源数firstReaderHoldCount减1;
- 若当前线程不是第一个读线程,那么首先会获取缓存计数器,若计数器为空或者tid不等于当前线程的tid值,则获取当前线程的计数器,如果计数器的计数count小于等于1,则移除当前线程对应的计数器,如果计数器的计数count小于等于0,则抛出异常,之后再减少计数即可。
- 哪种情况,都会进入自选操作,该循环可以确保成功设置状态state
6.注意
6.1 HoldCounter的作用
在读锁的获取、释放过程中,总是会有一个对象存在着,同时该对象在获取线程获取读锁是+1,释放读锁时-1,该对象就是HoldCounter。
6.2 HoldCounter的原理
要明白HoldCounter就要先明白读锁。前面提过读锁的内在实现机制就是共享锁,对于共享锁它更加像一个计数器的概念。一次共享锁操作就相当于一次计数器的操作,获取共享锁计数器+1,释放共享锁计数器-1。只有当线程获取共享锁后才能对共享锁进行释放、重入操作。所以HoldCounter的作用就是当前线程持有共享锁的数量,这个数量必须要与线程绑定在一起,否则操作其他线程锁就会抛出异常。
6.3 读锁部分源码详解
// 表示第一个读锁线程,第一个读锁firstRead是不会加入到readHolds中
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
// 第一个读锁线程重入
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
// 如果当前线程不是第一个读线程
// 获取缓存计数器
HoldCounter rh = cachedHoldCounter;
// 计数器为空或者计数器的tid不为当前正在运行的线程的tid
if (rh == null || rh.tid != current.getId())
// 获取当前线程对应的计数器
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
// 加入到readHolds中
readHolds.set(rh);
//计数+1
rh.count++;
}
这里为什么要搞一个firstRead、firstReaderHoldCount呢?而不是直接使用else那段代码?
这是为了一个效率问题,firstReader是不会放入到readHolds中的,如果读锁仅有一个的情况下就会避免查找readHolds。我们先看firstReader、firstReaderHoldCount的定义:
private transient Thread firstReader = null;
private transient int firstReaderHoldCount;
这两个变量比较简单,一个表示线程,一个是firstReader的计数。
HoldCounter的定义:(文章中第二次提到该代码)
HoldCounter主要有两个属性,count和tid,其中count表示某个读线程重入的次数,tid表示该线程的tid字段的值,该字段可以用来唯一标识一个线程
static final class HoldCounter {
int count = 0;
final long tid = Thread.currentThread().getId();
}
在HoldCounter中仅有count和tid两个变量。但是如果要将一个对象和线程绑定起来仅记录tid肯定不够的,而且HoldCounter根本不能起到绑定对象的作用,只是记录线程tid而已。
在java中,我们知道如果要将一个线程和对象绑定在一起只有ThreadLocal才能实现。所以如下:
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
public HoldCounter initialValue() {
return new HoldCounter();
}
}
ThreadLocalHoldCounter继承ThreadLocal,并且重写了initialValue方法。
所以HoldCounter应该就是绑定线程上的一个计数器,而ThradLocalHoldCounter则是线程绑定的ThreadLocal。从上面我们可以看到ThreadLocal将HoldCounter绑定到当前线程上,同时HoldCounter也持有线程Id,这样在释放锁的时候才能知道ReadWriteLock里面缓存的上一个读取线程(cachedHoldCounter)是否是当前线程。这样做的好处是可以减少ThreadLocal.get()的次数,因为这也是一个耗时操作。需要说明的是这样HoldCounter绑定线程id而不绑定线程对象的原因是避免HoldCounter和ThreadLocal互相绑定而GC难以释放它们,所以其实这样做只是为了帮助GC快速回收对象而已。
7.总结
以上便是ReentrantReadWriteLock中读锁的分析,下一篇文章将是写锁的分析,如有错误之处,帮忙指出及时更正,谢谢,如果喜欢谢谢点赞加收藏加转发(转发注明出处谢谢!!!)
AQS之ReentrantReadWriteLock精讲分析上篇的更多相关文章
- Java并发指南10:Java 读写锁 ReentrantReadWriteLock 源码分析
Java 读写锁 ReentrantReadWriteLock 源码分析 转自:https://www.javadoop.com/post/reentrant-read-write-lock#toc5 ...
- 深入Java核心 Java内存分配原理精讲
深入Java核心 Java内存分配原理精讲 栈.堆.常量池虽同属Java内存分配时操作的区域,但其适用范围和功用却大不相同.本文将深入Java核心,详细讲解Java内存分配方面的知识. Java内存分 ...
- iOS开发——语法篇OC篇&高级语法精讲二
Objective高级语法精讲二 Objective-C是基于C语言加入了面向对象特性和消息转发机制的动态语言,这意味着它不仅需要一个编译器,还需要Runtime系统来动态创建类和对象,进行消息发送和 ...
- Linux实战教学笔记12:linux三剑客之sed命令精讲
第十二节 linux三剑客之sed命令精讲 标签(空格分隔): Linux实战教学笔记-陈思齐 ---更多资料点我查看 1,前言 我们都知道,在Linux中一切皆文件,比如配置文件,日志文件,启动文件 ...
- Linux实战教学笔记18:linux三剑客之awk精讲
Linux三剑客之awk精讲(基础与进阶) 标签(空格分隔): Linux实战教学笔记-陈思齐 快捷跳转目录: * 第1章:awk基础入门 * 1.1:awk简介 * 1.2:学完awk你可以掌握: ...
- 【原创】分布式之redis复习精讲
引言 为什么写这篇文章? 博主的<分布式之消息队列复习精讲>得到了大家的好评,内心诚惶诚恐,想着再出一篇关于复习精讲的文章.但是还是要说明一下,复习精讲的文章偏面试准备,真正在开发过程中, ...
- 转 Redis 总结精讲 看一篇成高手系统-4
转 Redis 总结精讲 看一篇成高手系统-4 2018年05月31日 09:00:05 hjm4702192 阅读数:125633 本文围绕以下几点进行阐述 1.为什么使用redis 2.使用r ...
- Java岗 面试考点精讲(基础篇01期)
即将到来金三银四人才招聘的高峰期,渴望跳槽的朋友肯定跟我一样四处找以往的面试题,但又感觉找的又不完整,在这里我将把我所见到的题目做一总结,并尽力将答案术语化.标准化.预祝大家面试顺利. 术语会让你的面 ...
- Keepalived原理与实战精讲--VRRP协议
. 前言 VRRP(Virtual Router Redundancy Protocol)协议是用于实现路由器冗余的协议,最新协议在RFC3768中定义,原来的定义RFC2338被废除,新协议相对还简 ...
随机推荐
- Fastjson 1.2.47 远程命令执行漏洞复现
前言 这个漏洞出来有一段时间了,有人一直复现不成功来问我,就自己复现了下,顺便简单记录下这个漏洞原理,以便后面回忆. 复现过程 网上已经有很多文章了,这里就不在写了.主要记录一下复现过程中遇到的问题 ...
- JVM虚拟机(三):Java内存区域
运行时数据区 Java虚拟机再执行Java程序过程中会把它所管理的内存划分为若干个不同分工的数据区域. 程序计数器 程序计数器时一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示 ...
- vue 表单基本 表单修饰符
表单的基础 利用v-model进行双向数据绑定: 1.在下拉列表中,将v-model写在select中 2.单选框和复选框需要每个按钮都需要写上v-model 3.v-model在输入框中获取得是输入 ...
- springmvc中ModelAttribute注解应用在参数中
可以用@ModelAttribute来注解方法参数或方法.带@ModelAttribute创建的参数对象会被添加到Model对象中.注解在参数上时,可以从Form表单或URL参数中获取参数并绑定到mo ...
- 面向切面@Aspect
package com.imooc.demo.filter; import org.springframework.core.Ordered; import org.springframework.c ...
- Mybatis-Plus的Service方法使用 之 泛型方法default <V> List<V> listObjs(Function<? super Object, V> mapper)
首先 我们先看到的这个方法入参是:Function<? super Object , V> mapper ,这是jdk1.8为了统一简化书写格式引进的函数式接口 . 简单 解释一下我对Fu ...
- idea提交svn不显示新建文件
在idea中,使用svn提交时可能会出现 预期文件没出现在提交目录里. 是因为没有把新建文件添加到版本控制里. 解决办法:右键选择文件→subversion→add to vcs. 自动把新文件添加 ...
- 由两个问题引发的对GaussDB(DWS)负载均衡的思考
摘要:GaussDB(DWS)的负载均衡通过LVS+keepAlived实现.对于这种方式,需要思考的问题是,CN的返回结果是否会经过LVS,然后再返回给前端应用?如果经过LVS,那么,LVS会不会成 ...
- [永恒之黑]CVE-2020-0796(漏洞复现)
实验环境: 靶机:windows10 1903 专业版 攻击机:kali 2020.3 VMware:vmware14 实验工具: Python 3.8.5 msfconsole 实验PROC: ...
- Mac如何下载软件
1.App Store 2.软件官网 3.Mac软件网站 4.搜狗微信 个人首选App Store,里面的软件安全可靠,其次就是官网,必不得已才去其他网站下载,毕竟不是App Store或官网 ...